生成式深度学习(第二版)-译文-第六章-归一化流模型
章节目标:
- 了解归一化流模型如何利用变量方程的变化。
- 知道 雅可比行列式(Jacobian determinant)在计算显式密度函数中的决定性作用。
- 理解我们如何使用耦合层来限制雅可比形式。
- 理解神经网络该如何设计成可逆。
- 构建一个RealNVP模型 — 一个归一化流的特定例子,以生成2D空间中的点。
- 使用RealNVP模型来生成新的点,看起来像是从数据分布中直接抽取。
- 了解RealNVP模型的两个关键拓展,GLOW 和 FFJORD。
截至目前,我们讨论了三个不同的生成式模型家族: VAE, GAN 和 AR 模型。每一种代表了一种不同的方式来解决对分布 p(x) 建模的挑战,要么引入一个隐变量,从中可以轻松采样 (以及利用VAEs中的解码器或者GAN中的生成器进行转换),或者易于驾驭地将分布建模为前序元素值的函数 (AR模型)。
在本章中,我们将看到一个新的生成式建模家族 — 归一化流模型。我们将看到,归一化流与 AR模型和 VAEs 都具有一定的相似性。与AR模型类似,归一化流可以显式样、易于驾驭地建模数据生成分布 p(x)。 与VAEs类似,归一化流尝试将数据 映射到一个简单一些的分布,例如高斯分布。其中的关键差异在于,归一化流在映射函数上施加了一些限制,使得它是可逆的,因此可以用于生产新的数据点。
在本章第一节中,在使用Keras实现一个名为RealNVP的归一化流模型之前,我们将进一步从细节上深入这一定义。我们也将看到归一化流可以被拓展到创建更多强大的模型,例如GLOW和 FFJORD。
简介
我们将以一则短故事开始,来展现归一化流背后的关键概念。
| JACOB 和 THE F.L.O.W. 机器 |
|---|
| 访问一个小乡村后,你注意到一个看起来颇为神秘的商店,门上的标识写到 JACOB’s。好奇的,你小心翼翼的进入,并问站在柜台的老人他有些什么东西可以售卖(图6-1)。 |
| 老人回复到,它提供了一个服务,可以数字化画作。在商店后面搜索了一阵之后,他拿出了一个银盒,上有浮雕字母 F.L.O.W. 。他告诉你这代表 Finding Likeness of Watercolors,这大概描述了机器做的事情。你决定让这个机器试试。 |
| 隔天,你返回商店,给店主一组你最喜欢的画作,他把这些画作传给机器。 F.L.O.W.机器开始发出响声,片刻之后输出一组数字,看起来像是随机生成的。店主给你这个列表,并开始走动,计算你需要为他的数字化服务和 F.L.O.W. 盒付费多少。你询问店主,你该对这个长数字list做什么,以及你该如何取回你最喜欢的画作。 |
| 店主转动眼睛,似乎答案是显然的。他走回机器处,把这一长串数字从另一侧输入。你听到机器轰鸣,等待,困惑,最终你你的原画作从它们进去的地方掉下来。 |
| 终于拿回来了自己的画作,你放心了,你觉得最好的方式是把它们放到阁楼上保存。然而,在你离开之前,店主引导你到了商店的另一角落,这里巨大钟悬挂在橼子上。他用力击打着钟形曲线,震动传达整个商店。 |
| 你胳膊下方的 F. L. O. W. 机器开始嘶鸣,就好像有一组新的数字刚刚传入。片刻之后,更多美丽的水彩画从F.L.O.W.机器掉下来,但是它们与你之前寻求数字化的并不相同。尽管他们的风格和形式与你原来那组画作类似,但确实每一个都是独一无二的。 |
| 你问店主,这个不可思议的机器是如何工作的。他解释道,魔法在于他构建了一个特殊的处理,可以确保转换是异常迅速的,并且计算上也比较简单,但又足够复杂,可以将钟声的震动转换成油画中的复杂模式和形状。 |
| 认识到该设备的巨大潜力之后,你很痛快的为之买单并离开了商店,你为自己高兴,你终于能通过某种方式生成你最喜欢风格的画作。 |

上面关于Jacob和 F.L.O.W. 机器的故事,事实上是归一化流模型的一个描述。在使用Keras实现一个实例之前,让我们进一步从细节上探索归一化流的理论。
归一化流
归一化流模型的动机与第三章中介绍的VAEs类似。回忆一下,在VAEs中,我们学习了一个复杂分布和一个相对简单、易于采样的分布之间的编码器映射函数。同时,我们也学习了一个解码器映射函数,可以把简单分布映射到复杂分布, 使得我们可以从简单分布中取样一个点 z ,并应用学到的变换来生成一个新的数据点。概率上来讲,解码器对 p(x|z)进行建模,而编码器只是真实 p(z|x) 的一个近似 q(z|x) — 编码器是两个完全不同的神经网络。
在一个归一化流模型中,解码函数被设计为编码函数的完美逆,且要便于计算,赋予归一化流易于驾驭地特性。然而,神经网络本身并不是默认可逆的。这提出了一个问题: 我们怎么创造一个可逆过程,可以在复杂分布(例如一组水彩画的数据生成分布)以及一个更简单分布(例如一个钟形高斯分布)之间互相转换,同时仍然能够利用深度学习的灵活性和强大功能。
为了回答这一问题,我们首先需要理解一项名为 变量变化 (change of variables) 的技术。在这一小节,我们仅仅会处理一种仅2维的简单例子,使得我们可以一起看看归一化流在细节上到底是如何工作的。更复杂的例子只是这里展示基础技术的拓展。
Change of Variables
假定我们有一个定义在2D矩形X上的概率分布 p X ( x ) p_X(x) pX(x), x = ( x 1 , x 2 ) x = (x_1, x_2) x=(x1,x2),如图6-2所示。

该函数在分布域内(即, x 1 x_1 x1在[1,4]范围内, x 2 x_2 x2在[0,2]范围内)积分为1,因此,它表示一个定义良好的概率分布。我们可以写作如下形式:
∫ 0 2 ∫ 1 4 p X ( x ) d x 1 d x 2 = 1 \int_0^2\int_1^4 p_X(x) dx_1dx_2 = 1 ∫02∫14pX(x)dx1dx2=1
现在,我们想要对该分布进行平移和放缩,使得它定义在一个单位矩形Z上。这可以通过重新定义一个新变量 z = ( z 1 , z 2 ) z = (z_1, z_2) z=(z1,z2) 和 一个将X中每个点映射到Z中的某个点的函数 f f f来实现:
z = f ( x ) z = f(x) z=f(x)
z 1 = x 1 − 1 3 z_1 = \frac{x_1 - 1}{3} z1=3x1−1
z 2 = x 2 2 z_2 = \frac{x_2}{2} z2=2x2
注意,上面的函数是可逆 (invertible) 的。也就是,存在一个函数 g g g,其可以将每个 z z z 反映射回对应的原始 x x x。这一点对于变量变化是最基本的,否则的话,我们就不能在两个空间来回变换。我们可以通过简单充足 f f f 的方程来找到 g g g, 如下图6-3所示。

现在,我们需要看看,从 X 到 Z的变量变换如何影响概率分布 p X ( x ) p_X(x) pX(x)。我们可以把 g g g 的函数定义直接插入 p X ( x ) p_X(x) pX(x),将它转换成用 z z z定义的函数 p Z ( z ) p_Z(z) pZ(z):
p Z ( z ) = ( ( 3 z 1 + 1 ) − 1 ) ( 2 z 2 ) 9 = 2 z 1 z 2 3 p_Z(z) = \frac{((3z_1 + 1) - 1)(2z_2)}{9} =\frac{2z_1z_2}{3} pZ(z)=9((3z1+1)−1)(2z2)=32z1z2
但是,如果我们在单位矩形上对 p Z ( z ) p_Z(z) pZ(z)进行积分,我们将看到一个问题!
∫ 0 1 ∫ 0 1 2 z 1 z 2 3 d z 1 d z 2 = 1 6 \int_0^1\int_0^1 \frac{2z_1z_2}{3} dz_1dz_2 = \frac{1}{6} ∫01∫0132z1z2dz1dz2=61
变换后的函数 p Z ( z ) p_Z(z) pZ(z) 目前不在是一个合法的概率分布,因为它的积分只有 1 6 \frac{1}{6} 61。如果我们想要将数据的复杂分布函数转换成可采样的简单形式,我们必须确保其积分为1。
缺失的因子 (6) 是由于变换后的分布函数,其domain是原始domain的 1 6 \frac{1}{6} 61 — 原始的矩形面积为6,它被压缩到一个面积仅为1的单位矩形 Z。因此,我们需要在新的概率分布上乘以一个归一化因子,该因子等于面积的相对变化(或者在更高维度上的体积)。
幸运的,对于给定变换,我们有方法可以计算体积变换 — 它是变换雅可比行列式之绝对值。让我们解构它!
雅可比行列式
一个函数 z = f ( x ) z = f(x) z=f(x) 的雅可比 (Jacobian) 是其一阶偏微分矩阵,如下所示:
KaTeX parse error: Expected & or \\ or \cr or \end at position 53: …egin{bmatrix} #̲ 中括号 b,大括号 B,小括…
解释这点最好的方式是使用我们的例子。如果我们计算 z 1 z_1 z1 相对于 x 1 x_1 x1 的偏微分,我们得到 1 3 \frac{1}{3} 31。如果我们计算 z 1 z_1 z1 相对于 x 3 x_3 x3 的偏微分,我们得到 0。类似的,如果我们计算 z 2 z_2 z2 相对于 x 1 x_1 x1 的偏微分,我们得到 0。如果我们计算 z 2 z_2 z2 相对于 x 3 x_3 x3 的偏微分,我们得到 1 2 \frac{1}{2} 21。
因此,我们函数 f ( x ) f(x) f(x) 的雅可比矩阵如下:
J = ( 1 3 0 0 1 2 ) J = \begin{pmatrix} \frac{1}{3} & 0 \\ 0 & \frac{1}{2} \end{pmatrix} J=(310021)
行列式 (determinant) 仅针对方阵定义,并且等于通过将矩阵表示的变换应用于单位(超)立方体而创建的平行六面体的带符号体积。因此,在二维中,这只是通过将矩阵表示的变换应用于单位正方形而创建的平行四边形的带符号面积。
对 n 维矩阵的行列式计算有通用公式,时间复杂度为 O ( n 3 ) \mathcal{O}(n^3) O(n3)。对于我们的例子而言,我们仅需要计算二维公式,简记如下:
d e t ( a b c d ) = a d − b c det\begin{pmatrix} a & b \\ c & d \end{pmatrix} = ad - bc det(acbd)=ad−bc
因此,对我们的例子来说,雅可比行列式是 1 3 × 1 2 − 0 × 0 = 1 6 \frac{1}{3} \times \frac{1}{2} - 0 \times 0 = \frac{1}{6} 31×21−0×0=61。这是放缩系数 1 6 , 我们需要用来确保转换后的概率分布积分仍然为 1 \frac{1}{6}, 我们需要用来确保转换后的概率分布积分仍然为1 61,我们需要用来确保转换后的概率分布积分仍然为1
| 小贴士 |
|---|
| 根据定义,行列式是有符号的 — 也即,它可能是负的。因此,我们需要取雅可比行列式的绝对值 以获得体积的相对变化。 |
变量方程变换
现在,我们可以写下一个单一方程来描述变量 X 和 Z 之间的变换过程。这又被称作 变量方程变换 (change of variables equation, 如公式 6-1)
p X ( x ) = p Z ( z ) ∣ d e t ( ∂ z ∂ x ) ∣ p_X(x) = p_Z(z) |det(\frac{\partial z}{\partial x})| pX(x)=pZ(z)∣det(∂x∂z)∣
这个如何帮助我们构造一个生成式模型呢?关键在于理解: 如果 p Z ( z ) p_Z(z) pZ(z)是一个容易采样的简单分布 (例如,高斯分布),那么在理论上,我们需要做的是找到一个合适的可逆函数 f ( x ) f(x) f(x), 帮助我们把 X 映射到 Z,而对应的逆函数 g ( z ) g(z) g(z) 帮助我们把采样点 z 反映射到原始domain中的一个点 x。我们可以用前面的公式及雅可比行列式来找到数据分布 p ( x ) p(x) p(x)的一个准确的、易于驾驭的公式。
然而,上面的思路如果要付诸实践,有两个主要的挑战需要解决:
- 首先,高维矩阵的行列式在计算上尤为复杂 – 具体说来,其时间复杂度是 O ( n 3 ) \mathcal{O}(n^3) O(n3)。这在实操时完全不可接受。即使对一个小的32x32灰度图像,也有1024维。
- 其次,该如何计算可逆函数 f ( x ) f(x) f(x) 并不是非常明确。我们可以使用一个神经网络来找到某个函数 f ( x ) f(x) f(x),但是我们不一定能够对该神经网络求逆 — 神经网络通常只能在一个方向上工作!
为了求解上面两个问题,我们需要一个特殊的神经网络架构,确保变量函数 f f f 的变换是可逆的,并且其行列式是易于计算的。
在下一小节,我们将看到如何利用一项名为 real-valued non-volume preserving (RealNVP) 变换的技术来实现这点。
RealNVP
RealNVP 由 Dinh等在 2017年 首度提出。在论文中,作者展示了如何构建一个可把复杂数据分布转换为简单高斯的神经网络,并且仍然具备可逆性,且其雅可比易于求解。
| 运行本示例代码 |
|---|
| 本示例代码可以在随书附带的代码库以下路径找到: “notebooks/06_normflow/01_realnvp/realnvp.ipynb” |
| 该代码从Keras 官网的 RealNVP 教程(由 Mandolini Giorgio Maria等贡献) 修改而来。 |
Two Moons 数据集
我们将在本例中使用的数据集是使用 Python 库 sklearn 中的 make_moons 函数来实现。这会构建一个看起来像两弯新月的带噪声的2D点集数据集,如下图6-4所示。

构建数据集的代码如下样例6-1所示。
#样例 6-1 构建月亮数据集
# 生成一个带噪声、未归一化的3000点月亮数据库
data = datasets.make_moons(3000, noise=0.05)[0].astype("float32")
norm = layers.Normalization()
norm.adapt(data)
# 归一化数据库使得均值为0,方差为1
normalied_data = norm(data)
我们将构建一个 RealNVP 模型,该模型可以生成2D点,点的图案遵循和双月数据集类似的分布。尽管这是一个简单的样例,它能帮助我们从细节上理解一个归一化流模型在实际中如何工作。
首先,我们需要引入一个新的层类型,成为 耦合层 (a coupling layer)。
耦合层
对于每个输入元素,一个耦合层生成一个尺度和平移因子。换句话说,它生成与输入相同尺寸的两个张量,一个是尺度因子,一个是平移因子,如下图6-5所示。

为了针对我们的简单样例构建一个耦合层,我们可以堆叠Dense层来创建一个尺度输出,以及另一个不同的Dense集来创建平移输出,如下样例6-2所示。
| 小贴士 |
|---|
| 对于图像,耦合层模块使用Conv2D层,而非Dense层。 |
# Keras中的耦合层
def Coupling():
# 耦合层模组的输入是2维
input_layer = layers.Input(shape=2)
# Scaling 流是一组256尺寸的Dense层之堆叠
s_layer_1 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(input_layer)
s_layer_2 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(s_layer_1)
s_layer_3 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(s_layer_2)
s_layer_4 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(s_layer_3)
# 最后的scaling层尺寸为2,激活函数维 tanh
s_layer_5 = layers.Dense(
2, activation = "tanh",
kernel_regularizer = regularizers.l2(0.01)
)(s_layer_4)
# translation 流是一组256尺寸的Dense层之堆叠
t_layer_1 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(input_layer)
t_layer_2 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(t_layer_1)
t_layer_3 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(t_layer_2)
t_layer_4 = layers.Dense(
256, activation = "relu",
kernel_regularizer = regularizers.l2(0.01)
)(t_layer_3)
# 最后的translation层尺寸为2,激活函数维 linear
t_layer_5 = layers.Dense(
2, activation = "linear",
kernel_regularizer = regularizers.l2(0.01)
)(t_layer_4)
# coupling 层由Keras Model构建,包含两个输出 (尺度和放缩因子)
return models.Model(inputs = input_layer, outputs = [s_layer_5, t_layer_5])
注意,通道数在最终降低到跟输入相同通道数之前,是如何临时增加以允许学到更复杂的表示。在原始的论文里,作者也在每层使用了正则项来惩罚大的权重。
将数据传递给耦合层
耦合层的架构并不是特别有趣 — 真正让它独特的是数据在传入这层时掩膜和变换的方式,如图6-6所示。
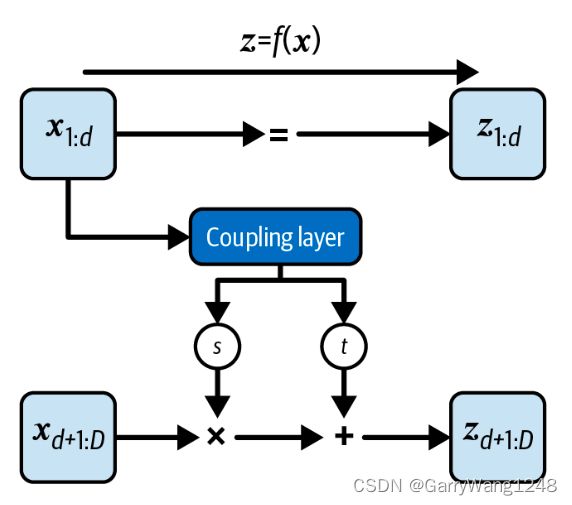
注意,只有数据的前 d 层传入第一个耦合层 — 剩下的 D - d 维则是完全掩膜的 (也即,设为0)。在我们的简单例子中,D=2,选择 d = 1 意味着耦合层不是看到两个值 ( x 1 , x 2 ) (x_1, x_2) (x1,x2),而是只能看到 ( x 1 , 0 ) (x_1, 0) (x1,0)。
耦合层的输出是 尺度 和 平移 因子。这些也是被掩膜的,但是这次是反向掩膜到前序,使得只有后半部分通过 — 也即,在我们的例子中,我们得到 ( 0 , s 2 ) (0, s_2) (0,s2) 和 ( 0 , t 2 ) (0, t_2) (0,t2)。这些被逐元素的应用于输入 x 2 x_2 x2 的第二半部分,而输入 x 1 x_1 x1的前半部分则简单的直接通过,而完全无需更新。总而言之,对于一个维度为D (d < D) 的向量,更新方程如下:
z 1 : d = x 1 : d z_{1:d} = x_{1:d} z1:d=x1:d
z d + 1 : D = x d + 1 : D ⊙ e x p ( s ( x 1 : d ) ) + t ( x 1 : d ) z_{d+1:D} = x_{d+1:D} \odot exp(s(x_{1:d})) + t(x_{1:d}) zd+1:D=xd+1:D⊙exp(s(x1:d))+t(x1:d)
你可能在怀疑为什么我们要这么麻烦来构建一个层对这么多信息加掩膜。如果我们进一步研究该函数的雅可比矩阵,那么答案是显然的:
∂ z ∂ x = [ I 0 ∂ z d + 1 : D ∂ x 1 : d d i a g ( e x p [ s ( x 1 : d ) ] ) ] \frac{\partial z} {\partial x} = \begin{bmatrix} \mathbf{I} & 0 \\ \frac{\partial z_{d+1:D}}{\partial x_{1:d}} & diag(exp[s(x_{1:d})]) \end{bmatrix} ∂x∂z=[I∂x1:d∂zd+1:D0diag(exp[s(x1:d)])]
左上 d x d d x d dxd 子矩阵就是一个 identity matrix,因为 z 1 : d = x 1 : d z_{1:d} = x_{1:d} z1:d=x1:d。这些元素直接通过,而无需更新。右上子矩阵式,因为$z_{1:d} $ 并不依赖于 x d + 1 : D x_{d+1:D} xd+1:D。
左下子矩阵是复杂的,我们并不寻求去简化这一部分。右下子矩阵是一个简单的对角阵,以元素 e x p ( s ( x 1 : d ) ) exp(s(x_{1:d})) exp(s(x1:d))来进行填充,因为$z_{d+1:D} $ 线性依赖于 x d + 1 : D x_{d+1:D} xd+1:D,且梯度只依赖于尺度因子 (并不依赖于平移因子)。图6-7展示了该矩阵的图,其中只有非零元素以彩色标识。

注意,在对角线以上区域并没有非零元素 — 因此,这个矩阵形式被称为 下三角。现在,我们看到了将矩阵如此结构化的好处 — 下三角矩阵的行列式就是对角线元素的乘积。换句话说,行列式并不依赖于左下子矩阵的复杂梯度。
因此,我们可以把矩阵的行列式写成如下形式:
d e t ( J ) = e x p [ ∑ j s ( x 1 : d ) j ] det(J) = exp[\sum \limits_j s(x_{1:d})_j] det(J)=exp[j∑s(x1:d)j]
这是易于计算的,这是我们构建归一化流模型两个原始目标之一。
另一个目标是该函数可以轻松求逆。当我们使用重组前向方程的方式写下逆函数时,我们可以看到这也是成立的。逆函数如下:
x 1 : d = z 1 : d x_{1:d} = z_{1:d} x1:d=z1:d
x d + 1 : D = ( z d + 1 : D − t ( x 1 : d ) ) ⊙ e x p ( − s ( x 1 : d ) ) x_{d+1:D} = (z_{d+1:D} - t(x_{1:d})) \odot exp(-s(x_{1:d})) xd+1:D=(zd+1:D−t(x1:d))⊙exp(−s(x1:d))
图6-8展示了等价图。

现在,我们几乎有了用以构建 RealNVP 模型的几乎所有东西。但是,仍然有一个问题遗留 — 我们该如何更新输入的前 d 个元素?当前来看,模型对他们完全没做任何改变!
耦合层堆叠
为了解决这一问题,我们可以使用一个简单trick。如果我们把耦合层互相堆叠起来,但是改变掩膜模式,那些在某层不变的层在下一层得到更新。这一架构能够学习数据更复杂的表示,因为它本身是更复杂的神经网络。
这种耦合层的复合之雅可比行列式计算仍然简单,因为线性代数告诉我们,矩阵乘积之行列式 等于 行列式 之乘积。类似的,两个函数复合之逆就是其逆的复合,如下方程所示:
d e t ( A B ˙ ) = d e t ( A ) d e t ( B ) det(A \dot B) = det(A) det(B) det(AB˙)=det(A)det(B)
( f b ∘ f a ) − 1 = f a − 1 ∘ f b − 1 (f_b \circ f_a)^{-1}= f_a^{-1} \circ f_b^{-1} (fb∘fa)−1=fa−1∘fb−1
因此,当我们堆叠耦合层时,每次翻转掩膜,我们都可以构建一个足以对整个输入张量进行变换的神经网络,同时仍然可以保留两大基本特性: 雅可比行列式简单可计算 以及 可逆。图6-9给出了全局结构。

训练RealNVP模型
既然我们已经构建了 RealNVP 模型,我们可以训练它来学习 双月数据集 的复杂分布。记住,我们希望能够最小化该模型下 数据的负对数似然 ( − l o g p X ( x ) - log p_X(x) −logpX(x))。使用方程 6-1,我们将该目标重写如下:
− l o g p X ( x ) = − l o g p Z ( z ) − l o g ∣ d e t ( ∂ z ∂ x ) ∣ - log p_X(x) = - log p_Z(z) - log |det(\frac{\partial z}{\partial x})| −logpX(x)=−logpZ(z)−log∣det(∂x∂z)∣
我们把前向过程 f f f 的 目标输出分布 p Z ( z ) p_Z(z) pZ(z) 选定为 标准高斯,因为我们可以很容易从该分布采样。我们通过其逆过程 g g g 可以很容易将一个从高斯分布中采样得来的点反向转换到原始的图像域, 如图6-10所示。

样例 6-3 使用典型的 Keras Model 展示了我们该如何构建一个 RealNVP 网络。
# 在Keras中构建 RealNVP
class RealNVP(models.Model):
def __init__(self, input_dim, coupling_layers, coupling_dim, regularization):
super(RealNVP, self).__init__()
self.coupling_layers = coupling_layers
# 目标分布是标准2D正态分布
self.distribution = tfp.dirstributions.MultivariateNormalDiag(loc = [0.0, 0.0], scale_diag = [1.0, 1.0])
# 构建轮换的 mask 模式
self.masks = np.array([[0, 1], [1, 0]] * (coupling_layers // 2), dtype = "float32")
self.loss_tracker = metrics.Mean(name = "loss")
# 一组耦合层定义了RealNVP
self.layers_list = [Coupling(input_dim, coupling_dim, regularization) for i in range(coupling_layers)]
@property
def metrics(self):
return [self.loss_tracker]
def call(self, x, training = True):
log_det_inv = 0
direction = 1
if training:
direction = -1
# 在网络的主call函数中,我们对耦合层将进行循环,如果training = true,则我们在层上继续前向推进(也即,从数据到隐空间)。如果training = fasle,则我们在层上反向推进(也即,从隐空间到数据)。
for i in range(self.coupling_layers)[::direction]:
x_masked = x * self.masks[i]
reversed_mask = 1 - self.masks[i]
s, t = self.layers_list[i](x_masked)
s *= reversed_mask
t *= reversed_mask
gate = (direction - 1) / 2
# 这一行描述了依赖于direction的前向和后向方程 (试着代入 direction = -1 和 direction = -1 以自行证明)
x = (
reversed_mask
* (x * tf.exp(direction * s) + direction * t * tf.exp(gate+s))
+ x_masked
)
# 雅可比的对数行列式,我们计算损失函数所必须得,简单来说就是尺度因子之和
log_det_inv += gate * tf.reduce_sum(s, axis = 1)
return x, log_det_inv
def log_loss(self, x):
y, logdet = self(x)
# 损失函数是负的转换后数据对数概率之和,在我们的目标高斯分布之下 以及雅可比的对数行列式
log_likelihood = self.distribution.log_prob(y) + logdet
return -tf.reduce_mean(log_likelihood)
def train_step(self, data):
with tf.GradientTape()as tape:
loss = self.log_loss(data)
g = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(g, self.trainable_variables))
self.loss_tracker.update_state(loss)
return {"loss":self.loss_tracker.result()}
def test_step(self,data):
loss = self.log_loss(data)
self.loss_trakcer.update_state(loss)
return {"loss":self.loss_tracker.result()}
model = RealNVP(
input_dim = 2,
coupling_layers = 6,
coupling_dim = 256,
regularization = 0.01
)
model.compile(optimizer=optimizer.Adam(learning_rate=0.0001))
model.fit(normalized_data, batch_size = 256, epochs = 300)
RealNVP模型分析
一旦模型训练完毕,我们可以用它将训练数据集转换到隐空间(使用前向方向,f), 更重要的是,也可以用它将隐空间中的一个采样点转换到 看起来像是从原始数据分布采样得来一样(使用反方向,g)。
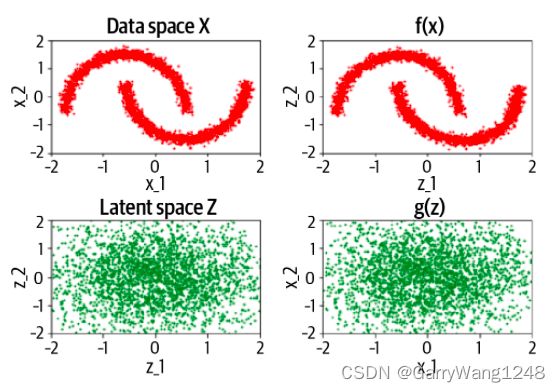
图6-11展示了在开始学习之前网络的输出 — 前向和后向方向只是传输信息,未进行任何变换。
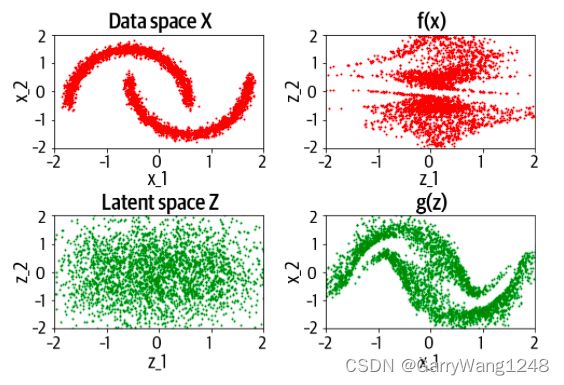
在训练之后(如图6-12所示),前向过程可以将训练集中的点转换到近似高斯分布。同样的,反向过程可以从高斯分布中采样取点,然后将它们反向映射回近似原始数据的分布。
训练过程的损失曲线如下图 6-13所示。

我们关于RealNVP的讨论暂时告一段落,这是归一化流生成模型的一种特殊形式。在下一节中,我们将讨论几种现代的归一化流模型,它们在 RealNVP 论文的基础上做了进一步延展。
其它归一化流模型
另外两种成功 且 重要的 归一化流模型分别是 GLOW 及 FFJORD。下面的小节将介绍他们的核心进展。
GLOW
GLOW 在 2018年的NeurIPS提出,它是首批证明归一化流有能力生成高质量样本的工作,并且产生了有意义的隐空间: 我们可以从中遍历以操作样本。最关键的步骤在于将方向的masking设置 替代为可逆的 1x1 卷积层。例如,在将 RealNVP应用于图像时,在每一步后通道的顺序是翻转的,以此来确保网络有机会对所有的输入进行转换。在GLOW中,作者使用了一个 1x1 卷积,它是一个成功的通用方法,可以产生模型希望的任何通道组合。作者展示了,即使使用了这一改变,整体的分布依然易于驾驭,行列式和反转也都是易于计算的。

FFJORD
RealNVP 和 GLOW是离散时间归一化流 — 也即,它们通过一组离散的耦合层来对输入进行变换。2019年ICLR上发表的FFJORD (Free-Form Continuous Dynamics for Scalable Reversible Generative Models),展示了将变换建模为连续时间过程 (也即,取极限,当步数趋于无穷,补偿趋向于0)。在这种情况下,动态过程可用 ODE 建模,该ODE的参数可用一个神经网络( f θ f_\theta fθ)产生。黑盒求解器用来求时间 t 1 t_1 t1 下的ODE — 也即,给定一个从高斯分布 t 0 t_0 t0点采样的初始点 z 0 z_0 z0,通过以下方程要找到 z 1 z_1 z1:
z 0 ∼ p ( z 0 ) z_0 \sim p(z_0) z0∼p(z0)
∂ z ( t ) ∂ t = f θ ( x ( t ) , t ) \frac{\partial z(t)}{\partial t} = f_\theta(x(t),t) ∂t∂z(t)=fθ(x(t),t)
x = z 1 x = z_1 x=z1
该变换过程的一个框图如下 6-15所示。

本章小节
在本章中,我们探索了归一化流模型,例如 RealNVP,GLOW,FFJORD。
归一化流模型是一个神经网络定义的可逆函数,该函数允许我们通过变量变换直接建模数据分布。在通常情况下,变量方程变换要求我们计算高度复杂的雅可比行列式,这在大多数情况下都不切实际。
为了规避这一问题,RealNVP模型限制了神经网络的形式,使得它具备两个基础特性:可逆的,且雅可比行列式易于计算。
RealNVP通过堆叠耦合层实现了这点,在每一步都产生尺度和平移因子。尤为重要的是,耦合层在数据流经网络时进行了掩膜,从而确保雅可比是下三角矩阵,因此行列式是易于计算的。输入数据的全局可视性是通过在每一层反转掩膜实现的。
设计上,尺度和平移操作是简单可逆的,因此一旦模型训练好了,我们是有可能让数据反向通过网络的。这意味着,我们可以将前向转换过程瞄准为一个标准高斯,以便于采样。进一步的,我们可以把采样点反向传入网络以生成新的观察。
RealNVP 论文也提出了通过在耦合层使用卷积而非全连接层,将该技术应用于图像是可能的。GLOW 论文则进一步延展了该思想,去除了任何硬编码掩膜组合的必要性。FFJORD模型通过将转换过程建模为神经网络定义的 ODE 引入了连续时间归一化流的概念。
总之,我们已经看到,归一化流是生成式建模家族的强大一员,它可以生成高质量的样本,同时保持数据密度函数易于描述的特性。