【网安AIGC专题11.1】11 Coreset-C 主动学习:特征选择+11种采样方法+CodeBERT、GraphCodeBERT+多分类(问题分类)二元分类(克隆检测)非分类任务(代码总结)
Active Code Learning: Benchmarking Sample-Efficient Training of Code Models
- 写在最前面
- 论文名片
- 先验知识的补充
-
- 主动学习
- 采样函数
- benchmark基准和baseline基准线的区别
- 背景Background
-
- 主动学习
- 动机Motivation
- 基准Benchmark
-
- 采样函数acquisition functions
- 设置set up
- RQ1: Feature Selection特征选择
-
- Answer to RQ1
- RQ2: Acquisition Function Comparison采样函数的比较
-
- 分类任务
- 非分类任务
- Answer to RQ2
- 探索性研究Exploratory Study
-
- 研究设计Study Design
- 不同的距离Different Distance
- 案例研究Case Study
- 结论Conclusion
- 课堂讨论
-
- 主动学习
- 采样函数
- 聚类
- kmeans
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
皇甫璟轩同学分享了Active Code Learning: Benchmarking Sample-Efficient Training of Code Models《主动代码学习:样本高效的代码模型训练基准测试》
分享时清晰简洁大方
学到了benchmark基准和baseline基准线的区别
主动学习:主动选择具有最大信息量的数据样本
采样函数:旨在选择最有价值的数据样本,以便有效地提高模型性能

论文名片
主题: 主动代码学习:基于特征选择的研究
摘要:
-
问题陈述: 机器学习模型的训练数据准备需要大量人力,这对于软件工程领域尤为明显。
主动学习是一种可以减少数据需求的技术,但在代码模型中的应用尚未得到充分研究。 -
研究目标: 本文的研究目标是探讨主动学习在代码模型训练中的有效性,并建立一个基准来评估不同的特征选择方法。
-
方法和实验: 收集了11个采集函数(用于数据选择),并在与代码相关的任务中使用这些函数。
进行了实证研究,检查这些采集函数是否保持了代码数据的性能。 -
结果和发现: 研究结果表明,特征选择在主动学习中起到重要作用,使用输出向量选择数据是最佳选择。
然而,在代码摘要任务中,主动代码学习被发现是无效的,导致生成的模型性能差距超过29.64%。 -
未来方向: 使用评估指标代替距离计算方法,并探索这些评估指标与代码模型性能之间的相关性。
结论:
本文的研究弥合了主动学习在代码模型中的应用的研究空白,并提供了有关特征选择方法的有用见解。
作者还强调了主动代码学习的限制,特别是在代码摘要任务中的有效性。
这项研究对于改进代码模型的训练过程具有重要意义,特别是在预算有限的情况下。
先验知识的补充
主动学习
主动学习是一种机器学习方法,它通过主动选择具有最大信息量的数据样本来改善模型的性能,从而减少训练数据的数量需求。
与传统的被动学习方法不同,其中所有可用数据都被用于模型训练,主动学习允许模型自己选择最具益处的样本,以便更有效地提高性能。
涉及到采样函数的算法,该算法能够评估数据样本对模型性能的潜在贡献,然后选择最有价值的样本供模型训练使用。
特别是在数据有限或成本高昂的情况下,可以提供显著的帮助。
采样函数
主动学习中的采样函数算法旨在选择最有价值的数据样本,以便有效地提高模型性能。步骤如下:
-
初始模型训练: 开始时,有一个初始的模型,通常是在少量标记数据上训练的。这个模型用来评估数据样本的价值。
-
候选样本选择: 采样函数首先从未标记的数据中选择一些候选样本。这些候选样本可以是数据池中的未标记数据,或者是通过某种主动选择策略(例如不确定性、多样性、或模型不确定性等)选出的。
-
样本评估: 选定的候选样本会经过当前模型的评估,以确定它们对模型性能改善的潜在贡献。通常,评估是通过一个或多个评估指标来完成,例如模型的不确定性、信息增益、错误率等。
-
采样函数选择: 采样函数会基于样本的评估结果,选择其中最具有信息量或价值的样本。这通常涉及到一种策略,例如不确定性最高的样本,或者最大化信息增益的样本。
-
标记数据: 选择出的样本会被标记,加入到已知数据中,用于下一轮模型训练。
-
模型更新: 使用新标记的样本重新训练模型。这一轮的模型通常会更好地适应这些新样本,从而提高性能。
-
重复迭代: 这个过程会反复迭代,每一轮都选择新的样本,标记它们,重新训练模型,并评估性能。迭代次数根据需要,可以持续直到模型达到所需的性能水平或收益不再显著增加。
采样函数的具体算法和策略可以因应用领域和任务而异。
通常,主动学习的目标是最大限度地提高模型性能,同时最小化标记新样本的成本。
因此,采样函数的设计需要综合考虑信息增益、模型不确定性、样本多样性和成本效益等因素。
benchmark基准和baseline基准线的区别
“Benchmark” 和 “baseline” 是两个在研究和评估中常常使用的术语,区别在于:
-
Benchmark(基准):
- 基准通常是指在某个领域或任务中的
最高标准或最佳性能水平。它代表了一个值得追求的目标,通常是由领域专家或业界认可的最佳方法或模型所达到的性能水平。 - 基准可以用作评估其他方法或模型的性能,以确定它们是否能够达到或超越该领域的最佳已知性能。基准通常用于验证新方法的有效性,以确定它们是否值得进一步研究或应用。
- 基准可以是一个具体的数值,也可以是一种方法的描述,例如 “state-of-the-art”(最新水平)。
- 基准通常是指在某个领域或任务中的
-
Baseline(基准线):
- 基准线是指在研究或实验中作为对照的
简单或基本方法或模型。它通常是一种相对简单的方法,用于比较其他更复杂或高级的方法的性能。 - 基准线有助于评估新方法的相对性能,它可以是一种简单的规则、传统方法或者是最初的尝试,用以提供一个性能的最低标准。
- 基准线通常不是最佳的性能,但它用于确定新方法是否能够明显改善现有的性能水平。
- 基准线是指在研究或实验中作为对照的
总结:
“benchmark” 是在某个领域或任务中的最高标准或最佳性能,用作目标和参考点,
而 “baseline” 是用于比较新方法相对于简单或基本方法的性能。
基准通常是最优性能,而基准线通常是最低性能,用于建立性能改进的上下界。
在研究和评估中,它们都起到了重要的作用,以帮助评估新方法的效用和贡献。
背景Background
近年来,使用机器学习(ML)来帮助开发人员解决软件问题(ML4Code) 一直是软件工程(SE)和ML领域的热门方向。然而准备机器学习(ML)模型的训练数据需要的巨额人力成本,这阻碍了它在软件工程(ML4Code)中的应用。
因此,如何在不影响模型性能的前提下减小人力成本已成为一项挑战。为了解决这一难题,本文提出采用主动学习的方法,因为它允许开发人员用少量的数据训练模型,同时不降低模型的性能,这在计算机视觉和自然语言处理领域得到了很好的研究。
主动学习
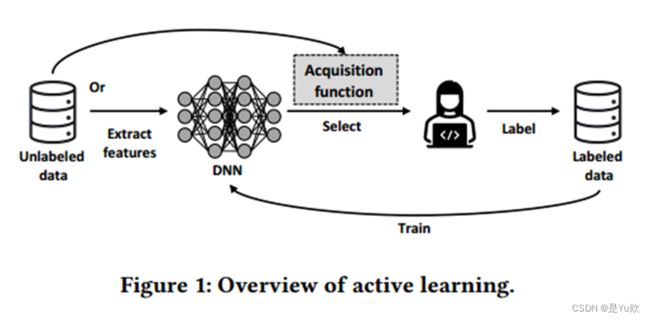
主动学习的关键思想是迭代地选择训练数据的子集进行标记、并使用它们来训练模型。已有研究表明,只需标注不到10%的训练数据,就可以训练出与使用整个训练数据训练出的模型性能相近的模型。
一般来说,可以使用两种类型的特征,
- 数据本身的特征(例如图像像素和代码标记)
- 从模型中提取的特征(例如输出概率和代码嵌入)
在获取这些特征之后,采样函数用于选择最有价值的数据进行人工标注。
动机Motivation
主动学习在许多领域(如计算机视觉和自然语言处理)得到了应用,但在ML4Code领域中还未受到关注。在该领域,研究人员主要关注模型架构、代码表示方法等,却忽略了如何降低模型训练成本的问题。因此,有必要提供一个基准来支持对这一重要问题的研究。
本文旨在建立一个基准来研究主动学习如何帮助代码模型高效构建,即:主动代码学习。要解决这一问题,需要回答:
- RQ1:基于聚类的采样函数应该选取哪些特征
- RQ2:采样函数在代码模型上的表现如何
基准Benchmark
采样函数acquisition functions
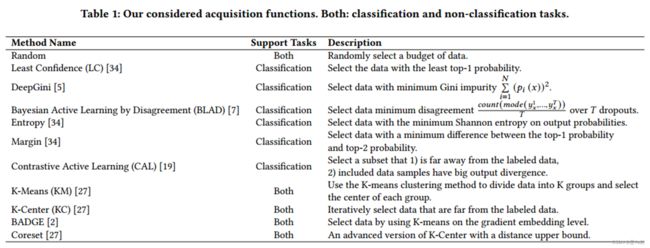
文章选取了11种采样函数进行研究
设置set up
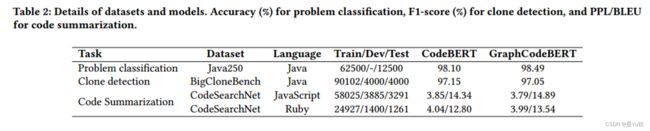
考虑了三种特征: Code Embeddings 、 Code tokens和Model outputs ;
三种代码任务:多类分类任务(问题分类)、二元分类任务(克隆检测)和非分类任务(代码总结)
预训练代码模型采用:CodeBERT和GraphCodeBERT
评价指标:
- Accuracy:计算整个输入数据中正确分类数据的百分比
- F1-score:是二元分类问题的常用度量。它计算precision和recall的调和平均值
- Perplexity (PPL):是一种广泛用于评价语言模型的度量,可以看作loss
- BLEU (Bilingual Evaluation Understudy):用于评估生成文本的质量
RQ1: Feature Selection特征选择
- 比较了不同采样函数在不同标注数据比例下训练的模型的性能。
- 结果如图2所示,相同的采样函数用不同特征训练的模型性能具有差别。特别是,对于K-Means, K-Center和Coreset函数,性能差异比较明显。相比之下,BADGE函数相对稳定。
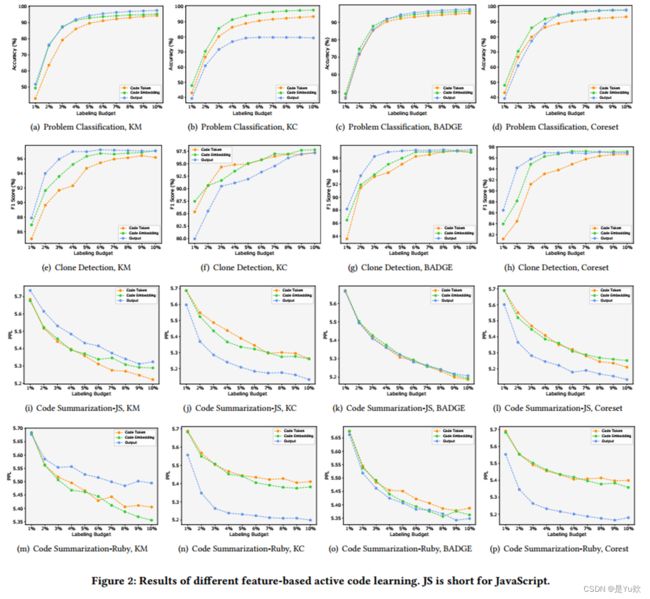
Answer to RQ1
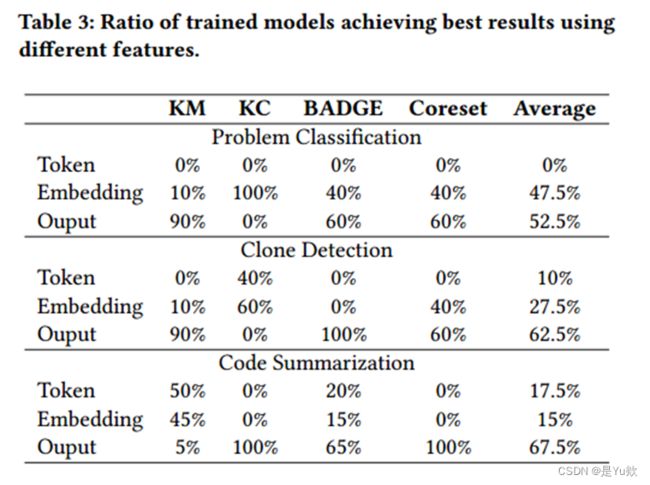
总结了每个函数在图2所有情况下表现出最佳性能的百分比。
如表3所示,总的来说,Model outputs是更好的特征。
此外,有一些采样函数的特征选择还取决于任务的类型。例如:对于在K-Means和K-center,
- 两个分类任务中,Output和Embedding分别是它们的最佳选择;
- 而在非分类任务中,为Token和Output。
基于实验结果,对特征选择提出建议:
- K-Means-C (KM-C):使用Output(Token)进行分类(非分类)任务。
- K-Center-C (kC-C):使用代Embedding(Output)进行分类(非分类)任务。
- BADGE-C:对所有代码任务使用Output 。
- Coreset-C:对所有代码任务使用Output 。
RQ2: Acquisition Function Comparison采样函数的比较
得出结论:
- 主动代码学习在非分类代码任务中还需要进一步研究,
- 此外,从分类任务中得出的结论适用于非分类任务。
分类任务
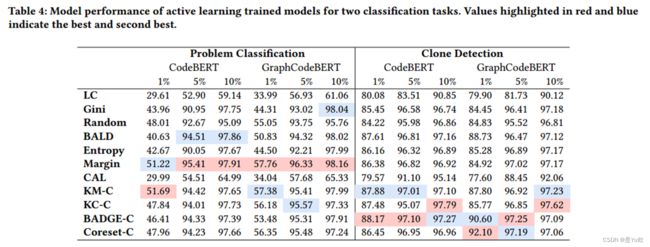
对于多类分类任务(问题分类),基于输出不确定性的方法通常比基于聚类的方法取得更好的结果。
其中,仅使用输出的top-1和top-2概率的Margin在6个案例中的5个中表现最佳。
这一现象与先前的研究得出了类似的结论,即简单的方法在主动学习中表现良好。
对于二分类任务(克隆检测),基于聚类的方法更好。
非分类任务
对于非分类任务(代码总结),有以下发现:
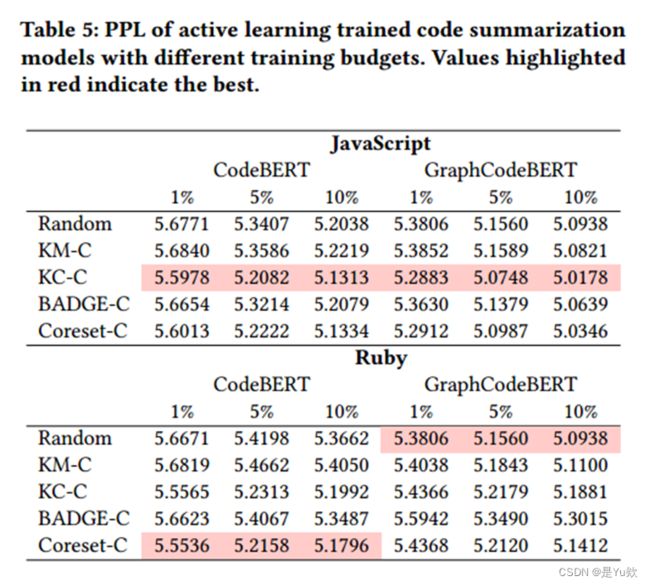
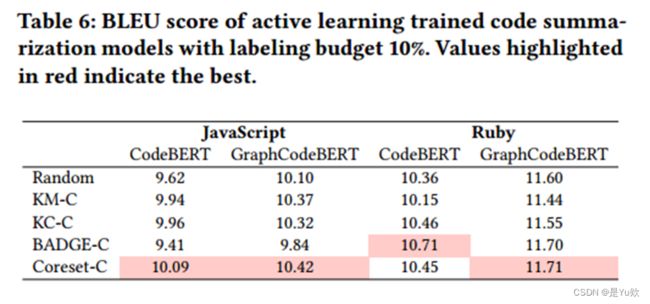
使用不同的评估指标得到的结论不同。例如,PPL和BLEU分别表明KC-C和Coreset-C是最好的采样函数。
对于两种评估指标,主动学习训练模型的性能与使用整个数据训练的模型的性能之间的差距很大。
例如,对于JavaScript-CodeBERT,在10%的标注预算下,最佳PPL分数和BLEU分数分别为5.1313和10.09,比完整训练模型的3.85和14.34分别低33.28%和29.64%。
这与分类任务的结果完全不同(对于克隆检测任务,使用10%的数据训练的模型(97.79%)的性能优于使用整个训练数据训练的模型(97.15%))。
Answer to RQ2
研究结果表明:
- 对于二分类任务克隆检测,基于聚类的采样函数始终优于基于输出不确定性的采样函数。
- 主动学习对于代码总结等非分类任务是
无效的,因为通过主动学习训练的模型的性能至少落后于使用整个数据集训练的模型29.64%。
探索性研究Exploratory Study
研究设计Study Design
为了探索更加有效的采样函数,提出使用评价指标作为基于聚类的采样函数的距离方法,并进行了以下实验:
- 准备了两组模型,第一组为初始模型,第二组为已经使用5%的训练数据训练的模型。
- 对每组模型使用随机采样函数进行100次主动代码学习,并记录100组选择的数据和训练好的模型。
- 测量100个训练模型在测试数据上的准确率,并计算每组所选数据样本之间的平均距离。最后得到100个准确率值和对应的100个距离值。
- 使用斯皮尔曼相关系数计算准确率与距离之间的相关性。
不同的距离Different Distance
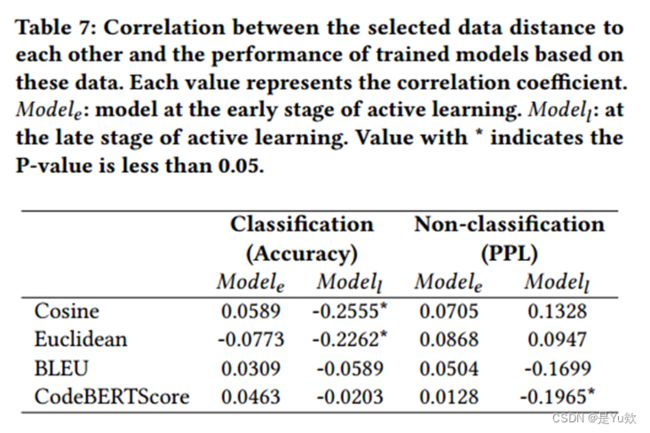
表7展示了距离和准确率之间的相关性的结果:
-
对于初始模型,模型的性能与数据之间的距离无关;
-
然而,对于5%数据训练后的模型,结论发生了变化。
- 在分类任务中,余弦和欧氏距离与模型的准确率之间存在
弱相关性。这意味着使用这两种距离计算方法有望训练出高准确率的模型。 - 在非分类任务中,这种
相关性变弱,这也是现有的采样函数不能很好地完成代码总结任务的原因。
- 在分类任务中,余弦和欧氏距离与模型的准确率之间存在
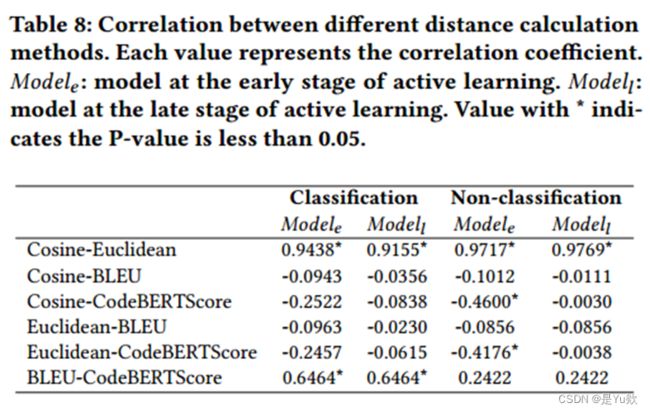
表8展示了不同距离计算方法之间的相关性,结果显示:
- 对于,CodeBERTSCore与余弦相似度或欧氏距离之间总是存在相关性,这意味着CodeBERSCore能够在这些模型中产生与普通距离方法相似的数据距离排序;
- 在则不相关。
这些结果表明,在进行代码总结任务时,采用评价指标作为距离计算方法的新采样函数是合理的。
案例研究Case Study
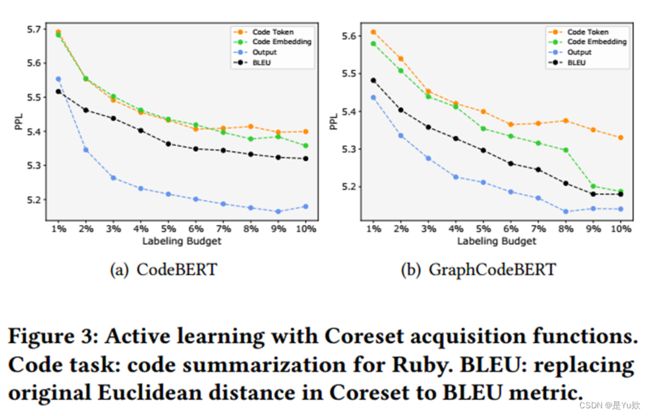
为探究评价指标作为距离的有效性,将Coreset函数中的距离计算方法修改为BLEU,并在Ruby上对代码总结任务进行实验。
结果显示:
- 使用BLEU分数的Coreset函数性能明显优于使用Token和Embedding计算欧氏距离的Coreset函数。
- 然而,使用输出向量作为聚类特征仍然是最好的选择。
这样的结果说明,基于评估指标提出新的获取函数有很大的研究空间。
结论Conclusion
本文首次创建了一个用于主动代码学习的基准。
基于本文的基准和经验性研究,解决了聚类采样函数的特征选取问题,同时得出结论:
- 主动代码学习可以有效地训练代码模型,并在问题分类和克隆检测等分类任务中表现出优异的性能。
- 对于代码总结等非分类任务,还需要进一步的研究。
此外,文章的探索性研究结果表明使用评估指标作为距离计算方法可以是采样函数研究的一个新方向。
课堂讨论
主动学习
主动学习,最开始是只有10%标注的数据
采样函数
11个
随机采样:模型输出或预测的概率分布中随机选择一个元素作为下一个词或标记的生成方式。这种方法是最常见的文本生成方式之一,因为它简单直观,但也可能导致生成的文本缺乏一定的连贯性。
贪婪采样:与随机采样不同,贪婪采样总是选择概率最高的元素作为下一个生成的词或标记。这种方法通常会导致生成的文本更加连贯,但有时会牺牲多样性。
温度采样:温度采样引入了一个温度参数,该参数控制了生成过程中的随机性程度。较高的温度值使得生成更加随机,而较低的温度值使得生成更加确定。温度采样的应用可平衡连贯性和多样性之间的权衡。
束搜索:束搜索是一种基于模型输出的多步骤生成方法。它维护一个候选词列表,然后根据模型的输出概率分布来扩展这些候选。束搜索可以生成较为连贯和有结构的文本,但也需要更多的计算资源。
自回归采样:自回归采样是一种逐步生成文本的方法,每一步都依赖于前一步的输出。这种方法通常使用循环神经网络(RNN)或变换器(Transformer)来维护生成的序列状态。
聚类
聚类的距离方面
余弦相似度
kmeans
需要给定设置的个数,但论文中没有提及