《Redis深度历险学习笔记》:Redis的基本数据结构
《Redis深度探险:核心原理和应用实践》
写在前面
Redis概述
官网地址:https://redis.io/
Redis命令在线演示地址:https://try.redis.io/
命令参考:http://doc.redisfans.com/
Redis 是一个开源,高级的键值存储和一个适用的解决方案,用于构建高性能,可扩展的 Web 应用程序。Redis 也被作者戏称为 数据结构服务器 ,这意味着使用者可以通过一些命令,基于带有 TCP 套接字的简单 服务器-客户端 协议来访问一组 可变数据结构 。
Redis的优点
https://mp.weixin.qq.com/s/MT1tB2_7f5RuOxKhuEm1vQ
- 异常快:每秒可执行大约 110000 次的设置(SET)操作,每秒大约可执行 81000 次的读取/获取(GET)操作。
- 支持丰富的数据类型:Redis 支持开发人员常用的大多数数据类型,例如列表,集合,排序集和散列等等。
- 操作具有原子性:确保如果两个客户端并发访问,Redis 服务器能接收更新的值。
- 多实用工具:Redis 是一个多实用工具,可用于多种用例,如:缓存,消息队列(Redis 本地支持发布/订阅),应用程序中的任何短期数据,例如,web应用程序中的会话,网页命中计数等。
Redis基础数据结构
string
数据结构
Redis中所有的数据结构都是以唯一的key字符串作为名称,并通过这个唯一的key值来获取相应的value数据。
并且,Redis中的key是binary safe二进制安全的,这意味这你可以使用任何的二进制序列作为key,包括空字符串。

Redis 的字符串是动态字符串Simple Dynamic String,是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如图中所示,内部为当前字符串实际分配的空间 capacity 一般要高于实际字符串长度 len。当字符串长度小于 1M 时,扩容都是加倍现有的空间,如果超过 1M,扩容时一次只会多扩 1M 的空间。
需要注意的是字符串最大长度为 512M。
通过查看sds源码sds.h,可以发现redis对内存做了极致的优化,不同的字符串长度使用不同的结构体来表示。查看sds.c#sdscatlen查看字符串追加的函数:
sds sdscatlen(sds s, const void *t, size_t len) {
// 获取原字符串的长度
size_t curlen = sdslen(s);
// 按需调整空间,如果容量不够容纳追加的内容,就会重新分配字节数组并复制原字符串的内容到新数组中
s = sdsMakeRoomFor(s,len);
if (s == NULL) returnNULL; // 内存不足
memcpy(s+curlen, t, len); // 追加目标字符串到字节数组中
sdssetlen(s, curlen+len); // 设置追加后的长度
s[curlen+len] = '\0'; // 让字符串以 \0 结尾,便于调试打印
return s;
}
常用命令
键值对
字符串的value可以是任何种类的字符串,包括二进制数据,例如图片等,但注意字符串的长度限制512M。
当key存在时,set命令会覆盖掉上一次设置的value值。
> set name summerday
OK
> get name
"summerday"
> type name
"string"
> exists name # 查询key是否存在, 1为存在
(integer) 1
批量键值对
> mset name1 summerday name2 天乔巴夏
OK
> mget name1 name2
1) "summerday"
2) "天乔巴夏"
> del name1 name2
(integer) 2
> mget name1 name2
1) (nil)
2) (nil)
过期和set命令扩展
设置5秒中的过期时间,5s后自动删除。
> setex name 5 summerday # 等价于 set name summerday; expire name 5;
OK
> get name
"summerday"
> ttl name # 查看剩余存活时间
(integer) 3
> ttl name
(integer) -2
> get name # 5s之后过期
(nil)
锁
> setnx name summerday # 如果 name 不存在就执行 set 创建
(integer) 0
> get name
"summerday"
> setnx name tqbx # name 已经存在,所以 set 创建不成功
(integer) 0
> get name
"summerday"
计数
> set age 10
OK
> incr age # incrby age 1
(integer) 11
> incrby age 3 # 加3
(integer) 14
> incrby age -3 # 减3
(integer) 11
> set long_max 9223372036854775807 # 最大限制long_value
OK
> incr long_max
(error) ERR increment or decrement would overflow
典型应用场景
常见的用途就是缓存用户信息。我们将用户信息结构体使用 JSON 序列化成字符串,然后将序列化后的字符串塞进 Redis 来缓存。同样,取用户信息会经过一次反序列化的过程。
list
数据结构
Redis列表是通过链表实现的,相当于 Java 语言里面的 LinkedList,因此,list的插入和删除的时间复杂度为O(1),而索引的时间复杂度为O(N)。源码查看:adlist.h:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
Redis中list的优势体现在:
- 能够以非常快的方式向一个非常长的列表中添加元素是非常重要的。
- 可以在恒定的时间内以恒定的长度获取元素。
Redis会在list不存在且我们希望添加元素之前创建空列表,当列表中的最后一个元素被移除时,Redis会删除该key,这一点对其他几种类型也是适用的:Streams,Sets,Sorted Sets 和Hashes。
常用命令
push 和 lrange
rpush表示从右往左添加元素,lpush则正好相反,这两个命令都可以在一个调用中把多个元素放入一个列表中。
lrange命令表示获取一段范围的元素,接受两个index,表示首尾两个元素的索引位置,索引可以为复数,-1表示最后一个位置,-2表示倒数第二个位置,以此类推。lrange命令本身是O(N)的时间复杂度,但访问首尾少量元素时,效率也是高的。
Redis中index取值相关操作需要遍历,效率相对较低,如llen,lindex,lrange,ltrim等。
> rpush mylist 1 2 3 4 5 "summerday" #从右往左一次性添加多个元素
(integer) 6
> lpush mylist tqbx # 从左往右添加元素
(integer) 7
> lrange mylist 0 -1 # 获取全部元素
1) "tqbx"
2) "1"
3) "2"
4) "3"
5) "4"
6) "5"
7) "summerday"
> lrange mylist -2 -1 # 获取倒数第二index->倒数第一index范围内的元素
1) "5"
2) "summerday"
> llen mylist # 获取长度
(integer) 7
> lindex mylist 0 # 获取index为0的元素
"tqbx"
> ltrim mylist 0 2 # 只保留0 - 2位置上的元素
OK
> lrange mylist 0 -1
1) "tqbx"
2) "1"
3) "2"
实现队列
> rpush queue 1 2 3
(integer) 3
> lpop queue
"1"
> lpop queue
"2"
> lpop queue
"3"
> lpop queue
(nil)
实现栈
> rpush stack 1 2 3
(integer) 3
> rpop stack
"3"
> rpop stack
"2"
> rpop stack
"1"
> rpop stack
(nil)
支持列表阻塞操作
可用版本: >= 2.0.0
list拥有支持列表阻塞操作的特性,使得它适合用于进程间通信的实现队列。
brpop移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
> DEL list1 list2
(integer) 0
> RPUSH list1 a b c
(integer) 3
> BRPOP list1 list2 0
1) "list1"
2) "c"
假如在指定时间内没有任何元素被弹出,则返回一个 nil 和等待时长。 反之,返回一个含有两个元素的列表,第一个元素是被弹出元素所属的 key ,第二个元素是被弹出元素的值。
典型应用场景
- 用作异步队列使用,生产者将需要延后处理的任务结构体序列化为字符串塞进list中,另一个线程消费者从这个列表中轮询数据进行处理。
- 记录用户发布的最新更新,每当发布一个更新,就用lpush将ID添加到list中,可以使用
lrange 0 9获取最新的10条记录。
Hash
数据结构
Redis的Hash看起来就像我们平时所说的hash一样,拥有字段键值对,相当于Java中的HashMap,是一种无序的字典。
查看一下源码dictht的定义:dict.h/dictht
/* hashtable结构. 在我们实现增量式重散列时,每个字典都有两个这样的表,从旧表到新表 */
typedef struct dictht {
dictEntry **table; //哈希表数组
unsigned long size; //哈希表大小
unsigned long sizemask; //哈希表大小掩码,计算索引值,为size-1
unsigned long used; //该哈希表已有节点的数量
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; // 内部存在两个hashtable
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
// 哈希表数组存放的元素
typedef struct dictEntry {
void *key; //键
union { //值
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;// 指向下个哈希表节点,形成链表
} dictEntry;
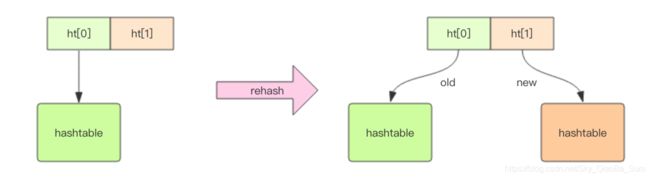
dict 结构内部包含两个 hashtable,通常情况下只有一个 hashtable 是有值的。但是在 dict 扩容缩容时,需要分配新的 hashtable,然后进行渐进式搬迁,这时候两个 hashtable 存储的分别是旧的 hashtable 和新的 hashtable。待搬迁结束后,旧的 hashtable 被删除,新的 hashtable 取而代之。
redis中使用渐进式rehash,原因在于:大字典的扩容比较耗时,需要重新生成新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,是O(N)的操作,单线程的redis很难承受这样的耗时,因此使用渐进式rehash小步搬迁。
常用命令
set和get
> hmset user:1000 username summerday age 18 location hangzhou # 设置多字段的hash
3
> hget user:1000 username # 获取单个字段
"summerday"
> hget user:1000 age
"18"
> hgetall user:1000 # 返回所有
1) "username"
2) "summerday"
3) "age"
4) "18"
5) "location"
6) "hangzhou"
> hmget user:1000 username age location # 返回多字段
1) "summerday"
2) "18"
3) "hangzhou"
递增某数值字段
> hget user:1000 age
"18"
> hincrby user:1000 age 10
(integer) 28
典型应用场景
可以用来存储用户信息,不同于字符串一次性需要全部序列化整个对象。
-
优点在于:hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话就只能一次性全部读取,这样就会比较浪费网络流量。
-
缺点:hash结构的存储消耗要高于单个字符串。
Set
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
常用命令
> sadd myset 1 2 3 # 向set中添加1 2 3三个元素
(integer) 3
> smembers myset # 查看所有的元素
1) "1"
2) "2"
3) "3"
> sismember myset 3 # 判断3是不是myset对应的set中的元素 1 表示true,0表示false
(integer) 1
> sismember myset 30
(integer) 0
> sadd myset 1 # set中已经存在元素1,添加失败
(integer) 0
> scard myset # 获取长度
3
> spop myset # 弹出一个元素
"2"
典型应用场景
- 存储活动中奖的用户ID,保证同一个用户不会中两次奖。
Sorted set
类似于Java中的SortedSet和HashMap的结合,内部实现是跳跃表,对指定位置的操作可以达到O(N)的时间复杂度,比如更新指定位置的score,在指定位置添加元素等等。
- set保证了内部value的唯一性。
- 每个value都可以赋予一个score,代表value的排序权重。
排序规则:
- 如果A和B是两个具有不同score的元素,如果A.score> B.score,则A > B。
- 如果A和B的score相同,A的字典序>B的字典序,则A>B。
常用命令
> zadd student 100.0 小明
(integer) 1
> zadd student 60.5 小红
(integer) 1
> zadd student 78 小刚
(integer) 1
> zrange student 0 -1 # 按score排序,start_index -> end_index
1) "小红"
2) "小刚"
3) "小明"
> zrevrange student 0 -1 # 按score逆序
1) "小明"
2) "小刚"
3) "小红"
> zcard student # 计数
3
> zscore student 小红 # 获取指定value的score
60.5
> zrank student 小明 # 获取指定value的排名
2
> zrangebyscore student 0 80 # 根据score,start_index,end_index区间获取数据
1) "小红"
2) "小刚"
> zrangebyscore student -inf 80 withscores # 根据分值区间(-∞, 80],同时返回score
1) "小红"
2) 60.5
3) "小刚"
4) 78.0
> zrem student 小明 # 删除指定value
1
> zrange student 0 -1
1) "小红"
2) "小刚"
典型应用场景
- 排行榜,排行依据可以作为score,保证key唯一,且有序。
参考阅读
-
Redis 深度历险:核心原理与应用实践
-
Redis—5种基本数据结构