2019独角兽企业重金招聘Python工程师标准>>> 
第二章 一份Lisp-Stat教程
本章打算将使用Lisp-Stat作为统计计算器和绘图器做一个介绍。在介绍完基本的数值和绘图操作之后,介绍如何构建随机的和系统的数据集合,如何修改数据集,如何使用一些内建的动态绘图工具,如何构建线性回归模型。最后两节给出了简略的介绍,关于如何写你自己的函数和使用功能数据进行高级建模的工具。
2.1 Lisp解释器
你与Lisp-Stat系统的交互是由你和lisp解释器之间的对话组成的。想象一下,你坐在计算机前打开了你的系统,或者更好点儿,你获取了某个版本的Lisp-Stat,并且启动了它。当准备好要开始对话时,Lisp-Stat在一个空白行的前边给出了一个提示符,就像这样:
>如果你键入一个表达式,解释器就会打印这个表达式的计算结果来响应你。例如,如果你给解释器一个数字,然后按回车键,那么解释器就会响应你——简单地 打印 这个数字,然后 在下一行 退出并给你一个新的提示符。
> 1
1
>对数字的操作可以通过组合数字和一个符号并把它们复合成一个表达式来执行,就像这样(+ 1 2):
> (+ 1 2)
3
>就像你猜想的一样,这个表达式就是将数字1和2加在一起。这种操作符放在操作数前边的表示方法叫前置表示法。这种表示方法起初可能让你很迷惑,因为它背离了标准的数学实践,但是却会带来一些很有意义的优势。一个优势是可以容纳进行任意数量的参数操作。例如,
> (+ 1 2 3)
6
> (* 2 3.7 8.2)
60.68
>为了理解解释器是如何工作的,要记住的一条基本的原则是所有的东西都是可以被求值的。数字求值得到它本身。
> 416
416
> 3.14
3.14
> -1
-1
>还有一些其它的基本数据形式求值后也会得到它本身。它们包括逻辑值
> t
T
> nil
NIL
>还有字符串,它们将用双引号括起来。
> "This is a string 1 2 3 4"
"This is a string 1 2 3 4"
>分号";"是Lisp注释符,任何在分号后键入的字符,直到你下次键入回车,其间的所有内容都会被解释器忽略。
如果解释器接收到一个符号(symbol,Lisp术语),像"pi"或者"this-is-a-symbol",来计算的话,它将首先检查是否有一个值与该符号关联,如果有值关联就返回那个值:
> pi
3.141593
>如果没有值与该符号关联,解释器将发出一个错误信号:
> x
error: unbound variable - X
>符号pi是系统预定义的,作为数字π的一个近似值。从这点来看,符号x是没有值的。下一节我们将看到如何给一个符号赋值。
当你敲写符号名称时,可以用大写形式也可以用小写形式。Lisp内部会将小写字母转换为大写形式。
组合表达式的求值有一点点复杂。一个组合表达式是由一些放在小括号内部对的,用空格分开的元素的列表组成的。列表的元素可以是字符串、数字或者其它的组合表达式。在对形如(+ 1 2 3)这样的表达式求值时,解释器把这个列表当成一个函数表达式。列表的第一个元素代表一个Lisp函数——可以接受一些参数并且返回一个结果的代码段。本例中的函数式加法函数,由符号"+"表示,列表的其余元素是它的参数,这里是1、2和3。当要求对表达式求值时,解释器调用加法函数,把它应用到参数上,然后返回结果:
> (+ 1 2 3)
6函数的参数在函数使用之前已经被求值。在前边的例子里,参数都是数字,因此求值结果为自身。但是在下边这个例子里:
> (+ (* 2 3) 4)
10在加法函数使用之前,解释器不得不先对第一个参数(* 2 3)求值,再传递给加法函数。
数字、字符串和符号是一些在Lisp里可以直接使用的基本数据类型。我将会指出这些基本数据类型共同当做简单数据。还有,Lisp提供了一些方法来形成更复杂的数据结构,那些叫复合数据。最基本的复合数据就是列表——list。列表可以使用"list"函数来构造:
> (list 1 2 3 4)
(1 2 3 4)解释器打印的这条结果很像我们已经用过的那个复合表达式:一个放在小括号里的,由空格分开的元素序列。事实上,Lisp表达式就是简单的列表。
一些其它复合数据形式也是可用的,包括矢量(vector)和多维数组。这些在4.4节再讨论。
在开始第一个统计应用程序之前,让我们再看一个解释器的特性。假设我们想要解释器打印一个列表(+ 1 2)给我们,直接把这个列表键入解释器是不行的,因为解释器会坚持对该列表求值:
> (+ 1 2)
3解决办法就是告诉解释器不要对列表求值。这个处理过程叫做引用(quoting)。就像这样,在一个手写的句子里,将一个表达式周围加上引号,然后说:把这个表达式当成字面意思理解。例如,使用引号标记下表这两个句子:Say your name! 和 Say "your name"!这两句话的意思是不同的。下表的表达方式告诉你如何在Lisp里引用表达式:
> (quote (+ 1 2))
(+ 1 2)"quote"不是一个函数,它不遵守上边描述的函数求值规则:它的参数不会被求值。"quote"可以被称为一个special form——特殊是因为在处理参数上它有特殊的规则。需要的时候我还会介绍其他的special forms。这些基本求值规则与这些special forms(特殊形式)一起组成了Lisp语言的语法。
"quote"使用频率如此之高以至于专门开发了一个速记符,就是标记在表达式之前的单引号:
> '(+ 1 2) ;单引号速记符
(+ 1 2)也就是说,上边的表达式与(quote (+ 1 2))是相同的。
一旦你学会如何启动一个计算机程序,确保指导如何退出程序是个好主意。在大多数Lisp系统里你可以通过使用exit函数退出。在提供%的shell提示符的UNIX操作系统里,使用exit函数应该会返回shell:
> (exit)
%其它操作系统可能会提供额外的退出方式。例如,在Macintosh操作系统里,你可以到“文件”菜单里选择“退出”选项退出。
练习 2.1
先预测,再上机实验。
a) (+ 3 5 6)
b) (+ (- 1 2) 3)
c) '(+ 3 5 6)
d) (+ (- (* 2 3) (/ 6 2)) 7)
e) 'x
f) ''x
2.2 初级计算与绘图
本节介绍一些在Lisp-Stat里可用的基本的数值与绘图操作。
2.2.1 一维概要与图形
统计数据经常是由数字组组成的。作为一个例子,下表展示了Minnea-St地区30年间3月份降水量数据记录,单位为英寸。
为了在Lisp-Stat里检测这些数据,我们可以list函数将数据重新显示为数字列表,表达式如下:
> (list .77 1.74 .81 1.20 1.95 1.20 .47 1.43 3.37 2.20
3.00 3.09 1.51 2.10 .52 1.62 1.31 .32 .59 .81
2.81 1.87 1.18 1.35 4.75 2.48 .96 1.89 .90 2.05)
这些数字必须用空格分开,不是逗号。解释器允许你跨多行表示数据,它不会求值直到你完成表达式的书写并键入回车为止。
"mean"函数可用来计算数字列表的平均值。我们可以用它和list函数组合在一起,来求取降水量样本数据的平均值:
> (mean (list .77 1.74 .81 1.20 1.95 1.20 .47 1.43 3.37 2.20
3.00 3.09 1.51 2.10 .52 1.62 1.31 .32 .59 .81
2.81 1.87 1.18 1.35 4.75 2.48 .96 1.89 .90 2.05))
1.675降水量的中位数可以这么计算:
> (median (list .77 1.74 .81 1.20 1.95 1.20 .47 1.43 3.37 2.20
3.00 3.09 1.51 2.10 .52 1.62 1.31 .32 .59 .81
2.81 1.87 1.18 1.35 4.75 2.48 .96 1.89 .90 2.05))
1.47每次我们想对数据样本进行统计计算的时候,都不得不敲入30组数字,这当然是一件令人恼火的事情。为了避免做那要的工作,我们可以Lisp-Stat的一个特殊形式"def"来给数据列表一个变量名。
> (def precipitation
(list .77 1.74 .81 1.20 1.95 1.20 .47 1.43 3.37 2.20
3.00 3.09 1.51 2.10 .52 1.62 1.31 .32 .59 .81
2.81 1.87 1.18 1.35 4.75 2.48 .96 1.89 .90 2.05))
PRECIPITATION现在,符号precipitation有一个值与它绑定了,我们的30个数字的列表可以这样获得:
> precipitation
(.77 1.74 .81 1.20 1.95 1.20 .47 1.43 3.37 ...)现在,我们再对这些数据记性各种数值描述性统计及容易得多了:
> (mean precipitation)
1.675
> (median precipitation)
1.47
> (standard-deviation precipitation)
1.00062
> (interquartile-range precipitation)
1.145函数histogram和boxplot可以用来获得样本数据的图形化展示,见图2.1和图2.2。
> (histogram precipitation)
#
> (boxplot precipitation)
# 图2.1 数据柱状图
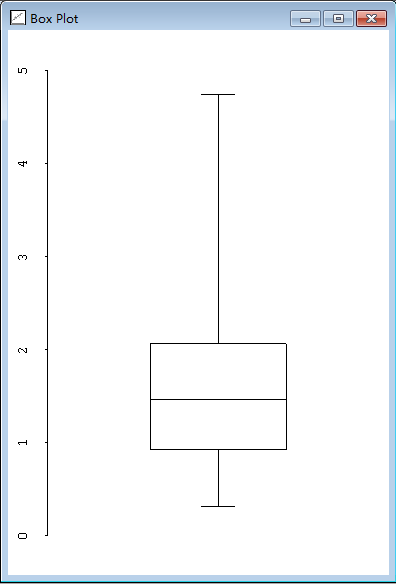
图2.2 数据盒图
这两个表达式是会将绘图窗口显示在显示器上。这两个函数返回两条类似这样的信息:
#这个结果之后会被用来识别包含图形的窗口,但这会儿你可以忽略它。
Lisp-Stat也支持数字列表数据的对应元素相乘操作(点乘)。例如,我们可以在降水量数据的每个元素上加1:
> (+ 1 precipitation)
(1.77 2.74 1.81 2.2 2.95 2.2 1.47 2.4299999999999997 4.37 3.2 4.0 4.09 2.51 3.1 1.52 2.62 2.31 1.32 1.5899999999999999 1.81 3.81 2.87 2.1799999999999997 2.35 5.75 3.48 1.96 2.8899999999999997 1.9 3.05)或者计算它们的自然对数,
> (log precipitation)
(-0.2613647641344075 0.5538851132264376 -0.21072103131565253 0.1823215567939546 0.6678293725756554 0.1823215567939546 -0.7550225842780328 0.3576744442718159 1.2149127443642704 0.7884573603642703 1.0986122886681098 1.128171090909654 0.412109650826833 0.7419373447293773 -0.6539264674066639 0.4824261492442928 0.2700271372130602 -1.1394342831883648 -0.527632742082372 -0.21072103131565253 1.0331844833456545 0.6259384308664954 0.16551443847757333 0.30010459245033816 1.55814461804655 0.9082585601768908 -0.040821994520255166 0.636576829071551 -0.10536051565782628 0.7178397931503168)或者平方根:
(sqrt precipitation)
(0.8774964387392122 1.3190905958272918 0.9 1.0954451150103321 1.396424004376894 1.0954451150103321 0.6855654600401044 1.1958260743101399 1.835755975068582 1.4832396974191326 1.7320508075688772 1.7578395831246945 1.2288205727444508 1.449137674618944 0.7211102550927979 1.2727922061357855 1.1445523142259597 0.565685424949238 0.7681145747868608 0.9 1.676305461424021 1.3674794331177345 1.0862780491200215 1.161895003862225 2.179449471770337 1.5748015748023623 0.9797958971132712 1.374772708486752 0.9486832980505138 1.4317821063276353)降水量数据的分布有些右偏,平均值和中位数是分离的。你可能想要试着做一些简单的变换来看看能否对称化数据,比如说平方根或者对数。你可以查看图形和概要统计来确定是否这些变换确实导致数据更加对称化一些。例如,可以用下边的表达式计算数据样本的平方根的均值:
> (mean (sqrt precipitation))
1.2401878297708169也可以获得样本数据的平方根的柱状图:
> (histogram (sqrt precipitation))boxplot函数还能用来并列地产生两个或者更多的数据样本。只需要传递给boxplot函数列表型参数,这个列表型参数是由多个列表数据组成的,其中的每条列表数据都是要显示在统计图形串口上的数据样本。让我们用这个函数测试一些数据样本,这些数据来源于危地马拉的一些社会经济学团体对血液化学的研究。高收入的城市区域和低收入的乡村区域样本的血清总胆固醇数据,可以用下边的表达式输入:
> (def urban (list 206 170 155 155 134 239 234 228 330 284
201 241 179 244 200 205 279 227 197 242))
URBAN
> (def rural (list 108 152 129 146 174 194 152 223 231 131
142 173 155 220 172 148 143 158 108 136))
RURAL并列的盒图可以用以下表达式表示:
> (boxplot (list urban rural))结果见图2.3。

图2.3 危地马拉城市与乡村总胆固醇水平并列盒图
练习 2.2
先预测,后实践,并解释其间的不同。
a) (mean (list 1 2 3))
b) (+ (list 1 2 3) 4)
c) (* (list 1 2 3) (list 4 5 6))
d) (+ (list 1 2 3) (list 4 5))
练习 2.3
略。
练习 2.4
略。
2.2.2 二维绘图
很多单一样本是随着时间的推移收集的。上面用到的降水量数据就是一个例子。在一些情况下假设观测数据之间相互独立式合理的,但在有的情况下是不合理的。检查数据以获得序列相关性和趋势的一种方式,就是绘制观测数据相对于时间,或者相对于数据自身顺序的图形。我们可以使用plot-points函数来产生一幅降水量数据相对于时间的散点图。plot-points函数使用下边的表达式形式调用:(plot-points
> (iseq 1 30)那么为了生成散点图,我们需要键入以下表达式:
> (plot-points (iseq 1 30) precipitation)结果见图2.4。对数据来说,本图似乎过多的形式,独立性的假设对该数据来说可能是合理的。
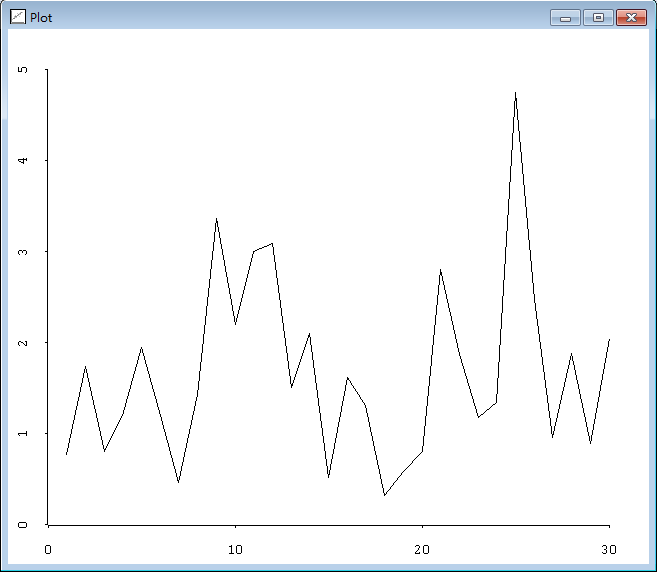
图2.4 降水量水平相对于时间的散点图
有时用线将点连接起来,就很容易在图形里看到时间形式。使用plot-lines函数可以构造一个连接点数据的连接线。plot-lines也可以被用来构造函数的曲线图。假设你想得到自变量在-π到+π范围内的sin(x)函数的图形,其中常量π由变量pi预定义,你可以使用这个表达式:(rseq
> (plot-lines (rseq (- pi) pi 50) (sin (rseq (- pi) pi 50)))你也可以先定义一个变量x来简化这个表达式,
> (def x (rseq (- pi) pi 50)然后重新构造表达式:
> (plot-lines x (sin x))最终图形见图2.5。
图2.5 sin(x)图形
散点图在检测两组数值观测量之间的关系上,当然是非常有用的,这两组观测量是针对同一目标的。一项针对机动车尾气排放过程的研究给出了46两汽车的HC和CO排放数据,结果放在两个变量hc和co里:
> (def hc (list .50 .65 .46 .41 .41 .39 .44 .55 .72 .64 .83 .38
.38 .50 .60 .73 .83 .57 .34 .41 .37 1.02 .87 1.10
.65 .43 .48 .41 .51 .41 .47 .52 .56 .70 .51 .52
.57 .51 .36 .48 .52 .61 .58 .46 .47 .55))
> (def co (list 5.01 14.67 8.60 4.42 4.95 7.24 7.51 12.30
14.59 7.98 11.53 4.10 5.21 12.10 9.62 14.97
15.13 5.04 3.95 3.38 4.12 23.53 19.00 22.92
11.20 3.81 3.45 1.85 4.10 2.26 4.74 4.29
5.36 14.83 5.69 6.35 6.02 5.79 2.03 4.62
6.78 8.43 6.02 3.99 5.22 7.47))然后,可以用plot-points函数将它们一一对应地绘制到一幅图里:
> (plot-points hc co)结果见图2.6。
图2.6 机动车尾气排放的CO相对HC图形
练习2.6
略。
2.2.3 绘图函数
上一节中,正弦函数的制图函数显得非常笨重。作为一个代替品,我们可以使用plot-function来绘制有一个参数的函数,该参数有一个指定的范围。为了产生图2.5中的图形,我们可以使用表达式:
> (plot-function (function sin) (- pi) pi)表达式(function sin)用来提取与符号sin相关联的Lisp函数,仅仅使用sin还不够,原因是Lisp里的符号可能是由def设定的数值,同时也可能是一个函数定义。起初这一特性看起来有些奇怪,但是它也有一个很大的优势——键入一个像这样的合法表达式:
> (def list '(2 3 4))而不会销毁list函数。
从一个符号里提取一个函数定义就像引用表达式一样常见。所以又有一个新的可用的缩写符号,表达式#'sin和表达式(function sin)是等价的(注:这点与Common Lisp里相似,有兴趣的朋友可以参考Common Lisp里的function和apply的用法)。#'的读音是sharp-quote。使用这个缩写,产生正弦图形的表达式可以写成这样:
> (plot-function #'sin (- pi) pi)2.3 进一步了解解释器
Lisp-Stat解释器允许保存创建的变量,可以部分或全部地记录与解释器的会话。另外,它还提供了获得最近几条计算结果的机制,还有获得在线帮助的机制。这几个特性可能根据所运行的系统的不同稍微有些差异,尤其是在线帮助系统,例如,一些系统可能提供了单独的帮助窗口。我的相关工作是基于XLIST-STAT这一实现版本的。
2.3.1 保存你的工作
如果你想要与解释器的一个会话,你可以使用dribble函数。表达式
> (dribble "myfile")将开始一个记录。所有你输入的表达式和解释器返回的结果都会输入到这个叫myfile的文件,表达式
> (dribble)会停止录制工作。表达式(dribble "myfile")通常会开始一个名称为myfile的新文件,如果你已经有了这个名字的文件,其内容将全部丢失。因此你不能用dribble函数对单个文件进行开启和关闭。
dribble仅会记录文本,不会记录图形。Macintosh的XLISP-STAT里你能使用标准Macintosh快捷命令COMMAND-SHIFT-3来保存当前屏幕的图像。也可以到Edit菜单里选择Copy命令,或者其快捷键COMMAND-C,图形窗口是一个活动窗口,用来将内容保存到剪切板。在X11版的XLISP-STAT,绘图菜单包含一个选项,该选项可以将图形的PostScript版本保存成文件。
你在Lisp-Stat里定义的变量只能存在于当前会话,如果你从Lisp-Stat里退出,或者程序崩溃了,你的数据就会丢失。为了保存你的数据可以使用savevar函数。这个函数允许你将一个或多个变量保存到一个文件里。新文件创建时,任何同名文件都会被销毁。为了将变量precipitation保存到一个名为precipitation.lsp的文件,键入:
> (savevar 'precipitation "precipitation")不需要加.lsp后缀名,savevar会帮你加上的。为了保存两个变量hc和co到examples.lsp文件,键入:
(savevar '(hc co) "samples")我使用一个带引号的列表'(hc co)并将该符号列表传递给savevar函数。还有一个长点的表达式可以代替它:(list 'hc 'co)。
文件precipitation.lsp和samples.lsp获得了表达式集合,当使用read函数读取这两个文件的时候,它们将重新创建precipitation、hc和co变量。为了加载precipitation.lsp文件,可以使用如下表达式:
> (load "precipitation")2.3.2 命令历史机制
Common Lisp提供了一个简单的命令历史机制。符号 -, *, **, ***, +, ++和+++就是为实现这一意图的。解释器将这些符号与其意义绑定如下:
- - 当前输入的表达式
- + 读取最近一个表达式
- ++ +返回的表达式的前一个表达式
- +++ ++返回的表达式的前一个表达式
- * 最近的一个表达式的结果
- ** *所属表达式的前一个表达式的结果
- *** **所属表达式的前一个表达式的结果
*, **, ***这三个变量也许是最有用的。例如,如果你想求某个变量的对数值,但忘了给它定义变量名,你就可以使用那几个历史变量来避免重复计算对数:
> (log precipitation)
(-0.2613647641344075 0.5538851132264376 -0.21072103131565253 0.1823215567939546 0.6678293725756554 0.1823215567939546 -0.7550225842780328 0.3576744442718159 1.2149127443642704 0.7884573603642703 1.0986122886681098 1.128171090909654 0.412109650826833 0.7419373447293773 -0.6539264674066639 0.4824261492442928 0.2700271372130602 -1.1394342831883648 -0.527632742082372 -0.21072103131565253 1.0331844833456545 0.6259384308664954 0.16551443847757333 0.30010459245033816 1.55814461804655 0.9082585601768908 -0.040821994520255166 0.636576829071551 -0.10536051565782628 0.7178397931503168)
> (def log-precip *)现在,变量log-precip就包含降水量数值的对数了。
系统利用了2.2.3节讨论的一个事实,那就是符号可以同时又函数定义和数值。符号*的函数定义是乘法函数,它的值是解释器返回的上一个求值结果。
2.3.3 获取帮助
Lisp-Stat提供了大量的不同的函数。我们不可能精确地记起每个函数的用法。一个交互式的帮助应用可以完成一些任务:找出需要的正确的函数,找出如何更容易地使用这个函数。例如,下边就是如何获得median函数帮助的例子:
> (help 'median)
loading in help file information - this will take a minute ...done
MEDIAN [function-doc]
Args: (x)
Returns the median of the elements of X.
NIL
>median函数前面的引号是必要的。help函数本身也是函数,它的参数是median函数的符号形式。为了确保help函数能够接受到符号,而不是符号的值,你需要引用(quote)这个符号(symbol)。
如果你对函数的名字不确定,你可能需要使用help*函数来获取帮助。假设你想找出与正太分布相关的函数,它们的名字里多数都包含"norm",表达式(help* 'norm)将打印函数名里包含"norm"的所有符号的帮助信息:
(help* 'norm)
------------------------------------------------------------------------------
BIVNORM-CDF [function-doc]
Args: (x y r)
Returns the value of the standard bivariate normal distribution function
with correlation R at (X, Y). Vectorized.
------------------------------------------------------------------------------
Sorry, no help available on NORM
------------------------------------------------------------------------------
Sorry, no help available on NORMAL
------------------------------------------------------------------------------
NORMAL-CDF [function-doc]
Args: (x)
Returns the value of the standard normal distribution function at X.
Vectorized.
------------------------------------------------------------------------------
NORMAL-DENS [function-doc]
Args: (x)
Returns the density at X of the standard normal distribution. Vectorized.
------------------------------------------------------------------------------
NORMAL-QUANT [function-doc]
Args (p)
Returns the P-th quantile of the standard normal distribution. Vectorized.
------------------------------------------------------------------------------
NORMAL-RAND [function-doc]
Args: (n)
Returns a list of N standard normal random numbers. Vectorized.
------------------------------------------------------------------------------
Sorry, no help available on NORMALREG-MODEL
------------------------------------------------------------------------------
Sorry, no help available on NORMALREG-PROTO
------------------------------------------------------------------------------
NIL
>符号norm, normal, normalreg-model和normalreg-proto没有函数定义,因此没有可用的帮助信息。函数文档里的术语vectorized意味着这个函数可以被应用到形式为列表的参数上;它的结果是这个函数作用到参数的每一个元素后返回的结果列表。文档中出现的一个相关的术语是vector reducing。如果一个函数可以递归地操作它的参数,直到只剩一个单独的数字为止,那么这个函数就是vector reducing(矢量减少)的。函数sum, prod, max和min都是矢量减少的。
作为使用help*的替代品,你可以使用apropos函数来获得包含字符串"norm"作为其名字一部分的那些符号的列表:
> (apropos 'norm)
NORMALREG-PROTO
NORMALREG-MODEL
NORM
BIVNORM-CDF
NORMAL-QUANT
NORMAL-RAND
NORMAL
NORMAL-CDF
NORMAL-DENS
>然后使用help函数询问每个符号的更多信息。
让我来简要地介绍一下help函数打印的信息所用到的表示方法,来描述一个函数期望参数有的功能。表示方法对应的Lisp函数定义的参数列表的规格将在4.2节描述。多数函数期望参数列表是固定的,想在帮助信息里的这行一样: Args: (x y z)。有的参数可能会接收一个或多个可选参数,这种函数的参数可能会这样表示: Args: (x &optional y (z t)),这意味着x是必选参数,y和z是可选参数。如果这个函数命名是f,可以这样调用:(f x-val), (f x-val y-val),或者(f x-val y-val z-val)。列表(z t)意味着没有提供参数z,那它的默认值就是t;y是没有强制指定默认值的参数,因此它的默认值是nil。实参必须按照形参规定的顺序和规则来提供,因此如果你要是想传递参数z,那就必须先对y赋值。
另一个形式的可选参数是关键字参数。例如,histogram函数的参数是这样的:Args: (data &key (title "Histogram")),data参数是必选的,title就是可选的关键字参数,其默认值是"Histogram"。如果你用2.2.1节用到的降水量数据创建一张表,它的名字是"Precipitation"可以用这个表达式:
> (histogram precipition :title "Prcipitation")图2.7 图形title修改示意图
因此,为了给关键字参数一个值,你将需要显式地给出这个关键字名,也就是一个由冒号紧跟着参数名的一个符号,然后是这个参数的值。如果一个函数带多个关键字参数,在调用时这些关键字参数之间的顺序可以任意指定,前提是他们需呀在必选参数可可选函数之后。(注:关于这点建议参考《实用Common Lisp编程》第4.2~4.5节,认真实践,方可领悟!)
最后,一些函数可能带不定数量的参数,可用下式表示:Args: (x &rest ars)。该参数列表表示参数x是必选参数,同时可以带0个到多个附加参数。(注:相当于C语言参数列表里的 “...”)
除了函数,help函数还能针对数据类型和一些变量给出帮助信息。例如:
> (help 'complex)
loading in help file information - this will take a minute ...done
COMPLEX [function-doc]
Args: (realpart &optional (imagpart 0))
Returns a complex number with the given real and imaginary parts.
COMPLEX [type-doc]
A complex number
NIL这个例子展示了complex复数数据类型的功能和类型信息。下边这个例子
> (help 'pi)
PI [variable-doc]
The floating-point number that is approximately equal to the ratio of the
circumference of a circle to its diameter.
NIL展示了pi这个变量的文档。
2.3.4 列举变量和取消变量定义
在工作一段时间之后,你可能想要查明使用def宏定义了哪些变量,variables函数将以列表的方式返回这些变量:
> (variables)
(CO HC PRECIPITATION RURAL URBAN)你可能偶尔对不在使用的变量进行释放以获得一些空间。要达到这个目的你可以使用undef函数:
> (undef 'co)
CO
> (variables)
(HC PreCIPITATION RURAL URBAN)undef的参数是一个符号(symbol),本例总我们必须引用它以避免解释器对其求值。undef也能接受符号列表当做参数,因此想要取消定义当前所有已经定义的变量,可以这样:
> (undef (variables))
(HC PRECIPITATION RURAL URBAN)
> (variables)
NIL2.3.5 中断计算
偶尔你可能在系统里开始了这样一种计算,它耗用了太长的时间或者产生了一个看起来不合理的结果。每个系统都提供了一个机制来中断这样的计算过程,但是这些机制依据系统的不同而不同。在Macintosh操作系统下的XLISP-STAT里,你可以按住COMMON键和PERIOD键直到系统将解释器交由你来输入。在UNIX版本的XLISP-STAT里,你可以按下为你的系统准备的中断键组合来中断这种计算,通常这个中断键组合为CONTROL+C。
2.4 一些数据处理函数
目前为止我们都是将数据直接敲到解释器里的,数据集较小,所以这也不是什么大问题,然而,有其它的替代方法会更有用。Lisp-Stat提供了一些函数,可以生成系统的数据和随机数据,可以提取数据集的一部分,修改数据集,并且可以从文件中读取数据。
2.4.1 生成有系统的数据
函数iseq用来生成连续的整数序列,rseq用来生成等间隔的实数序列,它们在2.2.2节提到了。函数iseq也可以通过传递一个单独参数来调用,这种情况下参数应该是一个正整数n,结果是从0到n-1的整数列表。例如:
> (iseq 10)
(0 1 2 3 4 5 6 7 8 9) 函数repeat在生成具有一定格式的序列时是很有用的,调用repeat函数的一般格式是(repeat
> (repeat 2 3)
(2 2 2)
> (repeat (list 1 2 3) 2)
(1 2 3 1 2 3)如果
> (repeat (list 1 2 3) (list 3 2 1))
(1 1 1 2 2 3)函数repeat在设计实验中的编码处理层面上是极其有用的。例如,在一个测试植物种植密度对马铃薯生长的影响的实验里,有3个品种的马铃薯,种植在4个不同种植密度的地方,每一种测试组合重复3次,结果在下表中:
我们可以将这些数据按行,输入到产量变量里,如:
> (def yield (list 9.2 12.4 5.0 8.9 9.2 6.0 16.3 15.2 9.4
12.4 14.5 8.6 12.7 14.0 12.3 18.2 18.0 16.9
12.9 16.4 12.1 14.6 16.0 14.7 20.8 20.6 18.7
10.9 14.3 9.2 12.6 13.0 13.0 18.3 16.0 13.0))使用repeat,我们可以这样生成表示不同品种和密度水平的变量:
> (def variety (repeat (repeat (list 1 2 3) (list 3 3 3)) 4))
VARIETY
> (def density (repeat (list 1 2 3 4) (list 9 9 9 9)))
DENSITY
>练习2.7
略。
练习2.8
略。
2.4.2 生成随机数据
一些函数可以生成伪随机数字,例如,表达式(uniform-random 50)将生成一个的数字列表,列表的元素是50个在0和1之间的独立随机均匀分布的数字。函数normal-rand和cauchy-rand也类似地生成标准正态的或标准柯西随机变量。表达式:
> (gamma-rand 50 4)
(1.65463390351748 2.8773826027572174 3.324805876512575 3.7107737590852885 2.5322960063057325 2.3917079623070143 2.5738732854681405 5.114579884756656 4.503560922291987 3.8212691381896735 4.748609795710945 2.460930129538628 5.1583129719078125 2.8722892003673204 2.271632493827859 1.306689218830528 2.956587212984247 2.254496336799741 1.5432493948171886 1.0074517838362944 2.3221187903990685 2.9297357635208368 1.9111207190664348 4.086600231358658 8.498775494298609 3.309145002227253 8.43403656671126 2.9001355594385445 2.156028887326921 5.457111466807575 2.7180957670090233 6.727592025517272 3.2182935800579466 4.759355290676398 2.1463912302657 4.641326968027183 4.951716760175214 2.9685374305637593 5.934043534710339 6.847560103820065 5.612014958257557 4.4811213649680814 7.4465265497488975 2.6911820555097306 1.0087771420430949 1.4549088997831112 5.276729335543616 2.773807551655783 3.565519147704477 2.7611738530317305)生成一个大小为50的数据样本,这些数据符合伽马-分布,单位尺度,指数为4。
指数为3.5~7.2的β分布变量可以这样生成:
> (beta-rand 50 3.5 7.2)
(0.4565276604553964 0.2784641511528651 0.1992946182796908 0.15531331094658482 0.1524256312642991 0.26070619189857414 0.26797467262440017 0.22086809762954612 0.30818508575346343 0.31431320706862537 0.4767943879658169 0.3103165584027092 0.3099168733453603 0.48844354838756315 0.3850748530401529 0.5261394345014925 0.4729101627118159 0.34008228819566094 0.34728211784541685 0.11375668596438508 0.3177405260351405 0.15233790451255871 0.3247481923221466 0.16163693218582695 0.34148249992894264 0.26747115750175693 0.1917463536194362 0.3096184276126184 0.2815407126874605 0.27277307887112906 0.5364074613555034 0.5343432853990229 0.7113134763751001 0.2008014529296493 0.1610644249288089 0.14281693672275156 0.1994676889199915 0.3627351688059498 0.4983412412275205 0.4279902846854145 0.42865178072445864 0.32624949341033294 0.38525682966664915 0.3395031181658098 0.35242269440634416 0.3010577148339438 0.3497046925914022 0.12251980989006983 0.3635843569985974 0.12912742911247255)大小为50,自由度为4的t-分布随机变量样本:
> (t-rand 50 4)自由度为4的卡方-分布随机变量的生成表达式:
> (chisq-rand 50 4)分子自由度为3,分母自由度为12的F-分布的随机变量的生成表达式:
> (f-rand 50 3 12)参数n=5,p=0.3的二项式分布样本生成表达式为:
> (binomial-rand 50 5 .3)大小为50,期望值λ=4.3的泊松-分布随机数据样本生成表达式:
> (poisson-rand 50 4.3)这些样本生成函数的“大小”这一参数也可以是一个整数列表,相应地,返回的结果是样本列表的列表(即多条样本列表)。例如:
> (normal-rand (list 10 10 10))
((0.24711492524397788 -0.08672761627290786 -0.3586542916304954 -1.2370666723700587 0.4973152707135397 1.2779437429528906 0.5433681505645361 -0.15811161781047764 -2.444951338731246 1.4391452075883056)
(-0.024198159865474137 0.018494098689563702 -1.201497046490873 0.29215227642978814 -0.1504967544867967 0.8539957140604427 0.1866809359842353 -0.3235190277039044 1.2316501558225053 -0.3173822473522208)
(2.6816999640212815 1.312819856883247 0.3381892163767421 0.20384488399908143 0.9360472535774436 -1.3160001465807794 0.033750173542764696 -0.4613961332004225 -0.9523674256520025 -2.2724093805908905))该表达式产生了一个列表集,其中的每个列表都是有十个正态分布变量的列表。
最后,你可以使用sample函数从一个列表里随机里选出一个数据样本,表达式(sample (iseq 1 20) 5)的返回值就是,在1, 2, ..., 20这个列表里,随机地选择5个元素,组成一个大小是5的新的没有重复元素的样本,其结果可能是:
> (sample (iseq 1 20) 5)
(2 19 1 3 5)sample函数可以通过启用第三个参数(一个可选参数)来指定采样元素是否可以重复。那么下个表达式
> (sample (iseq 1 20) 5 t)
(11 11 5 4 16)将允许sample函数在采样的时候允许元素重复(注:原文使用replacement表示的,但我无法翻译成合适的中文,如果有更精确的翻译,欢迎指正)。
第三个参数为nil时,sample函数采样时不允许元素重复,这与忽略这个参数的情况是一样的。
练习2.9
略。
2.4.3 建立子集和删除
select函数允许你从一个列表里选择一个单独的元素或者一组元素。例如,你这样定义了一个x变量:
> (def x (list 3 7 5 9 12 3 14 2))那么
> (select x i)将返回变量x的第i个元素。Lisp语言列表的下标是从0开始的,这点与C语言相同,但是和FORTRAN不同。因此它的下标应该是0, 1, 2, 3, 4, 5, 6, 7,所以有:
> (select x 0)
3
> (select x 2)
5为了获取一组元素,我们可以使用下标数组来代替单个的下标,即:
> (select x (list 0 2))
(3 5)如果你想选择除了下标为2的元素之外的所有元素的话,使用以下表达式
> (remove 2 (iseq 8))来产生下标序列,并把它作为select函数的第二个参数:
> (select x (remove 2 (iseq 8)))
(3 7 9 12 3 14 2)表达式(iseq 8)生成了从0到7的整数列表。remove函数会返回一个移除指定元素的列表,那么
> (remove 3 (list 1 3 4 3 2 5))
(1 4 2 5)剩下的元素按它们在原始列表里的顺序返回。
另一个返回除了2号下标元素的方法是使用对照函数"/="(意思是“不等于”)来告诉你哪些下标不等于2:
> (/= 2 (iseq 8))
(T T NIL T T T T T)函数which能够返回,其函数的参数的不是nil的哪些下标的元素的列表,即
> (which (/= 2 (iseq 8)))
(0 1 3 4 5 6 7)结果可以传递给select函数:
> (select x (which (/= 2 (iseq 8))))
(3 7 9 12 3 14 2)对于删除一个元素来说,这个方法有一点太笨重了,然而它却是一个通用的方法。例如如下表达式
> (select x (which (< 3 x)))
(5 7 9 12 14)将返回所有比3大的元素。
由于我们在上边几个例子里用到的x变量比较短,通过数数我们也可以很容易地确定他的长度。对于再长点儿的列表就不太容易了,我们可以使用length函数来实现。使用length函数,我们也能实现"选择除了下边为2的其它元素"这一功能:
> (select x (remove 2 (iseq (length x))))练习2.10
略。
2.4.4 合并列表
有时你可能想将几个短的列表合并为一个长的列表,可以用append和combine函数来完成。例如,
> (append (list 1 2 3) (list 4) (list 5 6 7 8))
(1 2 3 4 5 6 7 8)或者
> (combine (list 1 2 3) (list 4) (list 5 6 7 8))
(1 2 3 4 5 6 7 8)这两个函数的不同在于它们对列表的列表的处理方式上。append函数只合并外部列表,而combine函数会递归地调用到子列表,并返回一个没有复合元素的列表(即不包含子列表):
> (append (list (list 1 2) 3) (list 4 5))
((1 2) 3 4 5)
> (combine (list (list 1 2) 3) (list 4 5))
(1 2 3 4 5)combine函数允许他的参数是数字或者其它简单数据项,比如:
> (combine 1 2 (list 3 4))
(1 2 3 4)而append函数的参数必须是列表(list)形式,否则会报错。
> (append 1 2 (list 3 4))
Error: bad argument type - 1
Happened in: #2.4.5 修改数据
setf可以用来修改列表的单个元素或者列表的元素集合。再一次假设我们设置了一个列表x:
> (def x (list 3 7 5 9 12 3 14 2))我们想把12改成11,使用如下表达式(setf (select x 4) 11)来做这个替换:
> (setf (select x 4) 11)
11
> x
(3 7 5 9 11 3 14 2)setf的一般形式为(setf