shell脚本 ( 函数 数组 冒泡排序)
目录
什么是函数
使用函数的方法
格式
注意事项
函数的使用
函数可以直接使用
函数变量的作用范围
函数返回值
查看函数
删除函数
函数的传递参数
使用函数文件
编辑
拓展递归函数
例:求5的阶乘
什么是数组
使用数组的方法
1.先声明
2.定义数组
3.查看数组
显示数组值个数
显示数组全部下标
4.调用数组
5.删除数组
数组切片
遍历数组(可以用来随机点名)
随机数比较大小
编辑
冒泡排序
什么是函数
在Linux中,函数是一个可重复使用的代码块,用于执行特定任务。函数通常被定义为一个具有特定名称的代码块,并可以接受输入参数和返回值。通过使用函数,可以将代码分解为更小的逻辑块,提高代码的可读性、可维护性和重用性
函数是脚本的别名
使用函数可以避免代码重复,增加可读性
使用函数的方法
1.定义函数
2.引用函数
格式
1.函数名() {
脚本
}
2.function 函数名() {
脚本
}
3.function 函数名 (
)
注意事项
1.直接写 函数中调用函数 直接写函数名
2.同名函数 后一个生效
3.调用函数一定要先定义
4.每个函数是独立
函数的使用
函数可以直接使用
a() { cd /qqq;ls;} #定义函数a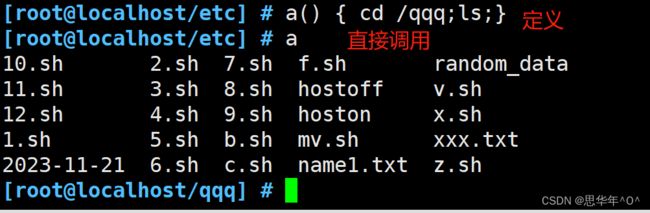
函数变量的作用范围
name=
local name= (函数名)
加 local 关键词 可以让变量只在函数中生效,
不会影响外界环境
函数返回值
如果使用函数
那 $? 使用就会受限
我们使用 return 自定义$?的返回值来判断
函数中的命令是否成功
user () {
if [ $1 = root ]
then
echo "你好管理员"
return 30 #是管理员返回值为30
else
echo "你不是管理员"
return 20 #不是管理员返回值为20
fi
}
user $1
echo $?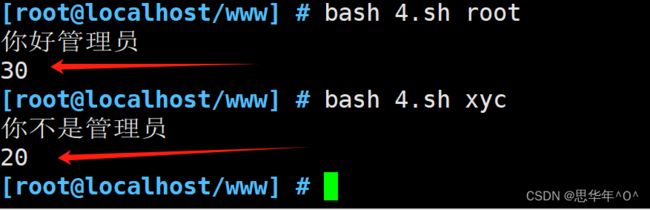
查看函数
declare -f 函数名
[root@localhost/qqq] # declare -f qwer #查看qwer函数
qwer ()
{
cd /qqq;
ls --color=auto
}
删除函数
ufunc_name
[root@localhost/qqq] # qwer #函数qwer可以调用
10.sh 2.sh 7.sh f.sh random_data
11.sh 3.sh 8.sh hostoff v.sh
12.sh 4.sh 9.sh hoston x.sh
1.sh 5.sh b.sh mv.sh xxx.txt
2023-11-21 6.sh c.sh name1.txt z.sh
[root@localhost/qqq] # unset func_name qwer #删除函数qwer
[root@localhost/qqq] # qwer #无法调用
bash: qwer: 未找到命令...
函数的传递参数
需注意
脚本 $1 $2
函数$1 $2
是没有关系
函数的$1 $2 是指跟在函数后面的值
#!/bin/bash
sum1 (){
echo $1
echo $2
}
sum1 $2 $1

使用函数文件
ostype (){ #定义函数
if grep -i -q "linux 6" /etc/os-release
then
echo "centos6"
elif grep -i -q "linux 7" /etc/os-release
then
echo "centos7"
elif grep -i -q "linux 8" /etc/os-release
then
echo "centos8"
else
echo "not linux"
fi
}

拓展递归函数
函数自己调用自己本身的函数
阶乘
例:求5的阶乘
4的阶乘结果*5
3的阶乘结果*4
2的阶乘结果*3
1的阶乘结果*2
1的阶乘结果就是1
#!/bin/bash
sum=1
read -p "请输入一个数字:" num
for i in `seq $num`
do
let sum=$[i*sum]
done
echo $sum
fact() {
if [ $1 -eq 1 ]
then
echo 1
else
local temp=$[$1 - 1]
local result=$(fact $temp)
echo $[$1 * $result]
fi
}
read -p "请输入:" n
fact $n

什么是数组
在Linux中,数组是一种数据结构,它用于存储一系列有序的元素。数组是一种线性数据结构,它可以用来存储相同类型的元素,这些元素按照顺序排列,每个元素都有一个唯一的索引,从0开始。
使用数组的方法
1.先声明
declare -a 普通数组 (不需要手动声明,系统帮你声明好了的)
declare -A 数组名 (关联数组一定要手动声明)
2.定义数组
1.数组名= (数组值,中间用空格隔开)
[root@localhost~] # xxx=( 10 20 30 )2.数组名 [下标1] =值1
数组名 [下标2] =值2
................
数组名 [下标n] 值n
3.查看数组
echo ${数组名[@]} echo ${数组名[*]}
[root@localhost~] # echo ${xxx[*]} #xxx为数组名
10 20 30
[root@localhost~] # echo ${xxx[@]}
10 20 30
显示数组值个数
echo $ {#数组名[@]} echo ${#数组名[*]}
[root@localhost~] # echo ${#xxx[@]} #数组名为xxx
3
[root@localhost~] # echo ${#xxx[*]}
3
显示数组全部下标
echo ${!数组名[@]} echo ${!数组名[*]}
[root@localhost~] # echo ${!xxx[@]}
0 1 2
[root@localhost~] # echo ${!xxx[*]}
0 1 2
4.调用数组
单个调用 echo ${数组名[0]} 调用第一个值 (调用数组值从0开始为第一个值)
[root@localhost~] # xxx=( 10 20 30 ) #定义数组
[root@localhost~] # echo ${xxx[0]} #调用第一个数组
10
[root@localhost~] # echo ${xxx[1]} #调用第二个数组
20
[root@localhost~] # echo ${xxx[2]} #调用第三个数组
30
5.删除数组
unset 数组名
[root@localhost~] # unset xxx
[root@localhost~] # echo ${xxx[@]}
单个删除 unset 数组名 [0下标] (删除数组值从0开始为第一个值)
[root@localhost~] # xxx=(10 20 30) #定义数组xxx
[root@localhost~] # echo ${xxx[@]} #查看数组
10 20 30
[root@localhost~] # unset xxx[0] #删除数组第一个值
[root@localhost~] # echo ${xxx[@]} #查看数组
20 30
数组切片
echo ${数组名[@]:2:2} (跳过前面2个往后取2个)
[root@localhost~] # a=(10 20 30 40 50 60) #定义数组
[root@localhost~] # echo ${a[@]:2:2} #跳过前面2个往后取2个
30 40
[root@localhost~] # echo ${a[@]:3:3} #跳过前面3个取后面2个
40 50 60
遍历数组(可以用来随机点名)
#!/bin/bash
# 定义一个数组
a=(apple banana orangen rape kiwi)
b=$(echo $[RANDOM%5]) #随机数
# 遍历数组并输出每个元素
echo "${a[$b]}"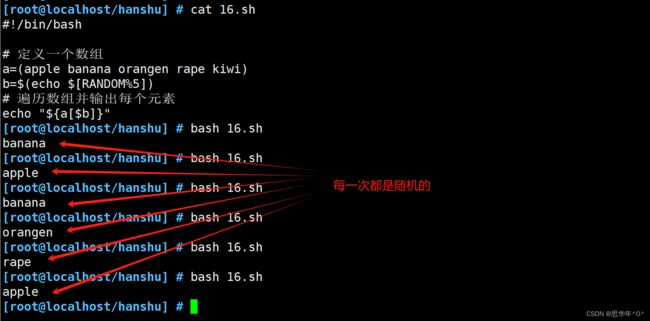
随机数比较大小
#!/bin/bash
for i in {0..9} #变量i在0到9之间循环
do
a[$i]=$RANDOM #建立数组a ,变量i是下标对应一次建立随机的数组值
[ $i -eq 0 ] && min=${a[0]} && max=${a[0]} #当下标为0时,定义其对标的数组值同时为最大和最小
[ ${a[$i]} -gt $max ] && max=${a[$i]}
[ ${a[$i]} -lt $min ] && min=${a[$i]}
#当下标为1时,下标对应的随机数会与当前的最大值与最小值作比较。比最大值大的,为最大值,比最小值小的,则为最小值。
done
echo "所有随机数为:${a[*]}"
echo "最大数为:$max"
echo "最小数为:$min"

冒泡排序
双重循环
内循环比较相邻数的大小找到最大数
#!/bin/bash
#生成一个随机数组
for i in {0..9}
do
a[$i]=$RANDOM
done
echo "原始数组为: ${a[@]}"
l=${#a[@]}
#定义变量l为数组a的长度10
for((i=1;i<$l;i++))
#需要比较的轮次
do
for ((j=0;j<$l-$i;j++))
#相邻的数需 要比较的次数
do
first=${a[$j]}
#数组的第一个数
k=$[$j+1]
#计算数组 下一个数的 下标
second=${a[$k]}
#下一个数
if [ $first -gt $second ]
#如果第一个数大于第二个数
then
temp=$first
a[$j]=$second
#第二个数就为下一次比较的第一个数
a[$k]=$temp
#第一个数就成为第二大的数
fi
done
done
echo "排序后的数组: ${a[@]}" 
![]()