【MySQL】查询进阶

- 专栏内容:MySQL
- ⛪个人主页:子夜的星的主页
- 座右铭:前路未远,步履不停
目录
- 一、数据库约束
-
- 1、约束类型
- 2、`not null`
- 3、`unique`
- 4、`default`
- 5、`primary key`
- 6、`foreign key`
- 二、新增
- 三、查询
-
- 1、聚合查询
- 2、分组查询
- 3、联合查询
-
- 内连接
- 外连接
- 自连接
- 4、合并查询
一、数据库约束
1、约束类型
not null 非空:指定某列不能存储 null 值
unique 唯一:保证某列的每行必须有唯一的值
default 默认: 规定没有给列赋值时的默认值
primary key 主键: not null 和 unique 的结合,确保某列有唯一标识,有助于更容易更快速的找到表中的一个特定值
foreign key外键:保证一个表中的数据匹配另一个表中的参照完整性
check保证列中的值符合指定的条件,对于 MySQL 数据库,堆 check 子句进行分析,但是忽略 check 子句
2、not null
create table student (id int , name varchar(20) not null);

3、unique
唯一,此处的限制不允许存在两行数据在指定列上重复。
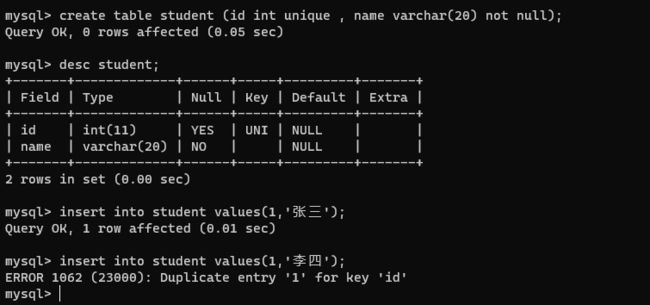
MySQL 咋找到已经有相同的数据了?
针对带有 unique 的数据,MySQL 会先进行查询,看是不是已经存在,存在就不插入了。
4、default
使用指定列插入的时候,未被指定的列就会按照默认值来填充。如果不修改其默认值,默认情况下的默认值就是 NULL。

5、primary key
主键约束:一条数据的身份表示。用于区分两条数据是不是一个数据。通过这个来指定某个列作为主键。
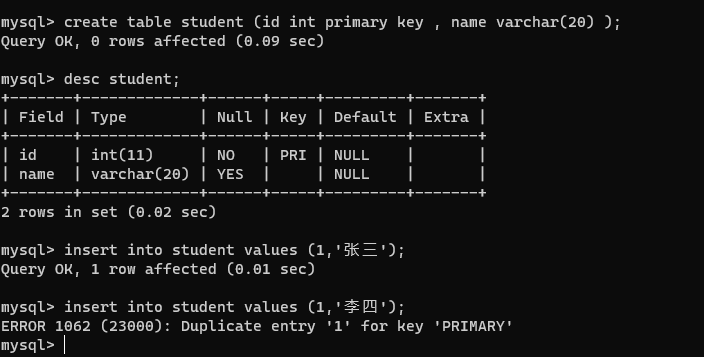
自增主键:允许客户端在插入的时候,不指定主键的值,交给 MySQL 自己分配。
create table student (id int primary key auto_increment , name varchar(20) );
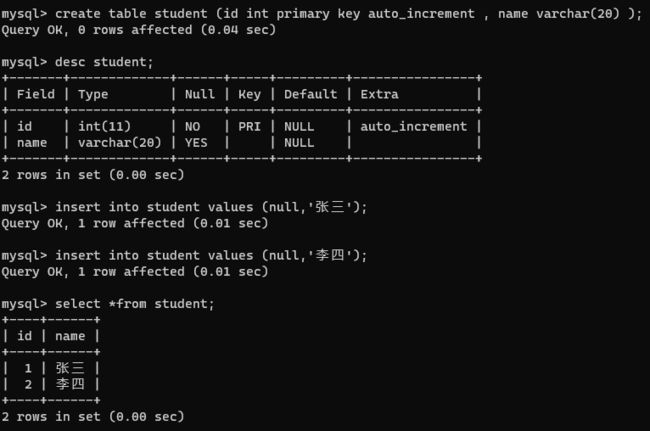
自增主键,id 用 null 是让数据库自行分配。自增主键,也是可以手动值的。下一个 分配的 id 就会在之前最大值的基础上继续自增。
当然,如果 MySQL 是单机系统,基于上面的策略是没有问题的,但是如果 MySQL 是一个分布式的系统,自增主键就没有办法保证唯一性。为了解决上述问题,也有一些分布式 id 的生成算法。把 id 作为一个字符串,字符串由下面几个部分组成:主机编号/机房编号+时间戳+随机因子。
6、foreign key
外键:涉及到两个表之间的约束。
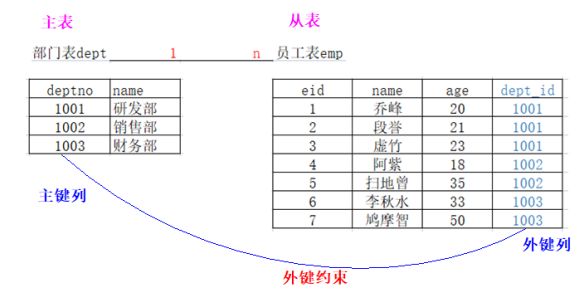
主(父)表用来约束从(子)表的。
create table dept(deptno int primary key,name varchar(20));
create table emp (id int primary key auto_increment , name varchar(20) ,
dept_id int ,foreign key(dept_id) references dept(deptno));
插入或者修改子表中受约束的这一列的数据,需要保证在父表中存在该数据。

删除或者修改父表中的记录,就需要看这个记录是否在子表中被使用了,如果被使用了,则不能进行删除或者修改。
二、新增
新增操作:把 insert和 select两个操作合并在一起。
insert into 表名 [(colum [,colum....])] select
insert into student2 select *from student;

此处的select查询的结构,得到的和你插入的那个表,得能对应(列的数目、类型、约束得匹配)

三、查询
1、聚合查询
查询的时候带表达式,本质上是用在列和列之间进行运算。
还有的时候,我们需要在行和行之间进行运算,这时候表达式查询就完全不行了。我们的聚合查询就是为了解决行与行之间的查询。
| 函数 | 说明 |
|---|---|
count([distinct] expr) |
返回查询到的数据的 数量 |
sum([distinct] expr) |
返回查询到的数据的 总和 |
avg([distinct] expr) |
返回查询到的数据的 平均值 |
max([distinct] expr) |
返回查询到的数据的 最大值 |
min([distinct] expr) |
返回查询到的数据的 最小值 |
select count(*) from student_scores;
select count(name) from student_scores;
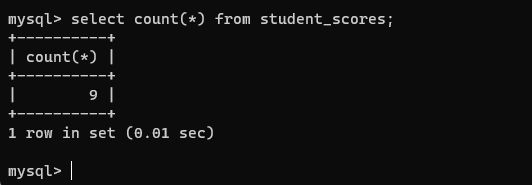
注意:在 sql 中聚合函数和()必须要紧紧的挨在一起。
select sum(math) from student_scores;
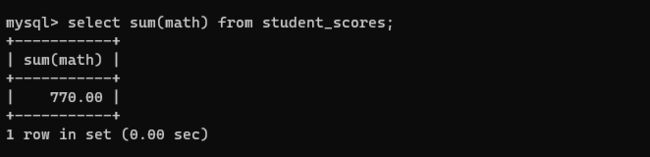
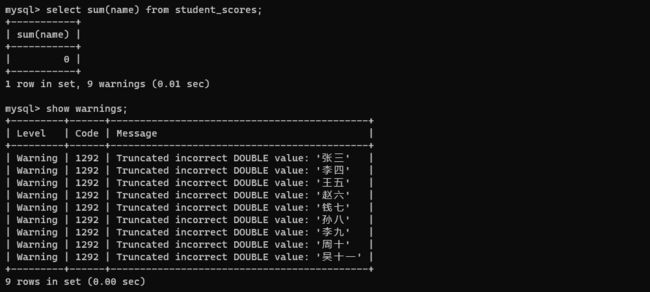
sum 是进行求和,会把这一列的若干行强行先转化为 double ,如果是字符类型就会出现问题。
 通过
通过 show warnings可以查看警告信息。
2、分组查询
group by 会指定一个列,按照这一列进行分组。这一列中,数值相同的行会被放到一组。每个分组中,都可以使用聚合函数进行计算。

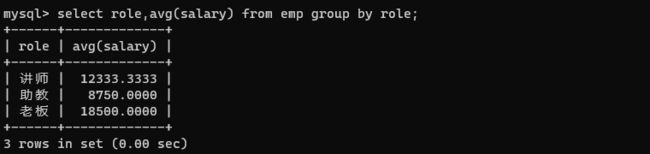
查询出每个岗位的平均薪资。此处可以用 role 进行分组,把 role 相同的放到一组。
select role,avg(salary) from emp group by role;
在分组查询中,select 中指定的列必须是当前 group by 指定的列,如果 select 中想用到其他的列,其他的列必须要放到聚合函数中,否则没有意义。
select role,name,avg(salary) from emp group by role;
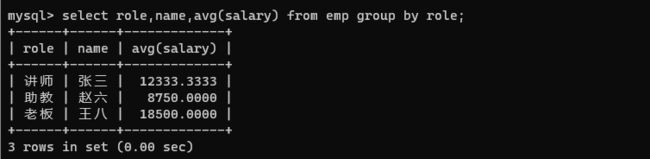
例如这样,就没有意义。role 其实只有三种情况,但是 name 有 6 个,按照上述的查询,只能现实三个结果,所以没有任何意义。此处现实的三个名字,是每组的第一个名字。没有任何意义。
分组查询也是可以搭配条件来使用的。这里的条件有两种情况
- 分组之前的条件:
where
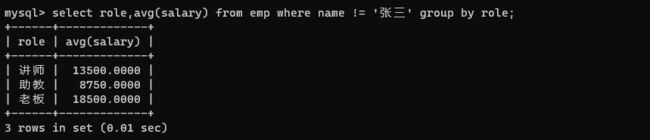
求每个岗位的平均薪资,但是除去张三的薪资。
select role,avg(salary) from emp where name != '张三' group by role;
- 分组之后的条件:
having
求每个岗位的平均薪资,除去平均薪资超过 18000 的。
select role ,avg(salary) from emp group by role having avg(salary) < 18000;

一个 sql 中可以同时包含分组前的条件和分组后的条件。
求每个岗位的平均薪资,除去张三和平均薪资超过 18000 的。
select role ,avg(salary) from emp where name !='张三' group by role having avg(salary) < 18000;

3、联合查询
查询中最复杂的写法。联合查询也叫多表查询,是针对多张表进行查询。
【笛卡尔积】数学上的运算,描述了多表查询的基本执行逻辑。
笛卡尔积,其实就是把两个表里的记录,按照排列组合的方式,构造成了一个更大的表了,笛卡尔积的列数,其实就说原来两个表的列数之和。笛卡尔积的行数,就是原来两个表的行数之积。
笛卡尔积是一个非常低效的操作,所以联合查询也是一个非常低效的操作。
实际开发中,使用联合查询一定要非常慎重。
-- 创建班级表
CREATE TABLE Classes (
ClassID INT PRIMARY KEY,
ClassName VARCHAR(50) NOT NULL,
CreateDate DATE
);
-- 插入班级数据
INSERT INTO Classes (ClassID, ClassName, CreateDate) VALUES
(1, '高一1班', '2023-01-01'),
(2, '高一2班', '2023-02-01'),
(3, '高二1班', '2023-03-01');
-- 创建学生表
CREATE TABLE Students (
StudentID INT PRIMARY KEY,
Name VARCHAR(100) NOT NULL,
ClassID INT,
EnrollmentDate DATE,
FOREIGN KEY (ClassID) REFERENCES Classes(ClassID)
);
-- 插入学生数据
INSERT INTO Students (StudentID, Name, ClassID, EnrollmentDate) VALUES
(1, '王小明', 1, '2023-01-15'),
(2, '李芳', 1, '2023-01-20'),
(3, '张强', 2, '2023-02-10'),
(4, '刘婷', 3, '2023-03-05');
-- 创建课程表
CREATE TABLE Courses (
CourseID INT PRIMARY KEY,
CourseName VARCHAR(50) NOT NULL
);
-- 插入课程数据
INSERT INTO Courses (CourseID, CourseName) VALUES
(1, '数学'),
(2, '历史'),
(3, '物理');
-- 创建分数表
CREATE TABLE Scores (
StudentID INT,
CourseID INT,
Score INT,
PRIMARY KEY (StudentID, CourseID),
FOREIGN KEY (StudentID) REFERENCES Students(StudentID),
FOREIGN KEY (CourseID) REFERENCES Courses(CourseID)
);
-- 插入分数数据
INSERT INTO Scores (StudentID, CourseID, Score) VALUES
(1, 1, 85),
(1, 2, 90),
(2, 1, 78),
(2, 2, 88),
(3, 2, 92),
(4, 3, 80);
查看学生表和班级表进行笛卡尔积的结果。
内连接
select * from students,classes;
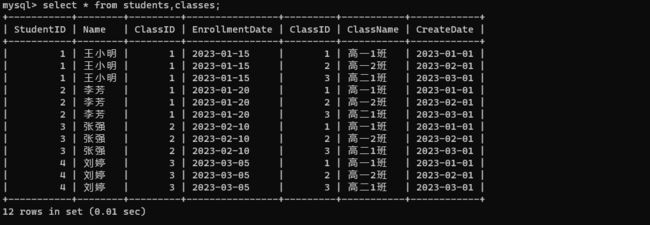
如果是单个表,条件中直接写列名即可。如果是多个表进行查询,那么条件中最好是写 表名.列名。
进行联合查询的这两个表中,有些列名可能是一样的。如果列名没有重复的,此时直接写列名也不是不行,但是最好是带上表名。
select * from students,classes where students.ClassID = classes.ClassID;

笛卡尔积 + 必要的条件 => 多表联合查询
查询王小明同学的成绩:
- 先计算学生表和成绩表的笛卡尔积。
select *from students,scores ;

- 指定连接条件: StudentID 是存在对应关系的,按照 ID 进行筛选。
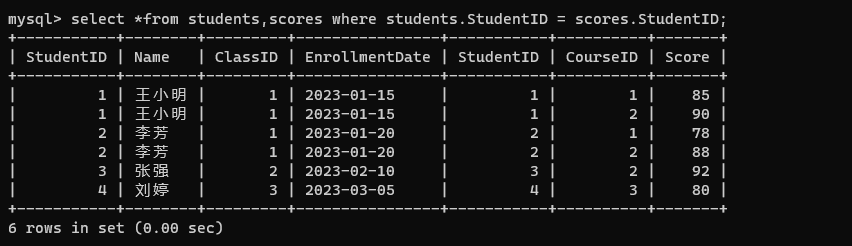
select *from students,scores where students.StudentID = scores.StudentID;
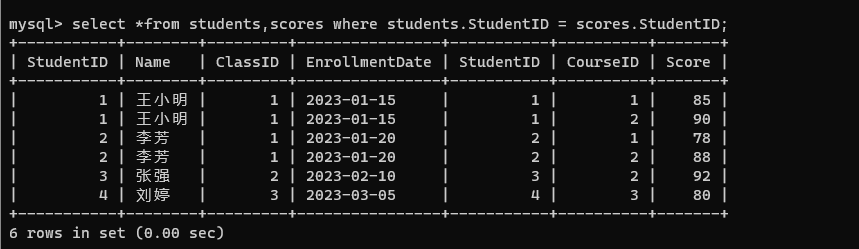
当前筛选后的就是每个同学每门课的成绩。
- 根据需求添加条件,按照名字为王小明再进行筛选。
select *from students,scores where students.StudentID = scores.StudentID and students.name = '王小明';

- 针对查询的结果的列进行精简。
select students.name,scores.score from students,scores where students.StudentID = scores.StudentID and students.name = '王小明';

查询所有同学的总成绩:
每个同学可以有很多课程,这几门课的成绩是按行来组织的。
- 先计算学生表和成绩表的笛卡尔积。
select * from students,scores;
- 指定连接条件: StudentID 是存在对应关系的,按照 ID 进行筛选。
select *from students,scores where students.StudentID = scores.StudentID;
- 根据需求添加条件,按照学生维度进行 group by
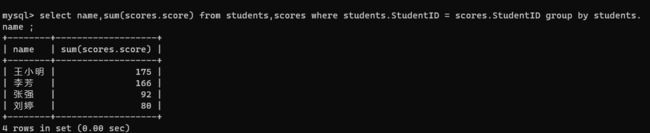
select *from students,scores where students.StudentID = scores.StudentID group by students.name ;

- 搭配聚合函数,针对分数进行计算
select name,sum(scores.score) from students,scores where students.StudentID = scores.StudentID group by students.
name ;
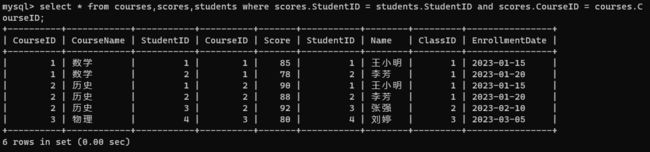
查询所有同学的总成绩,及同学的个人信息(列出名字、课程、分数):
- 先计算学生表和成绩表,课程表的笛卡尔积。
select * from courses,scores,students;
- 指定连接条件: 分数表是学生表和课程表的关联表。此处三个表进行笛卡尔积筛选数据,就需要两个连接条件。
select * from courses,scores,students where scores.StudentID = students.StudentID and scores.CourseID = courses.C
ourseID;
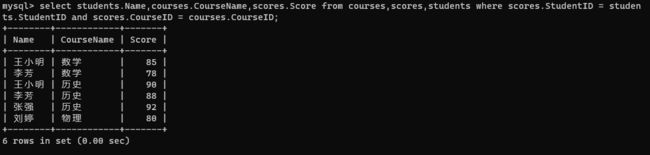
- 根据需求添加条件
select students.Name,courses.CourseName,scores.Score from courses,scores,students where scores.StudentID = studen
ts.StudentID and scores.CourseID = courses.CourseID;
select students.Name as '姓名',courses.CourseName as '课程',scores.Score as '分数'from courses,scores,students wh
ere scores.StudentID = students.StudentID and scores.CourseID = courses.CourseID;
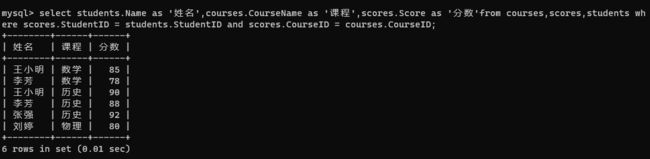
前面的写法都是内连接的写法,内连接除了这种写法外还有一种写法,那就是使用 inner join 其中 inner可以省略。前面使用 ,分割,现在使用 join分割,前面的连接方式使用 where,现在使用 on来指定。
查询王小明同学的成绩:
- 直接只写 join 没有 on 则是一个完整的笛卡尔积
select * from student join score;
- 使用
on表示连接条件
select * from students join scores on students.StudentID = scores.StudentID;
- 根据需求添加条件
select * from students join scores on students.StudentID = scores.StudentID and students.name = '王小明';
- 对列进行精简
select students.name,scores.score from students join scores on students.StudentID = scores.StudentID and students.name = '王小明';
外连接
join on还可以用来表示外连接。
内连接和外连接有什么区别?内连接(Inner Join)和外连接(Outer Join)是 SQL 中用于联接表格的两种主要方法。它们之间的主要区别在于如何处理未匹配的行。
- 内连接(Inner Join):
- 内连接只返回两个表之间匹配的行,即满足连接条件的行。
- 如果在一个表中找不到匹配的行,那么这些行将被忽略,不会出现在结果集中。
- 内连接使用 INNER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
INNER JOIN Classes ON Students.ClassID = Classes.ClassID;
- 左外连接(Left Outer Join):
- 左外连接返回左边表(即在 FROM 关键字之前的表)中的所有行,以及右边表中与左边表匹配的行。
- 如果在右边表中找不到匹配的行,那么将在结果中显示 NULL 值。
- 左外连接使用 LEFT JOIN 或 LEFT OUTER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
LEFT JOIN Classes ON Students.ClassID = Classes.ClassID;
- 右外连接(Right Outer Join):
- 右外连接与左外连接相反,返回右边表中的所有行,以及左边表中与右边表匹配的行。
- 如果在左边表中找不到匹配的行,那么将在结果中显示 NULL 值。
- 右外连接使用 RIGHT JOIN 或 RIGHT OUTER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
RIGHT JOIN Classes ON Students.ClassID = Classes.ClassID;
- 全外连接(Full Outer Join):
- 全外连接返回左右两个表中的所有行,如果没有匹配的行,将在结果中显示 NULL 值。
- 全外连接使用 FULL JOIN 或 FULL OUTER JOIN 关键字。
- 示例:
SELECT Students.StudentID, Students.Name, Classes.ClassName
FROM Students
FULL JOIN Classes ON Students.ClassID = Classes.ClassID;
总的来说,内连接只返回匹配的行,而外连接则返回匹配的行以及未匹配的行,用 NULL 值表示未匹配的部分。选择使用哪种连接取决于你的需求和数据关系。
内连接产生的结果,一定是两个表中都存在的数据(公共部分)
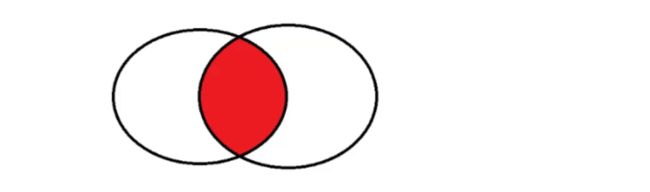
外连接中,在 MySQL 里面有两种情况。左外连接 left join 和右外连接 right join。
左外连接就是以左侧的表为主,左侧表的每一个记录值都会存在于结果中,如果遇到了左侧表存在,但是右侧表不存在的值,此时就会把对应的列变为空值。
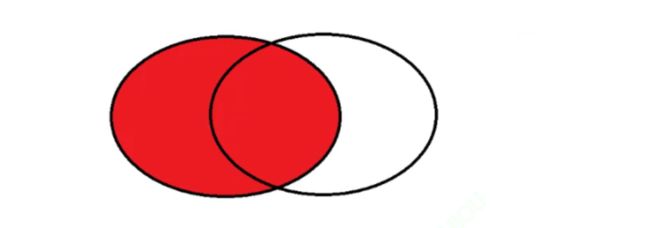
右外连接,就是以右侧为主。


select *from s1 join c1 on s1.id = c1.id;

select *from s1 left join c1 on s1.id = c1.id;
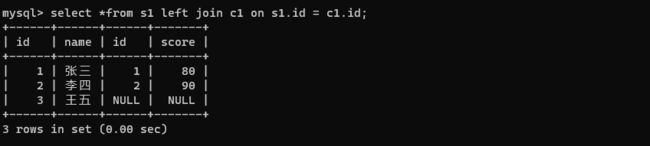
select *from s1 right join c1 on s1.id = c1.id;

自连接
本质上是自己和自己做笛卡尔积。
自连接本质是把行之间的关系,转化为列之间的关系。SQL 中,编写条件,条件都是列和列之间进行比较。但是 SQL 无法直接进行行和行之间的比较。
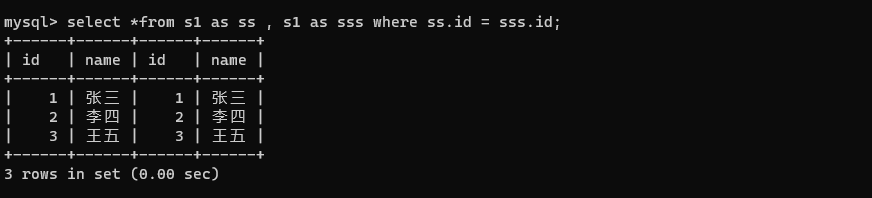
select *from s1 as ss , s1 as sss;
select多个表的时候,名字不能相同,以此需要取别名进行区分。

select *from s1 as ss , s1 as sss where ss.id = sss.id;
4、合并查询
把多个select查询得到的结果集合合并成一个集合。
关键字:union和 union all
select * from s1 union select * from s2;

能合并的前提是这两个查询的结果集是对应的。
select * from s1 union all select * from s2;
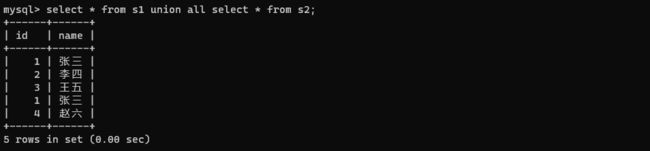
union all不会去重,而union会进行去重。