FastDFS集群同步合并压缩机制介绍
Java组件总目录
FastDFS整合Nginx与集群
- Java组件总目录
-
- 问题说明
- 一、FastDFS 的 Nginx 模块原理分析
-
- 1.1 模块介绍
- 二、集群下的文件同步
-
- 2.1 12.1何时开启同步线程
- 2.2 同步规则
- 2.3 同步流程
-
- 1. Binlog 目录结构
-
- Mark 文件
- Binlog 文件
- 2.4 同步过程
-
- 1 启动同步线程
- 2 同步线程执行过程
- 2.5 文件同步时间戳
- 2.6问题解释
- 三、 合并存储
-
- 1 合并存储好处
-
- 海量小文件存储问题
-
- 1 元数据管理低效
- 2 数据布局低效
- 3 IO访问流程复杂
- 2 合并存储介绍
- 3 合并存储介绍
-
- 概念区分
- Trunk文件内部结构
- 合并存储配置
- 4. 空闲空间概述
-
- 1. 空余空间
- 2. 使用空余空间
- 3 TrunkServer空闲空间分配
- 4 TrunkFile同步
- 5 空闲平衡树重建与压缩
-
- 1 为什么要重建空闲平衡树
- 2 TrunkBinlog压缩
- 四、 图片压缩
-
- 1. 压缩模块介绍
- 2. 模块安装与使用
理解FastDFS&nginx访问流程:
掌握FastDFS错误日志查看方法: base_path/log 中
理解FastDFS文件同步原理
掌握FastDFS文件合并存储机制
掌握FastDFS图片压缩机制
理解FastDFS快速定位文件机制
问题说明
- 上传文件的时候是nginx直接连接到文件服务器吗?
上传文件时 Clinet 与 Storage 是通过TCP 协议;不是nginx 服务器;
浏览器显示图片,通过nginx服务器(作为Http服务器存在),访问Storage 的图片是Http 协议。
一、FastDFS 的 Nginx 模块原理分析
由于经常需要为FastDFS存储的文件提供http下载服务,但是FastDFS在其storage及tracker都内置了http服务, 但性能表现却不尽如人意。
所以增加了基于当前主流web服务器的扩展模块(包括nginx/apache),其用意在于利用web服务器直接对本机storage数据文件提供http服务,以提高文件下载的性能。
其实不使用Nginx的扩展模块,只安装web服务器(Nginx和Apache),也可以对存储的文件进行访问。那么为什么要使用Nginx的扩展模块来访问存储的文件,原因有两个:
- 如果进行文件合并存储,那么不使用FastDFS的nginx扩展模块,是无法访问到合并后的文件的,因为文件合并之后,多个 小文件都是存储在一个trunk文件中的,在存储目录下,是看不到具体的小文件的。
- 如果文件未同步成功,那么不使用FastDFS的nginx扩展模块,是无法正常访问到指定的文件的,而使用了FastDFS的 nginx扩展模块之后,如果要访问的文件未同步成功,那么会解析出来该文件的源存储服务器ip,然后将该访问请求重定向或者代理到源存储服务器中进行访问。
1.1 模块介绍
模块结构

在每一台storage服务器主机上部署Nginx及FastDFS扩展模块,由Nginx模块对storage存储的文件提供http下载服务, 仅当当前storage节点找不到文件时会向源storage主机发起redirect或proxy动作。
概念说明
- storage_id:指storage server的id,从FastDFS4.x版本开始,tracker可以对storage定义一组ip到id的映射,以id的形式对storage进行管理。而文件名写入的不再是storage的ip而是id,这样的方式对于数据迁移十分有利。
- storage_sync_file_max_delay:指storage节点同步一个文件最大的时间延迟,是一个阈值;如果当前时间与文件创建时间的差距超过该值则认为同步已经完成。
- anti_steal_token:指文件ID防盗链的方式,FastDFS采用token认证的方式进行文件防盗链检查。
组件初始化流程:

下载文件流程:

二、集群下的文件同步
2.1 12.1何时开启同步线程
从Tracker Server获取到同组storage server集合后,就会为除了自己之外的其他同组storage server分别开启同步线程。
如果组内有三个Storage Server,那么每台Storage Server都应该开启两个独立同步线程。
2.2 同步规则
- 只在本组内的storage server之间进行同步;
- 源头数据才需要同步,备份数据不需要再次同步,否则就构成环路了;
- 同步采取push方式,即源服务器同步给同组其他服务器;
- 上述第二条规则有个例外,就是新增加一台storage server时,由已有的一台storage server将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器
2.3 同步流程
1. Binlog 目录结构
binlog.index # 记录当前使用的binlog文件序号,如为100,则表示使用binlog.010
192.168.1.2_33450.mark
192.168.1.3_33450.mark
binlog.100
Mark 文件
同步状态文件,192.168.1.2_33450.mark 记录本机到192.168.1.2_33450的同步状态。
binlog_index=0 # 对应于哪个binlog
binlog_offset=1334 # binlog.xxx的偏移量,可以直接这个偏移量获取下一行记录, 同步到哪一行了
need_sync_old=1 #本storage是否是对侧storage(10.100.66.82)的源结点, 同时是否需要从起点同步所有的记录
sync_old_done=1 # 是否同步完成过
until_timestamp=1457542256 # 上次同步时间结点
scan_row_count=23 # 总记录数
sync_row_count=11 #已同步记录数
Binlog 文件
Binlog文件内容:在该文件中是以binlog日志组成,比如:
1470292943 c M00/03/61/QkIPAFdQCL-AQb_4AAIAi4iqLzk223.jpg
1470292948 C M00/03/63/QkIPAFdWPUCAfiraAAG93gO_2Ew311.png
1470292954 d M00/03/62/QkIPAFdWOyeAO3eUAABvALuMG64183.jpg
1470292959 C M00/01/23/QUIPAFdVQZ2AL_o-AAAMRBAMk3s679.jpg
文件说明:
其中的每一条记录都是使用[空格符]分成三个字段,分别为:
- 第一个字段 表示文件 upload 时间戳 如:1470292943
- 第二个字段 表示文件执行操作,值为下面几种(其中源表示客户端直接操作的那个 Storage 即为源,其他的 Storage 都为副本)
- 第三个字段 表示文件
C 表示源创建、c 表示副本创建
A 表示源追加、a 表示副本追加
D 表示源删除、d 表示副本删除
2.4 同步过程
从fastdfs文件同步原理中我们知道Storaged server之间的同步都是由一个独立线程负责的,这个线程中的所有操作都是以同步方式执行的。比如一组服务器有A、B、C三台机器,那么在每台机器上都有两个线程负责同步,如A机器,线程1负责同步数据到B,线程2负责同步数据到C。每个同步线程负责到一台Storage的同步,以阻塞方式进行。
1 启动同步线程
在Storage.conf配置文件中,只配置了Tracker的IP地址,并没有配置组内其他的Storage。因此同组的其他Storage必须从Tracker获取。具体过程如下:
1)Storage启动时为每一个配置的Tracker启动一个线程负责与该Tracker的通讯。
2)默认每间隔30秒,与Tracker发送一次心跳包,在心跳包的回复中,将会有该组内的其他Storage信息。
3)Storage获取到同组的其他Storage信息之后,为组内的每个其他Storage开启一个线程负责同步。
2 同步线程执行过程
每个同步线程负责到一台Storage的同步,以阻塞方式进行。
1)打开对应Storage的mark文件,如负责到10.0.1.1的同步则打开10.0.1.1_23000.mark文件, 从中读取binlog_index、binlog_offset两个字段值, 如取到值为:1、100,那么就打开binlog.001文件,seek到100这个位置。
2)进入一个while循环,尝试着读取一行,若读取不到则睡眠等待。若读取到一行, 并且该行的操作方式为源操作,如C、A、D、T(大写的都是), 则将该行指定的操作同步给对方(非源操作不需要同步), 同步成功后更新binlog_offset标志,该值会定期写入到10.0.1.1_23000.mark文件之中。
2.5 文件同步时间戳
举个例子:一组内有Storage-A、Storage-B、Storage-C三台机器。对于A这台机器来说,B与C机器都会同步Binlog(包括文件)给他,A在接受同步时会记录每台机器同步给他的最后时间(也就是Binlog中的第一个字段timpstamp)。比如B最后同步给A的Binlog-timestamp为100,C最后同步给A的Binlog-timestamp为200,那么A机器的最后最早被同步时间就为100。
这个值的意义在于,判断一个文件是否存在某个Storage上。比如这里A机器的最后最早被同步时间为100,那么如果一个文件的创建时间为99,就可以肯定这个文件在A上肯定有。为什呢?一个文件会Upload到组内三台机器的任何一台上:
1)若这个文件是直接Upload到A上,那么A肯定有。
2)若这个文件是Upload到B上,由于B同步给A的最后时间为100,也就是说在100之前的文件都已经同步A了,那么A肯定有。(同步不一定完成)
3)同理C也一样。
Storage会定期将每台机器同步给他的最后时间告诉给Tracker,Tracker在客户端要下载一个文件时,需要判断一个Storage是否有该文件,只要解析文件的创建时间,然后与该值作比较,若该值大于创建创建时间,说明该Storage存在这个文件,可以从其下载。
Tracker也会定期将该值写入到一个文件之中,storage_sync_timestamp.dat,内容如下:
group1,10.0.0.1, 0, 1408524351, 1408524352
group1,10.0.0.2, 1408524353, 0, 1408524354
group1,10.0.0.3, 1408524355, 1408524356, 0
每一行记录了,对应Storage同步给其他Storage的最后时间,如第一行表示10.0.0.1同步给10.0.0.2的最后时间为1408524351,同步给10.0.0.3的最后时间为1408524352;同理可以知道后面两行的含义了。每行中间都有一个0,这个零表示自己同步给自己,没有记录。按照纵列看,取非零最小值就是最后最早同步时间了,如第三纵列为10.0.0.1被同步的时间,其中1408524353就是其最后最早被同步时间。
2.6问题解释
问题一:同步到中途,把源文件删除,备份服务器怎么办?
源文件删除,同步就读取不到数据,把中断写入日志,直接同步下一条数据。
问题二:同步到中途,服务器宕机,如何解决?
Make,binlog 同步文件,记录同步偏移量,时间戳。 服务器宕机,下次重新启动,重新加载同步文件,发现没有同步完成。继续同步。
问题三:此时需要下载文件,如何确定从那台storage服务器下载文件呢? 此时服务器同步未完成?
Tracker 通过解析文件的创建时间和每台Storage机器的最小同步时间, 创建时间小于最小同步时间,说明该Storage存在这个文件,可以从其下载。
三、 合并存储
在处理【海量小文件(LOSF)】问题上,文件系统处理性能会受到显著的影响,在读写次数(IOPS)与吞吐量(Throughput)这两个指标上会有不少的下降。通常我们认为大小在【1MB以内】的文件称为小文件,【百万级数量及以上】称为海量,由此量化定义海量小文件问题,以下简称LOSF(全称lots of small files)
1 合并存储好处
海量小文件存储问题
1 元数据管理低效
由于小文件数据内容较少,因此元数据的访问性能对小文件访问性能影响巨大。当前主流的磁盘文件系统基本都是面向大文件高聚合带宽设计的,而不是小文件的低延迟访问。磁盘文件系统中,目录项(dentry)、索引节点(inode)和数据(data)保存在存储介质的不同位置上。因此,访问一个文件需要经历至少3次独立的访问。
这样,并发的小文件访问就转变成了大量的随机访问,而这种访问对于广泛使用的磁盘来说是非常低效的。同时,文件系统通常采用Hash树、 B+树或B*树来组织和索引目录,这种方法不能在数以亿计的大目录中很好的扩展,海量目录下检索效率会明显下降。正是由于单个目录元数据组织能力的低效,文件系统使用者通常被鼓励把文件分散在多层次的目录中以提高性能。然而,这种方法会进一步加大路径查询的开销

2 数据布局低效
磁盘文件系统使用块来组织磁盘数据,并在inode中使用多级指针或hash树来索引文件数据块。数据块通常比较小,一般为1KB、2KB或4KB。当文件需要存储数据时,文件系统根据预定的策略分配数据块,分配策略会综合考虑数据局部性、存储空间利用效率等因素,通常会优先考虑大文件I/O带宽。
对于大文件,数据块会尽量进行连续分配,具有比较好的空间局部性。对于小文件,尤其是大文件和小文件混合存储或者经过大量删除和修改后,数据块分配的随机性会进一步加剧,数据块可能零散分布在磁盘上的不同位置,并且会造成大量的磁盘碎片(包括内部碎片和外部碎片),不仅造成访问性能下降,还导致大量磁盘空间浪费。对于特别小的小文件,比如小于4KB,inode与数据分开存储,这种数据布局也没有充分利用空间局部性,导致随机I/O访问,目前已经有文件系统实现了data in inode。
3 IO访问流程复杂
对于小文件的I/O访问过程,读写数据量比较小,这些流程太过复杂,系统调用开销太大,尤其是其中的open()操作占用了大部分的操作时间。当面对海量小文件并发访问,读写之前的准备工作占用了绝大部分系统时间,有效磁盘服务时间非常低,从而导致小I/O性能极度低下。
因此一种【解决海量小文件】的途径就是将小文件【合并存储】成大文件,使用seek来定位到大文件的指定位置来访问该小文件。
2 合并存储介绍
FastDFS提供了【合并存储】功能,可以将【海量小文件】,合并存储为【大文件】。
默认创建的大文件为64MB,然后在该大文件中存储很多小文件。大文件中容纳一个小文件的空间称为一个Slot,规定Slot最小值为256字节,最大为16MB,也就是小于256字节的文件也需要占用256字节,超过16MB的文件不会合并存储而是创建独立的文件。
当没有启动合并存储时fileid和磁盘上实际存储的文件一一对应;当采用合并存储时就不再一一对应,而是多个fileid对应的文件被存储成一个大文件。
注:下面将采用合并存储后的大文件统称为trunk文件,没有合并存储的文件统称为源文件;
3 合并存储介绍
概念区分
- trunk文件:
storage服务器磁盘上存储的合并后的实际文件,默认大小为64MB。
Trunk文件文件名格式:fdfs_storage1/data/00/00/000001 文件名从1开始递增,类型为int; - 合并存储文件的fileid:
表示服务器启用合并存储后,每次上传返回给客户端的fileid,注意此时该fileid与磁盘上的文件没有一一对应关系; - 没有合并存储的fileid:
表示服务器未启用合并存储时,Upload返回的fileid。
合并存储时fileid:
group1/M00/00/00/CgAEbFQWWbyIPCu1AAAFr1bq36EAAAAAQAAAAAAAAXH82.conf
可以看出合并存储的fileid更长,因为其中需要加入保存的大文件id以及偏移量。
Trunk文件内部结构
trunk内部是由多个小文件组成,每个小文件都会有一个trunkHeader(占用24个字节),以及紧跟在其后的真实数据,结构如下:
|||——————————————————— 24bytes———-----———-——————————————————|||
|—1byte —-|— 4bytes ——|—4bytes —|—4bytes—|—4bytes—|——— 7bytes ————-|———2bytes————|
|—filetype—|—alloc_size—|—filesize—|—crc32—–|—mtime—|—formatted_ext_name—|—file_data filesize bytes—|
||———————file_data————————————————————————————||
合并存储配置
FastDFS提供了合并存储功能的实现,所有的配置都在tracker.conf文件之中,具体摘录如下:
注意:开启合并存储只需要设置use_trunk_file = true和store_server=1
4. 空闲空间概述
1. 空余空间
Trunk文件为64MB(默认),因此每次创建一次Trunk文件总是会产生空余空间,比如为了存储一个10MB文件,创建一个Trunk文件,那么就会剩下接近54MB的空间(TrunkHeader 会24字节,后面为了方便叙述暂时忽略其所占空间),下次要想再次存储10MB文件时就不需要创建新的文件,存储在已经创建的Trunk文件中即可。
另外当删除一个存储的文件时,也会产生空余空间。
2. 使用空余空间
在Storage内部会为每个store_path构造一颗以空闲块大小作为关键字的空闲平衡树,相同大小的空闲块保存在链表之中。
每当需要存储一个文件时会首先到空闲平衡树中查找大于并且最接近的空闲块,然后试着从该空闲块中分割出多余的部分作为一个新的空闲块,加入到空闲平衡树中。
例如:
- 要求存储文件为300KB,通过空闲平衡树找到一个350KB的空闲块,那么就会将350KB的空闲块分裂成两块,前面300KB返回用于存储,后面50KB则继续放置到空闲平衡树之中。
- 假若此时找不到可满足的空闲块,那么就会创建一个新的trunk文件64MB,将其加入到空闲平衡树之中,再次执行上面的查找操作(此时总是能够满足了)
3 TrunkServer空闲空间分配
假若所有的Storage都具有分配空闲空间的能力(upload文件时自主决定存储到哪个TrunkFile之中),那么可能会由于同步延迟导致数据冲突。
例如:
Storage-A中上传了一个文件A.txt 100KB,将其保存到000001这个TrunkFile的开头,与此同时,Storage-B也上传了一个文件B.txt 200KB,也将其保存在000001这个TrunkFile文件的开头,当Storage-B收到Storage-A的同步信息时,他无法将A.txt 保存在000001这个trunk文件的开头,因此这个位置已经被B.txt占用。
为了处理这种冲突,引入了TrunkServer概念,只有TrunkServer才有权限分配空闲空间,决定文件应该保存到哪个TrunkFile的什么位置。TrunkServer由Tracker指定,并且在心跳信息中通知所有的Storage。
引入TrunkServer之后,一次Upload请求,Storage的处理流程图如下:
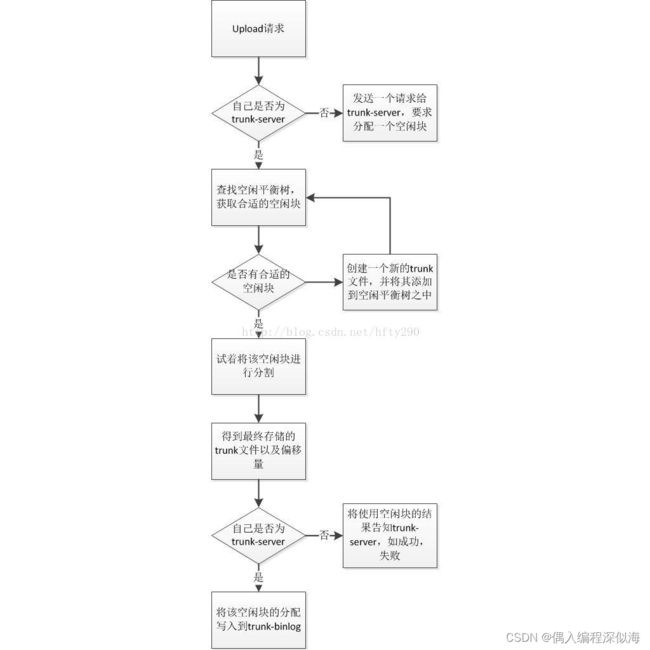
4 TrunkFile同步
开启了合并存储服务后,除了原本的源文件(trunk文件和未合并文件)同步之外,TrunkServer还多了TrunkBinlog的同步(非TrunkServer没有TrunkBinlog同步)。源文件的同步与没有开启合并存储时过程完全一样,都是从binlog触发同步文件。
TrunkBinlog记录了TrunkServer所有分配与回收空闲块的操作,由TrunkServer同步给同组中的其他Storage。TrunkServer为同组中的其他Storage各创建一个同步线程,【每秒】将TrunkBinlog的变化同步出去。同组的Storage接收到TrunkBinlog【只是保存到文件中,不做其他任何操作】
TrunkBinlog文件文件记录如下:
1410750754 A 0 0 0 1 0 67108864
1410750754 D 0 0 0 1 0 67108864
各字段含义如下(按照顺序):
时间戳
操作类型(A:增加,D:删除)
5 空闲平衡树重建与压缩
当作为TrunkServer的Storage启动时可以从TrunkBinlog文件中中加载所有的空闲块分配与加入操作,这个过程就可以实现空闲平衡树的重建。
1 为什么要重建空闲平衡树
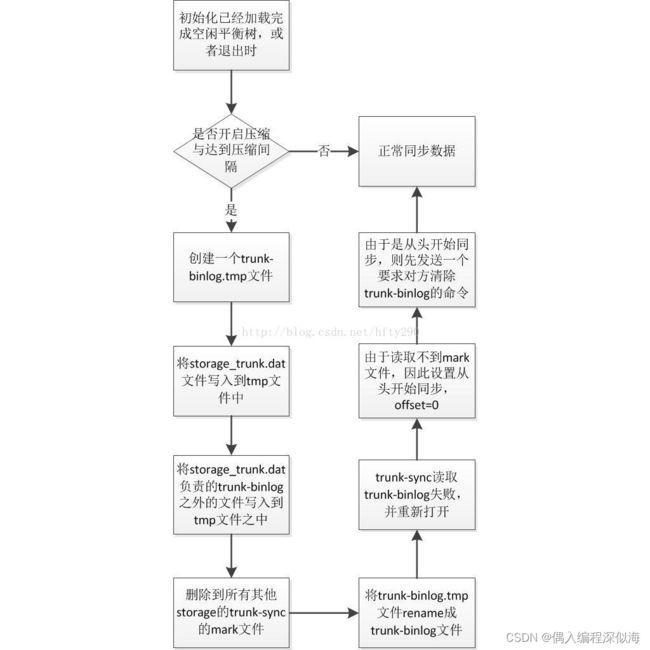
当长期运行时,随着空闲块的不断删除添加会导致TrunkBinlog文件很大,那么加载时间会很长,FastDFS为了解决这个问题,引入了检查点文件storage_trunk.dat,每次TrunkServer进程退出时,会将当前内存里的空闲平衡树导出为storage_trunk.dat文件,该文件的第一行为TrunkBinlog的offset,也就是该检查点文件负责到这个offset为止的TrunkBinlog。也就是说下次TrunkServer启动的时候,先加载storage_trunk.dat文件,然后继续加载这个offset之后的TrunkBinlog文件内容。
下面为TrunkServer初始化的流程图:

2 TrunkBinlog压缩
上文提到的storage_trunk.dat既是检查点文件,其实也是一个压缩文件,因为从内存中将整个空闲平衡树直接导出,没有了中间步骤(创建、删除、分割等步骤),因此文件就很小。这种方式虽然实现了TrunkServer自身重启时快速加载空闲平衡树的目的,但是并没有实际上缩小TrunkBinlog文件的大小。假如这台TrunkServer宕机后,Tracker会选择另外一台机器作为新的TrunkServer,这台新的TrunkServer就必须从很庞大的TrunkBinlog中加载空闲平衡树,由于TrunkBinlog文件很大,这将是一个很漫长的过程
为了减少TrunkBinlog,可以选择压缩文件,在TrunkServer初始化完成后,或者退出时,可以将storage_trunk.dat与其负责偏移量之后的TrunkBinlog进行合并,产生一个新的TrunkBinlog。由于此时的TrunkBinlog已经从头到尾整个修改了,就需要将该文件完成的同步给同组内的其他Storage,为了达到该目的,FastDFS使用了如下方法:
- 1)TrunkServer将TrunkBinlog同步给组内其他Storage时会将同步的最后状态记录到一个mark文件之中,比如同步给A,则记录到A.mark文件(其中包括最后同步成功的TrunkBinlog偏移量)。
- 2)TrunkServer在将storage_trunk.dat与TrunkBinlog合并之后,就将本地记录TrunkBinlog最后同步状态的所有mark文件删除,如,一组有A、B、C,其中A为TrunkServer则A此时删除B.mark、C.mark。
- 3)当下次TrunkServer要同步TrunkBinlog到B、C时,发现找不到B.mark、C.mark文件,就会自动转换成从头开始同步文件。
- 4)当TrunkServer判断需要从头开始同步TrunkBinlog,由于担心B、C已经有旧的文件,因此就需要向B、C发送一个删除旧的TrunkBinlog的命令。
- 5)发送删除命令成功之后,就可以从头开始将TrunkBinlog同步给B、C了。
大家发现了么,这里的删除TrunkBinlog文件,会有一个时间窗口,就是删除B、C的TrunkBinlog文件之后,与将TrunkBinlog同步给他们之前,假如TrunkBinlog宕机了,那么组内的B、C都会没有TrunkBinlog可使用。
流程图如下:
四、 图片压缩
1. 压缩模块介绍
nginx_http_image_filter_module 在nginx 0.7.54以后才出现的,用于对JPEG, GIF和PNG图片进行转换处理(压缩图片、裁剪图片、旋转图片)。这个模块默认不被编译,所以要在编译nginx源码的时候,加入相关配置信息(下面会给出相关配置)。
2. 模块安装与使用
# 检测nginx模块安装情况
/kkb/server/nginx/sbin/nginx -V
# 安装gd,HttpImageFilterModule模块需要依赖gd-devel的支持
yum -y install gd-devel
# 将http_image_filter_module包含进来
cd /root/nginx-1.15.6
./configure \
--prefix=/kkb/server/nginx \
--pid-path=/var/run/nginx/nginx.pid \
--lock-path=/var/lock/nginx.lock \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--http-client-body-temp-path=/var/temp/nginx/client \
--http-proxy-temp-path=/var/temp/nginx/proxy \
--http-fastcgi-temp-path=/var/temp/nginx/fastcgi \
--http-uwsgi-temp-path=/var/temp/nginx/uwsgi \
--http-scgi-temp-path=/var/temp/nginx/scgi \
--with-http_gzip_static_module \
--add-module=/opt/fastdfs-nginx-module-1.20/src \ #http模块必须添加
--with-http_stub_status_module \
--with-http_ssl_module \
--with-http_realip_module \
--with-http_image_filter_module
make && make install
# 注意:重新编译时,必须添加上nginx编译http的扩展模块,否则无法访问fastdfs图片
location ~ group1/M00/(.+)_(\d+)x(\d+)\.(jpg|gif|png) {
# 设置别名(类似于root的用法)
alias /kkb/server/fastdfs/storage/data/;
# fastdfs中的ngx_fastdfs_module模块
ngx_fastdfs_module;
set $w $2;
set $h $3;
if ($w != "0") {
rewrite group1/M00(.+)_(\d+)x(\d+)\.(jpg|gif|png)$ group1/M00$1.$4 break;
}
if ($h != "0") {
rewrite group1/M00(.+)_(\d+)x(\d+)\.(jpg|gif|png)$ group1/M00$1.$4 break;
}
#根据给定的长宽生成缩略图
image_filter resize $w $h;
#原图最大2M,要裁剪的图片超过2M返回415错误,需要调节参数image_filter_buffer
image_filter_buffer 2M;
#try_files group1/M00$1.$4 $1.jpg;
}
# 重启Nginx, 由于添加了新的模块,所以nginx需要重新启动,不需要重新加载reload
/kkb/server/nginx/sbin/nginx -s stop
/kkb/server/nginx/sbin/nginx
访问方式:
![]()