重构——条件逻辑判断
1.案例分析
如何去除If,else,switch条件判断
对于具有一定复杂逻辑的代码实现,避免不了出现if,else,switch等逻辑判断。当逻辑分支越来越多的时候,大大地加大了阅读的难度。这种情况,我们该如何处理呢?
2.switch 与if else谁快
对同一个变量的不同值作条件判断时,可以用switch语句与if语句,哪个语句执行效率更高呢,答案是switch语句,尤其是判断的分支越多越明显。(具体测试的代码,小伙伴可以试一下)
public static void main(String[] args) {
testIF("12");
testSwitch("12");
}
public static void testIF(String arg) {
long t1 = System.nanoTime();
if ("1".equals(arg)) {
System.out.println(arg);
} else if ("2".equals(arg)) {
System.out.println(arg);
} else if ("3".equals(arg)) {
System.out.println(arg);
} else if ("4".equals(arg)) {
System.out.println(arg);
} else if ("5".equals(arg)) {
System.out.println(arg);
} else if ("6".equals(arg)) {
System.out.println(arg);
} else if ("7".equals(arg)) {
System.out.println(arg);
} else if ("8".equals(arg)) {
System.out.println(arg);
} else if ("9".equals(arg)) {
System.out.println(arg);
} else if ("10".equals(arg)) {
System.out.println(arg);
} else if ("11".equals(arg)) {
System.out.println(arg);
} else if ("12".equals(arg)) {
System.out.println(arg);
} else if ("13".equals(arg)) {
System.out.println(arg);
} else if ("14".equals(arg)) {
System.out.println(arg);
} else {
System.out.println(arg);
}
long t2 = System.nanoTime();
System.out.println("test if : " + (t2 - t1));
}
public static void testSwitch(String arg) {
long t1 = System.nanoTime();
switch (arg) {
case "1":
System.out.println(arg);
break;
case "2":
System.out.println(arg);
break;
case "3":
System.out.println(arg);
break;
case "4":
System.out.println(arg);
break;
case "5":
System.out.println(arg);
break;
case "6":
System.out.println(arg);
break;
case "7":
System.out.println(arg);
break;
case "8":
System.out.println(arg);
break;
case "9":
System.out.println(arg);
break;
case "10":
System.out.println(arg);
break;
case "11":
System.out.println(arg);
break;
case "12":
System.out.println(arg);
break;
case "13":
System.out.println(arg);
break;
case "14":
System.out.println(arg);
break;
default:
System.out.println(arg);
break;
}
long t2 = System.nanoTime();
System.out.println("test switch: " + (t2 - t1));
}
最终现实结果
12
test if : 482713
12
test switch: 24870
3.逻辑分支多为什么看起来费劲呢?
复杂!复杂!代码圈复杂度高!
什么是代码圈复杂度?圈复杂度
1)概念:
- 用来衡量一个模块判定结构的复杂程度,数量上表现为独立现行路径条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,根据经验,程序的可能错误和高的圈复杂度有着很大关系。
1)计算公式:
- 计算公式为:V(G)=e-n+2。其中,e表示控制流图中边的数量,n表示控制流图中节点的数量。 其实,圈复杂度的计算还有更直观的方法,因为圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1,也即控制流图的区域数,对应的计算公式为:V(G)=区域数=判定节点数+1。
- 对于多分支的CASE结构或IF-ELSE结构,统计判定节点的个数时需要特别注意一点,要求必须统计全部实际的判定节点数,也即每个 ELSEIF语句,以及每个CASE语句,都应该算为一个判定节点。判定节点在模块的控制流图中很容易被识别出来,所以,针对程序的控制流图计算圈复杂度 V(G)时,最好还是采用第一个公式,也即V(G)=e-n+2;而针对模块的控制流图时,可以直接统计判定节点数,这样更为简单。
4.如何重构这样的代码呢?
1) NULL Object空对象模式
- 描述: 当你在处理可能会出现null的对象时,可能要产生相对乏味的代码来做相应的处理,使用空对象模式可以接受null,并返回相应的信息。
- 代码示例:
interface ILog {
void log();
}
class FileLog implements ILog {
public void log() {
}
}
class ConsoleLog implements ILog {
public void log() {
}
}
class NullObjectLog implements ILog {
public void log() {
}
}
public class LogFactory {
static ILog Create(String str) {
ILog log = new NullObjectLog();
if ("file".equals(str))
log = new FileLog();
if ("console".equals(str))
log = new ConsoleLog();
return log;
}
}
2) 表驱动法(Table-Driven Approach)
- 描述:表驱动法是一种设计模式,可用来代替复杂的if、else逻辑判断。
观察下面的一维数组的形式可以发现,定义了2个变量。
例如:int a[12],a[x]=y;
相当于函数 y=f(x) (在此例子中,x和y为均为int类型),于是就变成了我们平时熟悉的普通的c函数。而函数一般通过数学表达式和逻辑判断的形式得出结果,而这样的结果一般的来说有数学规律,例如像n!就很适合于使用函数实现。
而表驱动法的函数关系是人为定义的,如果采用函数,一般会出现很多的if、else判断。所以表驱动法适合于去实现“人造逻辑”的函数。
例子1:假设你要编写一个计算医疗保险费用的程序,其中保险费用是随着性别、年龄、婚姻状况 和是否吸烟而变化的。(这是代码大全书上的例子,原版是Pasca版本,方便阅阅读改成Java办)。这时候,第一反应可能就是一大堆的if-else语句,如下:
enum SexStatus {
Female, Male
}
enum MaritalStatus {
Single, Married
}
enum SmokingStatus {
NonSmoking, Smoking
}
public double ComputeInsuranceCharge(SexStatus sexStatus, MaritalStatus maritalStatus, SmokingStatus smokingStatus, int age) {
double rate = 1;
if (sexStatus.equals(SexStatus.Female)) {
if (maritalStatus.equals(MaritalStatus.Single)) {
if (smokingStatus.equals(SmokingStatus.NonSmoking)) {
if (age < 18) {
rate = 40.00;
} else if (age == 18) {
rate = 42.50;
} else if (age == 19) {
rate = 45.00;
}
...
else if (age > 65) {
rate = 150.00;
}
} else if (smokingStatus == SmokingStatus.Smoking) {
if (age < 18) {
rate = 44.00;
} else if (age == 18) {
rate = 47.00;
} else if (age == 19) {
rate = 50.00;
}
...
else if (age > 65) {
rate = 200.00;
}
}
} else if (maritalStatus == MaritalStatus.Married) {
//......
}
}
return rate;
}
但是仔细看一下代码,其实保险费率和性别、婚姻、是否抽烟、年龄这个几个因素有一定的关系,尤其年龄的变化区间是相当大,按照上述的写法,可想而知,代码的复杂会达到什么样子的程度。
这时候,肯定有人会想不需要对每个年龄进行判断,而且将保险费用放入年龄数组中,这样将极大地改进上述的代码。不过,如果把保险费用放入所有影响因素的数组而不仅仅是年龄数组的话,将会使程序更简单,类似于可以设计一个费率表格,来降低代码的复杂度呢。
- 定义好费率表格之后, 你就需要确定如何把数据放进去。你可以用从文件中读入费率表格数据。
- 当你建立好数据之后, 便做好了计算保险费用的一切工作。现在就可以用下面这个简单的语句来代替前面那个复杂的逻辑结构了。
Table<Integer, RateFactor, Double> rateTable = HashBasedTable.create();
enum RateFactor {
MALE_SINGLE_NONSMOKING,
MALE_SINGLE_SMOKING,
MALE_MARRIED_NONSMOKING,
MALE_MARRIED_SMOKING,
FEMALE_SINGLE_NONSMOKING,
FEMALE_SINGLE_SMOKING,
FEMALE_MARRIED_NONSMOKING,
FEMALE_MARRIED_SMOKING,
}
public double ComputeInsuranceCharge(RateFactor rateFactor, int age) {
int ageFactor;
if (age < 18) {
ageFactor = 0;
} else if (age > 65) {
ageFactor = 65 - 17;
} else {
ageFactor = age - 17;
}
return rateTable.get(ageFactor, rateFactor);
}
例子2:前端语言可以采用表驱动法简化逻辑吗?
原先代码:
switch (something) {
case 1:
doX();
break;
case 2:
doY();
break;
case 3:
doN();
break;
// And so on...
}
重构后代码:
var cases = {
1: doX,
2: doY,
3: doN
};
if (cases[something]) {
cases[something]();
}
关于表驱动法,还是其他灵活的使用方法,可以参考《代码大全》
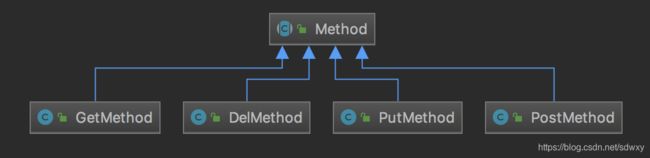
3) 继承子类的多态
使用继承子类的多态,它们使用对象的间接性有效地摆脱了传统的状态判断。
使用继承子类多态的方式,通常对于某个具体对象,它的状态是不可改变的(在对象的生存周期中)。
- 原先代码:
public class Method {
private int type;
public static final int POST = 0;
public static final int GET = 1;
public static final int PUT = 2;
public static final int DELETE = 3;
public Method(int type) {
this.type = type;
}
public String getMethod() throws RuntimeException {
switch (type) {
case POST:
return "这是 POST 方法";
case GET:
return "这是 GET 方法";
case PUT:
return "这是 PUT 方法";
case DELETE:
return "这是 DELETE 方法";
default:
throw new RuntimeException("方法类型调用出错");
}
}
}
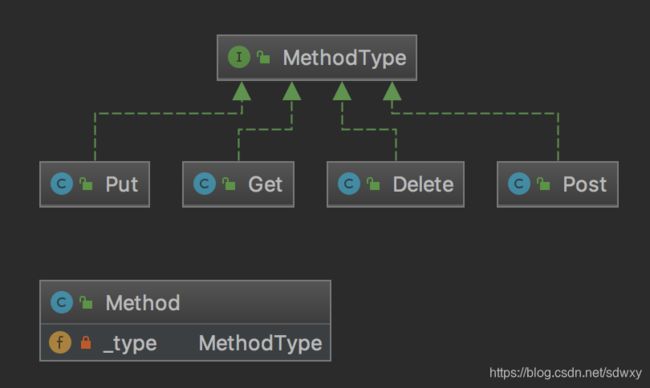
- 重构方法: 现在使用四个子类分别代表四种类型的方法。这样就可以使用多态将各个方法的具体逻辑分置到子类中去了
4) 使用state模式
如果希望对象在生存周期内,可以变化自己的状态,则可以选择state模式。
重构方法:这里抽象状态为一个接口MethodType,四种不同的状态实现该接口。