大语言模型概述(三):基于亚马逊云科技的研究分析与实践
上期介绍了基于亚马逊云科技的大语言模型相关研究方向,以及大语言模型的训练和构建优化。本期将介绍大语言模型训练在亚马逊云科技上的最佳实践。
大语言模型训练在亚马逊云科技上的最佳实践
本章节内容,将重点关注大语言模型在亚马逊云科技上的最佳训练实践。大致分为五大方面:
计算(Compute) — Amazon SageMaker Training
存储(Storage) — 可以通过两种方式完成数据加载和检查点(checkpointing)配置:Amazon FSx Lustre 文件系统或Amazon S3
并行化(Parallelism)— 选择分布式训练库对于正确使用 GPU 至关重要。我们建议使用经过云优化的库,例如 SageMaker 分片数据并行处理,但自管理库和开源库也可以使用
联网(Networking) — 确保 EFA 和 NVIDA的 GPUDirectRDMA已启用,以实现快速的机器间通信
弹性(Resiliency) — 在大规模情况下,可能会发生硬件故障。我们建议定期写入检查点(checkpointing)
以下我们会简单介绍下大语言模型训练并行化(Parallelism)在亚马逊云科技上的最佳实践。
大语言模型训练的并行化(Training Parallelism)
大语言模型通常有数十到数千亿个参数,这使得它们无法容纳在单个 GPU 卡中。大语言模型领域目前已有多个训练分布式计算的开源库,例如:FSDP、DeepSpeed 和 Megatron。你可以在 Amazon SageMaker Training 中直接运行这些库,也可以使用 Amazon SageMaker 分布式训练库,这些库已经针对亚马逊云进行了优化,可提供更简单的开发人员体验。
因此,在大语言模型领域的开发人员,在亚马逊云科技上目前有两种选择:
在 Amazon SageMaker 上使用优化过的分布式库进行分布式训练;
自己来管理分布式训练。
以下将概述如何在 Amazon SageMaker 上,使用优化过的分布式库进行分布式训练。
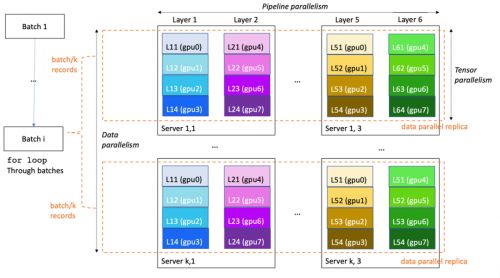
为了提供更好的分布式训练性能和可用性,Amazon SageMaker Training 提出了几种专有扩展来扩展 TensorFlow 和 PyTorch 训练代码。在真实场景里,大语言模型的训练通常以多维度并行(3D-parallelism)的方式在进行:
数据并行(data parallelism):可拆分训练小批次并将其馈送到大语言模型的多个相同副本,以提高处理速度
流水线并行(pipeline parallelism):将大语言模型的各个层归因于不同的 GPU 甚至实例,以便将大语言模型的大小扩展到单个 GPU 和单个服务器以外
Tensor 并行(tensor parallelism):将单个层拆分为多个 GPU,通常位于同一服务器内,以将单个层扩展到超过单个 GPU 的大小
以下示例图,展示了如何在具有 8*k*3 个 GPU(每台服务器 8 个 GPU)的 k*3 服务器集群上训练 6 层模型。数据并行度为 k,流水线并行度为 6,张量并行度为 4。集群中的每个 GPU 包含模型层的四分之一,完整模型分为三台服务器(总共 24 个 GPU)。
其中和大语言模型特别相关的分布式实践包括:
Amazon SageMaker 分布式模型并行 — 该库使用图形分区生成针对速度或内存进行了优化的智能大语言模型分区。Amazon SageMaker 分布式模型并行提供了最新、最好的大语言模型训练优化,包括数据并行、流水线并行、张量并行、优化器状态分片、激活检查点和卸载。
Amazon SageMaker 分片数据并行——在 MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud 论文中,引入了一种新的模型并行策略,该策略仅在数据并行组上划分模型,而不是整个集群。借助 MiCS,亚马逊云科技的科学家们能够在每个 GPU 上实现 176 万亿次浮点运算(理论峰值的 56.4%),从而在 EC2 P4de 实例上训练 210 层、1.06 万亿个参数的大语言模型。作为 Amazon SageMaker 并行共享数据,MIC 现已能够向 Amazon SageMaker Training 客户提供。
Amazon SageMaker 分布式训练库提供高性能和更简单的开发者体验。开发人员无需编写和维护自定义的并行进程启动器,或使用特定于框架的启动工具,因为并行启动器已经内置在 Amazon SageMaker 的任务启动 SDK 之中。
与传统分布式训练相比,大语言模型的微调通常不仅要求数据并行,数据并行和模型并行需要同时进行。Amazon SageMaker Model Parallelism 在易用性和稳定性 (OOM) 上与开源自建方案(如 DeepSpeed)相比具有核心竞争优势。对于基于哪些大语言模型进行具体微调、具体最佳实践等技术细节,你还可以咨询亚马逊云科技的解决方案架构师团队,获得更进一步的技术支持和专业建议。
总结
本期文章我们一起探讨大语言模型的发展历史、语料来源、数据预处理流程策略、训练使用的网络架构、最新研究方向分析(LLaMA、PaLM-E 等),以及在亚马逊云科技上进行大语言模型训练的一些最佳落地实践等。