C语言开启多线程
文章目录
文章目录
- 文章目录
- 多线程
- C语言中的多线程
- 创建多线程
- 阻塞和分离
- 等待和退出
- 线程标识和判断
- 独占数据
-
- 线程对象
- 线程存储
- 共享数据
-
- 互斥
- 条件互斥
- 原子操作
- 内存栅栏
- 多线程总结
多线程
计算机发展初期为单核单任务,windows开始发展为单核多任务,而后是多核多任务,多任务开始为多进程,后来出现了多线程,多核为多进程和多线程提供了更好的支持,不仅可以分配时间线,还可以分配空闲的核心。进程是一个独立功能的程序,为了防止程序之间相互干扰,操作系统在内存中为进程之间筑了一道墙,这就导致进程之间切换和通信变得困难。线程是一个进程中的多任务,线程之间共享进程的资源也可以有自己的独占资源,这就使得线程之间共享资源和通信变得容易。一个程序必须有一个进程,一个进程必须有一个线程,当解决并发任务时可以选择多进程也可以选择多线程,它们各有优点,具体如下:
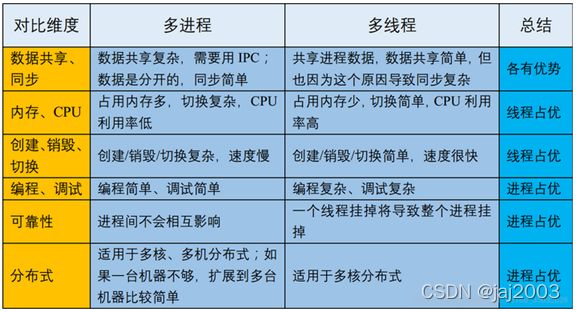 可以看出进程编程和调试简单,可靠性也好,缺点是资源消耗大,线程刚好相反,它资源利用率高,但编写比较复杂,虽然共享数据简单,但解决数据同步的问题很麻烦。
可以看出进程编程和调试简单,可靠性也好,缺点是资源消耗大,线程刚好相反,它资源利用率高,但编写比较复杂,虽然共享数据简单,但解决数据同步的问题很麻烦。
一个进程可以看作:程序 + 数据集合 + PCB,PCB(Program Control Block)包含进程的描叙信息和控制信息,它是一个进程的标志。进程可以分为交互进程、批处理进程和守护进程,交互进程是人机互动的程序,应用程序、游戏都是交互式进程,批处理是无需人为干预自动运行的程序,守护进程又称监控进程,通常作为后台服务进程,它的生存周期较长,例如维持操作系统运作的后台服务或者杀毒软件。进程之间的切换和数据交换资源开销很大,因为需要频繁调用操作系统内核,最有效的数据交换方式是共享内存,随着程序日趋复杂,这种低效的多任务已经无法满足要求,于是就发明了线程,线程是程序执行中的最小单元,是处理器调度和分派的基本单位,线程可以是程序中一个单一的顺序流程,通常为一个函数,它们可以共享的资源包括:
可执行指令(代码)
静态数据
进程中打开的文件描述符
当前的工作目录
用户ID
用户组ID
可以分配的独占资源包含:
线程ID
PC(程序计数器)和相关寄存器
堆栈
错误号(errno)
优先级
执行状态和属性
一个线程可以看作:程序 + 共享资源 + 独占资源 + 线程标识,对于C语言来说,线程可以共享进程中的全局变量,又可以维持自己的局部变量,只有共享的全局变量才需要同步。进程和线程都可以被阻塞,例如等待IO完成,线程为了同步数据常常人为调用阻塞函数,直到等待其它线程调用结束或人为唤醒才会继续运行。
C语言中的多线程
多线程不在C语言的标准中,只能通过调用系统api实现,不同的编译器根据不同的操作系统和自己的版本提供了不同的库,C++和C提供的库又不一样,不管是什么库,它们思路是一样的,重点在于掌握多线程编程的概念。这里使用VS 2017中的threads库,VS 2019中已经删除了threads库,只能使用c++的库,而使用c++库又会纳入很多c++中的内容,不利于简化代码,选择VS 2017中的threads库是因为无需进行任何配置就可以使用多线程,便于讲解,即使它并不完善。
创建多线程
在VS 2017中通过#include
int thrd_create(thrd_t thr, thrd_start_t func, void arg)
其中thr是线程对象地址,func是执行函数指针,arg是函数的参数,函数指针类型为strd_start_t,strd_start_t的类型为int()(void),它有一个类型为void*的参数和一个int类型的返回值。如果线程创建成功,thread_create()将新线程写入thrd_t对象中并返回thread_success。下面创建线程thr1并输出函数的参数,代码如下:
#include返回值thrd_success是一个枚举类型,值为0,因此也可以写通过下列语句来报告错误:
if (thrd_create(&thr1, printId, “th1”)) puts(“创建thr1失败”);
为了简化代码,后面例子均不报告线程错误。_Id是每个线程的唯一标识,线程函数依赖此标识来区分线程。
阻塞和分离
对于单线程来说,函数按照进栈顺序执行,当执行新函数时前面的函数会被挂起,新函数执行完毕后挂起的函数继续运行,而多线程执行时是并发的,不同线程的两个函数可以并发执行,没有顺序可言,将代码修改如下:
#include从结果看出,两个线程可以同时执行for循环,即便主函数调用system(“pause”)暂停,也不会影响线程的执行,线程默认执行方式是分离状态,实际上是thr1,thr2和主线程main()三个线程并行,当thr1和thr2执行完毕后自动释放线程占用的资源,相当于调用thrd_detach(),例如:
thrd_detach(thr1);
thrd_detach(thr2);
只有当主线程结束后程序才会结束,如果我们需要让thr1和thr2执行时主线程等待,执行结束后返回主线程,需要使用thrd_join()将主线程设置为阻塞状态,如下:
#include阻塞函数thrd_join()如下:
int thrd_join(thrd_t thr, int *result);
该函数阻塞当前线程,直到参数thr指定的线程执行完毕后才会恢复,并将函数返回值写入到地址result中,如果想让thr1执行完后再执行thr2,最后执行主线程,应该使用如下代码:
#include上面代码在thr2中调用thrd_join(thr1, &r1)阻塞自身等待thr1执行完毕,在main()中阻塞自身等待thr2执行完毕。在这个线性调用中分别将结果保存到全局变量r1和r2,这种线性调用类似函数栈,但它并不是将函数挂起,而是等待一个线程运行结束,不会产生溢栈,当一个线程释放资源后才会继续下一个线程。线程只有分离和阻塞两种状态,调用 thread_join()或 thread_detach()不得超过一次。
等待和退出
可以让一个线程等待指定的时间也可以让它提前结束,等待函数为:
int thrd_sleep(const struct timespecduration,struct timespecremaining)
等待时间为duration,remaining为剩余时间,它们的类型为timespec,timespec是一个结构体,它有两个成员,tv_sec为秒,tv_nsec为纳秒,1秒相当于1,000,000纳秒,例如:
#include经测试无论是主线程还是其它线程thrd_sleep()在VS 2017中都不起作用,而Sleep()既可以用在进程中又可以用于线程。
如果想提前结束线程,除了在函数中调用return之外,还可以调用thrd_exit()函数,相比return它可以在线程任意调用堆栈中结束该线程并可以指定返回值,而不是通过层层返回来结束,这在层级调用或递归调用中尤其有用。
线程标识和判断
很多线程操作函数需要在线程自身中运行而不能进行外部操作,当多个线程调用的函数一样时,要知道当前哪个线程正在执行,可以使用thrd_current()函数返回该线程,例如:
#includethrd_current()可以在线程函数中返回线程对象,从运行结果来看,thr1,thr2和main()是操作系统分配的3个不同线程。判断两个线程是否相同的函数为:
int thrd_equal(thrd_t thr0,thrd_t thr1)
如果相同返回不为0的数值,不同返回0,通过thrd_equal()可以在相同函数中执行不同的代码,例如:
#include独占数据
当多个线程调用相同的函数时,由于函数栈上开辟的内存空间不同,栈中的数据不会相互影响,但共享全局变量时,势必会造成数据竞争。如果想要使用同一个全局变量的副本而不是为每个线程声明一个全局变量有两种方式,一种是使用线程对象,一种是使用线程存储。
线程对象
在linux中使用修饰符_Thread_local或在VS中使用declspec(thread)可以声明一个独占全局变量,例如:
#include这里循环变量i会在thr1和thr2和main()中呈现三个副本,相互不影响。线程对象声明简单,但却是不建议使用的方式,因为它性能不佳且不够灵活,独占数据更推荐线程存储技术。
线程存储
线程存储为每个线程指定一个地址空间并且自动维护它,这个空间可以是静态区域的内存也可以是堆上的内存,显然选择堆作为动态临时空间比较理想,因为每次可以分配不同的大小且用完后可以释放。首先需要为自动管理的内存空间创建一个类型为tss_t的密匙,然后调用tss_create()方法将密匙关联到一个析构函数,当线程执行完毕后会自动调用这个析构函数。tss_create()方法参数如下:
int tss_create(tss_tkey,tss_dtor_t dtor)
tss_dtor_t是一个函数指针,类型为void()(void*),它包含一个参数且没有返回值。关联密匙和析构函数后可以调用tss_set()和tss_get()为每个线程设置内存空间,它们的格式为:
int tss_set(tss_t key,voidval)
void tss_get(tss_t key)
这两个函数只能在线程函数中调用,为当前线程指定存储空间,密匙的优点是不同线程的存储空间可以共用一个密匙,tss_t对象会分别引用它们。当所有线程执行完毕后,先自动调用各自析构函数,最后通过tss_delete()函数删除tss_t对象占用的资源。下面创建两个线程thr1和thr2,将堆上的空间作为它们的线程储存空间,线程执行完毕后自动通过析构函数释放堆上的内存。
#include这段代码在VS 2017中会报错,VS 2017对tss_开头的函数支持并不完整。
共享数据
当多个线程同时访问共享数据时会发生数据竞争,例如一个线程正在读取数据而另一个线程正在修改数据,同时读写可能导致某个IO操作失败,运行结果不可预知,测试代码如下:
#include这段代码中thr1对counter进行递增,同时thr2对counter进行递减,在main()中等待两个线程执行完毕后输出counter和所花费的时间,可以看到counter并未归零。对于小的循环数据竞争表现不太明显,但在大循环中数据竞争就会导致不同步的问题,并且随着线程的增加数据竞争愈发严重。要避免数据竞争产生的不同步问题,必须防止多个线程同时访问共享数据。
互斥
使用互相排斥技术防止多个线程同时访问共享资源称为互斥技术,互斥技术采用一个对象控制独占访问权限,该对象称之为互斥对象。互斥对象类型为mtx_t,它能在一段时间内只被一个线程锁定,而其他线程必须等待,直到它被解锁。使用mtx_init()初始化一个互斥,格式如下:
int mtx_init(mtx_t *mtx, int mutextype)
互斥属性由参数mutextype指定,mutextype取值如下:
mtx_plain 简单互斥
mtx_timed 超时互斥
mtx_plain | mtx_recursive 递归互斥
mtx_timed | mtx_recursive 超时+递归互斥
调用mtx_init()初始化互斥后,会将互斥对象写入mtx表示的地址,销毁互斥并释放资源的函数为:
void mtx_destroy(mtx_t *mtx)
学会创建和销毁互斥后,我们就可以通过锁定和解锁方法防止数据竞争,这两个函数如下:
int mtx_lock(mtx_t *mtx)
阻塞该线程,直到该线程获得mtx引用的互斥,成功返回thrd_success,否则返回thrd_error,阻塞的线程不能是已持有互斥的线程,如果该线程获取互斥会忽略该函数。
int mtx_unlock(mtx_t* mtx)
释放持有mtx引用的互斥,成功返回thrd_success,否则返回thrd_error。
通常将访问共享资源的代码放入这两个函数中间来保证只有一个线程执行,修改之前的代码如下:
#include此时incFunc()和decFunc()不再并行访问counter,只有获得互斥的线程才能读写数据,因而性能也大打折扣,测试结果counter为0,耗时却是原来的几十倍甚至上百倍,因为锁定互斥远比一个自增自减耗时。当函数包含多行代码时,可以在函数的头尾放置互斥也可以只在访问共享数据的代码块放置互斥,显然后一种方式性能更高。
条件互斥
在线程互斥时默认情况下线程会自动获取某个时间片互斥,可以在此基础上增加条件,如果在互斥中使用条件阻塞线程,只有收到以此条件唤醒的函数通知才会重新获得互斥。条件变量由一个cnd_t类型的变量表示,使用条件变量的函数如下:
int cnd_init(cnd_t *cond)
初始化一个条件变量,成功返回thrd_success,失败返回thrd_error。
void cnd_destroy(cnd_t *cond)
释放cond引用的条件对象资源。
int cnd_wait(cnd_t cond, mtx_tmtx)
阻塞当前线程并释放互斥,当前线程必须持有互斥,如果另外一个线程发送信号解除该线程的阻塞,该线程会再次获得互斥。调用成功返回thrd_success,失败返回thrd_error。
int cnd_timedwait(cnd_t *cond, mtx_t *mtx, const struct timespec *ts)
与cnd_wait()类似,但仅等待ts指定的时间。成功返回thrd_success,失败返回thrd_error,当时间达到限定值时,会返回thrd_timedout。
int cnd_signal(cnd_t *cond)
在等待指定条件变量的任意数量的线程中唤醒其中一个线程,成功返回thrd_success,失败返回thrd_error。
int cnd_broadcast(cnd_t *cond)
唤醒所有等待指定条件变量的线程,成功返回thrd_success,失败返回thrd_error。
下例创建两个线程,这两个线程都包含无限循环直到按esc键退出程序,两个线程均使用互斥,线程1递增,线程2递减,当线程1递增到50时自动暂停,然后唤醒线程2进行递减,线程2递减到0时自动暂停,然后唤醒线程1,以此反复直到按下esc退出整个程序。
#include两个线程循环条件为flag,当监测到一个线程中按下esc键时将flag设置为0,并且唤醒其它等待线程让它结束,否则另外一个线程永远处于阻塞状态导致程序不能结束。可以看到无论是thrd_join()还是cnd_wait(),都只能在线程函数中让自身等待,一个线程不能强行阻塞另外一个线程,否则它就有了破坏的能力。
原子操作
所谓的原子操作,取的就是“原子是最小的、不可分割的最小个体”的意义,它表示在多个线程访问同一个全局资源的时候,能够确保所有其他的线程都不在同一时间内访问相同的资源,这有点类似互斥对象对共享资源的访问的保护,但是原子操作更加接近底层,因而效率更高。与多线程不同,原子操作是在C11提出的标准,它不仅用于多线程,还关系到编译器代码的优化。可惜VS 2017并不支持C11这个标准。在C11中,可以使用类型限定符_Atomic声明一个原子对象,例如:
_Atomic long counter = ATOMIC_VAR_INIT(0L);
宏ATOMIC_VAR_INIT在stdatomic.h中定义,它初始化一个原子类型的变量并设置初始值,只有基本数据类型和结构体可以作为原子类型,数组和函数不能作为原子类型,结构或联合类型的原子对象只能被作为一个整体读取或写入,原子类型的空间大小和对齐方式往往也和非原子类型不同。
原子操作除了使用运算符,还有很多函数,例如:
atomic_store() 替换原子变量的值
atomic_load() 获取原子变量的值
atomic_exchange()替换原子变量的值并返回之前保存的值
atomic_compare_exchange_strong 通过比较替换值
将一个变量声明为原子对象后,读取变量、赋值、自增自减等操作都会被看作原子操作,原子操作函数不仅包含普通读写操作还有很多其它功能,但原子操作不是这里讲述的重点,我们看中的是它可以防止数据竞争且能影响线程代码执行顺序。
内存栅栏
内存栅栏比explicit函数更加灵活,它可以在relaxed顺序下约束内存乱序,要设置一个栅栏,C11 提供了以下函数:
void atomic_thread_fence(memory_order order)
如果建立了一个释放栅栏,原子写操作会在栅栏之后发生,如果建立了一个捕获栅栏,原子读操作必须在捕获栅栏之前发生。例如:
#include虽然没有使用原子对象,但原子栅栏仍然保证同一时刻只有一个线程可以修改counter的值。
多线程总结
在应用程序中多线程常常用于两种情况,一种情况是在交互程序中减少用户等待时间以提升用户体验,例如一边等待下载一边可以填写表格;另一种情况是充分利用多核提升性能,特别是对于压缩、转码等耗时操作。如果线程之间不共享数据,那么处理起来就会变得非常简单,例如每个线程都单独处理一个文件;如果使用多线程同时处理一个文件问题就会变得复杂,因为同一时刻只能有一个线程进行读写,否则就会产生数据竞争导致混乱局面,这时需要使用互斥技术或原子操作防止数据错乱。