后端开发面经
后端开发面经(大厂汇总):
-
-
- 目录:
-
- 一、TCP三次挥手四次握手;
-
- 1.1、三次握手的过程
- 1.2、四次挥手过程
- 1.3、 为什么TCP客户端最后还要发送一次确认呢?
- 1.4、如果已经建立了连接,但是客户端突然出现故障了怎么办?
- 1.5、为什么建立连接是三次握手,关闭连接确是四次挥手呢?
- 1.6、为什么客户端最后还要等待2MSL?
- 1.7、报文段主要含义
- 1.8、TCP 协议如何保证可靠传输?
- 1.9、TCP与UDP的区别
- 二、HTTPS和HTTP区别
- 三、 SSL与TLS
- 四、缓存穿透、击穿、雪崩
- 五、sychronized锁;
- 六、hashmap原理机制
- 七、进程通信;
- 八、打开一个网页的具体过程( 问的很详细 )
- 九、PCB
- 十、redits的持久化机制
- 十一、AQS原理
- 十一、死锁、内存管理
- 十二、举一个线程不安全的例子?分析一下具体的原因
- 十三、多线程
- 13.1、ConcurrentHashMap 的底层实现原理
- 13.2、线程同步的方法有哪些?
- 13.3、进程和线程的区别有哪些?
- 十四、Hash 冲突,哈希冲突四种解决办法
- 十五、项目中有没有接触过OOM?怎么解决的?
- 十六、b树和b+树区别
- 十七、事务隔离级别
- 十八、日志系统了解吗?redo log和undo log
-
目录:
一、TCP三次挥手四次握手;
1.1、三次握手的过程
1)主机A向主机B发送TCP连接请求数据包,其中包含 主机A的初始序列号seq(A)=x。(其中报文中同步标志位SYN=1,ACK=0,表示这是一个TCP连接请求数据报文;序号seq=x,表明传输数据时的第一个数据字节的序号是x);
2)主机B收到请求后,会发回连接确认数据包。(其中确认报文段中,标识位SYN=1,ACK=1,表示这是一个TCP连接响应数据报文,并含主机B的初始序列号seq(B)=y,以及主机B对主机A初始序列号的确认号ack(B)=seq(A)+1=x+1)
3)第三次,主机A收到主机B的确认报文后,还需作出确认,即发送一个序列号seq(A)=x+1;确认号为ack(A)=y+1的报文;
三次挥手(带状态):最开始的时候客户端和服务器都是处于CLOSED状态。主动打开连接的为客户端,被动打开连接的是服务器。
- TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态;
- TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
- TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
- TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
- 当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。
1.2、四次挥手过程
假设主机A为客户端,主机B为服务器,其释放TCP连接的过程如下:
1) 关闭客户端到服务器的连接:首先客户端A发送一个FIN,用来关闭客户到服务器的数据传送,然后等待服务器的确认。其中终止标志位FIN=1,序列号seq=u。
2) 服务器收到这个FIN,它发回一个ACK,确认号ack为收到的序号加1。
3) 关闭服务器到客户端的连接:也是发送一个FIN给客户端。
4) 客户段收到FIN后,并发回一个ACK报文确认,并将确认序号seq设置为收到序号加1。 首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
四次握手(带状态):数据传输完毕后,双方都可释放连接。最开始的时候,客户端和服务器都是处于ESTABLISHED状态,然后客户端主动关闭,服务器被动关闭。
- 客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
- 服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
- 客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
- 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
- 客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗ *∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
- 服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
1.3、 为什么TCP客户端最后还要发送一次确认呢?
一句话,主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
如果使用的是两次握手建立连接,假设有这样一种场景,客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了,由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。此时此前滞留的那一次请求连接,网络通畅了到达了服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接。
1.4、如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
1.5、为什么建立连接是三次握手,关闭连接确是四次挥手呢?
建立连接的时候, 服务器在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。
而关闭连接时,服务器收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,而自己也未必全部数据都发送给对方了,所以己方可以立即关闭,也可以发送一些数据给对方后,再发送FIN报文给对方来表示同意现在关闭连接,因此,己方ACK和FIN一般都会分开发送,从而导致多了一次。
1.6、为什么客户端最后还要等待2MSL?
MSL(Maximum Segment Lifetime),TCP允许不同的实现可以设置不同的MSL值。
- 第一,保证客户端发送的最后一个ACK报文能够到达服务器,因为这个ACK报文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次,而客户端就能在这个2MSL时间段内收到这个重传的报文,接着给出回应报文,并且会重启2MSL计时器。
- 第二,防止类似与“三次握手”中提到了的“已经失效的连接请求报文段”出现在本连接中。客户端发送完最后一个确认报文后,在这个2MSL时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
1.7、报文段主要含义

- 序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生;给字节编上序号后,就给每一个报文段指派一个序号;序列号seq就是这个报文段中的第一个字节的数据编号。
- 确认号ack:占4个字节,期待收到对方下一个报文段的第一个数据字节的序号;序列号表示报文段携带数据的第一个字节的编号;而确认号指的是期望接收到下一个字节的编号;因此当前报文段最后一个字节的编号+1即为确认号。
- 确认ACK:占1位,仅当ACK=1时,确认号字段才有效。ACK=0时,确认号无效
- 同步SYN:连接建立时用于同步序号。当SYN=1,ACK=0时表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使得SYN=1,ACK=1。因此,SYN=1表示这是一个连接请求,或连接接受报文。SYN这个标志位只有在TCP建产连接时才会被置1,握手完成后SYN标志位被置0。
- 终止FIN:用来释放一个连接。FIN=1表示:此报文段的发送方的数据已经发送完毕,并要求释放运输连接
数据偏移:表示TCP报文段的首部长度,共4位,由于TCP首部包含一个长度可变的选项部分,需要指定这个TCP报文段到底有多长。它指出TCP 报文段的数据起始处距离 TCP报文段的起始处有多远。该字段的单位是32位(即4个字节为计算单位),4位二进制最大表示15,所以数据偏移也就是TCP首部最大60字节
URG:表示本报文段中发送的数据是否包含紧急数据。后面的紧急指针字段(urgent pointer)只有当URG=1时才有效
ACK:表示是否前面确认号字段是否有效。只有当ACK=1时,前面的确认号字段才有效。TCP规定,连接建立后,ACK必须为1,带ACK标志的TCP报文段称为确认报文段
PSH:提示接收端应用程序应该立即从TCP接收缓冲区中读走数据,为接收后续数据腾出空间。如果为1,则表示对方应当立即把数据提交给上层应用,而不是缓存起来,如果应用程序不将接收到的数据读走,就会一直停留在TCP接收缓冲区中
RST:如果收到一个RST=1的报文,说明与主机的连接出现了严重错误(如主机崩溃),必须释放连接,然后再重新建立连接。或者说明上次发送给主机的数据有问题,主机拒绝响应,带RST标志的TCP报文段称为复位报文段
SYN:在建立连接时使用,用来同步序号。当SYN=1,ACK=0时,表示这是一个请求建立连接的报文段;当SYN=1,ACK=1时,表示对方同意建立连接。SYN=1,说明这是一个请求
建立连接或同意建立连接的报文。只有在前两次握手中SYN才置为1,带SYN标志的TCP报文段称为同步报文段
FIN:表示通知对方本端要关闭连接了,标记数据是否发送完毕。如果FIN=1,即告诉对方:“我的数据已经发送完毕,你可以释放连接了”,带FIN标志的TCP报文段称为结束报文段
窗口大小:表示现在允许对方发送的数据量,也就是告诉对方,从本报文段的确认号开始允许对方发送的数据量,达到此值,需要ACK确认后才能再继续传送后面数据,由Window
size value * Window size scaling factor(此值在三次握手阶段TCP选项Window
scale协商得到)得出此值
校验和:提供额外的可靠性
紧急指针:标记紧急数据在数据字段中的位置
选项部分:其最大长度可根据TCP首部长度进行推算。TCP首部长度用4位表示,选项部分最长为:(2^4-1)*4-20=40字节
常见选项: 最大报文段长度:Maxium Segment Size,MSS,通常1460字节 窗口扩大:Window
Scale 时间戳: Timestamps
1 最大报文段长度MSS(Maximum Segment Size)
指明自己期望对方发送TCP报文段时那个数据字段的长度。比如:1460字节。数据字段的长度加上TCP首部的长度才等于整个TCP报文段的长度。MSS不宜设的太大也不宜设的太小。若选择太小,极端情况下,TCP报文段只含有1字节数据,在IP层传输的数据报的开销至少有40字节(包括TCP报文段的首部和IP数据报的首部)。这样,网络的利用率就不会超过1/41。若TCP报文段非常长,那么在IP层传输时就有可能要分解成多个短数据报片。在终点要把收到的各个短数据报片装配成原来的TCP报文段。当传输出错时还要进行重传,这些也都会使开销增大。因此MSS应尽可能大,只要在IP层传输时不需要再分片就行。在连接建立过程中,双方都把自己能够支持的MSS写入这一字段。
MSS只出现在SYN报文中。即:MSS出现在SYN=1的报文段中 MTU和MSS值的关系:MTU=MSS+IP
Header+TCP Header 通信双方最终的MSS值=较小MTU-IP Header-TCP Header
2 窗口扩大
为了扩大窗口,由于TCP首部的窗口大小字段长度是16位,所以其表示的最大数是65535。但是随着时延和带宽比较大的通信产生(如卫星通信),需要更大的窗口来满足性能和吞吐率,所以产生了这个窗口扩大选项
3 时间戳 可以用来计算RTT(往返时间),发送方发送TCP报文时,把当前的时间值放入时间
戳字段,接收方收到后发送确认报文时,把这个时间戳字段的值复制到确认报文中,当发送方收到确认报文后即可计算出RTT。也可以用来防止回绕序号PAWS,也可以说可以用来区分相同序列号的不同报文。因为序列号用32为表示,每2^32个序列号就会产生回绕,那么使用时间戳字段就很容易区分相同序列号的不同报文
PS: ACK、SYN和FIN这些大写的单词表示标志位,其值要么是1,要么是0;ack、seq小写的单词表示序号
1.8、TCP 协议如何保证可靠传输?
- 应用数据被分割成 TCP 认为最适合发送的数据块。
TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
校验和: TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。- TCP 的接收端会丢弃重复的数据。
- 流量控制: TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP
使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)- 拥塞控制: 当网络拥塞时,减少数据的发送。
- 停止等待协议 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。 超时重传: 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段
1.9、TCP与UDP的区别
UDP,在传送数据前不需要先建立连接,远地的主机在收到UDP报文后也不需要给出任何确认。虽然UDP不提供可靠交付,但是正是因为这样,省去和很多的开销,使得它的速度比较快,比如一些对实时性要求较高的服务,就常常使用的是UDP。对应的应用层的协议主要有 DNS,TFTP,DHCP,SNMP,NFS 等。
TCP,提供面向连接的服务,在传送数据之前必须先建立连接,数据传送完成后要释放连接。因此TCP是一种可靠的的运输服务,但是正因为这样,不可避免的增加了许多的开销,比如确认,流量控制等。对应的应用层的协议主要有 SMTP,TELNET,HTTP,FTP 等。
二、HTTPS和HTTP区别
基本概念:
超文本传输协议HTTP协议:被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
区别:
1、https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl/tls加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL/TLS+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
https如何实现可靠性:
对称加密+非对称加密+摘要算法+数字签名
对称加密: 对称加密(也叫私钥加密)指加密和解密使用相同密钥的加密算法。有时又叫传统密码算法,就是加密密钥能够从解密密钥中推算出来,同时解密密钥也可以从加密密钥中推算出来。而在大多数的对称算法中,加密密钥和解密密钥是相同的,所以也称这种加密算法为秘密密钥算法或单密钥算法。常见的对称加密有:DES(Data Encryption Standard)、AES(Advanced Encryption Standard)、RC4、IDEA
非对称加密: 与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey);并且加密密钥和解密密钥是成对出现的。非对称加密算法在加密和解密过程使用了不同的密钥,非对称加密也称为公钥加密,在密钥对中,其中一个密钥是对外公开的,所有人都可以获取到,称为公钥,其中一个密钥是不公开的称为私钥。非对称加密算法对加密内容的长度有限制,不能超过公钥长度。比如现在常用的公钥长度是 2048 位,意味着待加密内容不能超过 256 个字节。
摘要算法: 数字摘要是采用单项Hash函数将需要加密的明文“摘要”成一串固定长度(128位)的密文,这一串密文又称为数字指纹,它有固定的长度,而且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。“数字摘要“是https能确保数据完整性和防篡改的根本原因。
数字签名: 数字签名技术就是对“非对称密钥加解密”和“数字摘要“两项技术的应用,它将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性。
数字签名的过程如下:
明文 --> hash运算 --> 摘要 --> 私钥加密 --> 数字签名
数字签名有两种功效:
一、能确定消息确实是由发送方签名并发出来的,因为别人假冒不了发送方的签名。
二、数字签名能确定消息的完整性。
三、 SSL与TLS
SSL:(Secure Socket Layer,安全套接字层),位于可靠的面向连接的网络层协议和应用层协议之间的一种协议层。SSL通过互相认证、使用数字签名确保完整性、使用加密确保私密性,以实现客户端和服务器之间的安全通讯。该协议由两层组成:SSL记录协议和SSL握手协议。
TLS:(Transport Layer Security,传输层安全协议),用于两个应用程序之间提供保密性和数据完整性。该协议由两层组成:TLS记录协议和TLS握手协议。TLS是HTTP与TCP协议之间的一层,通常TLS发生在TCP三次握手之后,此时进行TLS四次握手,然后再进行HTTP通信
SSL/TLS协议的基本过程(TLS1.2):
客户端向服务器端索要并验证公钥。
双方协商生成"对话密钥"。
双方采用"对话密钥"进行加密通信。
HTTPS的主干层次介绍:
第一层:HTTPS本质上是为了实现加密通信,理论上,加密通信就是双方都持有一个对称加密的秘钥,然后就可以安全通信了
但是,无论这个最初的秘钥是由客户端传给服务端,还是服务端传给客户端,都是明文传输,中间人都可以知道。那就让这个过程变成密文就好了呗,而且还得是中间人解不开的密文。
第二层:使用非对称加密 加密客户端与服务端协商生成对称秘钥之前各种盐值、种子。
但是,在使用非对称加密秘钥之前,比如由服务端生成非对称秘钥,它需要将生成的公钥给到客户端,这个时候公钥就会在网络中明文传输,任何人都可以更改,会有中间人攻击的问题。因此,只能引入公信机构CA,使我们传输自己的公钥时可以保证不会被篡改!
第三层:服务端把自己的公钥给 CA,让 CA 用 CA 的私钥加密,然后返回加密结果(可以用CA的公钥解密,如果要篡改结果,必须再次用 CA 的私钥加密,由于中间人没法获取私钥,所以无法篡改)。
客户端在使用HTTPS方式与Web服务器通信时的步骤:

- 客户使用https的URL访问Web服务器,要求与Web服务器建立SSL连接。
- Web服务器收到客户端请求后,会将网站的证书信息(证书中包含公钥)传送一份给客户端。
- 客户端的浏览器与Web服务器开始协商SSL/TLS连接的安全等级,也就是信息加密的等级。
- 客户端的浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给网站。
- Web服务器利用自己的私钥解密出会话密钥。
- Web服务器利用会话密钥加密与客户端之间的通信。
四、缓存穿透、击穿、雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案:
设置热点数据永远不过期。
加互斥锁,互斥锁
https如何防止被恶意攻击
Https双向验证
服务器端对请求它的客户端要进行身份验证,客户端对自己所请求的服务器也会做身份验证。服务端一旦验证到请求自己的客户端为不可信任的,服务端就拒绝继续通信。客户端如果发现服务端为不可信任的,那么也中止通信
五、sychronized锁;
sychronized和lock锁的区别是什么?
1. 来源:
lock是一个接口,而synchronized是java的一个关键字,synchronized是内置的语言实现;
2.异常是否释放锁:
synchronized在发生异常时候会自动释放占有的锁,因此不会出现死锁;而lock发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生。(所以最好将同步代码块用try catch包起来,finally中写入unlock,避免死锁的发生。)
3.是否响应中断
lock等待锁过程中可以用interrupt来中断等待,而synchronized只能等待锁的释放,不能响应中断;
4.是否知道获取锁
Lock可以通过trylock来知道有没有获取锁,而synchronized不能;
Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
5.在性能上
如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
synchronized使用Object对象本身的wait 、notify、notifyAll调度机制,而Lock可以使用Condition进行线程之间的调度,
另一方面,Thread.currentThread()可以获取当前线程的引用,一般都是在没有线程对象又需要获得线程信息时通过Thread.currentThread()获取当前代码段所在线程的引用。
ReentreLock 锁和 sychronized 有什么区别?
- ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。
- ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
- ReenTrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。
JVM内存结构:
jvm内存结构
sychronized 原理是什么?
sychronized 原理
六、hashmap原理机制
HashMap和ConcurrentHashMap?讲一下红黑树
ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的synchronized锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。(JDK1.8之后ConcurrentHashMap启用了一种全新的方式实现,利用CAS算法。)
HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
普通的二叉查找树在极端情况下可退化成链表,此时的增删查效率都会比较低下。为了避免这种情况,就出现了一些自平衡的查找树,比如 AVL,红黑树等。这些自平衡的查找树通过定义一些性质,将任意节点的左右子树高度差控制在规定范围内,以达到平衡状态。以红黑树为例,红黑树通过如下的性质定义实现自平衡:
节点是红色或黑色。
根是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点(简称黑高)。
有了上面的几个性质作为限制,即可避免二叉查找树退化成单链表的情况。但是,仅仅避免这种情况还不够,这里还要考虑某个节点到其每个叶子节点路径长度的问题。如果某些路径长度过长,那么,在对这些路径上的及诶单进行增删查操作时,效率也会大大降低。这个时候性质4和性质5用途就凸显了,有了这两个性质作为约束,即可保证任意节点到其每个叶子节点路径最长不会超过最短路径的2倍。原因如下:
当某条路径最短时,这条路径必然都是由黑色节点构成。当某条路径长度最长时,这条路径必然是由红色和黑色节点相间构成(性质4限定了不能出现两个连续的红色节点)。而性质5又限定了从任一节点到其每个叶子节点的所有路径必须包含相同数量的黑色节点。此时,在路径最长的情况下,路径上红色节点数量 = 黑色节点数量。该路径长度为两倍黑色节点数量,也就是最短路径长度的2倍。
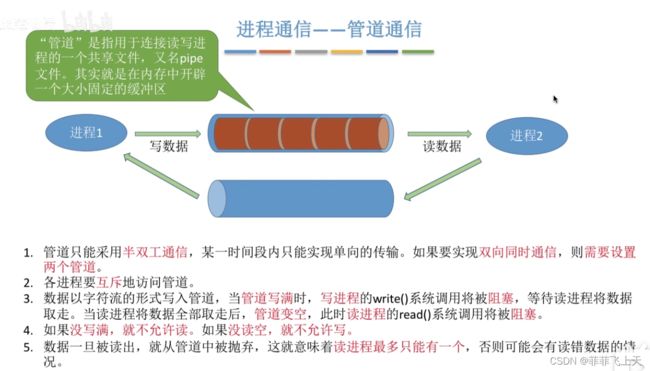
七、进程通信;


进程的五种基本状态
创建状态:进程在创建时需要申请一个空白PCB,向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态
就绪状态:进程已经准备好,已分配到所需资源,只要分配到CPU就能够立即运行
执行状态:进程处于就绪状态被调度后,进程进入执行状态
阻塞状态:正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用
终止状态:进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行
八、打开一个网页的具体过程( 问的很详细 )
(1)域名解析,其实就是根据用户输入的网址去寻找它对应的IP地址,比如输入 www.baidu.com的网址就会经历以下过程
先从浏览器缓存里找IP,因为浏览器会缓存DNS记录一段时间 如没找到,再从Hosts文件查找是否有该域名和对应IP
如没找到,再从路由器缓存找 如没好到,再从DNS缓存查找
如果都没找到,从根域名服务器开始递归搜索,到根、顶级域名服务器,再到自己的输入的域名服务器,直到找到IP
(2) 浏览器与服务器建立TCP连接(3次握手过程)
先是客户端发起请求过程:
使用应用层发起HTTP请求(这个可以根据你本身输入的url访问时,用的什么协议就发起对应协议去进行请求)
然后是传输层的TCP协议为传输报文提供可靠的字节流服务,这里也就使用了TCP三次握手
网络层是把TCP分割好的各种数据包传送给接收方。而要保证确实能传到接收方还需要接收方的MAC地址,也就是物理地址
然后才是链路层将数据发送到数据链路层传输。至此请求报文已发出,客户端发送请求的阶段结束
然后是服务端接受请求处理阶段:
原路进行处理:链路层—>网络层—>传输层—>应用层然后响应客户端发送报文。
(3) 浏览器向服务器发送HTTP 请求
HTTP的请求信息主要包含三部分内容:
请求方法URI协议/版本
请求头(Request Header)
请求正文(Request Body)
和HTTP请求一样,HTTP响应信息也主要包含三个部分:
状态行
响应头(Response Header)
响应正文(Response Body)
(4) 服务器收到请求,进行响应处理,将生成的html返回客户端;
(5)TCP连接释放
(6)客户端收到数据,浏览器对页面进行渲染,展示给用户;
浏览器根据HTML和CSS计算得到渲染树,绘制到屏幕上,js会被执行
九、PCB
PCB主要包含下面几部分的内容:
进程的描述信息,比如进程的名称,标识符,
处理机的状态信息,当程序中断是保留此时的信息,以便 CPU 返回时能从断点执行
进程调度信息,比如阻塞原因,状态,优先级等等
进程控制和资源占用,同步通信机制,链接指针(指向队列中下一个进程的 PCB 地址)
PCB 的作用:
PCB是进程实体的一部分,是操作系统中最重要的数据结构
由于它的存在,使得多道程序环境下,不能独立运行的程序成为一个能独立运行的基本单位,使得程序可以并发执行
系统通过 PCB 来感知进程的存在。(换句话说,PCB 是进程存在的唯一标识)
进程的组成可以用下图来表示,PCB 就是他唯一标识符。

十、redits的持久化机制
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
(1)RDB:是Redis DataBase缩写快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。
(2)AOF:持久化
AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。
当两种方式同时开启时,数据恢复Redis会优先选择AOF恢复。
Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化 (默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
十一、AQS原理
AQS 核心思想:,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
AQS 定义两种资源共享方式
Exclusive(独占):只有一个线程能执行,如 ReentrantLock。又可分为公平锁和非公平锁:
公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
Share(共享):多个线程可同时执行,如 CountDownLatch、Semaphore、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
非公平锁在调用 lock 后,首先就会调用 CAS 进行一次抢锁,如果这个时候恰巧锁没有被占用,那么直接就获取到锁返回了。
非公平锁在 CAS 失败后,和公平锁一样都会进入到 tryAcquire 方法,在 tryAcquire 方法中,如果发现锁这个时候被释放了(state == 0),非公平锁会直接 CAS 抢锁,但是公平锁会判断等待队列是否有线程处于等待状态,如果有则不去抢锁,乖乖排到后面。
十一、死锁、内存管理
参考:死锁,内存管理
十二、举一个线程不安全的例子?分析一下具体的原因
例子1:当有1000个线程同时执行i++操作时,i变量的副本拷贝到每个线程的线程栈,当同时有两个线程以上的线程读取线程变量,比如此时是5,那么同时执行i++操作,再写入到全局变量,最后,两个线程跑完了,这个i还是6,而并不会是7,所以,出现不安全性。(synchronized,volatile修饰)
例子2: HashMap是线程不安全的,其主要体现:
在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
在jdk1.8中,在多线程环境下,会发生数据覆盖的情况。
并发编程三要素(线程的安全性问题体现在):
原子性:原子,即一个不可再被分割的颗粒。原子性指的是一个或多个操作要么全部执行成功要么全部执行失败。
可见性:一个线程对共享变量的修改,另一个线程能够立刻看到。(synchronized,volatile)
有序性:程序执行的顺序按照代码的先后顺序执行。(处理器可能会对指令进行重排序)
出现线程安全问题的原因:
线程切换带来的原子性问题
缓存导致的可见性问题
编译优化带来的有序性问题
解决办法:
JDK Atomic开头的原子类、synchronized、LOCK,可以解决原子性问题
synchronized、volatile、LOCK,可以解决可见性问题
Happens-Before 规则可以解决有序性问题
十三、多线程
三个线程轮流打印 A B C
13.1、ConcurrentHashMap 的底层实现原理
ConcurrentHashMap
13.2、线程同步的方法有哪些?
线程同步方法
13.3、进程和线程的区别有哪些?
进程线程区别
十四、Hash 冲突,哈希冲突四种解决办法
哈希冲突
十五、项目中有没有接触过OOM?怎么解决的?
oom
十六、b树和b+树区别
树
十七、事务隔离级别
(Atomicity)原子性: 事务是最小的执行单位,不允许分割。原子性确保动作要么全部完成,要么完全不起作用;
(Consistency)一致性: 执行事务前后,数据保持一致;
(Isolation)隔离性: 并发访问数据库时,一个事务不被其他事务所干扰。
(Durability)持久性: 一个事务被提交之后。对数据库中数据的改变是持久的,即使数据库发生故障。
原子性
接着说说原子性。前文有提到 undo log ,回滚日志。隔离性的MVCC其实就是依靠它来实现的,原子性也是。 实现原子性的关键,是当事务回滚时能够撤销所有已经成功执行的sql语句。 当事务对数据库进行修改时,InnoDB会生成对应的 undo log;如果事务执行失败或调用了 rollback,导致事务需要回滚,便可以利用 undo log 中的信息将数据回滚到修改之前的样子。 undo log 属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB 会根据 undo log 的内容做与之前相反的工作:
对于每个 insert,回滚时会执行 delete;对于每个 delete,回滚时会执行insert;对于每个 update,回滚时会执行一个相反的 update,把数据改回去。
以update操作为例:当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态。
持久性
Innnodb有很多 log,持久性靠的是 redo log。
隔离性
binlog ,说到这,可能会疑问还有个 bin log 也是写操作并用于数据的恢复,有啥区别呢。 层次:redo log 是 innoDB 引擎特有的,server 层的叫 binlog(归档日志)内容:redolog 是物理日志,记录“在某个数据页上做了什么修改”;binlog 是逻辑日志,是语句的原始逻辑,如“给 ID=2 这一行的 c 字段加 1 ”写入:redolog 循环写且写入时机较多,binlog 追加且在事务提交时写入
一致性
一致性是事务追求的最终目标,前问所诉的原子性、持久性和隔离性,其实都是为了保证数据库状态的一致性。当然,上文都是数据库层面的保障,一致性的实现也需要应用层面进行保障。也就是你的业务,比如购买操作只扣除用户的余额,不减库存,肯定无法保证状态的一致。
十八、日志系统了解吗?redo log和undo log
redo log