机器学习 之分类

分类
分类旨在将项目分为不同类别。 最常见的分类类型是二元分类,其中有两类,通常分别为正数和负数。 如果有两个以上的类别,则称为多类分类。 spark.mllib支持两种线性分类方法:线性支持向量机(SVM)和逻辑回归。 线性SVM仅支持二进制分类,而逻辑回归支持二进制和多类分类问题。 对于这两种方法,spark.mllib支持L1和L2正则化变体。 训练数据集由MLlib中LabeledPoint的RDD表示,其中标签是从零开始的类索引:0,1,2,....
一、基本思想
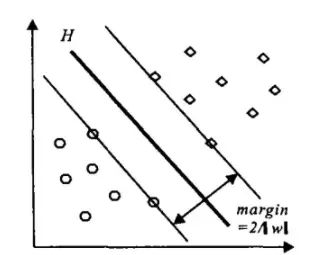
统计学习理论是在传统统计学基础上发展起来的一种机器学习方法 。SVM 的基本思想可由图 1说明 ,在二维两类线性可分情况下,有很多可能的线性分类器可以把这组数据分割开,但是只有一个使两类的分类间隔 margin最大,即图中的 H,这个线性分类器就是最优分类超平面,与其它分类器相比 ,具有更好的泛化性 。
二、计算公式
假设超平面可描述为:
![]()
线性SVM是大规模分类任务的标准方法。 其学习策略是使数据间的间隔最大化,最终可转化为一个凸二次规划问题的求解。
分类器的损失函数(hinge loss铰链损失):
L(w;x,y):=max{0,1−ywTx}.
默认情况下,线性SVM使用L2正则化进行训练。 我们还支持替代L1正则化。 在这种情况下,问题变成线性程序。线性SVM算法输出SVM模型。 给定一个新的数据点,用x表示,该模型根据wTx的值进行预测。 默认情况下,如果wTx≥0则结果为正,否则为负。
三、代码实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.mllib.classification.SVMModel;
import org.apache.spark.mllib.classification.SVMWithSGD;
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics;
import org.apache.spark.mllib.linalg.Vectors;
import org.apache.spark.mllib.regression.LabeledPoint;
3.1、读取数据:
SparkConf conf = new SparkConf().setAppName("SVM").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> source = sc.textFile("data/mllib/iris.data");
用LabeledPoint来存储标签列和特征列。 LabeledPoint在监督学习中常用来存储标签和特征,其中要求标签的类型是double,特征的类型是Vector
JavaRDD<LabeledPoint> data = source.map(line->{
String[] parts = line.split(",");
double label = 0.0;
if(parts[4].equals("Iris-setosa")) {
label = 0.0;
}else if(parts[4].equals("Iris-versicolor")) {
label = 1.0;
}else {
label = 2.0;
}
return new LabeledPoint(label,Vectors.dense(Double.parseDouble(parts[0]),
Double.parseDouble(parts[1]),
Double.parseDouble(parts[2]),
Double.parseDouble(parts[3])));
});
3.2、 构建模型
因为SVM只支持2分类,所以我们要进行一下数据抽取,这里我们通过filter过滤掉第2类的数据,只选取第0类和第1类的数据。然后,我们把数据集划分成两部分,其中训练集占60%,测试集占40%
JavaRDD<LabeledPoint>[] filters = data.filter(line->{
return line.label()!=2;
}).randomSplit(new double[]{0.6,0.4},11L);
JavaRDD<LabeledPoint> training = filters[0].cache();
JavaRDD<LabeledPoint> test = filters[1];
接下来,通过训练集构建模型SVMWithSGD。这里的SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)。设置迭代次数为1000,除此之外还有stepSize(迭代步伐大小),regParam(regularization正则化控制参数),miniBatchFraction(每次迭代参与计算的样本比例),initialWeights(weight向量初始值)等参数可以进行设置。
//构建训练集 SVMWithSGD
// SGD即著名的随机梯度下降算法(Stochastic Gradient Descent)
// 设置迭代次数为1000,
// 除此之外还有stepSize(迭代步伐大小),
// regParam(regularization正则化控制参数),
// miniBatchFraction(每次迭代参与计算的样本比例),
//initialWeights(weight向量初始值)等参数可以进行设置*/
SVMModel model = SVMWithSGD.train(training.rdd(), 1000);
3.3、 模型评估
//清除默认阈值,这样会输出原始的预测评分,即带有确信度的结果
model.clearThreshold();
JavaRDD<Tuple2<Object,Object>> scoreAndLabels = test.map(point->
new Tuple2<>(model.predict(point.features()),point.label()));
scoreAndLabels.foreach(x->{
System.out.println(x);
});
//输出结果:
(-2.627551665051128,0.0)(-2.145161194882099,0.0)
(-2.3068829871403618,0.0)(-3.0554378212130096,0.0)
(-2.3698036980710446,0.0)(-2.335545287277434,0.0)
(-2.6962358412306786,0.0)(-2.8222115665081975,0.0)
(-3.5549967121975508,0.0)(-1.963540537080021,0.0)
(-2.8307953180240637,0.0)(-3.5132621172293095,0.0)
(-3.8139420880575643,0.0)(-2.6303719513181254,0.0)
(-1.4913566958139257,0.0)(-2.5373343352394144,0.0)
(-2.4271282983451896,0.0)(-2.6590342514551977,0.0)
(3.2420043610860385,1.0)(3.5440500131703354,1.0)
(3.067344577412759,1.0)(3.269179005035978,1.0)
(2.141265211522379,1.0)(3.705816267306055,1.0)
(4.418311047904414,1.0)(2.955773777046275,1.0)
(4.117932735084642,1.0)(3.904874870539733,1.0)
(2.061176997559964,1.0)(2.685256091027288,1.0)
(3.210566236559426,1.0)(3.963262576277656,1.0)
(3.299206068645311,1.0)(3.7974891199125067,1.0)... ...
那如果设置了阈值,则会把大于阈值的结果当成正预测,小于阈值的结果当成负预测。
model.setThreshold(0.0);
scoreAndLabels.foreach(x->{
System.out.println(x);
});
输出结果:
(0.0,0.0)(0.0,0.0)(0.0,0.0)
(0.0,0.0)(0.0,0.0)(0.0,0.0)
(0.0,0.0)(0.0,0.0)(0.0,0.0)
(0.0,0.0)(0.0,0.0)(0.0,0.0)
(0.0,0.0)(0.0,0.0)(0.0,0.0)
(0.0,0.0)(0.0,0.0)(0.0,0.0)
(1.0,1.0)(1.0,1.0)(1.0,1.0)
(1.0,1.0)(1.0,1.0)(1.0,1.0)
(1.0,1.0)(1.0,1.0)... ...
构建评估矩阵,把模型预测的准确性打印出来:
BinaryClassificationMetrics metrics = new BinaryClassificationMetrics(JavaRDD.toRDD(scoreAndLabels));
System.out.println("Area under ROC = "+metrics.areaUnderROC());
//结果打印:
Area under ROC = 1.0
其中, SVMWithSGD.train() 方法默认的通过把正则化参数设为1来执行来范数。如果我们想配置这个算法,可以通过创建一个新的 SVMWithSGD对象然后调用他的setter方法来进行重新配置。下面这个例子,我们构建了一个正则化参数为0.1的L1正则化SVM方法 ,然后迭代这个训练算法2000次。
SVMWithSGD sgd = new SVMWithSGD();
sgd.optimizer().setRegParam(0.1).setNumIterations(2000).setUpdater(new L1Updater());
SVMModel modelL1 = sgd.run(training.rdd());
System.out.println("modelL1:"+modelL1);
//打印结果:
modelL1:org.apache.spark.mllib.classification.SVMModel:
intercept = 0.0, numFeatures = 4, numClasses = 2, threshold = 0.0
模型保存和加载:
model.save(sc.sc(), "data/mllib/FiveSVM");
SVMModel sameModel = SVMModel.load(sc.sc(), "data/mllib/FiveSVM");
四、性质
稳健性与稀疏性:SVM的优化问题同时考虑了经验风险和结构风险最小化,因此具有稳定性。从几何观点,SVM的稳定性体现在其构建超平面决策边界时要求边距最大,因此间隔边界之间有充裕的空间包容测试样本 。SVM使用铰链损失函数作为代理损失,铰链损失函数的取值特点使SVM具有稀疏性,即其决策边界仅由支持向量决定,其余的样本点不参与经验风险最小化 。在使用核方法的非线性学习中,SVM的稳健性和稀疏性在确保了可靠求解结果的同时降低了核矩阵的计算量和内存开销。
五、应用
SVM在各领域的模式识别问题中有广泛应用,包括人像识别(face recognition) 、文本分类(text categorization) 、笔迹识别(handwriting recognition) 、生物信息学 等。
六、参考资料:
1、张健沛[1], 徐华[1]. 支持向量机(SVM)主动学习方法研究与应用[J]. 计算机应用, 2004(1).
2、http://spark.apache.org/docs/latest/mllib-linear-methods.html#classification
3、数据下载地址:https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data