PaddlePaddle教学
文章目录
- PaddlePaddle教学
-
- 项目描述
- 数据集介绍
- 项目要求
- 数据准备
- 环境配置/安装
- PaddlePaddle 介绍
-
- Paddle中张量以及张量和numpy数组之间的转换
-
- `paddle.reshape()`
- `广播语义`
- 计算图
- CUDA 语义
- Paddle 是一个会自动计算梯度的框架
- 使用梯度
- 线性回归
-
-
- 注意数据维度
- 正确性检查
- 使用自动计算导数的GD来训练线性回归模型
- paddle.nn.Module
-
- 线性模型
- 激活函数
- 顺序容器
- 损失函数
- paddle.optimizer
- 用GD自动计算导数的线性回归和Paddle中的Modules
-
- Paddle中的神经网络基础
- 作业帮助
-
- Momentum
- 交叉熵损失
- 学习率调度器
- 卷积操作
PaddlePaddle教学
项目描述
此教程旨在介绍PaddlePaddle(一个易用、高效、灵活、可扩展的深度学习框架),根据PaddlePaddle 2.0 rc官方手册编写,介绍了PaddlePaddle中比较常用的一些API以及其基本用法。
数据集介绍
无
项目要求
- 学会使用自动微分(一个强大的实用工具)
- 使用PaddlePaddle实现深度学习中的常用功能
- 使用paddle.io.Dataset处理数据
- 了解PaddlePaddle中的自动混合精度训练
数据准备
无
环境配置/安装
无
PaddlePaddle 介绍
此教程根据 PaddlePaddle 2.0 rc官方手册编写。
此教程旨在介绍PaddlePaddle(一个易用、高效、灵活、可扩展的深度学习框架)
本教程只介绍了paddle中比较常用的一些API以及其基本用法,并不全面,如有任何问题请参考PaddlePaddle 2.0 rc官方手册,也可以百度一下
你将收获以下知识:
- 自动微分是一个强大的实用工具
- 使用PaddlePaddle实现深度学习中的常用函数
- 使用paddle.io.Dataset处理数据
- PaddlePaddle中的自动混合精度训练
import paddle
import paddle.fluid as fluid
from paddle import seed
# 使用动态图模式
paddle.disable_static()
seed(446) # 随机数种子446,方便复现本次操作
x = fluid.layers.uniform_random([10], dtype="float32", min=0.0, max=1.0) #创建正态随机分布数组x[10]
print(x)
paddle.seed(446)
x3 = fluid.layers.uniform_random(
[10], dtype="float32", min=0.0, max=1.0)
print(x3)
print(x.numpy() == x3.numpy())
Tensor(shape=[10], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.47338870, 0.43188271, 0.36742651, 0.46920347, 0.50838202, 0.65226251, 0.19124837, 0.46995333, 0.88267577, 0.35630536])
Tensor(shape=[10], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.47338870, 0.43188271, 0.36742651, 0.46920347, 0.50838202, 0.65226251, 0.19124837, 0.46995333, 0.88267577, 0.35630536])
[ True True True True True True True True True True]
Paddle中张量以及张量和numpy数组之间的转换
到目前为止,我们已经使用了不少和numpy数组相关的操作。 作为PaddlePaddle中数据处理的基本元素,张量tensor和numpy数组中的ndarray非常相似。
import paddle.fluid as fluid
import numpy as np
paddle.disable_static()
# 使用创建numpy数组相同的方式来创建Tensor
x_numpy = np.array([[2.5, 2.5], [2.5, 2.5], [2.5, 2.5]]) # 3行*2列
x_paddle = paddle.to_tensor(x_numpy)
data = fluid.layers.fill_constant(shape=[3, 2], value=2.5, dtype='float64') #填充常量
x_paddle = fluid.layers.create_tensor(dtype='float64')
# x_paddle = [2.50000000, 2.50000000, 2.50000000, 2.50000000, 2.50000000, 2.50000000]
fluid.layers.assign(data, x_paddle) # 将输入data数组拷贝至输出x_paddle
print('x_numpy, x_paddle')
print(x_numpy, x_paddle)
print()
# 根据numpy数组创建Paddle Tensor
x_numpy = np.array([[2.5, 2.5], [2.5, 2.5], [2.5, 2.5]], dtype=np.float32)
x_paddle = fluid.layers.assign(x_numpy)
print(x_paddle, x_paddle.numpy)
print()
# 使用 +-*/ 操作Paddle Tensors
y_numpy = np.array([[3,4], [5, 6], [7, 8]])
y_paddle = paddle.to_tensor([[3,4], [5, 6], [7, 8]])
print("x+y")
print(x_numpy + y_numpy)
print(x_paddle + y_paddle)
print()
# 很多numpy中函数使用方式同样适用于Paddle
print("norm")
print(np.linalg.norm(x_numpy), paddle.norm(x_paddle))
print()
# 计算指定维度上的数据均值
x_numpy = np.array([[1,2],[3,4.]])
x_paddle = paddle.to_tensor([[1,2],[3,4.]])
print(np.mean(x_numpy, axis=0), paddle.mean(x_paddle, axis=0))
x_numpy, x_paddle
[[2.5 2.5]
[2.5 2.5]
[2.5 2.5]] Tensor(shape=[3, 2], dtype=float64, place=CPUPlace, stop_gradient=True,
[[2.50000000, 2.50000000],
[2.50000000, 2.50000000],
[2.50000000, 2.50000000]])
to and from numpy and paddle
Tensor(shape=[3, 2], dtype=float32, place=CPUPlace, stop_gradient=True,
[[2.50000000, 2.50000000],
[2.50000000, 2.50000000],
[2.50000000, 2.50000000]])
x+y
[[ 5.5 6.5]
[ 7.5 8.5]
[ 9.5 10.5]]
Tensor(shape=[3, 2], dtype=float32, place=CPUPlace, stop_gradient=True,
[[5.50000000, 6.50000000],
[7.50000000, 8.50000000],
[ 9.50000000, 10.50000000]])
norm
6.1237245 Tensor(shape=[1], dtype=float32, place=CPUPlace, stop_gradient=True,
[6.12372446])
mean along the 0th dimension
[2. 3.] Tensor(shape=[2], dtype=float32, place=CPUPlace, stop_gradient=True,
[2., 3.])
paddle.reshape()
我们可以使用paddle.reshape()函数来改变Tensors的维度和排列,该函数的使用方法类似numpy.reshape()函数。
此函数还能根据指定的其他维度自动计算剩下那一个维度的值(参数中可以使用-1来替代),这在操作batch但是batch维度不明确的时候非常实用。
# "MNIST"
N, C, W, H = 10000, 3, 28, 28
# paddle.randn返回符合标准正态分布(均值为0,标准差为1的正态随机分布)的随机Tensor,形状为 shape,数据类型为 dtype。
X = paddle.randn((N, C, W, H))
print(X.shape)
print(paddle.reshape(X, shape=(N, C, 784)).shape)
# 根据第二、三个维度自动计算第一个维度的值
print(paddle.reshape(X, shape=(-1, C, 784)).shape)
[10000, 3, 28, 28]
[10000, 3, 784]
[10000, 3, 784]
广播语义
符合下面规则的两个tensor是“可广播的”:
每个tensor至少含有一个维度。
当迭代维度大小时,从最后一维开始,该维度的大小相等或者至少有一个等于1又或者其中一个tensor该维度不存在。
# Paddle operations support NumPy Broadcasting Semantics.
x=paddle.empty((5,1,4,1), dtype=np.int64)
y=paddle.empty(( 3,1,1), dtype=np.int64)
print((x+y).shape)
[5, 3, 4, 1]
计算图
Paddle中tensor的特殊之处在于它会在后台隐式的建一个计算图,计算图是一种将数学表达式计算过程用图表达出来的方法,算法会按照算术函数的计算顺序将计算图中所有变量的值有效计算出来。
比如这个表达式 e = ( a + b ) ∗ ( b + 1 ) e=(a+b)*(b+1) e=(a+b)∗(b+1) 当 a = 2 , b = 1 a=2, b=1 a=2,b=1时。 在Paddle中我们能画出评估计算图如下图所示"
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3jcooVve-1660818399879)(https://ai-studio-static-online.cdn.bcebos.com/3d9f4288031b40219090095c10b3821cedb8fcd8fa714cc5b657eadea1e7b37a)]
# we set requires_grad=True to let Paddle know to keep the graph
a = paddle.to_tensor(2.0, stop_gradient=False)
b = paddle.to_tensor(1.0, stop_gradient=False)
c = a + b
d = b + 1
e = c * d
print('c', c)
print('d', d)
print('e', e)
c Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[3.])
d Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[2.])
e Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[6.])
CUDA 语义
在Paddle中我们可以很简单的在指定的GPU或者CPU上创建tensor。
在Paddle中我们可以很简单的设置数据操作的全局运行设备。
# use cpu
cpu = paddle.set_device("cpu")
paddle.disable_static(cpu)
x = paddle.rand((10,))
print(x)
# use gpu
gpu = paddle.set_device("gpu")
paddle.disable_static(gpu)
y = x*2
print(y)
# create tensor on cpu
cpu_tensor = paddle.to_tensor(x, place=paddle.CPUPlace())
print(cpu_tensor)
# create tensor on gpu
gpu_tensor = paddle.to_tensor(x, place=paddle.CUDAPlace(0))
print(gpu_tensor)
Tensor(shape=[10], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.92685932, 0.60531497, 0.79962277, 0.33832616, 0.31140935, 0.39485791, 0.49070832, 0.57938600, 0.48189536, 0.95839733])
Tensor(shape=[10], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[1.85371864, 1.21062994, 1.59924555, 0.67665231, 0.62281871, 0.78971583, 0.98141664, 1.15877199, 0.96379071, 1.91679466])
Tensor(shape=[10], dtype=float32, place=CPUPlace, stop_gradient=True,
[0.92685932, 0.60531497, 0.79962277, 0.33832616, 0.31140935, 0.39485791, 0.49070832, 0.57938600, 0.48189536, 0.95839733])
Tensor(shape=[10], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0.92685932, 0.60531497, 0.79962277, 0.33832616, 0.31140935, 0.39485791, 0.49070832, 0.57938600, 0.48189536, 0.95839733])
Paddle 是一个会自动计算梯度的框架
我们知道Paddle无时无刻不在使用图,接下来我们展示一些Paddle自动计算梯度的使用案例。
函数 f ( x ) = ( x − 2 ) 2 f(x) = (x-2)^2 f(x)=(x−2)2.
Q: 如何计算 d d x f ( x ) \frac{d}{dx} f(x) dxdf(x) 以及如何计算 f ′ ( 1 ) f'(1) f′(1).
我们可以先计算叶子变量(y),然后调用backward()函数,一次性计算出y的所有所有梯度。
def f(x):
return (x-2)**2
def fp(x):
return 2*(x-2)
x = paddle.to_tensor([1.0], stop_gradient=False)
y = f(x)
y.backward()
print('Analytical f\'(x):', fp(x))
print('Paddle\'s f\'(x):', x.grad)
Analytical f'(x): Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[-2.])
Paddle's f'(x): [-2.]
该方法也能计算函数的梯度。
例如 w = [ w 1 , w 2 ] T w = [w_1, w_2]^T w=[w1,w2]T
函数 g ( w ) = 2 w 1 w 2 + w 2 cos ( w 1 ) g(w) = 2w_1w_2 + w_2\cos(w_1) g(w)=2w1w2+w2cos(w1)
Q: 计算 ∇ w g ( w ) \nabla_w g(w) ∇wg(w) 并验证 ∇ w g ( [ π , 1 ] ) = [ 2 , π − 1 ] T \nabla_w g([\pi,1]) = [2, \pi - 1]^T ∇wg([π,1])=[2,π−1]T
import paddle
import numpy as np
def g(w):
return 2*w[0]*w[1] + w[1]*paddle.fluid.layers.cos(w[0])
def grad_g(w):
return [2*w[1] - w[1]*paddle.fluid.layers.sin(w[0]), 2*w[0] + paddle.fluid.layers.cos(w[0])]
w = paddle.to_tensor([np.pi, 1], stop_gradient=False)
z = g(w)
z.backward()
print('Analytical grad g(w)', grad_g(w))
print('Paddle\'s grad g(w)', w.grad)
Analytical grad g(w) [Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[2.]), Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[5.28318548])]
Paddle's grad g(w) [2. 5.2831855]
使用梯度
我们得到梯度之后,就可以使用我们最喜欢的优化算法:梯度下降算法了!
函数 f f f (由上面定义并计算).
Q: 如何计算 x x x 让 f f f最小?"
线性回归
接下来,我们构造一些数据,并降低损失函数在这些数据上的计算值。
我们实现梯度下降方法来解决线性回归任务。
import paddle.fluid as fluid
paddle.disable_static()
# make a simple linear dataset with some noise
d = 2
n = 50
X = paddle.randn((n,d))
true_w = paddle.to_tensor([[-1.0], [2.0]])
y = fluid.layers.matmul(x=X, y=true_w) + paddle.randn((n,1)) * 0.1
print('X shape', X.shape)
print('y shape', y.shape)
print('w shape', true_w.shape)
X shape [50, 2]
y shape [50, 1]
w shape [2, 1]
注意数据维度
Paddle有很多处理batch数据的操作,按照约定俗成的规则,batch数据的维度是 ( N , d ) (N, d) (N,d),其中 N N N是batch的大小。
正确性检查
为了验证Paddle中梯度计算结果的正确性,我们可以调用梯度计算来计算RSS的梯度:
∇ w L R S S ( w ; X ) = ∇ w 1 n ∣ ∣ y − X w ∣ ∣ 2 2 = − 2 n X T ( y − X w ) \nabla_w \mathcal{L}_{RSS}(w; X) = \nabla_w\frac{1}{n} ||y - Xw||_2^2 = -\frac{2}{n}X^T(y-Xw) ∇wLRSS(w;X)=∇wn1∣∣y−Xw∣∣22=−n2XT(y−Xw)
Padddle梯度计算正确性验证完毕之后,接下来我们介绍如何使用梯度!
使用自动计算导数的GD来训练线性回归模型
我们接下来使用梯度来运行梯度下降算法
注意:这个例子是为了说明Paddle和我们之前所常用的一些使用方法之间的联系,在接下来的例子中,我们会看到如何使用Paddle所特有的方式来解决问题。
paddle.nn.Module
Module是Paddle处理tensor操作的一种方式。Modules是paddle.nn.Module类的子类,它的所有模块都是可调用的且能被组合成复杂函数。
paddle.nn docs
注意:Modules中大部分的功能都能通过paddle.nn.functional中的函数来访问, 如何通过paddle.nn.functional中的函数来访问,需要自己创建和管理权重tensors。
paddle.nn.functional docs.
线性模型
modules的基本组成部分是带有偏置的可进行线性变换的线性模型。线性模型的输入参数为输入数据的维度和输出数据的维度,并生成线性变换权重。
和我们手动初始化 w w w不同的是,线性模型能自动随机初始化权重。在最小化凸损失函数过程中(比如:训练神经网络),初始化非常重要且能影响模型结果。如果训练和我们预期的不一致,手动初始化权重改变默认的初始化权重是我们的解决方案之一。Paddle在paddle.nn.initializer模块中实现了一些常见的通用初始化函数。
paddle.nn.initializer docs
import paddle
import numpy as np
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear
from paddle.fluid.dygraph.base import to_variable
paddle.disable_static()
d_in = 3
d_out = 4
linear_module = Linear(d_in, d_out)
example_tensor = paddle.to_tensor([[1,2,3], [4,5,6]], dtype=np.float32)
print('example_tensor', example_tensor.shape)
# applys a linear transformation to the data
transformed = linear_module(example_tensor)
print('transormed', transformed.shape)
print('We can see that the weights exist in the background\n')
print('W:', linear_module.weight)
print('b:', linear_module.bias)
example_tensor [2, 3]
transormed [2, 4]
We can see that the weights exist in the background
W: Parameter containing:
Tensor(shape=[3, 4], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[ 0.29809543, 0.26950902, -0.15459038, -0.12214648],
[-0.50891304, -0.02956362, 0.54839021, 0.29554477],
[-0.64737576, 0.65565199, 0.74097818, -0.37470207]])
b: Parameter containing:
Tensor(shape=[4], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[0., 0., 0., 0.])
激活函数
Paddle实现了包括但不限于 ReLU, Tanh, and Sigmoid的一些激活函数。这些函数都是一些独立的modules,使用的时候都需要先实例化。
import paddle
# we instantiate an instance of the ReLU module
activation_fn = paddle.nn.ReLU()
example_tensor = paddle.to_tensor([-1.0, 1.0, 0.0])
activated = activation_fn(example_tensor)
print('example_tensor', example_tensor)
print('activated', activated)
example_tensor Tensor(shape=[3], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[-1., 1., 0.])
activated Tensor(shape=[3], dtype=float32, place=CUDAPlace(0), stop_gradient=True,
[0., 1., 0.])
顺序容器
很多时候,我们需要很多Modules组合在一起计算,paddle.nn.Sequential模块给我们组合这些modules实现了一个简单易用的接口。
import paddle
import paddle.nn as nn
paddle.disable_static()
d_in = 3
d_hidden = 4
d_out = 1
model = nn.Sequential(
paddle.nn.Linear(d_in, d_hidden),
paddle.nn.Tanh(),
paddle.nn.Linear(d_hidden, d_out),
paddle.nn.Sigmoid()
)
example_tensor = paddle.to_tensor([[1.,2,3],[4,5,6]])
transformed = model(example_tensor)
print('transformed', transformed.shape)
transformed [2, 1]
注意: 我们可以通过parameters()方法来访问nn.Module的所有的参数。
params = model.parameters()
for param in params:
print(param)
Parameter containing:
Tensor(shape=[3, 4], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[-0.15264523, -0.66133016, -0.78994864, -0.78432560],
[ 0.30688348, 0.44818300, -0.32373804, 0.68499100],
[ 0.46178973, -0.84470862, 0.04016883, 0.32043117]])
Parameter containing:
Tensor(shape=[4], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[0., 0., 0., 0.])
Parameter containing:
Tensor(shape=[4, 1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[-0.54592878],
[-0.49761561],
[0.51805198],
[0.06760501]])
Parameter containing:
Tensor(shape=[1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[0.])
损失函数
Paddle实现了包括MSELoss 和 CrossEntropyLoss在内的很多常见的损失函数。
paddle.optimizer
Paddle在paddle.optimizer模块中实现了一些基于梯度的优化函数,包括梯度下降等常见的优化方法。在最小化网络损失值的过程中,需要先获取模型参数和学习率。
优化函数不会计算梯度,我们需要调用backward()来计算梯度。我们还需要在调用backward()函数之前调用optim.clear_grad(),原因是Paddle是默认梯度累加而不是梯度更新。
paddle.optimizer docs
import paddle
paddle.disable_static()
# create a simple model
model = paddle.nn.Linear(1, 1)
# create a simple dataset
X_simple = paddle.to_tensor([[1.]])
y_simple = paddle.to_tensor([[2.]])
# create our optimizer
optim = paddle.optimizer.SGD(learning_rate=1e-2, parameters=model.parameters())
mse_loss_fn = paddle.nn.loss.MSELoss()
y_hat = model(X_simple)
print('model params before:', model.weight)
loss = mse_loss_fn(y_hat, y_simple)
loss.backward()
optim.clear_grad()
optim.step()
print('model params after:', model.weight)
model params before: Parameter containing:
Tensor(shape=[1, 1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[0.02650519]])
model params after: Parameter containing:
Tensor(shape=[1, 1], dtype=float32, place=CUDAPlace(0), stop_gradient=False,
[[0.02650519]])
正如我们所看到的这样,参数值是朝着正确的方向在更新的。
用GD自动计算导数的线性回归和Paddle中的Modules
接下里我们结合之前所学用Paddle的方式来解决线性回归问题。
import paddle
paddle.disable_static()
step_size = 0.1
linear_module = paddle.nn.Linear(d, 1)
loss_func = paddle.nn.loss.MSELoss()
optim = paddle.optimizer.SGD(learning_rate=step_size, parameters=linear_module.parameters())
print('iter,\tloss,\tw')
for i in range(20):
y_hat = linear_module(X)
loss = loss_func(y_hat, y)
loss.backward()
optim.minimize(loss)
linear_module.clear_gradients()
optim.step()
print('{},\t{},\t{}'.format(i, loss.numpy(), linear_module.weight.reshape((1,2)).numpy()))
print('\ntrue w\t\t', true_w.reshape((1, 2)).numpy())
print('estimated w\t', linear_module.weight.reshape((1, 2)).numpy())
iter, loss, w
0, [9.162705], [[-0.49290323 -0.8838542 ]]
1, [6.519801], [[-0.6316604 -0.45825648]]
2, [4.6673064], [[-0.73476887 -0.09626068]]
3, [3.3589], [[-0.8109495 0.21190366]]
4, [2.4285016], [[-0.86684537 0.47445077]]
5, [1.7629617], [[-0.9075095 0.69829774]]
6, [1.2844253], [[-0.93677884 0.8892783 ]]
7, [0.938824], [[-0.95756143 1.0523196 ]]
8, [0.688288], [[-0.9720562 1.1915888]]
9, [0.50608855], [[-0.9819219 1.3106143]]
10, [0.37323117], [[-0.9884058 1.412388 ]]
11, [0.27613637], [[-0.9924428 1.4994487]]
12, [0.20504509], [[-0.9947305 1.5739536]]
13, [0.15291256], [[-0.99578714 1.6377373 ]]
14, [0.1146336], [[-0.99599546 1.692361 ]]
15, [0.08649698], [[-0.99563605 1.7391548 ]]
16, [0.06579723], [[-0.9949129 1.7792525]]
17, [0.05055765], [[-0.99397284 1.8136212 ]]
18, [0.03933128], [[-0.9929198 1.8430864]]
19, [0.03105721], [[-0.9918263 1.8683532]]
true w [[-1. 2.]]
estimated w [[-0.9918263 1.8683532]]
Paddle中的神经网络基础
我们使用一个简单的神经网络来拟合数据。
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
d = 1
n = 200
X = paddle.rand(shape=[n,d])
y = 4 * paddle.sin(np.pi * X) * paddle.cos(6*np.pi*X**2)
plt.scatter(X.numpy(), y.numpy())
plt.title('plot of $f(x)$')
plt.xlabel('$x$')
plt.ylabel('$y$')
plt.show()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
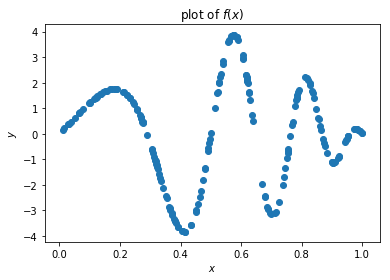
我们使用了一个简单的含有两个隐藏层和Tanh激活函数的神经网络。我们可以通过调节这个神经网络的一些超参数来说明超参数是如何改变模型结果的。
import paddle
paddle.disable_static()
# feel free to play with these parameters
step_size = 0.05
n_epochs = 6000
n_hidden_1 = 32
n_hidden_2 = 32
d_out = 1
neural_network = paddle.nn.Sequential(
paddle.nn.Linear(d, n_hidden_1),
paddle.nn.Tanh(),
paddle.nn.Linear(n_hidden_1, n_hidden_2),
paddle.nn.Tanh(),
paddle.nn.Linear(n_hidden_2, d_out)
)
loss_func = paddle.nn.loss.MSELoss()
optim = paddle.optimizer.SGD(learning_rate=step_size, parameters=neural_network.parameters())
print('iter,\tloss')
for i in range(n_epochs):
y_hat = neural_network(X)
loss = loss_func(y_hat, y)
loss.backward()
optim.minimize(loss)
neural_network.clear_gradients()
optim.step()
if i % (n_epochs // 10) == 0:
print('{},\t{}'.format(i, loss.numpy()))
iter, loss
0, [3.9513247]
600, [3.9373624]
1200, [3.916591]
1800, [3.250338]
2400, [1.502908]
3000, [0.85847753]
3600, [0.3803963]
4200, [0.35446128]
4800, [0.2153358]
5400, [0.13888188]
X_grid = paddle.to_tensor(np.linspace(0,1,50), dtype=np.float32).reshape((-1, d))
y_hat = neural_network(X_grid)
plt.scatter(X.numpy(), y.numpy())
plt.plot(X_grid.detach().numpy(), y_hat.detach().numpy(), 'r')
plt.title('plot of $f(x)$ and $\hat{f}(x)$')
plt.xlabel('$x$')
plt.ylabel('$y$')
plt.show()
<>:5: DeprecationWarning: invalid escape sequence \h
<>:5: DeprecationWarning: invalid escape sequence \h
<>:5: DeprecationWarning: invalid escape sequence \h
:5: DeprecationWarning: invalid escape sequence \h
plt.title('plot of $f(x)$ and $\hat{f}(x)$')
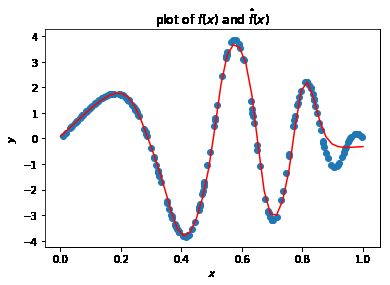
作业帮助
Momentum
除了随机梯度下降还有其他的一些优化算法:比如修改自SGD的momentum。这里我们不在详述,需要了解更多的可以点击此处学习。
在下面给出的代码中我们只修改了训练步数并且在优化函数中增加了momentum参数。注意观察momentum参数是如何在较少的迭代次数中减少训练损失的。
# feel free to play with these parameters
step_size = 0.05
momentum = 0.9
n_epochs = 1500
n_hidden_1 = 32
n_hidden_2 = 32
d_out = 1
neural_network = paddle.nn.Sequential(
paddle.nn.Linear(d, n_hidden_1),
paddle.nn.Tanh(),
paddle.nn.Linear(n_hidden_1, n_hidden_2),
paddle.nn.Tanh(),
paddle.nn.Linear(n_hidden_2, d_out)
)
loss_func = paddle.nn.MSELoss()
optim = paddle.optimizer.Momentum(learning_rate=step_size, parameters=neural_network.parameters(), momentum=momentum)
print('iter,\tloss')
for i in range(n_epochs):
y_hat = neural_network(X)
loss = loss_func(y_hat, y)
optim.clear_grad()
loss.backward()
optim.step()
if i % (n_epochs // 10) == 0:
print('{},\t{}'.format(i, loss.numpy()))
iter, loss
0, [3.956203]
150, [3.913073]
300, [1.176127]
450, [0.39796242]
600, [0.05624514]
750, [0.0124592]
900, [0.00491968]
1050, [0.00367964]
1200, [0.00305877]
1350, [0.0026587]
X_grid = paddle.to_tensor(np.linspace(0,1,50), dtype=np.float32).reshape((-1, d))
y_hat = neural_network(X_grid)
plt.scatter(X.numpy(), y.numpy())
plt.plot(X_grid.detach().numpy(), y_hat.detach().numpy(), 'r')
plt.title('plot of $f(x)$ and $\hat{f}(x)$')
plt.xlabel('$x$')
plt.ylabel('$y$')
plt.show()
<>:5: DeprecationWarning: invalid escape sequence \h
<>:5: DeprecationWarning: invalid escape sequence \h
<>:5: DeprecationWarning: invalid escape sequence \h
:5: DeprecationWarning: invalid escape sequence \h
plt.title('plot of $f(x)$ and $\hat{f}(x)$')
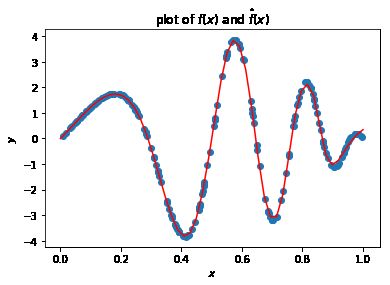
交叉熵损失
到目前为止,我们在回归任务中使用了MSELoss模块。在作业中,我们需要训练一个使用交叉熵损失的分类任务。
Paddle在CrossEntropyLoss模块中实现了一个交叉熵损失版本,它的使用方法相比MSE稍有不同,因此我们在这里给出了它的一些使用注释。
-
input (Tensor): - 输入 Tensor ,数据类型为float32或float64。其形状为 [N,C] , 其中 C 为类别数。对于多维度的情形下,它的形状为 [N,C,d1,d2,…,dk] ,k >= 1。
-
label (Tensor): - 输入input对应的标签值,数据类型为int64。其形状为 [N] ,每个元素符合条件:0 <= label[i] <= C-1。对于多维度的情形下,它的形状为 [N,d1,d2,…,dk] ,k >= 1。
-
output (Tensor): - 计算 CrossEntropyLoss 交叉熵后的损失值。
在三个预测结果中试着输出损失函数的值。真实的标签值为 y = [ 1 , 1 , 0 ] y=[1,1,0] y=[1,1,0]。和前两个例子相对应的预测值是正确的,因为它们在正确的便签所对应的列上有更高的分数值。其中第二个例子中的预测结果具有更高的置信度和更小的损失值。最后的两个例子是分别具有更低和更高置信度的不正确的预测。
学习率调度器
在训练过程中我们通常并不想使用混合学习率。Paddle提供了学习率调度器来随着训练时间的推移改变学习率。比较常用的策略是每训练一个epoch在学习率上乘以一个常数(比如0.9)或者当训练损失趋于平缓时,学习率减半。
想要获取更多的使用示例请参考 学习旅调度器 文档。
卷积操作
在处理图片时,我们经常需要使用卷积操作来提取特征。Paddle在paddle.nn.Conv2D模块中实现了这些卷积操作。该模块要求需要参数必须具有指定的维度(输入通道数目, 输出通道数目, 滤波器尺寸)。其中输入通道数目为图片的通道数目,输出通道数目为滤波器的个数,滤波器尺寸为滤波器的大小。
We can modify the convolution to have different properties with the parameters:
我们可以通过修改卷积操作的参数让卷积操作拥有不同的属性:
- 步长
- 填充
- 空洞大小
这些参数的修改会改变输出特征图的维度,因此使用的需要注意。
想了解更多信息,请参考paddle.nn.Conv2D 文档