机器学习实战之K近邻方法心得体会
暑假的时候在学习机器学习,买的第一本书是大名鼎鼎的的周志华老师的西瓜书,但由于是水平有限,所以看到了一半还是云里雾里的。于是在师兄的推荐下,入手了《机器学习实战》这本书,确实讲的很通俗易懂,而且每一章节都有相应的实战小项目练练手。暑假就把它给过了一遍,之后就看神经学习这方面的书籍去了,最近准备好好把暑假学习的知识好好整理一下,所以打算再好好过一遍这本书,并且把自己对于不同算法的认识也一并记录下来,保证原创,不糊弄各位读者。后面我会尽量保证一个星期2+次更新(由于本学期课程确实是很多)希望与大家共同学习,当然了水平有限,其中写的错误的还请各位不吝赐教!
1.1 K近邻算法简介
K-近邻算法采用测量不同的特征值之间的距离方法进行分类。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
- 优点:精度高、对异常数据不敏感、无数据输入假定。
- 缺点:计算复杂度高、空间复杂度高。
- 适用数据范围:数值型和标称型。
1.2 k近邻算法原理
存在一个样本数据集合(训练样本集),并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似的数据(最近邻)的分类标签。
一般来说我们只选择样本数据集中前k个最相似的数据。通常k是不大于20的整数。最后选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
1.3 核心算法比较
上面的一大串废话讲完了,这一part就是重点了。我将会对书上所讲的算法进行改善,使之能一次处理更多的数据,提高效率。先上书上的算法源码吧!(大家别走开哈)
# k-近邻算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]大家其实一看便知算法原理:求解不同向量之间的欧氏距离值并且按照从小到大的顺序保存在数组里面,然后选取与当前点距离最小的K个点,确定前K个点所在类别的出现频率,最后返回前k个点出现频率最高的类别作为当前点的预测分类。该方法虽然简单易懂,但是效率不高。如果是需要处理的数据很大,每次都是用一个点去与剩下所有的点计算相应距离,那么就太费时间了,这显然也不是我们想要的结果。所以我想到了sklearn第三方包里的NearestNeighbors方法,该方法就很直接粗暴了,大家不须了解其中原理,代码非常简短,而且一次可以处理大批量数据,很高效。下面就是其核心代码
nns = NearestNeighbors(n_neighbors=k).fit(dataSet).kneighbors(inX, return_distance=False)这行代码求的是输入的inX数组里相应数据对应的dataSet数据集里与之最近的k个点的相应位置集合
下面是完整的改进函数
# k近邻算法
def KNNclassify(inX, dataSet, labels, k):
nns = NearestNeighbors(n_neighbors=k).fit(dataSet).kneighbors(inX, return_distance=False)
max_labels = []
for i in range(len(nns)):
count_label = Counter(labels[nns[i]])
max_label = max(count_label.keys())
max_labels.append(max_label)
return array(max_labels)可能大家看到这还不觉得它有多方便,也就省了几行代码,我下面将会贴出书上第一个完整例子,以及我安照改进的方法所写的代码,大家可以看到尤其是在最后的测试函数datingClassTest()中会有很大改进
1.4 使用K近邻方法改进约会网站的配对效果
书中源代码(这儿我就不多做解释了,大家看看源码知道是什么意思就好)
from os import listdir
from numpy import *
import operator
# k-近邻算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 将文本记录转换为Numpy的解析程序
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
else:
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat, classLabelVector
# 归一化特征值
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m, 1))
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
# 分类器针对约会网站的测试代码
def datingClassTest():
hoRatio = 0.10
datingDataMat, datingLabels = file2matrix('dataSet/datingTestSet.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("the total error rate is: %f" % (errorCount / float(numTestVecs)))大家可以很清楚的看到在datingClassTest()中作者是用for循环将数据一条一条的输入进去进行计算,效率太低了。大家可以看看我改进的代码
from collections import Counter
from sklearn.neighbors import NearestNeighbors
from numpy import *
# 读取文本记录
def filematrix(fileName):
dataArray = []
labelArray = []
with open(fileName, 'r') as f:
for line in f:
line = line.strip().split('\t')
dataArray.append(line[:-1])
labelArray.append(int(line[-1]))
return array(dataArray), array(labelArray)
# 归一化特征值
def autoNorm(dataArray):
minVals = dataArray.min(axis=0)
maxVals = dataArray.max(axis=0)
meanVals = (minVals + maxVals) / 2
NormData = dataArray/meanVals
return NormData
# k近邻算法
def KNNclassify(inX, dataSet, labels, k):
nns = NearestNeighbors(n_neighbors=k).fit(dataSet).kneighbors(inX, return_distance=False)
max_labels = []
for i in range(len(nns)):
count_label = Counter(labels[nns[i]])
max_label = max(count_label.keys())
max_labels.append(max_label)
return array(max_labels)
# KNN分类器测试
def datingClassTest():
hoRatio = 0.1
dataArray, labelArray = filematrix('dataSet/datingTestSet2.txt')
print("labelArray:", labelArray)
TestDataNum = int(len(dataArray) * hoRatio)
autoArray = autoNorm(dataArray.astype(float))
results = KNNclassify(autoArray[:TestDataNum, :], autoArray[TestDataNum:, :], labelArray[TestDataNum:], 3)
# errorCount = 0.0
# for i in range(TestDataNum):
# result = KNNclassify([autoArray[i]], autoArray[TestDataNum:,:], labelArray[TestDataNum:], 3)
# print("result:", result)
# print("the classifier came back with: %d, the real answer is: %d" %(result[0].astype(int), labelArray[i]))
# if result[0] != labelArray[i]:
# errorCount += 1
errorCount = sum(results != labelArray[:TestDataNum])
errorRate = errorCount/TestDataNum
print("the total error rate is: ", errorRate)
if __name__ == '__main__':
# group, labels = createDataSet()
# sorted_label = KNNclassify([[0, 0]], group, labels, 3)
# print(sorted_label)
datingClassTest()
基本上是做了很大程度的改进。当然了还可以通过构建kd近邻树来提高搜索效率,这个我还是在李航老师的《统计学习方法》上看到的,李航老师没有给出源码,我在网上找了相关资料把源码补齐了。确实效率也会提高不少。
2.1 kd树的构建
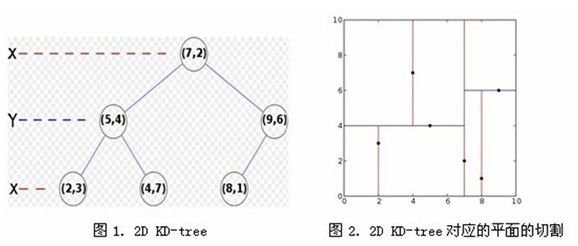
对于k近邻算法,因为需要寻找与样本距离最近的k个点,因此一种简单直接的方法就是计算输入实例与所有样本间的距离,当训练集很大时,其时间复杂度O(n)会很大,因此,为了提高k近邻搜索的效率,可以考虑使用kd树的方法。kd树是一个二叉树,表示对k维空间(这里的k与上文提到的k近邻法中的k意义不同)的划分。构建kd树的过程相当于不断用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个节点对应于一个k维超矩形区域。以下是一颗kd树构建的过程。
- 输入k维空间数据集T={x1,x2,...,xn}T={x1,x2,...,xn},其中xi=(x(1)i,x(2)i,...,x(k)i)T,i=1,2,...,nxi=(xi(1),xi(2),...,xi(k))T,i=1,2,...,n
- 开始:构造根节点。选择T中x(1)x(1)(也有文献每次使用xixi中方差最大的维度i作为切分平面)坐标的中位数作为且分点,将根节点对应的超矩形区域切分为两个子区域,切分面为垂直于x(1)x(1)轴的平面。将落在切分面上的点作为根节点,左子节点为对应坐标x(1)x(1)小于切分点的区域,右子节点为对应坐标x(1)x(1)大于切分点的区域。
- 选择l=j mod k + 1,以x(l)x(l)作为切分轴重复(2)的过程继续切分子区域。其中j为当前的树深度,每生成一层新的节点j+1
- 直到子区域内没有实例存在时停止。
这是一个由原始数据集生成kd树的一个简单例子(位于页面中部的右侧),可以帮助你更好的理解kd树的生成过程。
2.2 kd树的搜索
给定一个目标点,搜索其最近邻,首先找到包含目标点的叶节点,然后从该叶节点出发,依次退回到其父节点,不断查找是否存在比当前最近点更近的点,直到退回到根节点时终止,获得目标点的最近邻点。如果按照流程可描述如下:
1. 从根节点出发,若目标点x当前维的坐标小于切分点的坐标,则移动到左子节点,反之则移动到右子节点,直到移动到最后一层叶节点。
2. 以此叶结点为“当前最近点”
3. 递归的向上回退,在每个节点进行如下的操作:
a.如果该节点保存的实例点距离比当前最近点更小,则该点作为新的“当前最近点”
b.检查“当前最近点”的父节点的另一子节点对应的区域是否存在更近的点,如果存在,则移动到该点,接着,递归地进行最近邻搜索。如果不存在,则继续向上回退
4. 当回到根节点时,搜索结束,获得最近邻点
以上分析的是k=1是的情况,当k>1时,在搜索时“当前最近点”中保存的点个数<=k的即可。
相比于线性扫描,kd树搜索的平均计算复杂度为O(logN).但是当样本空间维数接近样本数时,它的效率会迅速降低,并接近线性扫描的速度。因此kd树搜索适合用在训练实例数远大于样本空间维数的情况。
2.3 图示说明
假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内,如图2:
说白了就是数据结构里的二分树结构,不断地在数据集里找的中点然后一分为二,直至该中点就是其本身为止。这样的话最后在搜索的时候就能充分发挥树结构的优势了,即只需要最多考虑一半的数据,比如目标点位于树的根节点左侧,那么树的根节点的右侧就不需要考虑了,运算量自然是大大的减少了,不得不佩服李航老师的聪明才智啊1
2.4 具体代码
说了这么多(虽然很多概念都是借鉴网上的)直接上代码,大家一看便知了
import numpy as np
# 树的节点类
class Node:
def __init__(self, data, lchild=None, rchild=None):
self.data = data
self.lchild = lchild
self.rchild = rchild
# kd树
class KdTree:
def __init__(self):
self.nearestValue = 0 # 保存最近的值
self.nearestPoint = None # 保存最近的点
self.kdTree = None
def create(self, dataSet, depth): # 创建kd树,返回根结点
if len(dataSet) > 0:
m, n = np.shape(dataSet) # 求出样本行,列
midIndex = int(m / 2) # 中间数的索引位置
axis = depth % n # 判断以哪个轴划分数据
sortedDataSet = sorted(dataSet, key=lambda x: x[axis])
node = Node(sortedDataSet[midIndex]) # 将节点数据域设置为中位数,具体参考下书本
# print sortedDataSet[midIndex]
leftDataSet = sortedDataSet[: midIndex] # 将中位数的左边创建2改副本
rightDataSet = sortedDataSet[midIndex + 1:]
print(leftDataSet)
print(rightDataSet)
node.lchild = self.create(leftDataSet, depth + 1) # 将中位数左边样本传入来递归创建树
node.rchild = self.create(rightDataSet, depth + 1)
return node
else:
return None
def preOrder(self, node): # 前序遍历
if node is not None:
print("tttt->%s" % node.data)
self.preOrder(node.lchild)
self.preOrder(node.rchild)
def search(self, node, x, depth=0):
if node is not None: # 递归终止条件
n = len(x) # 特征数
axis = depth % n # 计算轴
if x[axis] < node.data[axis]: # 如果数据小于结点,则往左结点找
self.search(node.lchild, x, depth + 1)
else:
self.search(node.rchild, x, depth + 1)
# 以下是递归完毕后,往父结点方向回朔
distNodeAndX = self.dist(x, node.data) # 目标和节点的距离判断
if self.nearestPoint is None: # 确定当前点,更新最近的点和最近的值
self.nearestPoint = node.data
self.nearestValue = distNodeAndX
elif self.nearestValue > distNodeAndX:
self.nearestPoint = node.data
self.nearestValue = distNodeAndX
print(node.data, depth, self.nearestValue, node.data[axis], x[axis])
if abs(x[axis] - node.data[axis]) <= self.nearestValue: # 确定是否需要去子节点的区域去找(圆的判断)
if x[axis] < node.data[axis]:
self.search(node.rchild, x, depth + 1)
else:
self.search(node.lchild, x, depth + 1)
return self.nearestPoint
def dist(self, x1, x2): # 欧式距离的计算
return ((np.array(x1) - np.array(x2)) ** 2).sum() ** 0.5
if __name__ == '__main__':
dataSet = [[2, 3],
[5, 4],
[9, 6],
[4, 7],
[8, 1],
[7, 2]]
x = [5, 3]
kdtree = KdTree()
tree = kdtree.create(dataSet, 0)
kdtree.preOrder(tree)
print(kdtree.search(tree, x))代码都是亲测跑过的,复制粘贴应该是没问题的。到了这儿k近邻相关方法算是讲的差不多了,目前这个阶段所能用到的各种方法都用了,如有疏漏,也望大家指出