计算机二级Python基本操作题-序号45
1. 键盘输入一组水果名称并以空格分隔,共一行。
示例格式如下:
苹果 芒果 草莓 芒果 苹果 草莓 芒果 香蕉 芒果 草莓
统计各类型的数量,从数量多到少的顺序输出类型及对应数量,以英文冒号分隔,每个类型行。输出结果保存在考生文件夹下,命名为“PY202.txt”。输出参考格式如下:
芒果:4
草莓:3
苹果:2
香蕉: 1
txt = input("请输入类型序列: ") # 从用户输入中读取类型序列并将其分割成水果列表
fo = open("PY202.txt","w") # 打开一个名为 PY202.txt 的文件,以写入模式打开
fruits = txt.split(" ")
d = {} # 创建一个空字典
# 遍历水果列表并将每个水果添加到字典中,如果水果已经在字典中,则将其数量加1
for fruit in fruits:
d[fruit] = d.get(fruit,0) + 1 #d.get(fruit,0)表示,在d中寻找fruit,如果没找到则返回0
# 将字典转换为列表并按数量排序(从高到低)
ls = list(d.items())
ls.sort(key = lambda x:x[1], reverse = True)
# 将每个水果及其数量写入文件中
for k in ls:
fo.write("{}:{}".format(k[0], k[1]))
fo.close() # 关闭文件
2. 键盘输入一组人员的姓名、性别、年龄等信息,信息间采用空格分隔,每人一行,空行回车结束录入。
示例格式如下:
张猛 男 35
杨青 女 18
汪梅 男 26
孙倩 女 22
计算并输出这组人员的平均年龄(保留1位小数)和其中女性人数
fo = open("PY202.txt","w")#打开
data = input("请输入一组人员的姓名、性别、年龄:") # 姓名 年龄 性别
women_num = 0
age_amount = 0
person_num = 0
while data:
name, sex, age = data.split(' ')
if sex == '女':
women_num += 1
age_amount += int(age)
person_num += 1
data = input("请输入一组人员的姓名、性别、年龄:")
average_age = age_amount / person_num
fo.write("平均年龄是{:.1f} 女性人数是{}".format(average_age, women_num))
fo.close()
3. 键盘输入某班各个同学就业的行业名称,行业名称之间用空格间隔(回车结束输入)。完善Python代码,统计各行业就业的学生数量,按数量从高到低方式输出。
例如输入:
护士 旅游 老师 护士 老师 老师
输出参考格式如下,其中冒号为英文冒号:
老师:3
护士:2
旅游:1
fo = open("PY202.txt","w")
names = input("请输入各个同学行业名称,行业名称之间用空格间隔(回车结束输入):")
name_list = names.split('')
d = {}
for item in name_list:
d[item] = d.get(item,0) + 1
ls = list(d.items())
ls.sort(key = lambda x:x[1], reverse=True) # 按照数量排序
for k in ls:
fo.write("{}:{}".format(k[0],k[1]))
4. 键盘输入张嘉译学习的课程名称及考分等信息,信息间采用空格分隔,每个课程一行,空行回车结束录入。
示例格式如:
数学 98
语文 89
英语 94
物理 74
科学 87
输出得分最高的课程及成绩,得分最低的课程及成绩,以及平均分(保留两位小数)
fo = open("PY202.txt","w")
data = input("请输入课程名及对应的成绩:")
course_score_dict = {}
while data:
course,score = data.split(' ')
course_score_dict[course] = eval(score) # 课程名为键,成绩为值
data = input("请输入课程名及对应的成绩:")
score_list = sorted(list(course_score_dict.values()))
# 将字典转换成列表,values()返回所有值的信息,对成绩进行排序
max_score,min_score= score_list[-1],score_list[0]
average_score = sum(score_list) / len(score_list)
max_course,min_course='','' # 设为空字符串
for item in course_score_dict.items(): # items方法遍历元组,元组里是键值对
if item[1] == max_score: # 因为(键,值),值为最大成绩时,最高分课程则为元组里的键
max_course = item[0]
if item[1] == min_score:
min_course = item[0]
fo.write("最高分课程是{}{},最低分课程是{}{},平均分是{:.2f}".format
(max_course,max_score,min_course,min_score,average_score))
fo.close()
5. 编写程序,实现将列表ls[51,33,54,67,88,431,111,141,72,45,2,78,12,15,5,69]中的素数去除,并输出去除素数后列表的元素个数
fo = open("PY202.txt","w")
def prime(num):
for i in range(2,num):
if num % i == 0:
return False
return True
ls = [51,33,54,67,88,431,111,141,72,45,2,78,12,15,5,69]
lis = []
for i in ls:
if prime(i) == False:
lis.append(i)#将不是素数的元素压入到新的列表中
fo.write(">>>{},列表长度为{}".format(lis,len(lis)))
fo.close()
“>>>”是Python语言运行环境的提示符,其表示可以在此符号后面输入Python语句。在提示符后输入exit()或者quit()可退出Python运行环境。
6. 闰年分为普通闰年和世纪闰年。普通闰年是指能被4整除但不能被100整除的年份,世纪闰年是能被400整除的年份。请编写一个函数,能够实现以下功能:输入一个年份,能够判断这个年份是否为闰年,并且打印在屏幕上。
def judge_year(year):
if(year % 4 == 0 and year % 100 != 0) or year % 400 == 0:
print(year,"年是闰年")
else:
print(year,"年不是闰年")
year = eval(input("请输入年份:"))
judge_year(year)
7. 键盘输入两个大于0的整数,按要求输出这两个整数之间(不包括这两个整数)的所有素数。素数又称质数,是除了 1 和它本身以外不能被其他整数整除的数
lower = int(input('输入区间最小值:'))
upper = int(input('输入区间最大值:'))
for num in range(lower + 1,upper):
if num > 1:
for i in range(2,num):
if(num % i) == 0:
break
else:
print(num)
8. 使用Python的异常处理结构编写对数计算,要求底数大于0且不等于1,真数大于0,且输入的必须为实数,否则抛出对应的异常。
import math
try:
a = eval(input('请输入底数:'))
b = eval(input('请输入真数:'))
c = math.log(b,a)
except ValueError: # ValueError-传入无效的参数
if a <= 0 and b > 0:
print('底数不能小于等于0')
elif b <= 0 and a > 0:
print('真数不能小于等于0')
elif a <= 0 and b <= 0:
print('真数和底数都不能小于等于0')
except ZeroDivisionError: # ZeroDivisionError-除(或取模)零 (所有数据类型)
print('底数不能为1')
except NameError: # NameError-未声明/初始化对象 (没有属性)
print('输入必须为实数')
else:
print(c)
Python 异常处理
9. 九九乘法表输出。按照乘法表的格式打印出九九乘法表
fo = open("PY202.txt","w")
for i in range(1,10):
for j in range(1,i + 1):
fo.write("{} * {} = {}".format(j,i,i * j))
fo.write("\n")
fo.close()
10. 使用turtle库的fd()函数和right()函数绘制一个边长为100像素的正六边形,再用circle()函数绘制半径为60像素的红色圆内接正六边形。
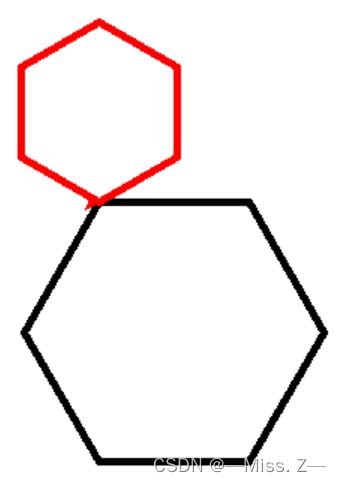
from turtle import *
pensize(5) # # 设置画笔的粗细
for i in range(6):
fd(100)
right(60)
color("red") # 画笔颜色为红色
circle(60,steps = 6) # 圆内接正六边形
总结
split()方法
Python中split()函数,具体作用如下:
拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
split() 方法语法:str.split(str="",num=string.count(str))[n]
参数说明:
- str:表示为分隔符,默认为空格,但是不能为空(’’)。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
- num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量。默认为 -1, 即分隔所有。
- [n]:表示选取第n个分片
注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
string = “www.gziscas.com.cn”
示例①:以’ . '为分隔符
print(string.split('.'))
//['www', 'gziscas', 'com', 'cn']
示例②:分割两次
print(string.split('.',2))
//['www', 'gziscas', 'com.cn']
示例③:分割两次,并取序列为1的项
print(string.split('.',2)[1])
//gziscas
get()方法
字典 get() 方法:返回指定键的值
get()方法语法:dict.get(key[, value])
参数:
- key – 字典中要查找的键。
- value – 可选,如果指定键的值不存在时,返回该默认值。
返回值:返回指定键的值,如果键不在字典中返回默认值,如果不指定默认值,则返回 None。
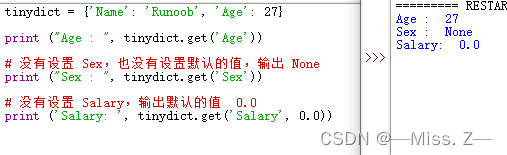
tinydict = {'Name': 'Runoob', 'Age': 27}
print ("Age : ", tinydict.get('Age'))
print ("Sex : ", tinydict.get('Sex')) # 没有设置 Sex,也没有设置默认的值,输出 None
print ('Salary: ', tinydict.get('Salary', 0.0)) # 没有设置 Salary,输出默认的值 0.0
items() 方法
字典 items() 方法:以列表返回视图对象,是一个可遍历的key/value 对
dict.keys()、dict.values() 和 dict.items() 返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。
视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。
我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
items()方法语法:dict.items()
Python 异常处理
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
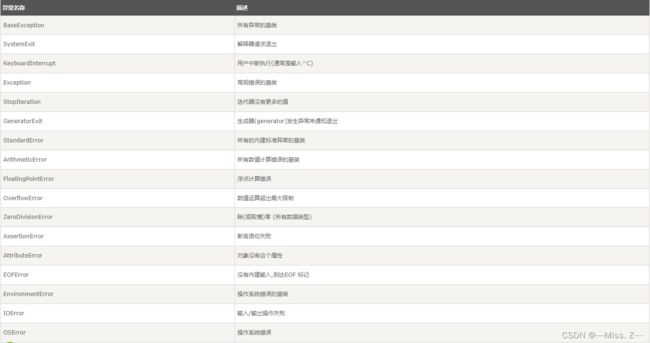
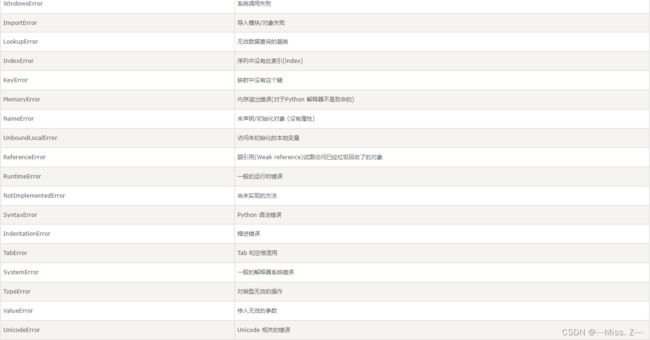
python标准异常:
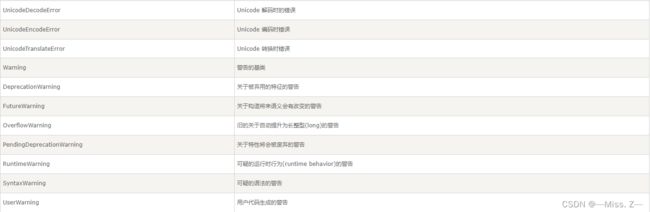
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
语法:
以下为简单的try…except…else的语法:
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生
try的工作原理是,当开始一个try语句后,python就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当try后的语句执行时发生异常,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句(除非在处理异常时又引发新的异常)。
- 如果在try后的语句里发生了异常,却没有匹配的except子句,异常将被递交到上层的try,或者到程序的最上层(这样将结束程序,并打印默认的出错信息)。
- 如果在try子句执行时没有发生异常,python将执行else语句后的语句(如果有else的话),然后控制流通过整个try语句。
11. 计算两个列表ls和lt对应元素乘积的和(即向量积),补充PY202.py文件。
ls = [111,222,333,444,555,666,777,888,999]
lt = [999,777,555,333,111,888,666,444,222]
ls = [111, 222, 333, 444, 555, 666, 777, 888, 999]
lt = [999, 777, 555, 333, 111, 888, 666, 444, 222]
s = 0
for i in range(len(ls)):
s += (ls[i] * lt[i])
print(s)
12. 使用字典和列表型变量完成村长选举。某村有40名有选举权和被选举权的村民,名单由考生文件夹下文件name.txt给出,从这40名村民中选出一人当村长,40人的投票信息由考生文件夹下文件vote.txt给出,每行是一张选票的信息,有效票中得票最多的村民当选。
- 问题1:请从vote.txt中筛选出无效票写入文件votel.txt。有效票的含义是:选票中只有一个名字且该名字在name.txt文件列表中,不是有效票的票称为无效票。
- 问题2:给出当选村长的名字及其得票数。在考生文件夹下给出了程序框架文件PY202.py,补充代码完成程序。
f = open("name.txt")
names = f.readlines()
f.close()
f = open("vote.txt")
votes = f.readlines()
f.close()
f = open("vote1.txt","w")
D = {}
NUM = 0
for vote in votes:
num = len(vote.split())
if num == 1 and vote in names:
D[vote[:-1]] = D.get(vote[:-1],0)+1
NUM += 1
else:
f.write(vote)
f.close()
l = list(D.items())
l.sort(key = lambda s:s[1],reverse = True)
name = l[0][0]
score = l[0][1]
print("有效票数为:{} 当选村长村民为:{},票数为:{}".format(NUM,name,score))