selenium点击链接下载文件,并获取文件
在自动化测试时,有时我们会需要自动化获取下载的文件,这是我们要怎么办呢,跟着我一步步的来获取下载的文件吧
首先声明下,我们需要引入的类
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os配置我们的chrome浏览的下载环境,去除弹窗确认
options = webdriver.ChromeOptions()
prefs = { 'profile.default_content_settings.popups': 0, 'download.default_directory': os.getcwd()}
options.add_experimental_option( 'prefs', prefs)
driver = webdriver.Chrome(chrome_options=options)这里profile.default_content_settings.popups设置成0,意思是取消下载的确认弹窗
download.default_directory是确认我们下载的路径,这里我们用时当前运行代码的路径
driver.get( "https://pypi.org/project/selenium/#files")
driver.find_element_by_xpath('//*[@id="files"]/div/div[2]/a[1]').click()
打开网页,并且点击下载的文件链接
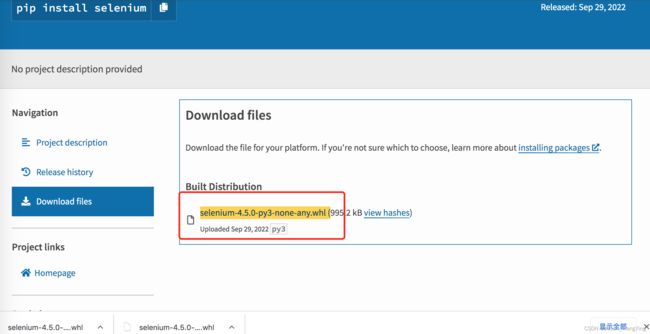
当然我们还可以换种方式,我们可以通过下载链接的文件名去搜索
driver.find_element_by_link_text('selenium-4.5.0-py3-none-any.whl').click() 这里我们可以通过ls命令来查询我们的文件
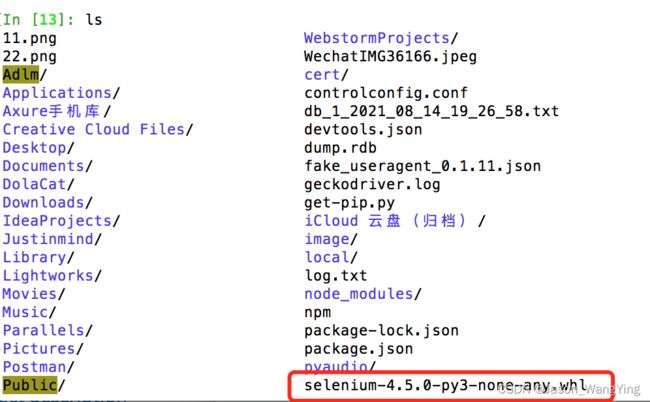
可以看到,我们获取到了我们的文件,这里我们就可以通过os命令来查询了