【算法】缓存淘汰算法
目录
- 1.概述
- 2.代码实现
-
- 2.1.FIFO
- 2.2.LRU
- 2.3.LFU
- 2.4.Clock
- 2.5.Random
- 3.应用
1.概述
缓存淘汰策略是指在缓存容量有限的情况下,当缓存空间不足时决定哪些缓存项应当被移除的策略。缓存淘汰策略的目标是尽可能地保持缓存命中率高,同时合理地利用有限的缓存空间。
需要注意的是,下面的代码实现只是对缓存淘汰算法的基本实现,在实际情况中,可以需要考虑更多的因素!
2.代码实现
2.1.FIFO
(1)FIFO (First-In-First-Out) 是一种基本的内存淘汰策略。其思路是按照元素的进入顺序来选择要淘汰的元素。具体来说,当有新的元素要加入到固定容量的缓存中时,如果缓存已满,就需要选择一个元素进行淘汰,以腾出空间存储新的元素。在 FIFO 策略中,选择被缓存时间最长的元素进行淘汰。
(2)FIFO 策略维护一个队列,在每次新元素加入缓存时,将新元素添加到队列的末尾。当需要淘汰元素时,选择队列的头部元素作为淘汰对象,即最早进入缓存的元素。通过这种方式,始终保持最早进入缓存的元素在队列头部,最新进入缓存的元素在队列末尾。
(3)使用 FIFO 策略的好处是它的实现简单且执行效率高。然而,它没有考虑元素的访问频率或重要性等因素,只根据进入缓存的顺序来进行淘汰,可能会导致缓存中的数据不够优化。因此,在某些应用场景下,FIFO 策略可能不是最优选择,需要根据实际需求选择更复杂的内存淘汰策略。其具体代码实现如下:
class FIFOCache<K, V> {
private int capacity;
private Deque<K> queue;
private Map<K, V> cache;
//进行初始化操作
public FIFOCache(int capacity) {
this.capacity = capacity;
this.queue = new ArrayDeque<>(capacity);
this.cache = new HashMap<>(capacity);
}
//接收一个键 key 并返回相应的值,如果键不存在,则返回 null
public V get(K key) {
return cache.getOrDefault(key, null);
}
//接收一个键 key 和一个值 value,并将它们存储在缓存中
public void put(K key, V value) {
if (!cache.containsKey(key)) {
//如果缓存已满,将使用队列的 poll 方法移除最早加入的键
if (queue.size() == capacity) {
K oldestKey = queue.poll();
cache.remove(oldestKey);
}
//然后将新的键加入队列的尾部
queue.offer(key);
}
//将新的键值对加入缓存
cache.put(key, value);
}
public V remove(K key) {
//从队列中移除指定键
queue.remove(key);
// 从缓存中移除指定键并返回对应的值
return cache.remove(key);
}
public void clear() {
//清空队列
queue.clear();
//清空缓存
cache.clear();
}
public int size() {
return cache.size();
}
}
2.2.LRU
参考 146.LRU 缓存这篇文章。
2.3.LFU
参考 460.LFU 缓存这篇文章。
2.4.Clock
(1)Clock 缓存淘汰算法是一种基于近似“最近未使用” (Not Recently Used) 策略的淘汰算法。该算法通过维护一个环形指针数组 (Clock),来判断缓存项是否被使用,从而进行淘汰决策。Clock 缓存淘汰算法的思路如下:
- 对于每个缓存项,维护一个额外的访问位来标记缓存项是否被访问过。
- 初始状态下,将所有缓存项的访问位都设置为 0。
- 创建一个环形指针数组,数组中的每个槽位对应一个缓存项,并按照某种顺序排列。
- 当需要淘汰一个缓存项时,根据指针指向的槽位判断:
- 如果该槽位的访问位为 0,表示该缓存项最近未被使用,可以选择淘汰。
- 如果该槽位的访问位为 1,表示该缓存项最近被使用过,将访问位置为 0,并将指针向后移动一位。
- 重复第 4 步,直到找到一个访问位为 0 的槽位,将该缓存项置换出来,让出空间给新的缓存项。
- 如果需要访问某个缓存项时,将其对应的访问位置为 1,表示该缓存项已被使用。
(2)Clock 缓存淘汰算法相对于经典的最近未使用 (LRU) 算法具有更低的时间和空间复杂度。它通过近似地追踪缓存项的访问状态来进行淘汰决策,适用于中小规模的缓存系统。
(3)然而,需要注意的是,Clock 算法可能出现缓存项的“反复使用”情况,即缓存项被不断地替换出去又被重新引入,这可能会影响缓存的命中率。因此,在实际应用中,需要根据具体场景和需求,综合考虑各个因素,选择合适的缓存淘汰策略。其具体代码实现如下:
class ClockCache<K, V> {
//循环链表节点
static class CircleListNode<K, V> {
K key;
V value;
boolean accessFlag;
CircleListNode<K, V> pre;
CircleListNode<K, V> next;
public CircleListNode() {
}
public CircleListNode(K key, V value) {
this.key = key;
this.value = value;
}
}
private int capacity;
//头节点
private CircleListNode<K, V> dummyHead;
private Map<K, CircleListNode<K, V>> cache;
public ClockCache(int capacity) {
this.capacity = capacity;
this.dummyHead = new CircleListNode<>();
this.dummyHead.next = this.dummyHead;
this.dummyHead.pre = this.dummyHead;
this.cache = new HashMap<>();
}
public V get(K key) {
if (cache.containsKey(key)) {
CircleListNode<K, V> node = cache.get(key);
//将访问位设置为 true
node.accessFlag = true;
return node.value;
} else {
return null;
}
}
public void put(K key, V value) {
if (cache.containsKey(key)) {
CircleListNode<K, V> node = cache.get(key);
//将访问位设置为 true
node.accessFlag = true;
node.value = value;
} else {
if (cache.size() >= capacity) {
//从最老的元素开始,此处直接从 head.next 开始,后续可以考虑优化记录这个 key
CircleListNode<K, V> node = this.dummyHead;
boolean removeFlag = false;
while (node.next != this.dummyHead) {
//下一个元素
node = node.next;
if (!node.accessFlag) {
//未访问,直接淘汰
removeNode(node);
System.out.println(node.key);
removeFlag = true;
break;
} else {
//设置当前 accessFlag 为 false,继续遍历下一个
node.accessFlag = false;
}
}
if (!removeFlag) {
//如果循环一遍都没找到,直接取第一个元素即可
CircleListNode<K, V> firstNode = this.dummyHead.next;
System.out.println(firstNode.key);
removeNode(firstNode);
}
}
CircleListNode<K, V> newNode = new CircleListNode<>(key, value);
newNode.accessFlag = true;
CircleListNode<K, V> tail = dummyHead.pre;
tail.next = newNode;
newNode.pre = tail;
newNode.next = dummyHead;
dummyHead.pre = newNode;
cache.put(key, newNode);
}
}
public void remove(K key) {
CircleListNode<K, V> node = cache.get(key);
if (node != null) {
cache.remove(key);
removeNode(node);
}
}
public void clear() {
cache.clear();
}
public int size() {
return cache.size();
}
private void removeNode(CircleListNode<K, V> node) {
CircleListNode<K, V> pre = node.pre;
CircleListNode<K, V> next = node.next;
pre.next = next;
next.pre = pre;
cache.remove(node.key);
}
}
2.5.Random
(1)Random(随机)内存淘汰算法的思想是基于随机选择的策略来进行缓存淘汰。该算法不依赖于缓存项的访问频率或时间等信息,而是通过随机选择一个缓存项进行淘汰,没有明确的优先级或规则。Random 内存淘汰算法的思想如下:
- 当缓存空间不足时,需要淘汰一个缓存项。
- 使用随机数生成器(如 Random 类)来生成一个随机索引,范围为缓存的容量。
- 根据生成的随机索引,随机选择一个缓存项进行淘汰。
- 被选择的缓存项被移除,让出空间给新的缓存项。
(2)随机选择的特点使得每个缓存项被淘汰的概率相等,没有明确的优先级,所有缓存项都有被淘汰的可能性。这种随机性的特点适用于一些无规律或无明确访问模式的缓存使用场景。然而,随机内存淘汰算法可能导致缓存命中率下降,因为被频繁访问的缓存项有可能被随机选中被淘汰,从而增加缓存不命中的概率。
因此,在选择淘汰算法时,需要根据具体应用场景和缓存使用模式来权衡各种算法的优劣,并选择适合的淘汰策略以达到最优的性能。
(3)其具体代码实现如下:
class RandomCache<K, V> {
private int capacity;
private List<K> keys;
private Map<K, V> cache;
private Random random;
public RandomCache(int capacity) {
this.capacity = capacity;
this.keys = new ArrayList<>(capacity);
this.cache = new HashMap<>(capacity);
this.random = new Random();
}
//接收一个键 key 并返回相应的值,如果键不存在,则返回 null
public V get(K key) {
return cache.getOrDefault(key, null);
}
public void put(K key, V value) {
if (!cache.containsKey(key)) {
//如果缓存已满,将使用 Random 对象的 nextInt 方法随机选择一个键索引并从列表中移除键
if (keys.size() == capacity) {
int index = random.nextInt(capacity);
K randomKey = keys.remove(index);
cache.remove(randomKey);
}
keys.add(key);
}
cache.put(key, value);
}
public V remove(K key) {
if (cache.containsKey(key)) {
//从列表中移除指定键
keys.remove(key);
//从缓存中移除指定键并返回对应的值
return cache.remove(key);
}
return null;
}
public void clear() {
keys.clear();
cache.clear();
}
public int size() {
return cache.size();
}
}
3.应用
Redis 的缓存淘汰策略如下:
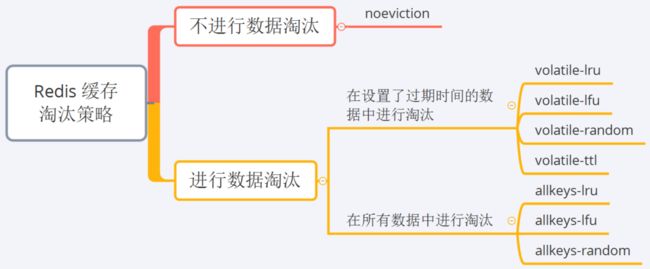
有关上面淘汰策略的一些具体说明如下:
noevction是 Redis 的默认配置。当缓存被写满时,再有写请求进来,Redis 不再提供服务,直接返回错误。LRU和LFU算法是常见的淘汰算法,其具体细节可以参考 146.LRU 缓存、460.LFU 缓存这两篇文章。random指随机删除,相关的算法实现可以参考 380. O(1) 时间插入、删除和获取随机元素这篇文章。volatile-ttl策略:针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的数据越先被淘汰,即 ttl 越小的数据越优先被淘汰,这里的 ttl 指Time to Live,即生存时间。
要想设置 Redis 的缓存淘汰策略,可以在其配置文件 redis.conf 中进行 maxmemory-policy 具体淘汰策略 的设置,例如设置淘汰策略为 volatile-lru:
maxmemory-policy volatile-lru