这次一定要弄懂-SVM-5-推广到soft margin svm和非线性的svm
有了前面推hard margin svm的经历,这次推soft margin svm应该会迅速很多。
开启~
昨晚还在B站上录制了一小段梳理整个SVM问题的视频:
https://www.bilibili.com/video/av62223878
文章目录
- 5-1 Soft Margin SVM
-
- 5-1-1 Soft Margin SVM的原问题
- 5-1-2 Soft Margin SVM的对偶问题
-
- 5-1-2-1 证明Soft Margin SVM满足Slater条件
- 5-1-2-2 对偶问题的推导
- 5-1-2-3 对偶问题是凸优化问题的证明
- 5-2 加入核函数
-
- 5-2-1 以多项式核函数为例,理解核函数是如何运作的
- 5-2-2 常见的核函数
- 5-2-3 rbf高斯核函数
- 5-3 SMO算法
-
- 5-3-1 KKT条件
- 5-3-2 SMO算法
-
- 5-3-2-1求解子问题
- 5-3-2-2 优化变量的寻找
- 5-3-2-3 计算阈值b和差值$E_i$
- 5-4 总结SVM
- 5-5 python实现
5-1 Soft Margin SVM
5-1-1 Soft Margin SVM的原问题
hard margin svm是针对一个线性可分的数据集,用超平面对数据集进行划分。可是现实中线性可分的数据集是少数,所以我们需要改进hard margin svm,使其能够在非线性可分的数据集上也能使用
如何推广呢?
min ω ∣ ∣ ω ∣ ∣ 2 2 \min \limits_{\bold{\omega}}\frac{||\omega||^2}{2} ωmin2∣∣ω∣∣2 s . t . y ( i ) ( ω T x ( i ) + b ) ⩾ 1 i=1,2,...m s.t.\quad y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 \quad\text{i=1,2,...m} s.t.y(i)(ωTx(i)+b)⩾1i=1,2,...m
对于非线性可分的数据集,SVM在划分时,一定会存在错误,所以需要SVM算法有一定的容错能力。在一些情况下,可以把一些点错误的分类,同时希望最终的结果泛化能力还是很强的。
在Hard Margin SVM中,约束条件 s . t . y ( i ) ( ω T x ( i ) + b ) ⩾ 1 i=1,2,...m s.t.\quad y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 \quad\text{i=1,2,...m} s.t.y(i)(ωTx(i)+b)⩾1i=1,2,...m就是要求所有的数据点都在Margin范围外,也就是所有的数据点都要在 w T + b = 1 w^T+b=1 wT+b=1与 w T + b = − 1 w^T+b=-1 wT+b=−1这两根直线外
现在为了让这些数据可以在margin区域内,所以要给他一个宽松量,宽松量为 ζ \zeta ζ
所以现在我们要求
s . t . y ( i ) ( ω T x ( i ) + b ) ⩾ 1 − ζ i s.t.\quad y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 -\zeta_i s.t.y(i)(ωTx(i)+b)⩾1−ζi ζ i ⩾ 0 i=1,2,...m \zeta_i\geqslant0\quad\text{i=1,2,...m} ζi⩾0i=1,2,...m
但是也不能让 ζ \zeta ζ无限大,毫无约束,所以对目标函数也进行了修改为
min 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ζ i \min\frac{1}{2}||w||^2+\textcolor{red}{C\sum\limits_{i=1}^m\zeta_i} min21∣∣w∣∣2+Ci=1∑mζi
用C这个惩罚因子来平衡Soft Margin SVM中这两个部分的重要程度
也可以理解在Soft Margin SVM中添加了L1正则项
我们加入正则化项,让我们的模型相对于训练数据集有更高的容错能力,拥有了这种容错能力后,使得模型本身对训练数据集中的极端数据点不那么敏感,使得模型的泛化能力得到提升。
C越大,越在意松弛因子的大小,容错空间越小;C越小,越不在意松弛因子,容错空间越大
如果C取正无穷,则逼迫 ζ \zeta ζ都为0,等价为Hard Margin SVM
对于Soft Margin SVM的原问题为
min 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ζ i \min\frac{1}{2}||w||^2+\textcolor{red}{C\sum\limits_{i=1}^m\zeta_i} min21∣∣w∣∣2+Ci=1∑mζi s . t . y ( i ) ( ω T x ( i ) + b ) ⩾ 1 − ζ i s.t.\quad y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 -\zeta_i s.t.y(i)(ωTx(i)+b)⩾1−ζi ζ i ⩾ 0 i=1,2,...m \zeta_i\geqslant0\quad\text{i=1,2,...m} ζi⩾0i=1,2,...m
5-1-2 Soft Margin SVM的对偶问题
5-1-2-1 证明Soft Margin SVM满足Slater条件
证明Soft Margin SVM满足Slater条件,这样强对偶关系就成立了
目标函数为 min 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ζ i \min\frac{1}{2}||w||^2+\textcolor{red}{C\sum\limits_{i=1}^m\zeta_i} min21∣∣w∣∣2+Ci=1∑mζi
是关于 w , ζ w,\zeta w,ζ的凸优化问题
在寻找一组严格满足不等式约束的 w , b , ζ w,b,\zeta w,b,ζ
令 w = 0 , b = 0 , ζ = 2 w=0,b=0,\zeta=2 w=0,b=0,ζ=2
则 y i ( w T x i + b ) = 0 > 1 − ζ = − 1 y_i(w^Tx_i+b)=0>1-\zeta=-1 yi(wTxi+b)=0>1−ζ=−1
所以存在一组变量,使得不等式约束严格成立,故Slater条件满足,强对偶关系成立
5-1-2-2 对偶问题的推导
1.将不等式约束转换为标准形式 g ( x ) ⩽ 0 g(x)\leqslant0 g(x)⩽0
y ( i ) ( ω T x ( i ) + b ) ⩾ 1 − ζ i y^{(i)}(\bold{\omega}^T\bold{x^{(i)}}+b)\geqslant1 -\zeta_i y(i)(ωTx(i)+b)⩾1−ζi ==== > 1 − ζ i − y i ( w x i + b ) ⩾ 0 1-\zeta_i-y_i(wx_i+b)\geqslant0 1−ζi−yi(wxi+b)⩾0
ζ i ⩾ 0 \zeta_i\geqslant0 ζi⩾0 === > − ζ ⩽ 0 -\zeta\leqslant0 −ζ⩽0
2.构造拉格朗日乘子函数
L ( w , b , ζ , α , β ) = 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ζ i + ∑ i = 1 m α i ( 1 − ζ i − y i ( w x i + b ) ) − ∑ i = 1 m β i ζ i L(w,b,\zeta,\alpha,\beta)=\frac{1}{2}||w||^2+C\sum\limits_{i=1}^m\zeta_i+\sum\limits_{i=1}^m\alpha_i\Big(1-\zeta_i-y_i(wx_i+b)\Big)-\sum\limits_{i=1}^m\beta_i\zeta_i L(w,b,ζ,α,β)=21∣∣w∣∣2+Ci=1∑mζi+i=1∑mαi(1−ζi−yi(wxi+b))−i=1∑mβiζi
3.对偶问题
即 max α , β min w , b , ζ L ( w , b , ζ , α , β ) \max\limits_{\alpha,\beta}\min\limits_{w,b,\zeta}L(w,b,\zeta,\alpha,\beta) α,βmaxw,b,ζminL(w,b,ζ,α,β)
所以我们先求得令 L ( w , b , ζ , α , β ) L(w,b,\zeta,\alpha,\beta) L(w,b,ζ,α,β)取最小的 w , b , ζ w,b,\zeta w,b,ζ值
分别对 w , b , ζ w,b,\zeta w,b,ζ求导得
∇ w L ( w , b , ζ , α , β ) = w − ∑ i = 1 m α i y i x i = 0 \nabla_wL(w,b,\zeta,\alpha,\beta)=w-\sum\limits_{i=1}^m\alpha_iy_ix_i=0 ∇wL(w,b,ζ,α,β)=w−i=1∑mαiyixi=0
∂ L ( w , b , ζ , α , β ) ∂ b = − ∑ i = 1 m α i y i = 0 \frac{\partial L(w,b,\zeta,\alpha,\beta)}{\partial b}=-\sum\limits_{i=1}^m \alpha_iy_i=0 ∂b∂L(w,b,ζ,α,β)=−i=1∑mαiyi=0
∇ ζ L ( w , b , ζ , α , β ) = C − α i − β i = 0 \nabla_\zeta L(w,b,\zeta,\alpha,\beta)=C-\alpha_i-\beta_i=0 ∇ζL(w,b,ζ,α,β)=C−αi−βi=0
整理可得:
w = ∑ i = 1 m α i y i x i w=\sum\limits_{i=1}^m\alpha_iy_ix_i w=i=1∑mαiyixi ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^m \alpha_iy_i=0 i=1∑mαiyi=0 C = α i + β i C=\alpha_i+\beta_i C=αi+βi
4.将上面的解带入,得到 min w , b , ζ L ( w , b , ζ , α , β ) \min\limits_{w,b,\zeta}L(w,b,\zeta,\alpha,\beta) w,b,ζminL(w,b,ζ,α,β)
min w , b , ζ L ( w , b , ζ , α , β ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 m α i y i b − ∑ i = 1 m α i y i x i w + C ∑ i = 1 m ζ i − ∑ i = 1 m α i ζ i − ∑ i = 1 m β i ζ i + ∑ i = 1 m α i = − 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i = − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j + ∑ i = 1 m α i \min\limits_{w,b,\zeta}L(w,b,\zeta,\alpha,\beta)=\frac{1}{2}||w||^2-\sum\limits_{i=1}^m\alpha_iy_ib-\sum\limits_{i=1}^m\alpha_iy_ix_iw+C\sum\limits_{i=1}^m\zeta_i-\sum\limits_{i=1}^m\alpha_i\zeta_i-\sum\limits_{i=1}^m\beta_i\zeta_i+\sum\limits_{i=1}^m\alpha_i\\ =-\frac{1}{2}||w||^2+\sum\limits_{i=1}^m\alpha_i\\ =-\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx_i\cdot x_j+\sum\limits_{i=1}^m\alpha_i w,b,ζminL(w,b,ζ,α,β)=21∣∣w∣∣2−i=1∑mαiyib−i=1∑mαiyixiw+Ci=1∑mζi−i=1∑mαiζi−i=1∑mβiζi+i=1∑mαi=−21∣∣w∣∣2+i=1∑mαi=−21i=1∑mj=1∑mαiαjyiyjxi⋅xj+i=1∑mαi
接下来就是调整乘子变量 α , β \alpha,\beta α,β求得最偶问题的最优解
max α , β − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j + ∑ i = 1 m α i \max\limits_{\alpha,\beta}-\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx_i\cdot x_j+\sum\limits_{i=1}^m\alpha_i α,βmax−21i=1∑mj=1∑mαiαjyiyjxi⋅xj+i=1∑mαi
等价于求
min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j − ∑ i = 1 m α i \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx_i\cdot x_j-\sum\limits_{i=1}^m\alpha_i α,βmin21i=1∑mj=1∑mαiαjyiyjxi⋅xj−i=1∑mαi
最后得到的对偶问题
min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j − ∑ i = 1 m α i \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx_i\cdot x_j-\sum\limits_{i=1}^m\alpha_i α,βmin21i=1∑mj=1∑mαiαjyiyjxi⋅xj−i=1∑mαi
s . t . s.t. s.t.
α i ⩾ 0 , i = 1 , 2 , . . . m \alpha_i\geqslant0,\quad i=1,2,...m αi⩾0,i=1,2,...m β i ⩾ 0 , i = 1 , 2 , . . . m \beta_i\geqslant0,\quad i=1,2,...m βi⩾0,i=1,2,...m α i + β i = C , i = 1 , 2 , . . . m \alpha_i+\beta_i=C,\quad i=1,2,...m αi+βi=C,i=1,2,...m ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^m\alpha_iy_i=0 i=1∑mαiyi=0
我们可以稍微整理下前3个不等式,将其合并为
0 ⩽ α i ⩽ C 0\leqslant\alpha_i\leqslant C 0⩽αi⩽C
最终对偶问题为:
min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j − ∑ i = 1 m α i \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx_i\cdot x_j-\sum\limits_{i=1}^m\alpha_i α,βmin21i=1∑mj=1∑mαiαjyiyjxi⋅xj−i=1∑mαi
s . t . s.t. s.t.
0 ⩽ α i ⩽ C 0\leqslant\alpha_i\leqslant C 0⩽αi⩽C ∑ i = 1 m α i y i = 0 \sum\limits_{i=1}^m\alpha_iy_i=0 i=1∑mαiyi=0
且
w = ∑ i = 1 m α i y i x i w=\sum\limits_{i=1}^m\alpha_iy_ix_i w=i=1∑mαiyixi
所以预测函数为
s g n ( ∑ i = 1 m α i y i x i ⋅ x 预 测 样 本 + b ) sgn\Big(\sum\limits_{i=1}^m\alpha_iy_ix_i\cdot x_{预测样本}+b\Big) sgn(i=1∑mαiyixi⋅x预测样本+b)
此时这还是一个线性模型,和线性可分的对偶问题相比,唯一的区别在于多了不等式约束。
相对于原问题,对偶问题的目标函数还是一个二次函数,但不等式和等式约束都更简单了,等式约束就是一条直线,不等式约束就是一个区间。
5-1-2-3 对偶问题是凸优化问题的证明
证明是凸优化问题,只需要证明可行域是凸集并且目标函数是凸函数即可。
由于对偶问题的等式约束和不等式约束都是线性约束,因此构成的集合是凸集。
同时我们将对偶问题写成向量形式
min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i ⋅ x j − ∑ i = 1 m α i = 1 2 α T Q i j α − e T α \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jx_i\cdot x_j-\sum\limits_{i=1}^m\alpha_i\\ =\frac{1}{2}\alpha^TQ_{ij}\alpha-e^T\alpha α,βmin21i=1∑mj=1∑mαiαjyiyjxi⋅xj−i=1∑mαi=21αTQijα−eTα
其中 Q i j = y i y j X i T X j Q_{ij}=y_iy_jX_i^TX_j Qij=yiyjXiTXj, e T = [ 1 , 1 , . . . , 1 ] e^T=[1,1,...,1] eT=[1,1,...,1]
目标函数的Hessian矩阵为
Q = X T X Q=X^TX Q=XTX
令 X = [ y 1 x 1 , y 2 x 2 , . . . y m x m ] X=[y_1x_1,y_2x_2,...y_mx_m] X=[y1x1,y2x2,...ymxm]
所以对于任意非0的向量x,有
x T Q x = x T X T X x = ( X x ) T ( X x ) ⩾ 0 x^TQx=x^TX^TXx=(Xx)^T(Xx)\geqslant0 xTQx=xTXTXx=(Xx)T(Xx)⩾0
因此矩阵Q半正定
5-2 加入核函数
在讲解线性分类器的时候,说到如何将线性分类器拓展到非线性的情形。
我们要做的就是先对已有的特征升维,在一个更高的维度进行线性分类。
比如我们原本只有x1这一维特征,对应的数据是线性不可分的,但如果我们添加一个维度 x 1 2 x_1^2 x12,则此时数据集就线性可分了。

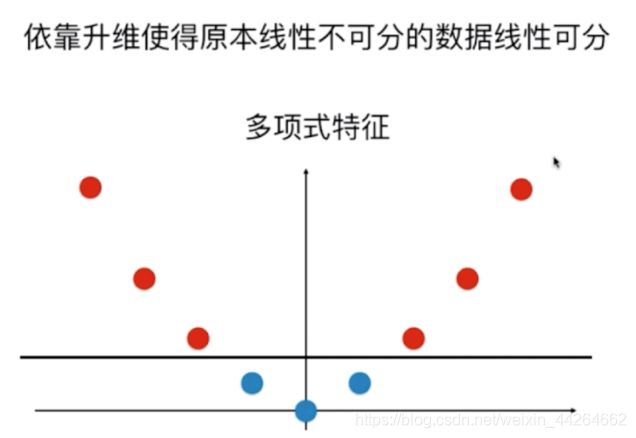
而核函数也是做的这样的事情,将原本的样本对应到高维的空间中,再进行线性分类。
5-2-1 以多项式核函数为例,理解核函数是如何运作的
在不使用核函数的时候,我们如果想将SVM拓展到非线性的情况,要做的是先把X->X’
假如我们的特征只有2个 X = [ X 1 , X 2 ] X=[X_1,X_2] X=[X1,X2]
将其添加二次多项式 X ′ = [ X 1 , X 2 , X 1 2 , X 2 2 , X 1 X 2 ] X'=[X_1,X_2,X_1^2,X_2^2,X_1X_2] X′=[X1,X2,X12,X22,X1X2]
带入SVM对应的对偶问题中,则对有问题由原先的
min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j X i ⋅ X j − ∑ i = 1 m α i \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jX_i\cdot X_j-\sum\limits_{i=1}^m\alpha_i α,βmin21i=1∑mj=1∑mαiαjyiyjXi⋅Xj−i=1∑mαi
转化为
min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j X i ′ ⋅ X j ′ − ∑ i = 1 m α i \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jX'_i\cdot X'_j-\sum\limits_{i=1}^m\alpha_i α,βmin21i=1∑mj=1∑mαiαjyiyjXi′⋅Xj′−i=1∑mαi
同时预测函数由原来的
s g n ( ∑ i = 1 m α i y i X i ⋅ X 预 测 样 本 + b ) sgn\Big(\sum\limits_{i=1}^m\alpha_iy_iX_i\cdot X_{预测样本}+b\Big) sgn(i=1∑mαiyiXi⋅X预测样本+b)
转化为
s g n ( ∑ i = 1 m α i y i X i ′ ⋅ X 预 测 样 本 ′ + b ) sgn\Big(\sum\limits_{i=1}^m\alpha_iy_iX_i'\cdot X'_{预测样本}+b\Big) sgn(i=1∑mαiyiXi′⋅X预测样本′+b)
原本的操作是先将 X i , X j X_i,X_j Xi,Xj转化为 X i ′ , X j ′ X'_i,X_j' Xi′,Xj′,再做点乘
有没有可能设置一个函数K,这个函数传入两个参数,参数为 X i , X j X_i,X_j Xi,Xj,直接对原来的样本进行数学计算,直接算出 X i ′ ⋅ X j ′ X_i'\cdot X_j' Xi′⋅Xj′
即 K ( X i , X j ) = X i ′ ⋅ X j ′ K(X_i,X_j)=X_i'\cdot X_j' K(Xi,Xj)=Xi′⋅Xj′
相当于重新定义了点乘计算,同时使用K函数后,我们就不再需要先对数据升维再带入对偶问题中了,因为把原来的样本带入K函数中,求得的就是升维后点乘的结果。
这个K函数就叫做核函数
他是针对目标函数中存在 X i ⋅ X j X_i\cdot X_j Xi⋅Xj点乘的式子或者类似这样的式子,都可以使用的一种数学技巧。对于一些复杂的变形,通常使用核函数可以减少计算量,同时节省存储空间。
因为用核函数,不需要存储变化后的高维数据,使用核函数就可以直接计算出点乘结果。
所以核函数不是SVM专用的一种思想。
我们用多项式核函数来验证下上面的思考
多项式核函数 K ( x , y ) = ( x ⋅ y + c ) d K(x,y)=(x\cdot y+c)^d K(x,y)=(x⋅y+c)d
以d=2,c=1为例
x = [ x 1 , x 2 , . . . x n ] x=[x_1,x_2,...x_n] x=[x1,x2,...xn]
y = [ y 1 , y 2 , . . . y n ] y=[y_1,y_2,...y_n] y=[y1,y2,...yn]
K ( x , y ) = ( x ⋅ y + 1 ) 2 = ( ∑ i = 1 n x i y i + 1 ) 2 = ( x 1 y 1 + x 2 y 2 + x 3 y 3 + . . . + x n y n + 1 ) ( x 1 y 1 + x 2 y 2 + x 3 y 3 + . . . + x n y n + 1 ) = ∑ i = 1 n ( x i ) 2 ( y i ) 2 + ∑ i = 1 n − 1 ∑ j = i + 1 n ( 2 x i x j ) ( 2 y i y j ) + ∑ i = 1 n ( 2 x i ) ( 2 y i ) + 1 K(x,y)=(x\cdot y+1)^2=(\sum\limits_{i=1}^nx_iy_i+1)^2\\ =(x_1y_1+x_2y_2+x_3y_3+...+x_ny_n+1)(x_1y_1+x_2y_2+x_3y_3+...+x_ny_n+1)\\ =\sum\limits_{i=1}^n(x_i)^2(y_i)^2+\sum\limits_{i=1}^{n-1}\sum\limits_{j=i+1}^n(\sqrt{2}x_ix_j)(\sqrt{2}y_iy_j)+\sum\limits_{i=1}^n(\sqrt{2}x_i)(\sqrt{2}y_i)+1 K(x,y)=(x⋅y+1)2=(i=1∑nxiyi+1)2=(x1y1+x2y2+x3y3+...+xnyn+1)(x1y1+x2y2+x3y3+...+xnyn+1)=i=1∑n(xi)2(yi)2+i=1∑n−1j=i+1∑n(2xixj)(2yiyj)+i=1∑n(2xi)(2yi)+1
而
x ′ = [ x 1 2 , x 2 2 , . . . , x n 2 , x 1 x 2 , x 1 x 3 , . . . x n − 1 x n , x 1 , x 2 , . . . x 3 , 1 ] x'=[x_1^2,x_2^2,...,x_n^2,x_1x_2,x_1x_3,...x_{n-1}x_n,x_1,x_2,...x_3,1] x′=[x12,x22,...,xn2,x1x2,x1x3,...xn−1xn,x1,x2,...x3,1]
y ′ = [ y 1 2 , y 2 2 , . . . , y n 2 , y 1 y 2 , y 1 y 3 , . . . y n − 1 y n , y 1 , y 2 , . . . y 3 , 1 ] y'=[y_1^2,y_2^2,...,y_n^2,y_1y_2,y_1y_3,...y_{n-1}y_n,y_1,y_2,...y_3,1] y′=[y12,y22,...,yn2,y1y2,y1y3,...yn−1yn,y1,y2,...y3,1]
x ′ ⋅ y ′ = ∑ i = 1 n ( x i ) 2 ( y i ) 2 + ∑ i = 1 n − 1 ∑ j = i + 1 n ( x i x j ) ( y i y j ) + ∑ i = 1 n x i y i + 1 x'\cdot y'=\sum\limits_{i=1}^n(x_i)^2(y_i)^2+\sum\limits_{i=1}^{n-1}\sum\limits_{j=i+1}^n(x_ix_j)(y_iy_j)+\sum\limits_{i=1}^nx_iy_i+1 x′⋅y′=i=1∑n(xi)2(yi)2+i=1∑n−1j=i+1∑n(xixj)(yiyj)+i=1∑nxiyi+1
除了系数的微小差别外, K ( x , y ) = x ′ ⋅ y ′ K(x,y)=x'\cdot y' K(x,y)=x′⋅y′
所以我们可以直接用原来的样本数据,计算出 K ( x , y ) K(x,y) K(x,y),这个结果和我们先变换成x’y’,再进行点乘的结果是一致的,这样我们就完成了对样本添加二次项这样的特征。这就是核函数的优势,降低计算复杂度。
5-2-2 常见的核函数
不同的核函数,对应对原始数据样本进行不同的转换。
在sklearn中,主要提供4种核"linear",“poly”,“RBF”,“sigmoid”
其中
| linear线性核函数 | K ( x , y ) = x ⋅ y K(x,y)=x\cdot y K(x,y)=x⋅y |
| poly多项式核函数 | K ( x , y ) = ( γ x ⋅ y + c ) d K(x,y)=(\gamma x\cdot y+c)^d K(x,y)=(γx⋅y+c)d |
| rfb高斯核函数 | K ( x , y ) = e − r ∥ x − y ∥ 2 K(x,y)=e^{-r\|x-y\|^2} K(x,y)=e−r∥x−y∥2 |
| sigmoid | t a n h ( γ x i T ⋅ x j + b ) tanh(\gamma x_i^T\cdot x_j+b) tanh(γxiT⋅xj+b) |
5-2-3 rbf高斯核函数
高斯核函数是SVM算法使用最多的一种核函数,核函数通常表示为 K ( x , y ) = e − r ∥ x − y ∥ 2 K(x,y)=e^{-r\|x-y\|^2} K(x,y)=e−r∥x−y∥2,重新定义向量x,y的点乘。
其中只有一个超参数 γ \gamma γ
高斯核函数和高斯分布(高斯函数)有什么联系呢?
仔细分析会发现,高斯核函数和高斯函数在表达式上有相似的形态。
高斯核函数 K ( x , y ) = e − r ∥ x − y ∥ 2 K(x,y)=e^{-r\|x-y\|^2} K(x,y)=e−r∥x−y∥2
高斯函数 g ( x ) = 1 σ 2 π e − 1 2 ( x − μ σ ) 2 g(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{1}{2}(\frac{x-\mu}{\sigma})^2} g(x)=σ2π1e−21(σx−μ)2
我们会发现高斯核函数中的 γ \gamma γ和高斯分布中的 1 2 σ 2 \frac{1}{2\sigma^2} 2σ21有共同的作用
所以可以猜测,小的 γ \gamma γ对应大的 σ \sigma σ,模型的复杂度越低。而大的 γ \gamma γ对应小的 σ \sigma σ,模型对训练数据太敏感,泛化能力低,容易过拟合。
对于多项式核函数的本质,其实是将我们所有的数据点首先添加多项式项,再将这些有了多项式项的新的数据特征进行点乘,形成了我们的多项式核
相应的,高斯核函数的本质,也是将我们原本的数据点先映射成一种新的特征向量,然后是这种新的特征向量点乘的结果。
高斯核函数背后对每一个样本点相应的变形是非常复杂的,但经过变形后进行点乘的结果的结果却非常简单。这样的一个式子,再次显示核函数的威力。它不需要我们具体计算出对于每一个样本点x和y到底先变成了一个怎样的样本点,我们只需要直接关注这样映射后的点乘结果。
用一个简单的例子来模拟高斯函数
为了方便可视化,对核函数进行一个改变,将y的值固定,也就是说,y不取样本点,而是取固定的点,取2个固定的点当y。

这2个固定的点分别叫l1,l2,英文为landmark,中文翻译为地标。
高斯核函数做的升维过程就是,对于原本的每一个x值,如果我们有两个地标的话,就把它升维成一个二维的样本点。

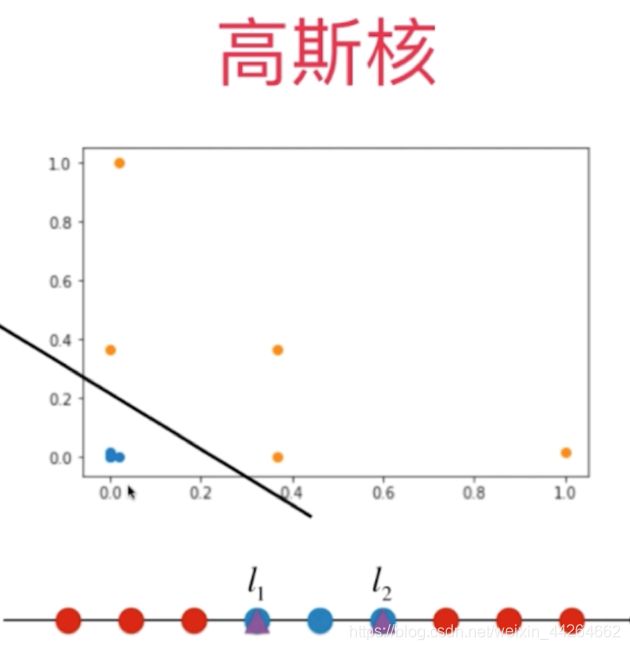
实际高斯核函数中,y的位置是每一个数据点。换句话说,高斯核函数干的事情和我们之前干的事情一样,只不过那个地标点比我们之前取得要多得到。
样本有多少个,就有多少个地标点。换句话说,对于每一个样本x,它都尝试对每一个样本y进行一个核函数的计算,称为新的高维空间中对应的某一个维度元素。
高斯核函数的本质就是将原本的数据映射进了一个无穷维的空间。所谓的无穷可以理解为由于样本数据点是有无穷多个,所以它映射进了一个无穷维的空间。
但具体拿到一组数据的时候,因为m是有限个,所以它映射成了m*m这样的数据。
我们在使用高斯核函数时,由于这个映射过程,所以计算开销非常大。因此,SVM使用高斯核函数的训练时间比较长。尽管如此,还是存在非常适合使用高斯核函数的样本集。
最典型的应用就是如果我们初始的样本数据维度非常高,但是样本数据的数量可能并不多。换句话说,也就是当m KKT条件的中要求 我们的原问题中存在两个不等式约束: 所以对应的KKT条件为 接下来分情况讨论 α i \alpha_i αi 故 α i \alpha_i αi的取值有三种情况: α i = 0 \alpha_i=0 αi=0 α i = C \alpha_i=C αi=C 0 < α i < C 0<\alpha_i<C 0<αi<C 最终总结一下: KKT条件用于: 假设我们已经选出了优化变量KaTeX parse error: Expected 'EOF', got '\alpah' at position 1: \̲a̲l̲p̲a̲h̲_1和 α 2 \alpha_2 α2 因为将除 α 1 \alpha_1 α1和 α 2 \alpha_2 α2以外的变量看作是常数,所以对偶问题可以写成以下形式的二元二次函数的形式 其中 K i j = K ( X i , X j ) K_{ij}=K(X_i,X_j) Kij=K(Xi,Xj) min α , β 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j K i j − ∑ i = 1 m α i = 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + y 1 y 2 K 12 α 1 α 2 + y 1 α 1 ∑ j = 3 m α j y j K 1 j + y 2 α 2 ∑ j = 3 m α j y j K 2 j − α 1 − α 2 + c \min\limits_{\alpha,\beta}\frac{1}{2}\sum\limits_{i=1}^m\sum\limits_{j=1}^m\alpha_i\alpha_jy_iy_jK_{ij}-\sum\limits_{i=1}^m\alpha_i\\ =\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{22}\alpha_2^2+y_1y_2K_{12}\alpha_1\alpha_2+y_1\alpha_1\sum\limits_{j=3}^m\alpha_jy_jK_{1j}+y_2\alpha_2\sum\limits_{j=3}^m\alpha_jy_jK_{2j}-\alpha_1-\alpha_2+c α,βmin21i=1∑mj=1∑mαiαjyiyjKij−i=1∑mαi=21K11α12+21K22α22+y1y2K12α1α2+y1α1j=3∑mαjyjK1j+y2α2j=3∑mαjyjK2j−α1−α2+c 为了方便表示,定义 故上式为 根据约束条件 y 1 α 1 + y 2 α 2 = − ∑ k = 3 m y k α k = ξ y_1\alpha_1+y_2\alpha_2=-\sum\limits_{k=3}^my_k\alpha_k=\xi y1α1+y2α2=−k=3∑mykαk=ξ 带入上式,求出关于 α 2 \alpha_2 α2的函数,并求极值点 接下来我们要求对应的极值点,所以可以通过求一阶导数,并令其为0,得 为了让表达式看起来更整洁 但由于 α 2 \alpha_2 α2是有约束的,所以最终的 α 2 \alpha_2 α2不一定就是 α 2 u n c l i p p e d \alpha_2^{unclipped} α2unclipped 关于 α 2 \alpha_2 α2和 α 1 \alpha_1 α1的取值要求有 通过分类讨论和画图,最终可以得到 所以消元后,最终 α 2 n e w \alpha_2^{new} α2new为 因为要满足等式约束 α 1 n e w y 1 + α 2 n e w y 2 = α 1 o l d y 1 + α 2 o l d y 2 \alpha_1^{new}y_1+\alpha_2^{new}y_2=\alpha_1^{old}y_1+\alpha_2^{old}y_2 α1newy1+α2newy2=α1oldy1+α2oldy2 α 1 \alpha_1 α1的寻找: 这个检验是在 ϵ \epsilon ϵ范围内进行的,检查过程中,外层循环首先遍历所有满足条件 0 < α i < C 0<\alpha_i<C 0<αi<C的样本点,即在间隔边界上的支持向量点,检验它们是否满足KKT条件。如果这些样本点都满足KKT条件,那么遍历整个训练集,检验它们是否满足KKT条件 第2个变量 α 2 \alpha_2 α2的选择 之前的推导中发现 α 2 u n c l i p p e d \alpha_2^{unclipped} α2unclipped是依赖于 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣,为了加快计算速度,一种简单的做法是选择 α 2 \alpha_2 α2,使其对应的 ∣ E 1 − E 2 ∣ |E_1-E_2| ∣E1−E2∣最大。为了节省计算时间,将所有的|E_i|值保存在一个列表中。 每次计算阈值b 按照李航老师的说法 所以最终b的取值为 将原问题转化为对偶问题,通过SMO算法,求得对偶问题的最佳解。 建立数据集 涉及到的公式和流程 代码写的还很幼稚,以后有机会会继续修改的。 参考资料:5-3 SMO算法
5-3-1 KKT条件
μ k g k ( x ∗ ) = 0 \mu_k g_k(x^*)=0 μkgk(x∗)=0
y i ( w T X i + b ) ⩾ 1 − ζ i y_i(w^TX_i+b)\geqslant1-\zeta_i yi(wTXi+b)⩾1−ζi
ζ i ⩾ 0 \zeta_i\geqslant0 ζi⩾0
α i ( y i ( w T X i + b ) − 1 + ζ i ) = 0 \alpha_i\Big(y_i(w^TX_i+b)-1+\zeta_i\Big)=0 αi(yi(wTXi+b)−1+ζi)=0
β i ζ i = 0 \beta_i\zeta_i=0 βiζi=0
i = 1 , 2 , . . . m i=1,2,...m i=1,2,...m
在对偶问题中,我们知道 α i \alpha_i αi的不等式约束为
0 ⩽ α i ⩽ C 0\leqslant\alpha_i\leqslant C 0⩽αi⩽C
则 y i ( w T X i + b ) − 1 + ζ i ⩾ 0 y_i(w^TX_i+b)-1+\zeta_i\geqslant0 yi(wTXi+b)−1+ζi⩾0
由因为 α i + β i = C \alpha_i+\beta_i=C αi+βi=C,
故 β i = C \beta_i=C βi=C
因为 β i ζ i = 0 \beta_i\zeta_i=0 βiζi=0
故 ζ i = 0 \zeta_i=0 ζi=0
最终 y i ( w T X i + b ) ⩾ 1 y_i(w^TX_i+b)\geqslant1 yi(wTXi+b)⩾1
则 β i = 0 \beta_i=0 βi=0, ζ i ⩾ 0 \zeta_i\geqslant0 ζi⩾0
又因为 y i ( w T X i + b ) − 1 + ζ i = 0 y_i(w^TX_i+b)-1+\zeta_i=0 yi(wTXi+b)−1+ζi=0
故 y i ( w T X i + b ) = 1 − ζ ⩽ 1 y_i(w^TX_i+b)=1-\zeta\leqslant1 yi(wTXi+b)=1−ζ⩽1
故 y i ( w T X i + b ) − 1 + ζ i = 0 y_i(w^TX_i+b)-1+\zeta_i=0 yi(wTXi+b)−1+ζi=0
又因为 β i > 0 \beta_i>0 βi>0,所以 ζ i = 0 \zeta_i=0 ζi=0
所以 y i ( w T X i + b ) = 1 y_i(w^TX_i+b)=1 yi(wTXi+b)=1
{ α i = 0 y i ( w T X i + b ) ⩾ 1 对 应 自 由 变 量 , 对 确 定 分 类 超 平 面 不 起 作 用 0 < α i < C y i ( w T X i + b ) = 1 支 撑 向 量 α i = C y i ( w T X i + b ) ⩽ 1 违 反 了 不 等 式 约 束 , 进 行 了 惩 罚 \begin{cases} \alpha_i=0&y_i(w^TX_i+b)\geqslant1 &对应自由变量,对确定分类超平面不起作用\\ 0<\alpha_i<C&y_i(w^TX_i+b)=1& 支撑向量\\ \alpha_i=C&y_i(w^TX_i+b)\leqslant1&违反了不等式约束,进行了惩罚 \end{cases} ⎩⎪⎨⎪⎧αi=00<αi<Cαi=Cyi(wTXi+b)⩾1yi(wTXi+b)=1yi(wTXi+b)⩽1对应自由变量,对确定分类超平面不起作用支撑向量违反了不等式约束,进行了惩罚
5-3-2 SMO算法
5-3-2-1求解子问题
s = y 1 y 2 s=y_1y_2 s=y1y2
v i = ∑ k = 3 m y k α k K i k v_i=\sum\limits_{k=3}^my_k\alpha_kK_{ik} vi=k=3∑mykαkKik
= 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + s K 12 α 1 α 2 + y 1 v 1 α 1 + y 2 v 2 α 2 − α 1 − α 2 + c =\frac{1}{2}K_{11}\alpha_1^2+\frac{1}{2}K_{22}\alpha_2^2+sK_{12}\alpha_1\alpha_2+y_1v_1\alpha_1+y_2v_2\alpha_2-\alpha_1-\alpha_2+c =21K11α12+21K22α22+sK12α1α2+y1v1α1+y2v2α2−α1−α2+c
故 α 1 = y 1 ξ − s α 2 \alpha_1=y_1\xi-s\alpha_2 α1=y1ξ−sα2
令 w = y 1 ξ w=y_1\xi w=y1ξ
则 α 1 = w − s α 2 \alpha_1 = w-s\alpha_2 α1=w−sα2
上式为
= ( 1 2 K 11 + 1 2 K 22 − K 12 ) α 2 2 − ( w s K 11 − w s K 12 + s y 1 v 1 − y 2 v 2 + 1 − s ) α 2 + c ′ =\Big(\frac{1}{2}K_{11}+\frac{1}{2}K_{22}-K_{12}\Big)\alpha_2^2-(wsK_{11}-wsK_{12}+sy_1v_1-y_2v_2+1-s)\alpha_2+c' =(21K11+21K22−K12)α22−(wsK11−wsK12+sy1v1−y2v2+1−s)α2+c′
( K 11 + K 22 − 2 K 12 ) α 2 = w s K 11 − w s K 12 + s y 1 v 1 − y 2 v 2 + 1 − s (K_{11}+K_{22}-2K_{12})\alpha_2=wsK_{11}-wsK_{12}+sy_1v_1-y_2v_2+1-s (K11+K22−2K12)α2=wsK11−wsK12+sy1v1−y2v2+1−s
等号右边可以进一步化简为
α 2 o l d ( K 11 + K 22 − 2 K 12 ) + y 2 ( ( u 1 − y 1 ) − ( u 2 − y 2 ) ) \alpha_2^{old}(K_{11}+K_{22}-2K_{12})+y_2\Big((u_1-y_1)-(u_2-y_2)) α2old(K11+K22−2K12)+y2((u1−y1)−(u2−y2))
令
η = K 11 + K 22 − 2 K 12 \eta=K_{11}+K_{22}-2K_{12} η=K11+K22−2K12
E i = u i − y i E_i=u_i-y_i Ei=ui−yi即原来的预测值与真实值之间的差距
则 α 2 u n c l i p p e d = α 2 o l d + y 2 ( E 1 − E 2 ) η \alpha_2^{unclipped}=\alpha_2^{old}+\frac{y2(E_1-E_2)}{\eta} α2unclipped=α2old+ηy2(E1−E2)
所以我们需要计算下 α 2 \alpha_2 α2的取值范围
α 1 y 1 + α 2 y 2 = − ∑ i = 3 m α i y i = ξ \alpha_1y_1+\alpha_2y_2=-\sum\limits_{i=3}^m\alpha_iy_i=\xi α1y1+α2y2=−i=3∑mαiyi=ξ
0 ⩽ α 1 ⩽ C 0\leqslant\alpha_1\leqslant C 0⩽α1⩽C
0 ⩽ α 2 ⩽ C 0\leqslant\alpha_2\leqslant C 0⩽α2⩽C
{ L = max { α 1 + α 2 − C , 0 } H = min { α 1 + α 2 , C } y 1 y 2 = 1 L = max { 0 , α 2 − α 1 } H = min { C + α 2 − α 1 , C } y 1 y 2 = − 1 \begin{cases} L=\max\{\alpha_1+\alpha_2-C,0\}&H=\min\{\alpha_1+\alpha_2,C\}&y_1y_2=1\\ L=\max\{0,\alpha_2-\alpha_1\}&H=\min\{C+\alpha_2-\alpha_1,C\}&y_1y_2=-1 \end{cases} {L=max{α1+α2−C,0}L=max{0,α2−α1}H=min{α1+α2,C}H=min{C+α2−α1,C}y1y2=1y1y2=−1
α 2 n e w = { H α j u n c l i p p e d > H α j u n c l i p p e d L ⩽ α j u n c l i p p e d ⩽ H L α u n c l i p p e d < L \alpha_2^{new}= \begin{cases} H&\alpha_j^{unclipped}>H\\ \alpha_j^{unclipped}&L\leqslant\alpha_j^{unclipped}\leqslant H\\ L&\alpha^{unclipped}<L \end{cases} α2new=⎩⎪⎨⎪⎧HαjunclippedLαjunclipped>HL⩽αjunclipped⩽Hαunclipped<L
α 1 n e w = α 1 o l d + s ( α 2 o l d − α 2 n e w ) \alpha_1^{new}=\alpha_1^{old}+s(\alpha_2^{old}-\alpha_2^{new}) α1new=α1old+s(α2old−α2new)5-3-2-2 优化变量的寻找
SMO算法称第1个变量的寻找过程为外层循环。外层循环在训练样本中选取违反KKT条件最严重的样本点,将其对应的变量作为第1个变量。具体地,检查训练样本点 ( x i , y i ) (x_i,y_i) (xi,yi)是否满足KKT条件,即
{ α i = 0 y i g ( x i ) ⩾ 1 对 应 自 由 变 量 , 对 确 定 分 类 超 平 面 不 起 作 用 0 < α i < C y i g ( x i ) = 1 支 撑 向 量 α i = C y i g ( x i ) ⩽ 1 违 反 了 不 等 式 约 束 , 进 行 了 惩 罚 \begin{cases} \alpha_i=0&y_ig(x_i)\geqslant1 &对应自由变量,对确定分类超平面不起作用\\ 0<\alpha_i<C&y_ig(x_i)=1& 支撑向量\\ \alpha_i=C&y_ig(x_i)\leqslant1&违反了不等式约束,进行了惩罚 \end{cases} ⎩⎪⎨⎪⎧αi=00<αi<Cαi=Cyig(xi)⩾1yig(xi)=1yig(xi)⩽1对应自由变量,对确定分类超平面不起作用支撑向量违反了不等式约束,进行了惩罚
其中, g ( x i ) = ∑ j = 1 m α j y j K ( x i , x j ) + b g(x_i)=\sum\limits_{j=1}^m\alpha_jy_jK(x_i,x_j)+b g(xi)=j=1∑mαjyjK(xi,xj)+b
SMO算法称选择第2个变量的过程为内层循环。假设在外层循环中已经找到第1个变量 α 1 \alpha_1 α1,现在要在内层循环中找第2个变量 α 2 \alpha_2 α2。第2个变量选择的标准是希望能够使 α 2 \alpha_2 α2有足够大的变化5-3-2-3 计算阈值b和差值 E i E_i Ei
根据KKT条件
b 1 n e w = b ∗ − E 1 + y 1 K 11 ( α 1 ∗ − α 1 n e w ) + y 2 K 21 ( α 2 ∗ − α 2 n e w ) b_1^{new}=b^*-E_1+y_1K_{11}(\alpha_1^*-\alpha_1^{new})+y_2K_{21}(\alpha_2^*-\alpha_2^{new}) b1new=b∗−E1+y1K11(α1∗−α1new)+y2K21(α2∗−α2new)
b 2 n e w = b ∗ − E 2 + y 1 K 12 ( α 1 ∗ − α 1 n e w ) + y 2 K 22 ( α 2 ∗ − α 2 n e w ) b_2^{new}=b^*-E_2+y_1K_{12}(\alpha_1^*-\alpha_1^{new})+y_2K_{22}(\alpha_2^*-\alpha_2^{new}) b2new=b∗−E2+y1K12(α1∗−α1new)+y2K22(α2∗−α2new)

这一部分的理论推导通过看知乎上的一篇文章弄懂了
(1)当 α 1 n e w \alpha_1^{new} α1new和 α 2 n e w \alpha_2^{new} α2new都在0,C之间,根据 α 1 \alpha_1 α1和 α 2 \alpha_2 α2的关系曲线可以知道,此时 α 2 \alpha_2 α2不再边界点上取得最小值,所以 α 2 n e w = α 2 u n c l i p p e d \alpha_2^{new}=\alpha_2^{unclipped} α2new=α2unclipped
故 α 2 \alpha_2 α2为 ( K 11 + K 22 − 2 K 12 ) α 2 = w s K 11 − w s K 12 + s y 1 v 1 − y 2 v 2 + 1 − s = 0 (K_{11}+K_{22}-2K_{12})\alpha_2=wsK_{11}-wsK_{12}+sy_1v_1-y_2v_2+1-s=0 (K11+K22−2K12)α2=wsK11−wsK12+sy1v1−y2v2+1−s=0的点
根据这个式子,可以推导出 b 1 n e w b_1^{new} b1new和 b 2 n e w b_2^{new} b2new的等式
(2)当 α 1 n e w \alpha_1^{new} α1new和 α 2 n e w \alpha_2^{new} α2new同时不满足0,C之间,则根据 α 1 \alpha_1 α1和 α 2 \alpha_2 α2的关系曲线,当y1y2== 1时,只能一个为0,一个为C;当y1y2== -1时,只能同时为0或者同时为C,经过推导可以知道, b n e w b^{new} bnew必须在 [ b 1 n e w , b 2 n e w ] [b_1^{new},b_2^{new}] [b1new,b2new]之间
{ b 1 n e w 0 < α 1 n e w < C b 2 n e w 0 < α 2 n e w < C b 1 n e w + b 2 n e w 2 o t h e r w i s e \begin{cases} b_1^{new}&0<\alpha_1^{new}<C\\ b_2^{new}&0<\alpha_2^{new}<C\\ \frac{b_1^{new}+b_2^{new}}{2}&otherwise \end{cases} ⎩⎪⎨⎪⎧b1newb2new2b1new+b2new0<α1new<C0<α2new<Cotherwise5-4 总结SVM
5-5 python实现
import numpy as np
import matplotlib.pyplot as plt
X=np.array([
[-1,6],
[1,5],
[1,7],
[3,3],
[5,4],
[2,0]])
y=np.array([1,1,1,-1,-1,-1])
plt.scatter(X[y==1,0],X[y==1,1],label='+',color='r')
plt.scatter(X[y==-1,0],X[y==-1,1],label='-',color='b')
plt.legend()

1.初始化alpha,E,C,b
2.根据kkt条件选取优化变量
{ α i = 0 y i g ( x i ) ⩾ 1 对 应 自 由 变 量 , 对 确 定 分 类 超 平 面 不 起 作 用 0 < α i < C y i g ( x i ) = 1 支 撑 向 量 α i = C y i g ( x i ) ⩽ 1 违 反 了 不 等 式 约 束 , 进 行 了 惩 罚 \begin{cases} \alpha_i=0&y_ig(x_i)\geqslant1 &对应自由变量,对确定分类超平面不起作用\\ 0<\alpha_i<C&y_ig(x_i)=1& 支撑向量\\ \alpha_i=C&y_ig(x_i)\leqslant1&违反了不等式约束,进行了惩罚 \end{cases} ⎩⎪⎨⎪⎧αi=00<αi<Cαi=Cyig(xi)⩾1yig(xi)=1yig(xi)⩽1对应自由变量,对确定分类超平面不起作用支撑向量违反了不等式约束,进行了惩罚class SVM:
def __init__(self,kernel='linear',max_iter=200):
self.max_iter = max_iter
self._kernel = kernel
def _calE(self,i):
return self._u(i)-self.y[i]
def _u(self,i):
return np.sum(self.X.dot(self.X[i])*self.alpha*self.y)+self.b
def _KKT(self,i):
yu = self._u(i)*self.y[i]
if np.abs(self.alpha[i] - 0) <= self.epsilon:
return yu >= 1+self.epsilon
elif 0<self.alpha[i]<self.C:
return np.abs(yu - 1) <= self.epsilon
else:
return yu <= 1-self.epsilon
def kernel(self,i,j):
if self._kernel == 'linear':
return self.X[i].dot(self.X[j])
def _new_alpha(self,i,j):
if self.y[i]== self.y[j]:
L = max(0,self.alpha[i]+self.alpha[j]-self.C)
H = min(self.C,self.alpha[i]+self.alpha[j])
else:
L = max(0,self.alpha[j]-self.alpha[i])
H = min(self.C,self.C+self.alpha[j]-self.alpha[i])
eta = self.kernel(i,i)+self.kernel(j,j)-2*self.kernel(i,j)
if eta==0:
print("bug",i,j)
alpha_2_un = self.alpha[j]+self.y[j]*(self.E[i]-self.E[j])/eta
if alpha_2_un > H:
alpha_2_new = H
elif alpha_2_un < L:
alpha_2_new = L
else:
alpha_2_new = alpha_2_un
alpha_1_new=self.alpha[i]+self.y[i]*self.y[j]*(self.alpha[j]-alpha_2_new)
return alpha_1_new,alpha_2_new
def fit(self,features,labels,C=1,epsilon=1e-3):
self.X = features
self.y = labels
self.b = 0
self.C = C
self.alpha = np.zeros(len(self.X))
self.epsilon=epsilon
self.E = np.array([self._calE(k) for k in range(len(self.X))])
self.w = 0
for internum in range(self.max_iter):
index_list = np.array(np.where(self.alpha > self.epsilon)).flatten()
non_list = np.array(np.where(abs(self.alpha) <= self.epsilon)).flatten().copy()
all_list = np.hstack([index_list,non_list])
for k in all_list:
if self._KKT(k):
continue
j_index = index_list[index_list!=k]
j_non = non_list[non_list!=k]
if(len(j_index))>1:
E_temp=np.abs(self.E[j_index]-self.E[k])
j=j_index[np.argmax(E_temp)]
i=k
break
else:
E_temp=np.abs(self.E[j_non]-self.E[k])
j=j_non[np.argmax(E_temp)]
i=k
break
alpha_1_new,alpha_2_new=self._new_alpha(i,j)
b1_new = -self.E[i]-self.y[i]*self.kernel(i,i)*(alpha_1_new-self.alpha[i])-self.y[j]*self.kernel(j,i)*(alpha_2_new-self.alpha[j])+self.b
b2_new = -self.E[j]-self.y[i]*self.kernel(i,j)*(alpha_1_new-self.alpha[i])-self.y[j]*self.kernel(j,j)*(alpha_2_new-self.alpha[j])+self.b
if 0 < alpha_1_new <self.C:
b_new = b1_new
elif 0 < alpha_2_new <self.C:
b_new = b2_new
else:
b_new = (b1_new+b2_new)/2
self.alpha[i]=alpha_1_new
self.alpha[j]=alpha_2_new
self.b = b_new
for k in range(len(self.X)):
self.E[k]=self._calE(k)
self.w = self._weight()
def _weight(self):
return np.sum(self.X*np.tile(self.y.reshape(-1,1),(1,self.X.shape[1]))*np.tile(self.alpha.reshape(-1,1),(1,self.X.shape[1])),axis=0)
clf = SVM()
clf.fit(X,y,C=1000)
clf.alpha
w3 = clf.w
b3 = clf.b
clf.alpha
array([0. , 0.132, 0. , 0.132, 0. , 0. ])
x_plot=np.linspace(-1,5,10000)
y_plot=(-b-w[0]*x_plot)/w[1]
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==-1,0],X[y==-1,1])
plt.plot(x_plot,y_plot)

from sklearn.svm import LinearSVC
clf = LinearSVC()
clf.fit(X,y)
w0=clf.coef_
b0=clf.intercept_
x_plot=np.linspace(-1,5,1000)
y_plot=(-b-w[0]*x_plot)/w[1]
y_plot2=(-b0-w0[0,0]*x_plot)/w0[0,1]
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==-1,0],X[y==-1,1])
plt.plot(x_plot,y_plot)
plt.plot(x_plot,y_plot2)

from sklearn.datasets import load_iris
iris=load_iris()
X=iris.data[iris.target!=2]
X=X[:,0:2]
y=iris.target[iris.target!=2]
y[y==0]=-1
clf = SVM(max_iter=1000)
clf.fit(X,y,C=1000)
clf.alpha
w = clf.w
b = clf.b
clf.alpha
array([ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, -2.22044605e-16, 0.00000000e+00,
7.67179484e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 2.52991452e+01, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 3.29709400e+01, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00])
x_plot=np.linspace(4,7,10000)
y_plot=(-b-w[0]*x_plot)/w[1]
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==-1,0],X[y==-1,1])
plt.plot(x_plot,y_plot)

from sklearn.svm import LinearSVC
clf = LinearSVC(C=1000)
clf.fit(X,y)
w0=clf.coef_
b0=clf.intercept_
x_plot=np.linspace(4,7,1000)
y_plot=(-b-w[0]*x_plot)/w[1]
y_plot2=(-b0-w0[0,0]*x_plot)/w0[0,1]
plt.scatter(X[y==1,0],X[y==1,1])
plt.scatter(X[y==-1,0],X[y==-1,1])
plt.plot(x_plot,y_plot,label='myself')
plt.plot(x_plot,y_plot2,label='svm')
plt.legend()
/anaconda3/lib/python3.7/site-packages/sklearn/svm/base.py:931: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.
"the number of iterations.", ConvergenceWarning)

https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/tr-98-14.pdf