《MedSegDiff Medical Image Segmentation with Diffusion Probabilistic Model》论文阅读理解
《MedSegDiff Medical Image Segmentation with Diffusion Probabilistic Model》论文阅读理解
领域:Anomaly Detection(缺陷检测)
论文地址:MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
1 主要动机
医学图像分割为医生检测疾病提供了一定的便利。DPM扩散概率模型在计算机视觉的分割任务中取得了很大的成功。同时,DPM对于超分辨率和去模糊任务以及缺陷检测任务中也很有效。医学图像分割任务中,损伤/器官是不容易和背景区分开的,因此,在分割阶段提出一个自适应矫正过程对得到清晰可区分的结果是重要的。
2 主要贡献
- 提出了基于DPM的通用医学图像分割模型;
- 对于步进式注意力机制,提出了动态条件编码策略;
- 为了消除高频的高斯噪声的影响,提出了FF-Parser特征频率解析器;
- 文中提出的方法在三种不同图像形态的医学分割任务中的表现SOTA;
3 方法概述
在迭代采样过程中,MedSegDiff以图像先验条件约束每一步,以便从中学习分割映射。对于自适应区域注意,文中将当前步骤的分割图整合到每一步的图像先验编码中。具体实现是将当前步分割掩码与先验图像在特征层上进行多尺度融合。这样,当前步骤的分割掩码有助于动态增强条件特征,从而提高重建精度。
在此过程中,为了消除当前的分割掩码中的高频噪声,文中进一步提出了特征频率解析器(FF-Parser)以对傅里叶空间中的特征进行滤波。在每个跳跃连接路径上采用FF-Parser,实现多尺度集成。
4 文章内容
4.1 方法详述
4.1.1 整体流程和架构
在正向过程中,通过T个步骤给分割二值Mask不断地添加高斯噪声,反向过程使用一个被训练的神经网络来反转噪声来恢复原始数据,该过程可以表示为如下公式:
p θ ( x 0 : T − 1 ∣ X T ) = ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p_\theta(x_{0:T-1|}X_T)=\prod^T_{t=1}p_\theta(x_{t-1}|x_t) pθ(x0:T−1∣XT)=t=1∏Tpθ(xt−1∣xt)
其中, θ \theta θ是反向过程中的参数。
从高斯噪声开始,反向过程将隐式变量分布 p θ ( x T ) p_\theta(x_T) pθ(xT)转换为数据集分布 p θ ( x 0 ) p_\theta(x_0) pθ(x0)。与前向传播相对称,反向过程一步一步将噪声图片进行恢复来得到最终的清晰分割Mask。
文中使用UNet来作为训练网络,图1展示了MedSedDiff模型的整体架构。
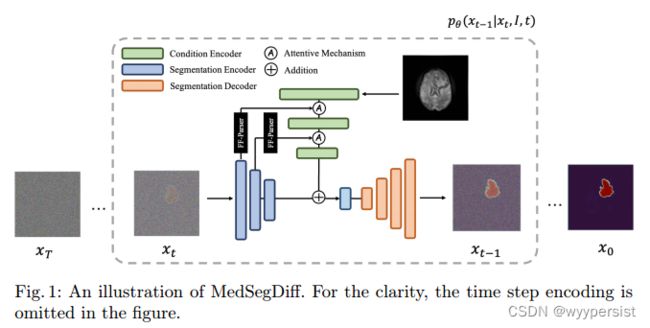
为了得到分割Mask,文中提出了步进估计函数 ϵ \epsilon ϵ,将原始图像作为参数输入进去,其被表示为如下公式:
ϵ ( x t , I , t ) = D ( ( E t I + E t x , t ) , t ) \epsilon(x_t,I,t)=D((E^I_t+E_t^x,t),t) ϵ(xt,I,t)=D((EtI+Etx,t),t)
其中, E t I E_t^I EtI是条件的特征嵌入,原始图片嵌入 E t x E_t^x Etx是当前步骤step的分割Mask特征嵌入。这两个组件被加在一起然后送入到UNet网络的解码器 D D D进行重建。步骤index: t包含了被加在一起的嵌入embedding和解码器输出的特征。在每个步骤,使用共享学习look-up表(参考文章[1])来进行嵌入。
4.1.2 动态条件编码
文中表明,对医学图像分割领域来说,仅仅在DPM反向恢复重建图片的时候加入静态图片 I I I作为条件约束是难以使得网络进行学习的。因此,文中引入了动态条件编码。一方面,原始的图片包含了准确的分割信息,但是难以与图片背景区分开来,另一方面,在DPM反向恢复重建阶段的分割Map包含了加强后的目标分割区域但是不准确,因此这些原因促使作者将当前步骤 t t t对应的模糊分割Map与原始图像输入到编码模块之后的输出进行结合,作为相互补充的特征然后共同输入到一个Decoder中。
需要注意的是,在对原始图像使用encoder编码时,作者结合了当前步骤 t t t下的编码特征。每个原始图像编码之后得到的条件Mask特征 m I k m_I^k mIk与当前步骤 t t t中的 x t x_t xt通过编码器得到的特征 m x k m_x^k mxk在相同的尺度和形状上进行融合。其中, k k k为特征融合的层index。
上述的融合过程使用attentive-like机制 A A A。需要注意的是,两个每层特征融合的时候都需要首先经过一个正则化层,然后将两个特征进行相乘来得到融合后的层index特征。然后,使用这个融合后的index特征再与原始图像通过编码器得到的特征进行相乘以增强需要注意区域,上述完整过程可以表示为如下公式:
A ( m I k , m x k ) = ( L N ( m I k ) ⨂ L N ( m x k ) ) ⨂ m I k A(m_I^k,m_x^k)=(LN(m_I^k)\bigotimes LN(m_x^k))\bigotimes m_I^k A(mIk,mxk)=(LN(mIk)⨂LN(mxk))⨂mIk
其中, ⨂ \bigotimes ⨂表示element-wise乘法, L N LN LN表示层级正则化。这个操作应用与ResNet34中的两个卷积阶段。这个策略帮助MedSegDiff动态调整和定位分割区域。
上述这个策略也带来了一些问题:将原始图像通过编码器得到的特征与 x t x_t xt对应的特征嵌入进行融合的时候会带入高频的噪声。因此,文中又提出了FF-Parser来限制高频噪声对融合后特征的影响。
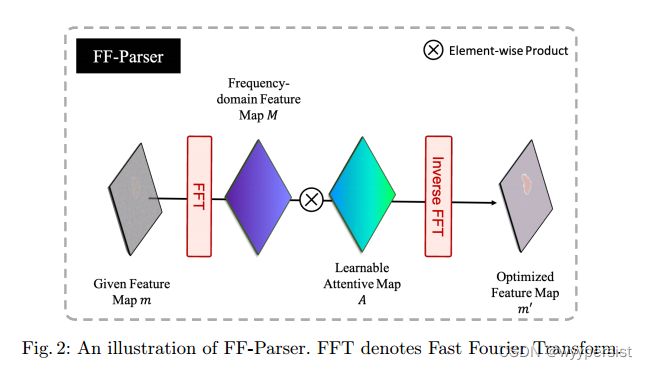
4.1.3 FF-Parser
文中将FF-Parser放置在了从 x t x_t xt提取特征之后与原始图像Mask进行融合之前的路径上。主要目的是去学习一个参数化的注意力(权重)map其应用了傅里叶空间特征。给定一个解码器输出的map, m ∈ R H × W × C m\in R^{H\times W\times C} m∈RH×W×C,我们首先沿着空间维度执行二维的FFT(快速傅里叶变换),该过程可以被表示为:
M = F [ m ] ∈ C H × W × C M=F[m]\in C^{H\times W\times C} M=F[m]∈CH×W×C
其中, F [ ⋅ ] F[\cdot] F[⋅]表示2D FFT。然后,通过将 M M M与一个参数化的注意力map, A ∈ C H × W × C A\in C^{H\times W\times C} A∈CH×W×C进行相乘来调节 m m m的频谱。
M ′ = A ⨂ M M'=A\bigotimes M M′=A⨂M
其中, ⨂ \bigotimes ⨂表示element-wise乘法。
最后,使用逆FFT将 M ′ M' M′送回到原始的空间域中。
m ′ = F − 1 [ M ′ ] m'=F^{-1}[M'] m′=F−1[M′]
FF-Parser可以被认为是一个可学习版的序列滤波器,其被广泛的应用到数字图像处理过程中。
4.2 训练过程和模型整体框架
文中指出,MedSegDiff的训练遵循DPM[1]中的标准过程,其使用的损失函数如下:
L = E x 0 , ϵ , t [ ∣ ∣ ϵ − ϵ θ ( a ^ t x 0 + 1 − a ^ t ϵ , I i , t ) ∣ ∣ 2 ] L=E_{x_0,\epsilon,t}[||\epsilon -\epsilon_{\theta}(\sqrt{\hat{a}_tx_0}+\sqrt{1-\hat{a}_t\epsilon},I_i,t)||^2] L=Ex0,ϵ,t[∣∣ϵ−ϵθ(a^tx0+1−a^tϵ,Ii,t)∣∣2]
在每个训练迭代中,一对随机选择的原始图片 I i I_i Ii和分割二值标签 S i S_i Si被输入到训练过程中。
迭代数量从一个正态分布中采样得到, ϵ \epsilon ϵ从高斯分布中采样得到。
MedSegDiff的主要架构来自于一个修改的ResUNet[2]。其中,作者遵循UNet编码器并使用ResNet编码器来实现修改。具体的网络相关的设置可以参考文献[3]。
I I I和 x t x_t xt使用两个独立的编码器来进行编码。
编码器由三个卷积阶段组成。每个阶段包含了一些残差块。每个阶段的残差块数量遵循了ResNet34。每个残差块由两个卷积模块组成,每个卷积模块包含批量正则化+SiLU[4]激活层和一个卷积层。
残差块通过一个线性层+SiLU激活+其他的线性层来得到时间嵌入。然后,这个时间嵌入的结果被添加到第一个卷积模块的输出中。
上述阶段得到的 E I E^I EI和 E x i E^{x_i} Exi被加到一起,然后被送入到最后的编码阶段。
最后连接一个标准的卷积解码器来得到最终的结果。
5 实验结果
5.1 数据集
- 来自fundus图片数据的视杯分割数据集;
- 来自MRI图片数据的脑肿瘤分割数据集;
- 来自超声波图片数据的甲状腺结节数据集;
视杯、甲状腺结节和脑肿瘤的实验诊断是在 REFUGE-2 数据集 [5]、BraTs-2021 数据集 [6] 和 DDTI数据集[7],分别包含1200、2000、8046个样本。
5.2 实验细节
文中分别对模型的大型、大型、基本和小型变体 MedSegDiff++、MedSegDiff-L、MedSegDiff-B 和 MedSegDiff-S 进行了实验。
在 MedSegDiff-S、MedSegDiff-B、MedSegDiff-L、MedSegDiff++ 中,文中分别使用具有 4x、5x、6x、6x 下采样的 UNet。在实验中,作者使用 100 个扩散步骤进行推理,这比以前的大多数研究小得多。除了 MedSegDiff++ 和 MedSegDiff-L 之外,所有实验均使用 PyTorch 平台实现,并在具有 24GB 内存的 4 个 Tesla P40 GPU 上进行训练/测试。所有图像统一调整为 256×256 像素的尺寸。使用 AdamW优化器以端到端的方式训练网络。MedSegDiff-B 和 MedSegDiff-S 以 32 batchsize大小进行训练,MedSegDiff-L 和 MedSegDiff++ 以 64 batchsize大小进行训练。学习率初始设置为 1×10−4。所有模型在推理中都设置了 25 次集成。文中使用 STAPLE算法来融合不同的样本。基于扩散的竞争对手 EnsemDiff使用相同的设置进行复制,以进行公平比较。
5.3 实验结果
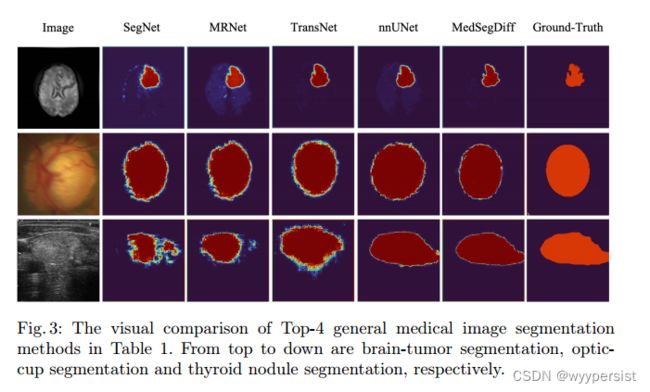
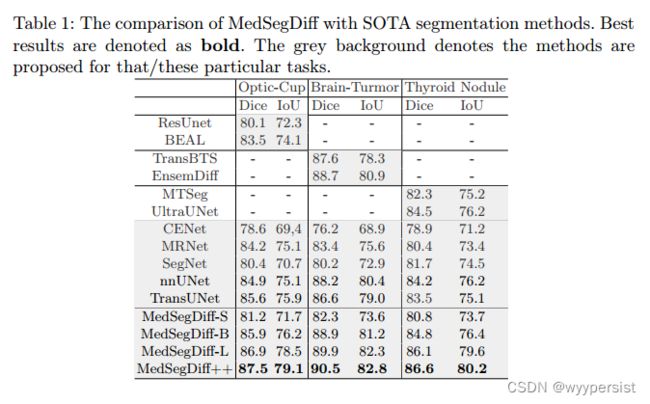
文中进行了全面的消融研究,以验证所提出的动态调节和 FF-Parser 的有效性。 结果如表2所示,其中Dy-Cond表示动态调节。 文中通过 Dice 分数 (%) 评估所有三个任务的性能。 从表中可以看到 Dy-Cond 相对于 vanilla DPM 有了相当大的改进。 在区域定位很重要的情况下,即视杯分割,它提高了 2.1%。 在图像对比度较低的情况下,如脑肿瘤和甲状腺结节分割,分别提高了 1.6% 和 1.8%。 它表明 Dy-Cond 对于这两种情况都是一种普遍有效的 DPM 策略。 在 Dy-Cond 上建立的 FF-Parser 减轻了高频噪声,从而进一步优化了分割结果。 它帮助 MedSegDiff 进一步提高近 1% 的性能,并在所有三项任务上均达到最佳。

参考文献
[1] Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 33, 6840–6851 (2020)
[2] Yu, S., Xiao, D., Frost, S., Kanagasingam, Y.: Robust optic disc and cup segmentation with deep learning for glaucoma detection. Computerized Medical Imaging and Graphics 74, 61–71 (2019)
[3] Nichol, A.Q., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: International Conference on Machine Learning. pp. 8162–8171. PMLR (2021)
[4] Elfwing, S., Uchibe, E., Doya, K.: Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Networks 107, 3–11(2018)
[5] Fang, H., Li, F., Fu, H., Sun, X., Cao, X., Son, J., Yu, S., Zhang, M., Yuan, C., Bian, C., et al.: Refuge2 challenge: Treasure for multi-domain learning in glaucoma assessment. arXiv preprint arXiv:2202.08994 (2022)
[6] Baid, U., Ghodasara, S., Mohan, S., Bilello, M., Calabrese, E., Colak, E., Farahani, K., Kalpathy-Cramer, J., Kitamura, F.C., Pati, S., et al.: The rsna-asnr-miccai brats 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv preprint arXiv:2107.02314 (2021)
[7] Pedraza, L., Vargas, C., Narváez, F., Durán, O., Muñoz, E., Romero, E.: An open access thyroid ultrasound image database. In: 10th International symposium on medical information processing and analysis. vol. 9287, pp. 188–193. SPIE (2015)