Apache集群安装Impala
文章目录
- 1 前言
-
- 1.1 中间件版本选取
- 1.2 各个实例通信网络端口
- 1.3 环境准备
-
- 1.3.1 CentOS 6.8
- 1.3.2 关闭防火墙
- 2 Apache Impala简述
-
- 2.1 Apache Impala架构组成介绍
- 2.2 Apache Impala的特点
-
- 2.2.1 优点
- 2.2.2 缺点
- 3 Apache Impala部署
-
- 3.1 Impala安装
-
- 3.1.1 环境检查
- 3.1.2 下载安装包
- 3.1.3 Impala主从机安装
- 3.2 Impala配置
-
- 3.2.1 Impala依赖的包
- 3.2.2 Impala依赖组件的配置
- 3.2.3 Impala自身的配置
- 3.3 启动
- 3.4 安装检查
- 4 Apache Impala基本操作
- 5 Apache Impala常见问题分析
-
- 5.1 Service启动失败
- 5.2 Impala-shell启动失败
- 5.3 端口冲突
1 前言
Impala是典型的内存性数据查询引擎,其他的内存型数据查询引擎有很多,比如SparkSQL、Doris等。这里分别从架构、中间件部署维护、基本操作、性能等方面简单说一下Impala
1.1 中间件版本选取
| 中间件名称 | 版本号 |
|---|---|
| CentOS | CentOS 6.8 |
| Java | 1.8.0_121 |
| zookeeper | 3.4.10 |
| Hadoop | 2.4.2 |
| mysql | 5.6.24 |
| hive | 1.2.1 |
| hbase | 1.3.1 |
| impala | 2.11.0 |
| cdh | 5.14.0 |
| Presto | 0.196 |
| Presto-cli | 0.196 |
| yanagishima | 18.0 |
1.2 各个实例通信网络端口
| 端口名称 | 默认端口 | 说明 |
|---|---|---|
| impala | 25000 | impala Web端口 |
| statestore | 25010 | statestore web |
| impala | 21000 | impala-shell通信端口 |
| MetaStore | 9083 | hive元数据端口 |
| coordinator | 8881 | coordinator Web端口 |
| yanagishima | 7080 | yanagishima Web端口 |
1.3 环境准备
默认已经安装好CentOS6.8、Apache Hadoop、hive、zookeeper、mysql、jdk、hbase
1.3.1 CentOS 6.8
CentOS6.8安过程省略。预先创建用户/用户组zhouchen
预先安装jdk1.8.0_92+
预先安装zookeeper
预先安装hadoop
预先安装mysql
预先安装hive
预先安装hbase
1.3.2 关闭防火墙
针对CentOS7以下
1.查看防火墙状态
service iptables status
2.停止防火墙
service iptables stop
3.启动防火墙
service iptables start
2 Apache Impala简述
Impala由Cloudera公司推出,提供对HDFS、HBase数据的高性能、低延迟的交互式SQL查询功能。基于Hive,使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。是CDH平台首选的PB级大数据实时查询分析引擎。

2.1 Apache Impala架构组成介绍
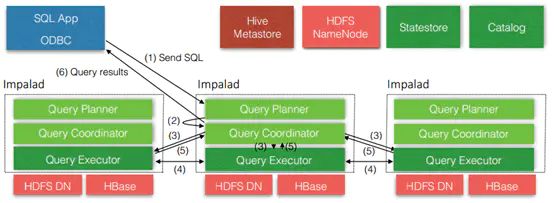
从上图可以看出,Impala自身包含三个模块:Impalad、Statestore和Catalog,除此之外它还依赖Hive Metastore和HDFS。
1)mpalad:
接收client的请求、Query执行并返回给中心协调节点;
子节点上的守护进程,负责向statestore保持通信,汇报工作。
2)Catalog:
分发表的元数据信息到各个impalad中;
接收来自statestore的所有请求。
3)Statestore:
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息;
2.2 Apache Impala的特点
2.2.1 优点
1)基于内存运算,不需要把中间结果写入磁盘,省掉了大量的I/O开销。
2)无需转换为Mapreduce,直接访问存储在HDFS,HBase中的数据进行作业调度,速度快。
3)使用了支持Data locality的I/O调度机制,尽可能地将数据和计算分配在同一台机器上进行,减少了网络开销。
4)支持各种文件格式,如TEXTFILE 、SEQUENCEFILE 、RCFile、Parquet。
5)可以访问hive的metastore,对hive数据直接做数据分析。
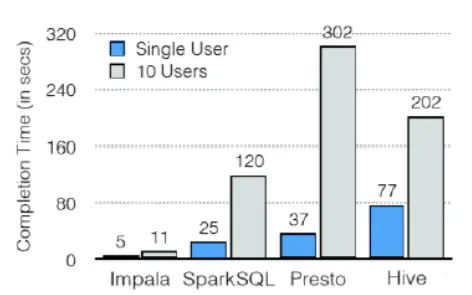
2.2.2 缺点
1)对内存的依赖大,且完全依赖于hive。
2)实践中,分区超过1万,性能严重下降。
3)只能读取文本文件,而不能直接读取自定义二进制文件。
4)每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
3 Apache Impala部署
3.1 Impala安装
Impala是cloudera公司的产物,最简便的方式是直接安装CDH集群一键安装impala,这里不赘述。本文详细描述如何在Apache大数据集群下单独安装impala。
3.1.1 环境检查
1.检查Java版本,$JAVA_HOME
2.检查hadoop版本
3.检查MySQL安装
4.检查zookeeper安装
3.1.2 下载安装包
1.下载CDH的安装包到本地
CDH安装包
2.选择安装包
cdh/5.14.0/RPMS/x86_64下
hadoop-*
impala-*
cdh/5.14.0/RPMS/noarch下
bigtop-utils*
hive-*
sentry-*
3.将以上包上传到所有主从机节点备用
!!从机不需要impala-state-store/impala-catalog两个包
3.1.3 Impala主从机安装
由于是rpm包,直接安装就可以了(分别在主从机上安装,确保从机上删除了impala-state-store/impala-catalog两个包)
sudo rpm -ivh --nodeps impala*
sudo rpm -ivh --nodeps hadoop*
sudo rpm -ivh --nodeps bigtop-utils-*
sudo rpm -ivh --nodeps hive*
sudo rpm -ivh --nodeps sentry*
3.2 Impala配置
impala主要的目录/文件有3个
- /usr/lib/impala/lib/ --安装目录下的包
- /etc/impala/conf --依赖的配置文件
- /etc/default/impala --impala自身的配置
3.2.1 Impala依赖的包
由于我们impala是从cdh的包中取出来的,impala安装目录下的包中,很多依赖的包默认是指向cdh版本的hadoop、hive、habse等的。这里首先删除/usr/lib/impala/lib/下无效的软连接,类似如下(主从机都删除):

又因为我们安装了cdh下的hadoop、hive、sentry包,这些相关的软链接我们不用改到Apache版本的包上(后续发现不改的话会与原Hadoop、hive等冲突)。
由于没有安装cdh版本的hbase,只需要创建已安装的hbase下的jar到impala下的lib的软链接即可(主从机都要执行,且链上去的$HBASE_HOME下的包都要真实存在):
sudo ln -s $HBASE_HOME/lib/hbase-client-1.3.1.jar /usr/lib/impala/lib/hbase-client.jar
sudo ln -s $HBASE_HOME/lib/hbase-common-1.3.1.jar /usr/lib/impala/lib/hbase-common.jar
sudo ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar /usr/lib/impala/lib/hbase-hadoop2-compat.jar
sudo ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar /usr/lib/impala/lib/hbase-hadoop-compat.jar
sudo ln -s $HBASE_HOME/lib/hbase-procedure-1.3.1.jar /usr/lib/impala/lib/hbase-procedure.jar
sudo ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar /usr/lib/impala/lib/hbase-protocol.jar
sudo ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar /usr/lib/impala/lib/hbase-server.jar
3.2.2 Impala依赖组件的配置
- 首先将Apache版本的hadoop和hive的配置copy到impala的配置目录下
[zhouchen@hadoop102 lib]$ cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml /etc/impala/conf
[zhouchen@hadoop102 lib]$ cp $HADOOP_HOME/etc/hadoop/core-site.xml /etc/impala/conf
[zhouchen@hadoop102 lib]$ cp $HIVE_HOME/conf/hive-site.xml /etc/impala/conf
- 修改hive-site.xml(注意这里地址最好写成ip的形式,填主机名会报错访问不到)
[zhouchen@hadoop102 conf]$ sudo vim hive-site.xml
<!-- 指定hive metastore服务请求的uri地址 -->
hive.metastore.uris</name>
thrift://192.168.139.130:9083</value>
</property>
- 修改hdfs-site.xml
[zhouchen@hadoop102 conf]$ sudo mkdir -p /var/run/hadoop-hdfs/
[zhouchen@hadoop102 conf]$ sudo vim hdfs-site.xml
#添加如下内容
dfs.client.read.shortcircuit</name>
true</value>
</property>
dfs.domain.socket.path</name>
/var/run/hadoop-hdfs/dn._PORT</value>
</property>
dfs.client.file-block-storage-locations.timeout.millis</name>
10000</value>
</property>
dfs.datanode.hdfs-blocks-metadata.enabled</name>
true</value>
</property>
4.配置完成之后,将/etc/impala/conf下的3个配置文件同步分发到从机上
3.2.3 Impala自身的配置
1.修改impala配置文件
[zhouchen@hadoop102 conf]$ sudo vim /etc/default/impala
#内容如下:
#catalog和state-store都是主机才有的需要配成主机的ip(最好写ip)
IMPALA_CATALOG_SERVICE_HOST=192.168.139.130
IMPALA_STATE_STORE_HOST=192.168.139.130
IMPALA_STATE_STORE_PORT=24000
IMPALA_BACKEND_PORT=22000
IMPALA_LOG_DIR=/var/log/impala
IMPALA_CATALOG_ARGS=" -log_dir=${IMPALA_LOG_DIR} "
IMPALA_STATE_STORE_ARGS=" -log_dir=${IMPALA_LOG_DIR} -state_store_port=${IMPALA_STATE_STORE_PORT}"
IMPALA_SERVER_ARGS=" \
-log_dir=${IMPALA_LOG_DIR} \
-catalog_service_host=${IMPALA_CATALOG_SERVICE_HOST} \
-state_store_port=${IMPALA_STATE_STORE_PORT} \
-use_statestore \
-state_store_host=${IMPALA_STATE_STORE_HOST} \
-be_port=${IMPALA_BACKEND_PORT}"
ENABLE_CORE_DUMPS=false
LIBHDFS_OPTS=-Djava.library.path=/usr/lib/impala/lib
#元数据的驱动包,将已安装的mysql的驱动copy过来即可
MYSQL_CONNECTOR_JAR=/var/lib/impala/mysql-connector-java-5.1.27-bin.jar
IMPALA_BIN=/usr/lib/impala/sbin
IMPALA_HOME=/usr/lib/impala
# HIVE_HOME=/opt/module/hive
# HBASE_HOME=/opt/module/hbase
IMPALA_CONF_DIR=/etc/impala/conf
HADOOP_CONF_DIR=/etc/impala/conf
HIVE_CONF_DIR=/etc/impala/conf
# HBASE_CONF_DIR=/etc/impala/conf
2.修改完配置同步分发到各从机
3.3 启动
1.启动hadoop
2.启动zookeeper
3.启动hbase
4.启动hive服务/opt/module/hive/bin
[zhouchen@hadoop102 bin]$ hive --service metastore
[zhouchen@hadoop102 bin]$ hive --service hiveserver2
5.启动impala(主机启动即可)
[zhouchen@hadoop102 impala]$ sudo service impala-state-store start
Started Impala State Store Server (statestored): [确定]
[zhouchen@hadoop102 impala]$ sudo service impala-catalog start
Started Impala Catalog Server (catalogd) : [确定]
[zhouchen@hadoop102 impala]$ sudo service impala-server start
Started Impala Server (impalad): [确定]
6.检查impala服务状态
[zhouchen@hadoop102 impala]$ sudo service impala-state-store status
Impala State Store Server is running [确定]
[zhouchen@hadoop102 impala]$ sudo service impala-catalog status
Impala Catalog Server is running [确定]
[zhouchen@hadoop102 impala]$ sudo service impala-server status
Impala Server is running [确定]
3.4 安装检查
1.查看进程
[zhouchen@hadoop102 impala]$ ps -ef | grep impala
statestored/catalog/impala服务都要起来

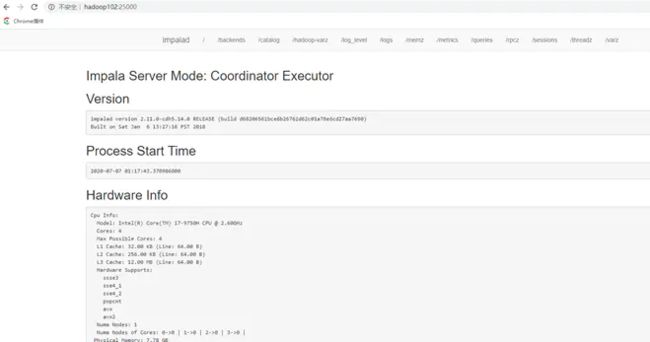
2.界面访问
访问impalad的管理界面http://hadoop102:25000/
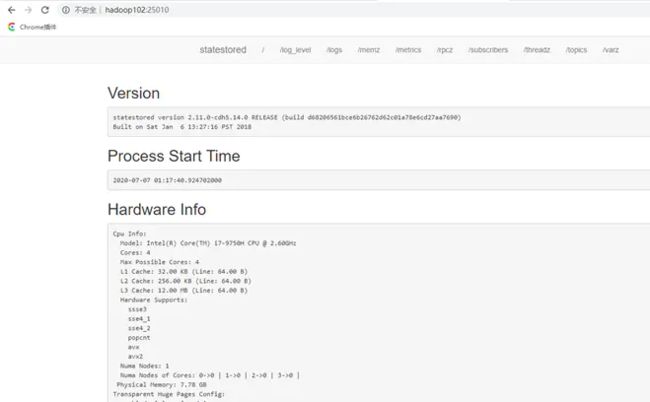
访问statestored的管理界面http://hadoop102:25010/
3.连接impala-shell
[zhouchen@hadoop102 ~]$ impala-shell
Starting Impala Shell without Kerberos authentication
Connected to hadoop102:21000
Server version: impalad version 2.11.0-cdh5.14.0 RELEASE (build d68206561bce6b26762d62c01a78e6cd27aa7690)
******************************************************************************
Welcome to the Impala shell.
(Impala Shell v2.11.0-cdh5.14.0 (d682065) built on Sat Jan 6 13:27:16 PST 2018)
When pretty-printing is disabled, you can use the '--output_delimiter' flag to set
the delimiter for fields in the same row. The default is ','.
******************************************************************************
[hadoop102:21000] > show databases;
Query: show databases
+------------------+----------------------------------------------+
| name | comment |
+------------------+----------------------------------------------+
| _impala_builtins | System database for Impala builtin functions |
| default | Default Hive database |
| gmall | |
| hiveexer | |
| sparkexercise | |
+------------------+----------------------------------------------+
Fetched 5 row(s) in 0.10s
4 Apache Impala基本操作
基本的语法跟hive的查询语句大体一样,这里不做赘述,只简述一些impala特殊的地方
- Impala不支持CLUSTERBY, DISTRIBUTE BY, SORT BY
- Impala中不支持分桶表
- Impala不支持COLLECT_SET(col)和explode(col)函数
- Impala支持开窗函数
[hadoop102:21000] > select id,order_id,dt over(partition by
month(dt)) from dwd_order_detail;
Query: select id,order_id,dt over(partition by month(dt)) from dwd_order_detail
Query submitted at: 2020-07-07 03:02:58 (Coordinator:http://hadoop102:25000)
ERROR: AnalysisException: Syntax error in line 1:
select id,order_id,dt over(partition by month(dt))...
- impala数据导入基本同hive类似,只是不支持load data local inpath…
- impala不支持insert overwrite…语法数据导出
- impala 数据导出一般使用impala -o
[zhouchen@hadoop103 ~]# impala-shell -q 'select * from student' -B --output_delimiter="\t" -o output.txt
[zhouchen@hadoop103 ~]# cat output.txt
1001 tignitgn
1002 yuanyuan
1003 haohao
1004 yunyun
- Impala不支持export和import命令
5 Apache Impala常见问题分析
5.1 Service启动失败
查看impala日志,如下报错:
E1118 16:59:21.978019 28852 impala-server.cc:210] Could not read the HDFS root directory at hdfs://hadoop102:9000. Error was:
Failed on local exception:com.google.protobuf.InvalidProtocolBufferException: Message missing required fields:callId, status; Host Details : local host is: "localhost/127.0.0.1";destination host is: "hadoop102":9000;
E1118 16:59:21.978039 28852 impala-server.cc:212] Aborting Impala Serverstartup due to improper configuration
解决:
此时impala依赖的组件是Apache hadoop,需要先启动hadoop
5.2 Impala-shell启动失败
报错:
[zhouchen@hadoop102 bin]$ impala-shell -i hadoop103 File"/usr/lib/impala-shell/impala_shell.py", line 235
print "Query options(defaults shown in []):"
^
SyntaxError: invalid syntax
原因:
由于Python3的启动问题导致的,需要修改impala-sehll脚本:
[zhouchen@hadoop102 bin]$ sudo vim /usr/bin/impala-shell

5.3 端口冲突
由于安装了CDH版本的hadoop、hive包,导致与原有的hadoop、hive端口出现部分的冲突,然后启动Apache版本的hadoop的时候出现异常报错导致Hadoop启动失败。
解决:
首先查看自启动服务中hadoop和hive的服务:
[zhouchen@hadoop103 lib]$ chkconfig | grep hadoop
hadoop-0.20-mapreduce-jobtracker 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-0.20-mapreduce-jobtrackerha 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-0.20-mapreduce-tasktracker 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-0.20-mapreduce-zkfc 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-hdfs-datanode 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-hdfs-journalnode 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-hdfs-namenode 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-hdfs-nfs3 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-hdfs-secondarynamenode 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-hdfs-zkfc 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-httpfs 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-kms-server 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-mapreduce-historyserver 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-yarn-nodemanager 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-yarn-proxyserver 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hadoop-yarn-resourcemanager 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
[zhouchen@hadoop104 lib]$ chkconfig | grep hive
hive-metastore 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hive-server 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hive-server2 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
hive-webhcat-server 0:关闭 1:关闭 2:关闭 3:启用 4:启用 5:启用 6:关闭
关闭Hadoop与hive的自启动(level3 4 5 ):
sudo chkconfig hive-metastore --level 5 off
sudo chkconfig hive-server --level 5 off
sudo chkconfig hive-server2 --level 5 off
sudo chkconfig hive-webhcat-server --level 5 off
sudo chkconfig hadoop-0.20-mapreduce-jobtracker -- level 5 off
sudo chkconfig hadoop-0.20-mapreduce-jobtrackerha -- level 5 off
sudo chkconfig hadoop-0.20-mapreduce-tasktracker -- level 5 off
sudo chkconfig hadoop-0.20-mapreduce-zkfc -- level 5 off
sudo chkconfig hadoop-hdfs-datanode -- level 5 off
sudo chkconfig hadoop-hdfs-journalnode -- level 5 off
sudo chkconfig hadoop-hdfs-namenode -- level 5 off
sudo chkconfig hadoop-hdfs-nfs3 -- level 5 off
sudo chkconfig hadoop-hdfs-secondarynamenode -- level 5 off
sudo chkconfig hadoop-hdfs-zkfc -- level 5 off
sudo chkconfig hadoop-httpfs -- level 5 off
sudo chkconfig hadoop-kms-server -- level 5 off
sudo chkconfig hadoop-mapreduce-historyserver -- level 5 off
sudo chkconfig hadoop-yarn-nodemanager -- level 5 off
sudo chkconfig hadoop-yarn-proxyserver -- level 5 off
sudo chkconfig hadoop-yarn-resourcemanager -- level 5 off