【论文翻译】A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects
原文地址:https://arxiv.org/ftp/arxiv/papers/2004/2004.02806.pdf
摘要
卷积神经网络(CNN)是深度学习领域最重要的网络之一。由于 CNN 在 许多领域取得了令人瞩目的成就,包括但不限于计算机视觉和自然语言处理,它在过去几年中引起了业界和学术界的广泛关注。现有的评论主要集 中在 CNN 在不同情景下的应用,没有从一般的角度来考虑 CNN,而且最近提出的一些新颖的想法也没有包括在内。在这篇综述中,我们的目标是 在这个快速发展的领域提供尽可能多的新想法和前景。此外,不仅仅是二维卷积,还包括一维和多维卷积。首先,这篇综述从简单介绍 CNN 的历史开始。其次,我们提供了 CNN 的概述。第三,介绍经典和先进的 CNN 模型,特别是那些使它们达到最先进的结果的关键点。第四,通过实验分析,我们得出了一些结论,并为函数选择提供了一些经验法则。第五,介绍了一维、二维和多维卷积的应用。最后,讨论了 CNN的一些公开问题和有希望的方向,作为未来工作的指导方针。
关键词:深度学习,卷积神经网络,深度神经网络,计算机视觉。
I.引言
卷积神经网络(CNN)已经取得了辉煌的成就。它已经成为深度学习领域最具代表性的神经网络之一。基于卷积神经网络的计算机视觉技术使人们能够完成在过去几个世纪被认为是不可能完成的任务,如人脸识别、自动驾驶汽车、自助超市和智能医疗。为了更好地理解现代卷积神经网络,使其更好地为人类服务,本文对 有线电视新闻网络进行了综述,介绍了经典的模型和应用,并对CNN的发展前景进行了展望。卷积神经网络的出现离不开人工神经网络(ANN)。 1943 年,McCulloch和 Pitts [1]提出了第一个神经元数学模型-MP 模型。在 20 世纪 50 年代末和 60 年代初,Rosenblatt [2] ,[3]提出了一个单层感知器模型, 通过增加学习能力的 MP 模型。但是,单层感知器网络不能处理线性不可分离的问题(如异或问题)。1986 年, Hinton 等[4]提出了一种基于误差反向传播算法训练的多层前馈网络 —— BP 网络,解决了单层感知器无法解决的题。1987 年, Waibel 等[5]提出了用于语音识别的时滞神经网(TDNN) ,它可以看 作是一维卷积神经网络。然后,Zhang [6]提出了第一个二维卷积神经网络ー Shift-invariant Artificial Neural Network(SIANN)。LeCun等[7]于 1989 年还构建了一个用于手写邮政编码识别的卷积神经网络,并首次使用了“卷积” 这个术语,这是LeNet的原始版本。在 20 世纪 90 年代,先后提出了 各种浅层神经网络,如混沌神经网络[8]和广义回归神经网络[9],最著名的是 LeNet-5[10]。然而,当神经网络的层数增加时,传统的 BP网络会遇到局部最优、过拟合、梯度消失和梯度爆炸等问题。2006 年, Hinton 等[11]提出了以下观点: 1)多隐层人工神经网络具有优良的特征学习能力; 2)分层预训练能有效地克服训练深层神经网络的困难,从而带来了深度学习的研究。2012 年,Alex 等[11]在 ImageNet 大规模视觉识别挑战(LSVRC)中利用深度CNN获得了当时最好的分类结果,引起了研究人员的广泛关注,极大地促进了现代CNN的发展。
在我们的工作之前,有几位研究人员回顾了CNN。Aloysius 等[12]注意深度学习的框架按时间顺序排列。尽管如此,他们没有充分解释为什么这些架构比他们的前辈更好,以及这些架构如何实现他们的目标。Dhillon 等[13]讨论了一些经典网络的体系结构,但也有许多新一 代网络,在他们的工作之后,已经提出,如MobileNet v3,Inception v4,和ShuffleNet 系列,值得研究人员的注意。此外,这项工作还回顾了CNN在物体检测方面的应用。Rawat等[14]审查了CNN的图像识别。Liu 等[15]讨论了CNN的图像识别。Ajmal等[16]讨论了CNN用于图像分割。上面提到的这些评论主要回顾了CNN在不同情况下的应用,而没有从一般的角度考虑CNN。另外,由于CNN的快速发展,在这个领域已经提出了许多鼓 舞人心的想法,但是这些评论并没有完全涵盖它们。
本文主要对CNN进行分析和探讨。本文的主要贡献如下: 1)简要介绍了CNN,包括现代CNN的一些基本组成部分,其中涉及到一些引人入胜的卷积结构和创新。2)一些经典的基于cnn的模型被涵盖,从LeNet-5,AlexNet到MobileNet v3和GhostNet。这些模型的创新强调帮助读者从杰作中获得一些有用的经验。3)讨论了几个具有代表性的激活值函数、损失函数和优化器。我们通过实验得出了一些结论。 4)尽管二维卷积的应用广泛,但一维和多维卷积的应用不容忽视。给出了一些典型的应用。5)我们对CNN的发展前景提出了几点看法。其 中一部分是为了完善现有的CNN,另一部分则是从零开始创建新的网络。
我们将本文的其余部分组织如下: 第二节概述了现代CNN。第三部分介绍了许多有代表性的和经典的基于CNN的模型。我们主要关注这些模型的创新,但不是所有的细节。第四部分讨论了一些代表性的激活值函数、损失函数和优化器,这些可以帮助读者正确地选择它们。 第五部分从不同维度卷积的角度介绍了CNN的一些应用。第六部分讨论了当前的挑战以及CNN未来工作的几个有希望的方向或趋势。第七部分通过对我们贡献的鸟瞰来结束这次调查。 它可以在保留有用信息的同时减少数据量。
II.CNN 简要概述
卷积神经网络是一种能够从具有卷积结构的数据中提取特征的前馈神经网络。与传统的特征提取方法[17] ,[18] ,[19]不同,CNN不需要手动提取特征。CNN的架构是受视知觉的启发[20]。生物神经元对应于人工神经元; CNN内核代表不同的受体,可以对各种特征作出反应; 激活值函数模拟只有超过某个阈值的神经电信号才能传递给下一个神经元的功能。损失函数和优化器是人们为了教会整个 CNN 系统学习我们所期望的东西而发明的。与一般的人工神经网络相比,CNN 有许多优势: 1)局部连接。每个神经元不再与前一层的所有神经元连接,而只与少数神经元连接,这有效地减少了参数,加快了收敛速度。一组连接可以共享相同的权重,这进一步减少了参数。3)向下采样降维。 池化层利用图像局部相关原理对图像进行下采样, 它可以在保留有用信息的同时减少数据量。它还可以通过移除琐碎的特征来减少参数的数量。这三个吸引人的特点使得CNN成 为深度学习领域最具代表性的算法之一。
具体来说,为了建立一个CNN模型,通常需要四个组件。卷积是特征提取的关键步骤。卷积的输出可以称为特征映射。当设置一个具有一定大小的卷积核时,我们会在边界处丢失信息。因此,引入了填充来放大零值的输入,这样可以间接地调整大小。此外,为了控制卷积的密度,采用了跨步。步幅越大,密度越低。卷积之后,特征映射由大量容易导致过度拟合问题的特征组成[21]。因此,池化[22](又称下采样)被提出以消除冗余,包括最大池化和平均池化。CNN的程序如图 1 所示。

此外,为了使卷积核感知更大的面积,提出了扩展卷积[23] 3x3 卷积核如图 2(a)所示,并且步长为2的3x3卷积核和 步长为4的3 × 3卷积核如图 2(b)和(c)所示。注意,在每个卷积核点之间有一个空值(填充为零)。即使有效核点仍为 3×3, 步长为的2的卷积仍有7×7个感受野,步长为4的卷积有15×15个感受野。
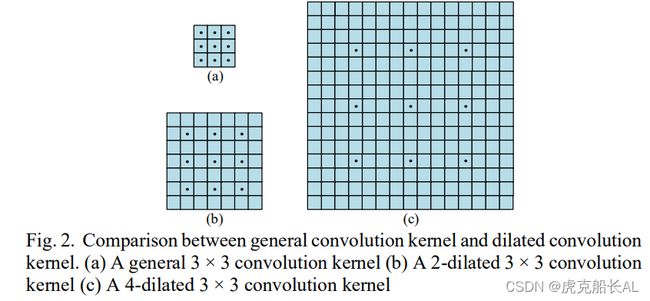
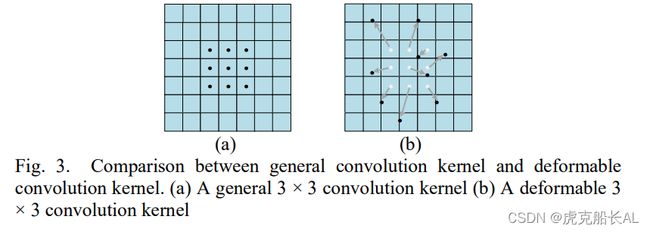
池化层利用图像局部相关原理对图像进行下采样, 如图 3 所示,可变形卷积[23]被提出来处理现实世界中物体的形状通常是不规则的问题。可变形卷积只能关注他们感兴趣的东西,使得特征映射更具代表性。
此外,还存在各种令人敬畏的卷积网络,如可分卷积[24] ,[25] ,[26] , [27] ,[28] ,群卷积[11] ,[29] ,[30] ,[31]和多维卷积,这些都在第 3 节和第 5 节中讨论。
III.经典 CNN 模型
自 2012 年提出 AlexNet 以来,研究人员已经发明了各种CNN模 型——更深、更宽、更轻。部分著名的模型可以在图 4 中看到。由于 论文篇幅的限制,本节旨在概述几种有代表性的模式,并着重讨论它们的创新之处,以帮助读者理解要点,并提出自己有希望的想法。

A. LeNet-5
LeCun 等[10]于1998 年提出了 LeNet-5,这是一种用后向传播算法训练的高效卷积神经网络,用于手写体字符识别。如图 5 所示,lenet-5 由包含两个卷积层、两个池化层和三个完全连接层 的七个可训练层组成。Lenet-5是一种先进的卷积神经网络,它结合了局部接受域、共享权值和时空子采样,在一定程度上保证了平移、尺度和失真不变性。它是现代CNN的基础。尽管 lenet-5算法在手写体字符识别和银行支票阅读方面具有一定的应用价值, 但它仍然不能超越传统的支持向量机(SVM)和增强算法。因此, lenet-5 在当时并没有得到足够的重视。

B. AlexNet
Alex 等 [11] 在 2012 年 提 出 了 AlexNet ,它在2012年 ImageNet 比赛中赢得了冠军。如图 6 所示,AlexNet有八层,包含五个卷积层和三个全连接层。

AlexNet将LeNet的思想发扬光大,并将CNN的基本原理应用于一个深广的网络。它首次在CNN上成功地利用了ReLU激活函数、dropout和局部归一化(LRN)。与此同时, AlexNet也利用GPU进行加速计算。AlexNet的主要创新在于:
- AlexNet 使用ReLU作为CNN的激活函数,这缓解了网络深度时梯度消失的问题。尽管ReLU激活函数早在AlexNet出现之前就已经被提出,但是直到AlexNet出现之后它才被继续使用。
- 在训练过程中,AlexNet使用Dropout随机忽略一些神经元, 以避免过度拟合。这种技术主要用于最后几个完全连接的层。
- 在卷积层的AlexNet中,重叠最大池化被用来代替以往卷积神经网络中常用的平均池化。最大池化可以避免平均池化的模糊结果,而重叠池化可以提高特征的丰富性。
- 本文提出用LRN模拟生物神经系统的侧抑制机制,即神经元接受刺激可以抑制外周神经元的活动。同样,LRN能使小值神经元被抑制,大值神经元相对活跃,其功能与归一化非常相似。因此,LRN是提高模型泛化能力的一种方法。
- AlexNet还使用了两个强大的GPU来训练组卷积。由于一个GPU的计算资源有限,AlexNet设计了一个群卷积结构,可以在两个不同的GPU上进行训练。然后,由两个GPU生成的两个特征映射可以合并为最终输出。
- AlexNet在训练中采用了两种数据增强方法。第一种方法是从原始的256×256图像及其水平反射中提取随机的224× 224的块,以获得更多的训练数据。此外,利用主元分析(PCA)改变训练集的RGB值。在进行预测时,AlexNet还会扩大数据集,然后计算出它们的预测平均值作为最终结果。AlexNet表明,使用数据增强可以大大减轻过拟合问题,提高泛化能力。
C. VGGNets
VGGNets [32]是牛津大学视觉几何组提出的一系列卷积神经网络算法,包括 VGG-11、 VGG-11-lrn、 VGG - 13 vgg-16 和 VGG-19。VGGNets 在 2014 年 ImageNet 定位挑战赛上获得第一名。VGGNets 的作者证明,增加神经网络的深度可以在一定程度上提高网络的最终性能。与 AlexNet相比,VGGNets 有以下改进:
- 因为VGGNets的作者发现LRN对深层CNN的影响并不明显,所以LRN层被移除了。
- VGGNets采用3×3的卷积核,而不是5×5或超过5×5的卷积核,因为几个小核与大核相比具有相同的感受野和更多的非线性变化。例如,3×3的内核的感受野与一个5×5个内核的感受野相同。然而,参数的数量减少了约45% ,三个核有三个非线性变化。
D. GoogLeNet
GoogLeNet [33]是 ILSVRC 2014 图像分类算法的获胜者。它是第 一个通过Inception模块形成的大规模 CNN。Inception 网络有四个版本,即 Inception v1[33]、 Inception v2[34]、[35]、 Inception v3[35]和 Inception v4[36]。
1) Inception v1
由于图像中的物体与摄像机的距离不同,一个图像比例较大的物体通常倾向于较大的卷积核或较小的卷积核。然而,图像中的小物体恰恰相反。 根据过去的经验,大卷积核有很多参数需要训练,而深层网络很难训练。因此,Inception v1[33]部署了1×1,3x3,5×5卷积核构造一个“宽”网络,如图 7 所示,不同尺寸的卷积核可以提取图像的不同尺度的特征映射。然后,将这些特征映射进行叠加, 以获得更具代表性的特征映射。此外,使用1×1的卷积核来减少通道的数量,即减少计算成本。

2) Inception v2
Inception v2[35]利用批处理归一化来处理数据内部分布不一致问题[34]。将各层的输出归一化为正态分布,提高了模型的鲁棒性,使模型具有较大的学习速率。此外,Inception v2 显示一个5×5的卷积层可以被两个3×3的卷积层取代,如图 8(a)所示。一个 n×n卷积层可以被一个1×n和 一个n×1卷积层替换,如图 8(b)所示。然而,原始论文指出,在早期层中使用因子分解是不有效的。最好在中等大小的特征映射上使用它。过滤器库应该扩大(更广泛但不是更深)以改善高维表示。因此, 每个图像只有最后的3×3卷积分支被分解,如图 8(c)所示。

3) Inception v3
Inception v3[35]集成了Inception v2中提到的主要创新。并将5×5和3×3个卷积核分解为两个一维卷积核(分别为1×7 和7×1、1×3和3×1)。这种操作加速了训练,进一步增加了网络的深度和网络的非线性。此外,网络的输入大小从224× 224变为299×299。 而且Inception v3使用RMSProp作为优化器。
4) Inception v4 和 Inception-ResNet
Inception v4模块[36]是基于Inception v3的模块。Inception v4的架构更简洁,使用了更多的Inception模块。实验评估证明了Inception v4比它的前辈更好。
此外,ResNet结构[37]被用来扩展Inception网络的深度,即Inception-ResNet-v1和Inception-ResNet-v2。实验证明,它们可以提高训练速度和性能。
E. ResNet
从理论上讲,深层神经网络(DNN)优于浅层神经网络,因为深层神经网络能够提取更复杂、更充分的图像特征。然而,随着层数的增加, DNNs容易导致梯度消失,梯度爆炸等问题。He等[37]在2016年提出了一个34层残差网络,它是ILSVRC 2015图像分类和物体检测算法的获胜者。ResNet的性能超过了 GoogLeNet Inception v3。
ResNet的一个重要贡献是由快捷连接构造的两层残差块, 如下图 9(a)所示。

50层ResNet,101层ResNet和152层ResNet使用三层剩余块, 如上图 9(b)所示,而不是两层一。三层剩余块也称为bottleneck模块,因为块比中间窄。使用1×1的卷积核不仅可以减少网络中的参数数量, 而且可以极大地改善网络的非线性。
[37]中的大量实验证明,由于梯度可以直接通过快捷连接流动,因此在深层神经网络中,ResNet 能够在不退化的情况下 缓解梯度消失问题。
在ResNet的基础上,许多研究成功地提高了原有ResNet的性 能,如预激活 ResNet [38]、宽 ResNet [39]、随机深度 ResNet (SDR)[40]和ResNet中的ResNet (RiR)[41]。
F. DCGAN
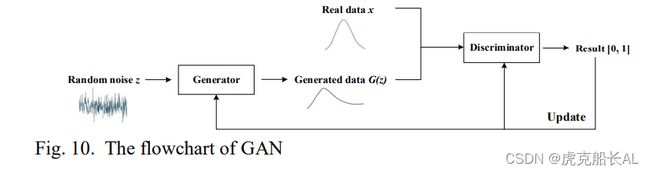
生成性对抗网络(GAN)[42]是Goodfellow等人在2014年提出的一个无监督模型。GAN包含生成模型g和判别模型d。具有随机噪声z的模型g生成受g学习的数据分布Pdata影响的样本g (z)。模型d可以确定输入样本是真实数据x还是生成的数据 g (z)。g和d 都可以是非线性函数,如深度神经网络。g的目的是生成尽可能真实的数据, 而d的目的是区分g生成的假数据和真数据。生成性网络和歧视性网络之间存在有趣的对抗关系。这种观点来源于博弈论,在博弈论中, 双方使用各自的策略来实现获胜的目标。这个过程如图 10 所示。
Radford 等[43]在 2015 年提出了深度卷积生成对抗网络(DCGAN)。 利用深度卷积神经网络实现了大规模场景理解数据集上的 DCGAN 生 成器,其结构如下图所示。

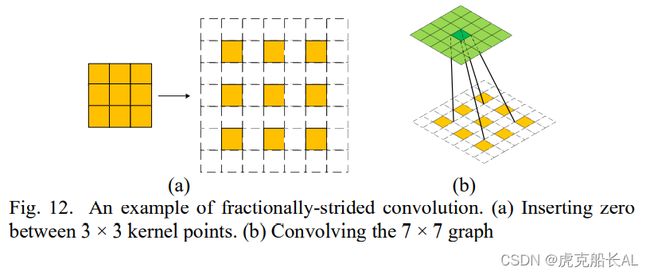
在图 11 中,DCGAN的生成模型通过“分数步进卷积”执行上采样。如图 12(a)所示,假设有一个3×3的输入,并且输出的大小预期大于3×3,那么3×3的输入可以通过在像素之间插入零来扩展。在扩展到5×5尺寸之后,进行卷积,如图 12(b)所示, 可以得到大于3×3的输出。
G. MobileNets
MobileNets是谷歌为移动电话等嵌入式设备提出的一系列轻量级模型。它们使用深度可分离的卷积和一些先进的技术来构建薄的深度神经网络。迄今为止,MobileNet 有三个版本,即 MobileNet v1[44] ,MobileNet v2[45]和 MobileNet v3[46]。
1) MobileNet v1
MobileNet v1[44]利用 Xception [26]中提出的深度可分卷积,将标准卷积分解为深度可分卷积和点向卷积(1×1卷积) ,如图 13 所示。 具体而言,标准卷积将每个卷积核应用于所有输入通道。相比之下,深度卷积将每个卷积核应用于一个输入通道,然后用1×1卷积合并深度卷积的输出。这种分解可以大大减少参数的数量。

MobileNet v1 还引入了宽度乘法器以减少每一层的通道数,并引入分辨率乘法器以降低输入图像(特征映射)的分辨率。
2) MobileNet v2
基于MobileNet v1,MobileNet v2[45]主要介绍了两个 改进: 反剩余块和线性瓶颈模块。
在第 3.5 节中,我们解释了三层剩余块,其目的是利用1×1卷积来 减少3×3卷积所涉及的参数个数。总之,剩余块的整个过程是通道压缩-标准卷积-通道扩展。在 MobileNet v2 中,反向残留块(见图 14(b))与残留块相对(见图 14(a))。首先用1×1个卷积核进行信道扩展,然后用 3 × 3 个深度可分离卷积进行卷积,最后用1×1 个卷积核进行卷积压缩信道数。简而言之,倒置残差块的整个过程是信道扩展ー深度可分卷积ー信道压缩。同时,由于深度可分卷积不能改变通道 的数量,导致输入通道的数量限制了特征提取,因此利用反向残差块来处理这一问题。

在进行通道扩展ー深度可分离卷积ー通道压缩时,会遇到“通道 压缩”后的一个问题。也就是说,在低维空间使用 ReLU 激活函数容易破坏信息,而在高维空间则不会发生。因此,消除了残差块 第二次1×1卷积后的ReLU激活函数,采用线性映射。因此, 这种架构被称为线性瓶颈模块。
3) MobileNet v3
MobileNet v3[46]实现了三个改进: 结合平台感知神经结构搜索(平台感知NAS)和 NetAdapt 算法[47]的网络搜索,基于挤压和激励的轻量级注意模型,以及h-swish激活函数。
对于MobileNet v3,研究人员使用平台感知的 NAS进行块式搜索。平台感知NAS利用基于RNN的控制器和分层搜索空 间来找到全局网络的结构。然后,NetAdapt算法,作为平台感知NAS的补充,被用于分层搜索。它可以通过微调来找到每一层中最佳的过滤器数量。
MobileNet v3利用了挤压和激励(SE)重新加权每一层的通道,以实现轻量级的注意力模型。如图 15 所 示,在倒置残余块的深度卷积之后,加入S模块。首先执行全 局池操作,然后在完全连接的层之后,通道的数量减少到 1/4。第二个完全连接层被用来恢复通道的数量和得到每一层的权重。最后,将权重和深度卷积相乘得到一个重新加权的特征映射。 Howard 等[46]证明,这种操作可以在没有额外时间成本的情况下提高准确性。

MobileNet v3 的作者指出,与ReLU相比,计算swish激活函数可以提高网络的准确性。然而,swish函数的计算成本太高了。因此,他们提出了一个hard swish (h-swish) ,以 减少计算的精度损失很小。然而,他们发现 h-swish 所获得 的好处只在深层,因此 h-swish 只在模型的后半部分被利用。 此外,他们发现sigmoid也可以被hard sigmoid(h-sigmoid)所替代。

H. ShuffleNets
ShuffleNets 是MEGVII提出的一系列基于CNN的模型,用于解决移动设备计算能力不足的问题。这些模型结合了逐点群卷积、通道重排等技术,大大降低了计算量,精度损失很小。到目前为止, ShuffleNet有两个版本,即 ShuffleNet v1[49]和 ShuffleNet v2[50]。
1) ShuffleNet v1
ShuffleNet v1[49]被提出用于为资源有限的设备构建高效的CNN结构。有两个创新: 逐点群卷积和通道重排。
ShuffleNet v1的作者认为Xception [26]和ResNeXt [29]在极小的网络中效率较低,因为1×1卷积需要大量的计算资源。因此,提出逐点群卷积来降低1×1卷积的计算复杂度。逐点群卷积, 如图 17(a)所示,要求每个卷积操作只在相应的输入通道群上进行,这样可以降低计算复杂度。
然而,一个问题是,逐点群卷积抑制了不同组之间的特征映射相互通信,这对提取代表性特征映射是有害的。因此,提出了图 17(b)所示的通道洗牌操作,以帮助不同组中的信息随机流向其他组。

在此基础上,提出了基于通道重排操作的洗牌单元。如下图所示,图 18(a)是具有深度卷积(DWConv)的单纯残余块; 图 18(b)用 标准卷积取代了标准卷积计算经济的逐点群卷积(GConv)和通道重排。此外,去掉了第二个ReLU激活函数,在图 18(c)中,在快捷路径中使用了一个3×3的两步平均池化,并用级联代替了元素级加。这些技巧进一步减 少了参数的数量。图 18(c)是最终ShuffleNet单元的架构。

2) ShuffleNet v2
ShuffleNet v2[50]的作者认为,许多网络都是由计算复杂性的度量标准主导的,即FLOPs。尽管如此,由于存储器访问成本(MAC)是另 一个关键因素,因此不应将FLOPs视为评估网络速度的唯一范式。它们提供了一些通过实验设计网络的指导方针,并使用这些指导方针来构建ShuffleNet v2。提出了四点来指导网络设计:
- 通过实验,比较了 ShuffleNet v1[49]和 MobileNet v2 在1×1卷积层的GPU和ARM平台上不同的输入输出信道比,发现当输入通道数与输出通道数相等时,MAC是最小的。
- 改变卷积群的数目对网络训练速度有影响。随着分组数量的增加,MAC增加,训练速度降低。
- 通过调整网络的碎片化结构和每个基本结构中的卷积层数,发现网络碎片化降低了并行度,如 GoogLeNet级数。虽然多个分段结构能够提高准确性,但它们可以降低并行计算能力(如 gpu)的效率。
- Elementwise 操作(如ReLU、张量加法、偏移量加法、分离卷积等)是不可忽略的,也就是说,它们将消耗大量的时间。因此,在设计网络时,研究人员应该尽可能减少元素运算的使用。
- ShuffleNet v2单元是根据以上四条原则设计的。此外,在ShuffleNet v2中提出了通道分裂。对于每个ShuffleNet v2 单元, 通道首先被分成两个分支,即 a 和 b。以下过程的细节可以在图 19(a)中看到。对于空间下采样,该单元稍作修改,细节可以在图 19(b)中看到。
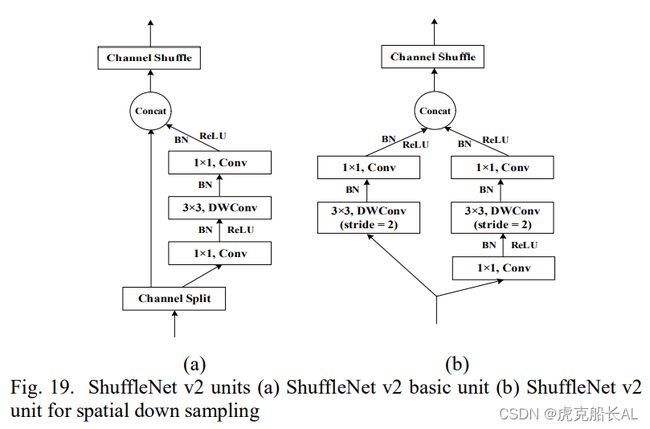
总之,lenet-5是第一个成功应用于手写体数字识别的现代CNN。它的卷积、激活值、池化和完全连接已被广泛使用。AlexNet提出了比lenet-5更深层次的结构,提出了一些技巧,比如dropout和数据增强,以及利用ReLU激活函数。VGGNet 进一步证明了深层网络通常工作得更好,并为网络设计提供了指导。GoogLeNet 系列提出的更广泛的网络也可以工作。 大尺寸的卷积内核可以被小尺寸的内核取代。此外,还采用了因子分解卷积和ResNet算法。ResNet使得极深的网络成为可能,这能够减缓梯度消失。DCGAN结合了CNN和GAN,扩展了两者的实际情况。深度可分卷积、残差块、基于 senet 的轻量级注意模型、平台感知NAS和NetAdapt算法被应用于计算能力有限的移动设备设计。ShuffleNet系列也是为移动设备发明的,它结合了逐点群卷积和通道重排。此外, ShuffleNet证明了除了 FLOPs 之外,MAC是影响网络速度的另一个因素。
I. GhostNet
由于现有的人工神经网络提取了大量冗余特征用于图像认知,Han 等[51]提出了GhostNet来有效地降低计算成本。他们发现在传统的卷积层中有许多类似的特征映射。这些特征映射被称为幽灵。因此,他们利用具有成本效益的GhostNet来达到最先进的结果。两个主要贡献如下:

他们把传统的卷积层分为两个部分。在第一部分中,较少的卷积 核直接用于特征提取,与原始卷积相同。然后,对这些特征进行线性映射处理,获得多个特征映射。他们证明 Ghost 模块适用于其他CNN 模型。
IV. 讨论和实验分析
A. 激活函数
1)激活函数的讨论
卷积神经网络可以利用不同的激活值来表达复杂的特征。与人类大脑的神经元模型的功能类似,这里的激活函数是一个决定哪些信息应该传递给下一个神经元的单位。神经网络中的每个神经元接受前一层神经元的输出值作为输入,并将处理后的值传递给下一层神经元。在多层神经网络中,两层之间有一个函数。这个函数被称为激活函数, 其结构如下图 21 所示。

在这个图中,xi 表示输入特征,n 个特征同时输入到神经元 j,wij 表示输入特征 xi 和神经元 j 之间连接的权重值,bj 表示神经元 j 的内部状态,即偏置值,yj 表示神经元 j 的输出。(∙)表示激活函数,可以 是 s 形函数,tanh (x)函数[10] ,矫正线性单位[52]等 。
如果不使用激活函数或使用线性函数,则每一层的输入将是前一层输出的线性函数。在这种情况下,He 等[38]验证了无论神经网络有多少层,输出总是输入的线性组合,这意味着隐藏层没有影响。这种情况是原始感知器[2] ,[3] ,它具有有限的学习能力。出于这个原因, 非线性函数被引入为激活值。理论上,具有非线性激活函数的深层神经网络可以逼近任意函数,从而大大提高了神经网络对数据的拟合能力。
在本节中,我们主要关注几个常用的激活值函数。首先,sigmoid函数是一个最典型的非线性激活值与总体 s 形函数(见图 22(a))。当 x 值接近 0 时,梯度变得更陡。S 形函数可以映射一个实数到(0,1) ,所以它可以用于二进制分类问题。另外,SENet [48]和 MobileNet v3[46]需要将注意机制的输出值转换为(0,1) ,其中sigmoid是一种很好的实现方法。
与sigmoid结构不同,tanh函数[10](见图 22(b))可以映射一 个实数到(- 1,1)。由于tanh输出的平均值为 0,它可以实现一 种归一化。这使得下一层更容易学习。
此外,Rectified Linear Unit(ReLU)[52](见图 22(c))是另一个有效的激活函 数。当x小于0时,其函数值为0; 当 x 大于或等于0时,其函数值为x本身。与s形函数和tanh函数相比,使用 ReLU 函数的一个显著优点是可以加快学习速度。Sigmoid 和tanh涉及在计算导函数时需要除法的指数运算,而ReLU的导函数是一个常数。此外,在双曲正切函数和双曲正切函数中,如果 x 的值太大或太小,则函数的梯度很小,这会导致函数收敛缓慢。然而, 当x小于0时,ReLU的导函数为0,当x大于0 时,导函数为1, 因此可以得到理想的收敛效果。AlexNet [11]是 ilsvrc-2012 中的最佳模型,它采用ReLU作为基于CNN的模型的激活函数,缓解了网络在深度时的梯度消失问题,验证了ReLU在深度网络中的应用优于Sigmoid 。

从上面讨论的,我们可以发现ReLU没有考虑上限。在实践中,我们可以设置一个上限,如ReLU6[54]。
然而,当x小于0时,ReLU的梯度为0,这意味着向后传播的错误将乘以0,导致没有错误被传递到前一层。在这种情况下,神经元将被视为失活或死亡。因此,提出了一些改进的版本。Leaky ReLU (见图 22(d))可以减少神经元失活。当x小于0 时,Leaky ReLU的输出是/,而不是零,其中‘a’是范围内的一个固定参数(1,+ ∞)。
ReLU的另一个变体是PReLU [38](见图 22(e))。与Leaky ReLU不同,PReLU 负面部分的斜率是基于数据的,而不是预定义的。He等[38]认为PReLU是超越 ImageNet 2012 分类数据集上人类分类水平的关键。
指数线性单位(ELU)函数[55](见图 22(f))是ReLU的另一个改进版本。由于ReLU是非负激活的,其输出的平均值大于0。这个问题将导致下一层单元的偏移量。ELU函数具有负值,因此其输出的平均值接近于0,使得收敛速度比ReLU函数快。然而,负的部分是一条曲线,需要很多复杂的导数。
2)实验评价
为了比较上述激活值,两个经典的CNN模型LeNet-5[10]和VGG-16[32]在四个基准数据集上进行了测试,包括MNIST [10]、 fashion-MNIST[56]、 CIFAR-10[57]和 CIFAR-100[57]。Lenet-5是第一个现代但相对较弱的CNN模型。在接下来的实验中,我们从头开始训练LeNet-5。Vgg-16是一个更深,更大,经常使用的模型。我们进行我们的实验基于预先训练的 vgg-16模型,没有ImageNet上的最后三层[58]。


我们的实验基于预先训练的vgg-16模型,没有ImageNet上的最后三层[58]。

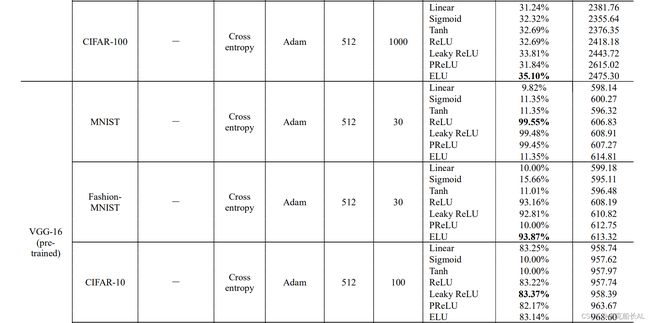

1)MNIST&fashion-MNIST: MNIST是一个由10个类别组成的手写数字数据集,其中有60,000个示例的训练集和 10,000个示例的测试集。每个例子是一个28×28的灰度图像,与10个类的标签相关联,从0到9。Fashion-MNIST数据集是原始MNIST的一个更复杂的版本,共享相同的图像大小、结构和分割。这两个数据集在lenet-5和vgg-16上进行了训练,结果显示在表 i 和 图 23 中。从结果中,我们可以得出一些有意义的结论。
- 线性激活函数确实会导致最坏的结果
- 在这些激活函数中,sigmoid的收敛速度是最慢的。通常情况下,sigmoid的最终表现并不那么出色。因此,如果我们期望快速收敛,sigmoid不是最佳解决方案。
- 从准确度的角度来看,ELU拥有最好的准确性,但只比ReLU、Leaky ReLU, 和PReLU好一点点。在训练时间方面,从表一中可以看出,ELU比ReLU 消耗的时间比ReLU和Leaky ReLU要多。
- ReLU和Leaky ReLU在训练过程中具有较好的稳定性。与PReLU和ELU相比,训练过程中的稳定性更好。
2)Cifar-10和CIFAR-100: cifar-10和cifar-100是8000万个微图像数据集的标记子集[57] ,这些数据集比MNIST和 fashion-MNIST更复杂。Cifar-10数据集由10个类别的60000个32×32RGB图像组成,每个类别有6000个图像。整个数据集分为50000个训练图像和10000个测试图像,也就是说,每个类有 5000个训练图像和1000个测试图像。Cifar-100类似于 CIFAR-10,只是它有100个类,每个类包含600个图像。每个类有500个训练图像和100个测试图像。同样,我们评估 lenet-5和vgg-16在这两个数据集上具有不同的激活值。结果可以在表 I 和图 1 中看到,从中我们可以得出一些结论。
- Tanh、PReLU和ELU的激活值较高有可能在训练结束后带来振荡。
- 当训练一个深层CNN模型的预先训练的权重时,使用sigmoid和tanh激活函数很难收敛。
- 在实验中,由Leaky ReLU和ELU训练的模型比其他模型有更好的准确性。但有时,ELU可能会使网络什么也学不到。更多的时候,Leaky ReLU在准确性和训练速度方面有更好的表现。
3)选择的经验法则
- 对于二元分类问题,最后一层可以利用sigmoid;对于多元分类问题。最后一层可以利用softmax。
- 由于梯度消失,有时应避免使用Sigmoid和tanh函数。通常情况下,在隐蔽层中,ReLU或Leaky ReLU是一个不错的选择。
- 如果你对选择激活函数没有概念,可以试试ReLU或Leaky ReLU。
- 如果大量的神经元在训练过程中未被激活,请尝试利用Leaky ReLU、PReLU等。
- Leaky ReLU中的负斜率可以被设置为 0.02来加快训练速度。
B. 损失函数
损失函数或代价函数被用来计算预测值和实际值之间的距离。损失函数通常用作最佳化问题的学习准则。损失函数可以与卷积神经网络 一起用来处理回归问题和分类问题,其目的是使损失函数最小化。常见的损失函数包括平均绝对误差(MAE) ,均方误差(MSE) ,交叉熵等。
1)回归的损失函数
在卷积神经网络中,当处理回归问题时,我们可能会使用MAE或MSE。
MAE计算预测值与实际值之间的绝对误差的平均值,MSE计算它们之间的平方误差的平均值。
MAE比MSE对异常值更具鲁棒性,因为MSE会计算异常值的平方误差。然而,MSE的结果是可导出的,因此它可以控制更新的速率。MAE的结果是不可推导的,其更新速度在优化过程中无法确定。
因此,如果训练集中存在大量的异常值,并且这些异常值可能对模型产生负面影响,则MAE优于MSE。否则,应该考虑MSE。
2)分类损失函数
在卷积神经网络中,当涉及到分类任务时,有许多损失函数需要处理。
最典型的一种方法是交叉熵损失法,用于评估当前训练得到的概率分布与实际概率分布的差异。这个函数将预测的概率与每个类的实际输出值(0或1)进行比较,并根据与它们之间的距离计算惩罚值。惩罚是对数的,因此函数为较小的差异提供较小的分数(0.1或0.2) ,为较大的差异提供较大的分数(0.9或1.0)。
交叉熵损失也被称为softmax损失。表明它总是被用在具有softmax层的CNN中。例如,AlexNet [11] ,Inception v1[33]和 ResNet [37]使用作为损失函数的交叉熵损失在他们的原始论文,这有助于他们达到最先进的结果。
然而,交叉熵损失也存在一些缺陷。交叉熵损失只关心分类的正确性,而不关心同一类别的紧凑程度或不同类别之间的差距。 因此,许多损失函数被提出来解决这个问题。
对比损失[59]扩大了不同类别之间的距离,并使相同类别内的距离最小化。它可以用于卷积神经网络的降维。降维后,两个原本相似的样本在特征空间上仍然相似,而两个原本不同的样本在特征空间上仍然不同。此外,对比度损失在人脸识别中广泛应用 于卷积神经网络。它最初被用于SiameseNet[60] ,后来被部署在 DeepID2[61] ,DeepID2 + [62]和 DeepID3[63]。
在对比度丢失之后,Schroff等人在 FaceNet [64]中提出了三重丢失,使得CNN模型能够更好地学习人脸的嵌入。三重损失函数的定义基于三幅图像。这三个图像分别是锚定图像、正面图像和负面图像。 正面形象和锚形象来自同一个人,而负面形象和锚形象来自不同的人。 最小化三重丢失是为了使锚和正面之间的距离更近,使锚和负面之间 的距离更远。三重丢失通常与卷积神经网络一起用于个体层次的细粒度分类,这就要求模型具有从同一类别中区分不同个体的能力。具有三重丢失或其变体的卷积神经网络可用于识别问题,如人脸识别[65] , [66] ,[64] ,人重新识别[67] ,[68] ,和车辆重新识别[69]。
另一个是中心损失[70] ,这是基于交叉熵的改进。中心损失的目的是关注同一类别内分布的均匀性。为了使它均匀地分布在类的中心,中心损失增加了一个额外的约束,以尽量减少类内的差异。 在人脸识别[70]、图像检索[71]、人重新识别[72]、speaker recognition[73] 等方面,均采用中心丢失法。
交叉熵的另一个变体是large-margin softmax损失[74]。它的目的也是类内压缩和类间分离。它的目的也是类内压缩和类间分离。large-margin softmax损失增加了不同类之间的边界,并通过约束权重矩阵的角度引入了边界规则性。Large-margin softmax损失被用于人脸识别[74]、情感识别[75]、speaker recognition[76]等。
3) 选择的经验法则
- 当使用CNN模型处理回归问题时,我们可以选择 l1 损失或 l2 损失作为损失函数。
- 在处理分类问题时,我们可以选择其余的损失函数。
- 交叉熵损失是最常见的选择,通常出现在CNN模型中,最后是一个softmax层。
- 如果类内的紧凑度或者是类与类之间的差值紧凑度,则可以考虑基于交叉熵损失的改进。可以考虑基于交叉熵损失的改进。如center loss和large-margin softmax损失。
- 人工神经网络中损失函数的选择也取决于损失函数的选择应用场景。例如,当涉及到人脸识别时,对比度丢失和三重丢失被证明是目前常用的方法。
C. 优化器
在卷积神经网络中,我们经常需要优化非凸函数。数学方法需要巨大的计算能力,因此在训练过程中采用优化器使损失函数最小化,以便在可接受的时间内获得最优的网络参数。常见的优化算法有Momentum,RMSprop,Adam等等。
1)梯度下降法
CNN模型的训练有三种梯度下降法: 批量梯度下降法 (BGD)、随机梯度下降法(SGD)和微型批量梯度下降法 (MBGD)。
BGD表明每次更新需要计算一批数据才能得到一个梯度,从而保证收敛到凸平面的全局最优和非凸平面的局部最优。然而,使用BGD是相当慢的,因为整批样本的平均梯度应该被计算出来。另外,对于不适合内存计算的数据,这种方法也很棘手。因此,BGD 在实际应用中很少被用来训练基于CNN的模型。
相反,SGD每次更新只使用一个样本。很明显,每次更新的SGD时间远远少于BGD,因为只需要计算一个样本的梯度。在这种情况下, SGD适合在线学习[77]。然而,SGD快速更新,方差很高,这将导致目标函数严重振荡。一方面,计算的振荡可以使梯度计算跳出局部最优,最终达到一个较好的点,另一方面,由于无穷无尽的振荡,SGD 可能永远不会收敛。
在 BGD 和 SGD 的基础上,结合 BGD 和 SGD 的优点,提出了 MBGD。MBGD 在每次更新时使用一小批样本,不仅比 BGD 更有效 地进行梯度下降,而且降低了方差,使收敛更加稳定。
在这三种方法中,MBGD 是最受欢迎的一种。许多经典的 CNN 模 型使用它来训练他们的网络在原始论文,如 AlexNet [11] ,VGG [32] , Inception v2[34] ,ResNet [37]和 DenseNet [78]。它也在FaceNet [64] ,DeepID [79]和 DeepID2[61]。
2)梯度下降法优化算法
在 MBGD 的基础上,提出了一系列有效的优化算法,以加速模型的训练过程。其中的一部分如下所示。
Qian等人提出了Momentum算法[80]。它模拟物理动量,使用梯度的指数加权平均值来更新权重。如果一个维度的梯度比另一个维度的梯度大得多,学习过程就会变得不平衡。Momentum算法可以防止一维的振荡,从而实现更快的收敛。一些经典的CNN模型,如VGG[32] ,Inception v1[33]和 ResNet[37]在其原始论文中使用了动量。
然而,对于Momentum算法来说,盲目跟随梯度下降是一个问题。Nesterov加速梯度(NAG)算法[81]给了Momentum算法一个可预测性,使其在斜率变为正值之前放慢速度。通过获得下 一个位置的近似梯度,它可以提前调整步长。Nesterov 加速梯度已被用于在许多任务中训练基于CNN的模型[82],[83] ,[84]。
Adagrad算法[85]是另一种基于梯度的优化算法。它可以根据参数调整学习速率,对频繁的特征相关参数执行较小的更新(即较低的学习速率) ,对不频繁的参数执行较大的步骤更新(即较高的学习速率)。因此,它非常适合处理稀疏据。Adagrad 的一个主要优点是不需要手动调整学习速率。在大多数情况下,我们只使用0.01作为默认学习速率 [50] 。 FaceNet [64] 在 培训中使用Adagrad作为优化器。
Adadelta算法[86]是Adagrad的扩展,旨在降低其单调递减的学习速率。它不仅累积所有的平方梯度,而且设置一个固定大小的窗口来限制累积的平方梯度的数量。同时,梯度的和被递归地定义为所有 以前的平方梯度的衰减平均值,而不是直接存储以前的平方梯度。 Adadelta在许多任务中被利用[87],[88],[89]。
为了解决 Adagrad 算法中学习速率急剧下降的问题,设计了根均方平均数(RMSprop)算法[90]。MobileNet [44] , Inception v3[35]和 Inception v4[36]使用 RMSprop 实现了他们最好的模型。
另一个经常使用的优化器是Adaptive Moment Estimation(Adam)[91]它本质上是一 个由动量和RMSprop组合而成的算法。Adam 存储过去平方梯度的指数衰减平均值,比如 Adadelta算法和Momentum算法。实践证明,Adam 算法在许多问题上运行良好,适用于许多不同卷积神经网络结构[92],[93] ,[88]。
AdaMax算法[91]是 Adam 的一个变体,它简化了学习速率的边界范围,并且已经被用于训练CNN模型[94] ,[95]。
Nesterov加速自适应矩估计是Adam和NAG的组合。Nadam对学习速率有更强的约束,并直接影响梯度的新。Nadam 用于许多任务[97] ,[98],[99]。
AMSGrad [100]是对Adagrad的改进。AMSGrad 算法的作者发现,Adam 算法的更新规则存在误差,在某些情况下导致 Adam 算法无法收敛到最优解。因此,AMSGrad 算法使用过去 平方梯度的最大值而不是原来的指数平均值来更新参数。 AMSGrad 已被用于培训 CNN 在许多任务[101] ,[102] ,[103]。
3)实验评估
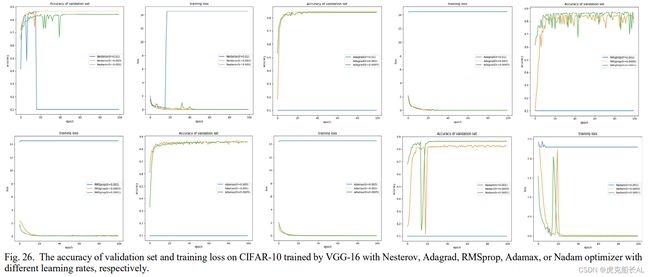
在实验中,我们在cifar-10数据集上测试了10种优化器ー mini-batch、 Momentum、 Nesterov、 Adagrad、 Adadelta、 RMSprop、 Adam、 Adamax、 Nadam 和 AMSgrad。最后九个优化器是基于mini-batch的。CIFAR-10数据集的格式与2.B的实验相同。我们也在没有 ImageNet 最后三层的预先训练的 vgg-16 模型的基础上进行实验[58]。结果可以在表 III 和图 25 中看到,从中我们可以得出一些结论。


几乎所有我们测试的优化器都可以使基于模型的收敛在训练结束时。
mini-batch梯度下降的收敛速度是最慢的,即使它能在最后收敛。
在实验中,我们发现Nesterov, Adagrad, RMSprop, Adamax和Nadam在训练期间振荡甚至不能收敛。在进一步的实验中(见图 26)我们发现学习速率对收敛有很大的影响。
Nesterov, RMSprop和Nadam可能会创造,但正是这种特性可能有助于模型跳出局部最优解。
4) 选择的经验法则
- 为了做出权衡,应该使用mini-batch计算成本和每次更新的准确性之间。
- 优化器的性能与数据分布密切相关,因此请尝试上述不同的优化器。
- 如果发生过度振荡或发散,降低学习速率可能是一个不错的选择。
V. CNN的应用
卷积神经网络是深度学习领域的关键概念之一。在大数据时代,不同于传统的方法,CNN能够利用大量的数据来达到一个有希望的结果。 因此,出现了很多应用程序。它不仅可以用于二维图像的处理,还可以用于一维和多维场景。
A. 一维 CNN 的应用
一维CNN通常利用一维卷积核来处理一维数据。当从整个数 据集中的固定长度段中提取特征时,这种方法非常有效,因为特 征的位置并不重要。因此,一维CNN可以应用于时间序列预测和信号识别,例如:
1)时间序列预测
一维CNN 可以应用于数据的时间序列预测,如心电图(ECG)时间序 列,天气预报和交通流量预测。Erdenebayar 等[104]提出了一种基于1d-cnn的方法,使用短期心电图数据自动预测心室颤动。Harbola 等 [105]提出了一维单(1DS) CNN 用于预测主导风速和风向。Han 等[106] 将 1d-cnn 应用于短期公路交通流量预测。1D-CNN 用于提取交通流的空间特征,结合时间特征来预测交通流。
2)信号识别
信号识别是根据CNN从训练数据中学到的特征来区分输入信号。它可以应用于心电信号识别,结构损伤识别和系统故障识别。Zhang等[107]提出了一种基于心电数据的多分辨率一维卷积神经网络结构来识 别心律失常和其他疾病。Abdeljaber 等[108]提出了一种基于1d CN 的直接损伤识别方法,可以应用于原始环境振动信号。Abdeljaber 等 [109]设计了一个紧凑的1d CNN,用于球轴承的故障检测和严重程度识别。
B. 二维 CNN 的应用
1)图像分类
图像分类是将图像分类为一个类别的任务。 CNN代表了这个领域 的一个突破。
LeNet-5[10]被认为是第一个用于手写数字分类的应用。AlexNet [11]使基于CNN的分类方法得以启动。然后,Simonyan等人强调深度的重要性,但这些原始的CNN不超过十层。之后,出现了更深层次的网络结构,如GoogLeNet [33]和VGGNets [32] ,这显着提高了分类任务的准确性
2014 年,He 等[110]提出了 SPP-Net,在最后一个卷积层和完全连通层之间插入一个金字塔池化层,使不同输入图像的大小得到相同大小的输出。2015 年,He 等[37]提出了ResNet 来解决退化问题, 使得训练更深层次的神经网络成为可能。2017 年,Chen等人通过分析ResNet[37]和 DenseNet[112]之间的相似性和差异, 提出了一种用于图像分类的双路径网络(DPN)。DPN 不仅共享相同的图像特征,而且确保了双路径结构特征提取的灵活性。2018年 ,Facebook开放了ResNeXt-101[113] 的源代码 , 并将ResNeXt 的层数增加到了101,从而在ImageNet上实现了最先进的结果。
此外,CNN还可用于医学图像分类[114] ,[115] ,交通场景相关分类[116] ,[117]等[118] ,[119] Li 等[114]设计了一个具有浅卷积层的定制CNN用于间质性肺病的分类。Jiang 等[115]提出了一种基于 SE-ResNet模块的方法来分类乳腺癌组织。Bruno 等[116]将 Inception网络应用于交通信号标志的分类。Madan 等[117]提出了一种不同的预 处理方法来分类交通信号。
2)目标检测
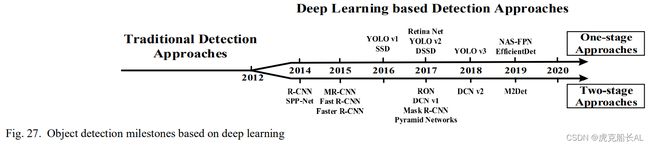
目标检测是基于图像分类的任务。系统不仅需要识别输入图像属于哪个类别,还需要用边界框标记它。基于深度学习的物体检测的发展过程如图 27 所示。物体检测的方法可以分为一个阶段的 方法,如 YOLO [120] ,[121] ,[122] ,SSD [123] ,corner net [124] ,[125] ,和两个阶段的方法,如 R-CNN [126] ,Fast R-CNN [127] ,Faster R-CNN [128]。
在两阶段物体检测中,提前选择区域方案,然后利用CNN对物体进行分类。2014 年,Girshick 等[126]使用区域提案和 CNN 来代替了传统物体检测中的滑动窗口和人工特征提取,设计了 R-CNN 框架,在物体检测中取得了突破。然后Girshick 等[127]总结了R-CNN [126]的缺点,并借鉴 SPP-Net [110]的经验,提出了Fast R-CNN,它引入了感兴趣区域(ROI)池层,使网络更快。此外,Fast RCNN 共享对象分类和边界盒回归之间的卷积特征。然而,Fast RCNN 仍然保留了 R-CNN 区域提案的选择性搜索算法。2015 年,Ren 等[128]提出了更快的R-CNN,增加了地区提案的选择,使其更快。 Faster R-CNN的一个重要贡献是在卷积层的末端引入RPN网络。 2016 年,Lin 等[129]将特征金字塔网络(Feature Pyramid Network, FPN)加入到更快的R-CNN中,在正向过程中,通过特征金字塔可以 融合多尺度的特征。
在一个阶段中,该模型直接返回目标的类别概率和位置坐标。 Redmon等人认为物体检测是一个回归问题,并提出了 YOLO v1[120] ,它直接利用一个神经网络来预测包围盒和对象的类别。之后,YOLO v2[121]提出了一种新的分类模型暗网 -19,其中包括19个卷积层和5个最大池层。在每个卷积层之后添加批量归一化层,这有利于 稳定的训练和快速收敛。YOLO v3[122]提出了采用1×1和3×3卷积和快捷连接去除最大池层和全连通层的方法。此外,YOLO v3借鉴了FPN的思想,实现了多尺度的特征融合。为了获得YOLO v3结构 的好处,许多经典的网络替换了它的后端,以获得更好的结果。所有上 述方法都利用锚箱来确定对象的位置。它们的性能取决于锚箱的选择, 并引入了大量的超参数。因此,Law 等[124]提出了“角点网络”,它抛弃了锚定框,直接预测物体边界框的左上角和右下角。为了确定不同类别中的哪两个角落彼此配对,并引入了嵌入向量。然后,CornerNet-Lite [125]在检测速度和准确性方面优化了CornerNet。
3)图像分割
图像分割是将图像分割成不同区域的任务。它必须标记出 图像中不同语义实体的边界。CNN 完成的图像分割任务如图 28 所示。
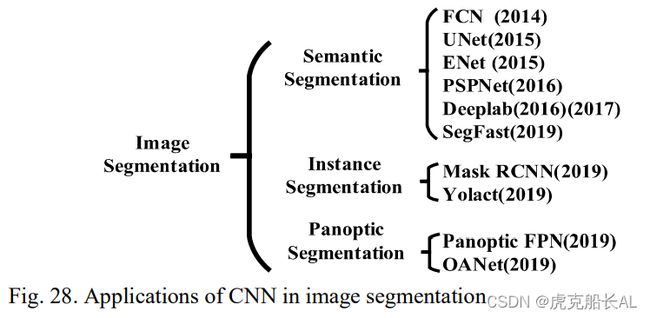
2014 年,Long 等[130]提出了全卷积网络(FCN)的概念,并首次 将 CNN 结构应用于图像语义分割。在 2015 年,Ronneberger 等[131]提出了U-Net,它具有更多的多尺度特征,并已应用于医学图像分割。此外,ENet [132] ,PSPNet [133]等[134] ,[135] 被提出来处理具体问题。
在实例分割任务方面,He等[136]提出了通过级联结构 共享卷积特征的Mask-RCNN。考虑到实时性,Bolya 等 [137]基于RetinaNet [138]利用 Resnet-101 和 FPN 来融 合多尺度特征。
2019 年,将FPN网络与Mask-RCNN网络相结合,生成了语 义分割的一个分支。在同一年,刘等[141]提出 OANet,也引入了基于Mask-RCNN的FPN,但不同的是,他们设计了一 个端到端网络。
4)面部识别
人脸识别是一种基于人脸特征的生物特征识别技术。图29显示了深度人脸识别的发展历史。DeepFace [142]和 DeepID [79]在LFW[74]数据集上取得了出色的结果,在无约束情景下首次超越了人类。 从此以后,基于深度学习的方法得到了更多的关注。Taigman等[142] 提出的DeepFace过程是检测,对齐,提取和分类。检测人脸后,使用三维对齐生成152×152图像作为CNN的输入。Taigman等[142] 利用Siamese network来训练模型,获得了最先进的结果。与 DeepFace 不同,DeepID直接将两个面部图像输入CNN以提取特征向量进行分类。 DeepID2[61]引入了分类丢失和验证丢失。基于DeepID2[61] , DeepID2+[62]增加了卷积层之间的辅助损失。DeepID3[63]提出了 两种结构,可以通过VGGNet或Inception模块的叠加卷积来构建。
上述方法利用标准的softmax损失函数。最近,人脸识别的改进主要集中在损失函数上。FaceNet [85]和谷歌在2015 年提出利用22层的CNN和2亿张图片,包括800万人,来训练一个模型。为了学习更有效的嵌入技术,FaceNet用三重丢失代替了softmax。此外,VGGFace [65] 还部署三重丢失来训练模型。此外,还有各种损耗函数利用,以达到更好的结果,如 L-softmax 损耗,球面,弧面,和余弦损耗,这可以看到在图 29 [74] ,[143],[144] ,[145]。

C. 多维 CNN 的应用
理论上,CNN可以用于任何维度的数据。然而,由于高维数据对人类来说很难理解,多维CNN在超过三维的情况下并不常见。因此, 为了更好地解释关键点,我们以三维 CNN(3D CNN)的应用为例。这并不意味着高维平均值是不可行的。
1)人类行为识别
人类行为识别是指机器对视频中人类行为的自动识别。作为一种丰富的视觉信息,基于人体姿势的动作识别方法在许多工作中得到了应用。Cao 等[146]利用三维神经网络提取关节特征而不是全身特征,然 后将这些特征输入线性支持向量机进行分类。另一种方法[147]是将二维图像卷积扩展到三维视频卷积以提取时空模式。Huang等[148]设 计了一种 3D-cnn 结构来实现手语识别,即三维卷积层自动从视频流中提取不同的空间和时间特征,并将这些特征输入到完全连接的层进行分类。此外,还可以整合从3D CNN和2D CNN提取的特征。 Huang 等[149]将三维卷积姿态流与二维卷积外观流融合,提供更多的判别性人体动作信息。
2)物体识别/检测
2015年,Wu 等[150]提出了一种生成型三维形状CNN,命名为 3D ShapeNet,可用于RGBD图像的物体检测。同年, Maturana等[151]提出了VoxNet,这是一个3D CNN 架构,包含2个卷积层、池化层和两个全连接层。2016年,Song等人[152]提出了一个3D区域建议网络来学习物体的几何特征,并设计了一个联合物体识别网络,融合了VGGNet和3D CNN的输出,共同学习3D边界盒和物体分类。2017 年,Zhou 等[153]提出了 一种用于基于点云的3D检测的单端到端VoxelNet。体素网络包含特征学习层,卷积中间层和RPN。每个卷积中间层使用三维卷积、批量归一化层和ReLU来聚合体素特征。Pastor 等[154]设计了 TactNet3D,利用触觉特征来识别物体。
此外,高维图像,如x射线和CT图像,可以检测到三维CNN。许多从业者[155] ,[156]都致力于这些工作。
VI. CNN 的前景
随着CNN的快速发展,人们提出了一些细化CNN的方法,包括模型压缩、安全性、网络体系结构搜索等。此外,卷积神经网络有许多明显的缺点,如丢失空间信息和其他限制。需要引入新的结构来处理这些问题。基于上面提到的几点,本节简要介绍了CNN的几个有前途的趋势。
A. 模型压缩
在过去的十年中,卷积神经网络设计了各种模块,帮助CNN达到了良好的精度。然而,高精度通常依赖于极其深入和广泛的架构,这使得将模型部署到嵌入式设备具有挑战性。因此,模型压缩是解决这个问题的可能方法之一,包括低秩近似、网络剪枝和网络量化。

低秩逼近方法将原网络的权矩阵作为全秩矩阵,然后将其分解为低秩矩阵来逼近全秩矩阵的效果。Jaderberg 等[157]提出了一 种结构无关的方法,使用跨通道冗余或过滤器冗余来重构低秩过滤器。Sindhwani 等[158]提出了一种结构变换网络,通过一个统一的框架来学习一类具有低位移秩的结构参数矩阵。
此外,根据网络的粒度,修剪可以分为结构化修剪和非结构化修剪。 Han 等[159]提出了 CNN 通过学习基本连接来修剪网络的深度修剪。 然而,细粒度修剪方法增加了卷积核的不规则稀疏性和计算成本。因此,许多修剪方法集中在粗粒度上。Mao 等[160]认为,粗修剪比细粒度修剪达到更好的压缩比。通过权衡稀疏性和精度之间的关系,他们就如何确保结构修剪的准确性提供了一些建议。
网络量化是另一种降低计算成本的方法,包括二进制量化、三进制量化和多元量化。2016 年,Rastegari 等[161]提出了二元权重网络和xnor-Networks。前者使网络的值近似于二进制值,后者通过二进 制操作近似卷积。Lin 等[162]利用多个二进制权值基的线性组合来逼 近全精度权值,并利用多个二进制激活值来减少信息损失,从而抑制 了先前二进制 CNN 引起的预测精度下降。Zhu 等[163]提出三元量化 可以减轻精度降低。此外,多变量量化被用来表示几个值的权重[164] ,[165]。
随着越来越多的网络使用1×1卷积,低秩近似难以实现模型压缩。 网络剪枝是模型压缩任务中一种主要的实用方法。二进制量化极大地减少了模型的大小,同时降低了精度的成本。因此,三元量化和多变量量化被用来在模型大小和准确性之间取得适当的平衡。
B. CNN的安全
CNN 在日常生活中有许多应用,包括安全识别系统[166]、[167]、 医学图像识别[168]、[156]、[155]、交通标志识别[169]和车牌识别 [170]。这些应用程序与生命和财产安全高度相关。一旦模型受到干扰 或被破坏,后果将是严重的。因此,CNN 的安全被认为是非常重要的。 更准确地说,研究人员[171] ,[172] ,[173] ,[174]提出了一些欺骗 CNN 的方法,导致准确性大幅下降。这些方法可以分为两类: 数据中毒和对抗性攻击。
数据中毒指的是在训练阶段中对训练数据中毒。Poison 指的是将噪 音数据插入到训练数据中。在图像级别上不容易区分,并且在训练过 程中没有发现异常。而在测试阶段,经过训练的模型将揭示准确性低 的问题。此外,噪声数据甚至可以进行微调,使模型能够错误地识别 某些目标。Liao 等[172]介绍了将生成的摄动掩模注入训练样本中作为 后门来欺骗模型。后门注入不会干扰正常行为,但会刺激后门实例错 误分类特定目标。Liu 等[175]提出了一种微调和修剪的方法,可以有 效地防止后门注入的威胁。修剪和微调的组合成功地抑制,甚至消除 了后门的影响。

敌对攻击也是深层神经网络所面临的威胁之一。在图 31 中,一些 噪声被添加到正常的图像中。尽管肉眼无法区分两幅图像之间的差异, 但基于CNN的模型无法将它们识别为相同的。Goodfellow等[174] 认为,造成神经网络脆弱性的主要因素是线性特征,如ReLU、 Maxout等。这些线性模型的廉价的分析性干扰会损害神经网络。此外,他们提出了一种快速的梯度表示法来生成对立的例子,并发现许多模型对这些例子进行了错误的分类。Akhtar 等[176]列出了对抗性攻击的三个防御方向,它们分别在训练示例、改进的训练网络和额外的网络上得到改进。首先,对于训练示例,可以使用对抗性示例来增强模型的稳健性。其次,可以调整网络体系结构以忽略噪声。最后, 额外的网络可以用来帮助骨干网络抵御敌对攻击。
C. 网络架构搜索
网络体系结构搜索(NAS)是另一种实现CNN自动机器学习的方法。 NAS 通过设计选择来构建搜索空间,比如内核数量,跳过连接等。此外, NAS会找到一个合适的优化器来控制搜索空间中的搜索过程。如图 32 所 示,NAS可以分为有代理的NAS和没有代理的NAS。由于NAS对计算资源的高需求,集成模型由小规模数据集中的学习最优卷积层组成。小规模数据集是生成整体模型的代理,所以这种方法就是NAS和代理。无代理NAS指的是直接在大规模数据集上学习整个模型。

2017 年,谷歌公司[177]提出了一种机器学习搜索算法,该算法利用强化学习来最大化目标网络,并在cifar-10数据集上实现了一个自动构建的网络,实现了与具有相似结构的网络相似的精度和速度。尽管 如此,这种方法在计算上是昂贵的。Pham 等[178]提出了有效的神经 结构搜索(ENAS) ,其在子模型之间共享参数并减少资源需求。Cai 等 [179]提出了 ProxylessNAS,这是一种路径级NAS方法,它在路径的末端有一个模型结构参数层,并在输出之前添加一个二进制门,以减少 GPU 的利用率。它可以直接学习大规模数据集上的架构。此外,还 有很多方法可以减少强化学习的搜索空间。Tan 等[180]设计了移动神经架构搜索(MNAS)来解决CNN推断延迟问题。他们引入了一个分解的层次搜索空间,并在该空间上执行了强化学习结构搜索算法。 Ghiasi 等[181]通过将NAS应用于物体检测的特征金字塔结构搜索, 提出了NAS-FPN。他们将可伸缩的搜索空间与NAS相结合,以减少搜索空间。可扩展的搜索空间可以覆盖所有可能的跨尺度连接,并生成 多尺度特征表示。
D. 胶囊神经网络
CNN 的许多令人印象深刻的应用正在现代社会出现,从简单的猫狗分类器[182]到复杂的自动驾驶汽车[181] ,[183] , [184]。然而,CNN 是灵丹妙药吗?它什么时候不起作用?

CNN对图像的细微变化不敏感,如旋转、缩放和对称性,Azulay 等[185]已经证明了这一点。然而,当用图 33(a)训练时, CNN 无法正确识别图 33(b)、(c)或(d)与前者是同一只猫,这对人类来说是显而易见的。这个问题是由CNN的架构引起的。因此, 为了使CNN系统能够识别一个对象的不同模式,需要提供大量的数据,以弥补CNN体系结构中多样化数据的缺陷。然而,标记的数据通常很难获得。虽然一些技巧,如数据增强可以带来一些影响,改善是相对有限的。
池层由于许多优点在 CNN 中被广泛使用,但是它忽略了整体和部 分之间的关系。为了有效地组织网络结构,解决传统 CNN的空间信息丢失问题,Hinton 等[186]提出了胶囊神经网络(Capsule Neural Networks,CapsNet)。当 CapsNet被激活时,胶囊之间的途径形成由稀疏激活的神经元组成的树状结构。胶囊的每个输出都是一个矢量, 其长度代表物体存在的概率。因此,输出特征包括物体的特定姿态信息,这意味着 CapsNet 有能力识别方向。此外,Hinton 等[187]创建 了无监督 CapsNet,称为 Stacked Capsule Autoencoder (SCAE)。 SCAE 由四部分组成: Part Capsule Autoencoder (PCAE) ,Object Capsule Autoencoder (OCAE)以及 PCAE 和 OCAE 的解码器。 PCAE是一个自上而下的注意力机制的CNN。它可以识别不同部位胶囊的姿势和存在。OCAE用于实现推理。SCAE可以直接基于姿势和存在来预测CapsNet的激活。一些实验已经证明CapsNet能够达到最先进的结果。虽然它没有在复杂的大规模数据集(如 cifar-100 或 ImageNet)上取得令人满意的结果,但我们可以看到它的潜力。
VII. 结论
由于卷积神经网络具有局部连接、权重分配和降维等优点,在研究和工 业项目中得到了广泛的应用。本文对 CNN 进行了详细的介绍,包括常见的构建模块、经典的网络、相关的功能、应用和前景。首先,我们讨论了 CNN 的基本构建模块,并介绍了如何从头构建一个基于 CNN 的模型。
其次,阐述了一些优秀的网络。从它们中,我们得到了一些从准确性和速度角度设计新型网络的指导方针。更具体地说,在准确性方面, 更深和更广泛的神经结构能够比浅层神经结构学习更好的表示。此外, 残余连接可以用来建立极深的神经网络,这可以提高处理复杂任务的能力。在速度方面,维度减化和低阶近似是非常方便的工具。
第三,介绍了CNN的激活值、损耗函数和优化器。通过实验分析, 提出了几种CNN的优化方法。同时,我们为这些函数的选择提供了一些经验法则。
第四,我们讨论了CNN的一些典型应用。不同维度的卷积应该针对不同的问题进行设计。除了用于图像相关任务的最常 用的二维CNN外,一维和多维CNN也被用于许多场景中。
最后,尽管卷积算法具有许多优点并得到了广泛的应用,但是我们认为它在模型大小、安全性和超参数选择方面还可以进一步改进。此外,还存在很多卷积难以处理的问题,如泛化能力低、均方差不足、 拥挤场景结果差等,从而指出了几个有希望的方向