倒排索引的理论和代码实现
一、倒排索引概念
- 倒排索引常使用在搜索引擎当中,是搜索引擎为文档内容建立索引,实现内容快速检索必不可少的数据结构
- 倒排索引是由单词的集合“词典”和倒排列表的集合“倒排文件”组成的
- 倒排索引的存储:内存索引和B+树索引
- 理解正排索引结构和倒排索引结构;掌握词典、倒排项,倒排列表的具体实现
我们在打开搜索网站,我们输入关键字以后,浏览器作为客户端把关键字发到对应的搜索引擎服务器server端,服务器去分析这个关键字,在全网几千万,乃至上亿个所有html网页中快速找到我们想要的内容,然后把相关的页面发送给客户端
既然要搜索海量的网页,如果在数据库花费磁盘I/O去搜索,那应该花费很长事件吧?
其实不是的,服务器可以在ms级别的时间内把页面给我们返回回来,这都是因为搜索引擎(比如ElasticSearch)的服务器会提前对全网的页面的内容进行分词,看看有哪些关键字,对这些关键字建立了倒排索引,利用倒排索引搜索所有出现过关键字的html页面
比如我们有两个文档(好比是两个html页面)

正排索引结构如下: 行表示文档,列表示关键词key

如果使用正排索引,我们遍历的时候都是按行遍历,看google是否出现在当前行,需要遍历完所有的文档,才能知道关键词engine在哪些文档中出现,效率太低
由于我们都是用关键字搜索,那我们把关键字作为行,文档作为列,这就是倒排索引:

这样我们就能在 O ( 1 ) O(1) O(1)的时间内知道,关键词engine在哪些文档中出现
搜索引擎会把各个文档排一个优先级,按照优先级给用户展示,优先级会和很多因素相关:比如竞价、关键词匹配程度、关键词在html页面的出现频率、网站权威性等等
还可以记录关键词在文档中出现的位置,提取该位置前后的内容,作为摘要展示给用户

二、应用场景
我们使用电商平台搜索时,商品是海量的,由于SQL的查找效率低,而且数据保存在磁盘上,读取到内存也慢,所以不可能直接在数据库中查找
我们都是使用搜索引擎solr、elastic search进行全文搜索
全文搜索:对文档(HTML页面)中的所有句子或词语建立索引,提供快速检索功能。全文搜索包括两种功能,全文本匹配搜索(BF/KMP)、利用倒排索引进行全文搜索
三、倒排索引结构
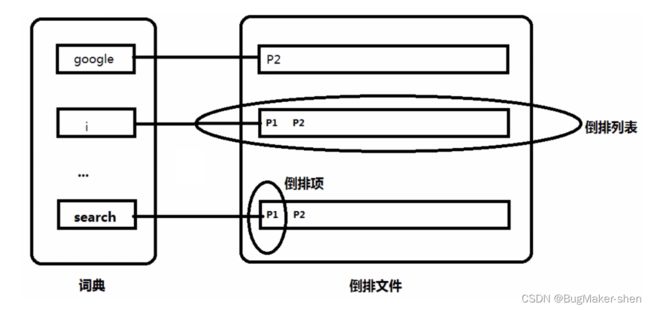
词典:倒排索引结构的左边那一部分,包含了从所有文档中抽取出来的关键字
倒排项:关键词所在文档的描述信息,也就是图中的P1、P2,包括文档的id、关键词出现频率、关键词出现的位置
倒排列表:关键词可能会出现在很多文档中,这些关键词对应的倒排项集合就是倒排列表
倒排文件:由很多倒排列表组成,用于数据持久化
倒排文件存在磁盘上的数据进行持久化,我们把磁盘上的数据读出来,组织在B+树上,磁盘I/O次数少,搜索速度快,我们实际使用倒排索引的时候,我们直接把倒排索引存到数据库就可以了,关系型数据库天然的实现了磁盘的读取,B+树的结构,我们就不用自己实现了
使用倒排索引搜索的方法:
- 搜索单个单词:直接在词典里找到这个单词,然后就可以找到所有的倒排项,就能知道这个单词出现在哪些文档里,出现的频率以及位置等信息
- 搜索一个句子:比如我们搜索“search google”,搜索引擎会按照一定的分词算法进行分词,根据分词的结果到词典中进行匹配,然后获取关键词的倒排项,最终需要给所有的倒排项打分并展示给用户。比如可以先求倒排列表交集,然后判断单词在文档中的位置来计算匹配程度,最终得到展示给用户的优先级
搜索注意事项:无论用户搜索单数还是复数,大写还是小写,我们都应该给出语义上能够匹配的结果。用户用小写搜索,我们也需要把大写给展示给用户,用户用单数搜索,我们需要把复数给展示给用户。还有包括近义词等都需要注意展示给用户

#include
#include
#include