concat与join
concat():连接两个DataFrame,两种方式行连接(axis=0)与列连接(axis=1)。
行连接:(axis=0)可以省略不写 df = pd.concat([df1, df2]) ,行连接保留df1,df2的所有行,列有重复则取交集,若有缺值,则为空如下例子:
import pandas as pd
df1 = pd.DataFrame({
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']}
)
df2 = pd.DataFrame({
'a': ['B4', 'B5', 'B6'],
'B': ['C4', 'C5', 'C6'],
'C': ['D4', 'D5', 'D6']}
)
# 使用concat函数连接这两个数据框
df = pd.concat([df1, df2])
print(df)
列连接:axis=1 df = pd.concat([df1, df2],asix=1),列连接保留所有的列,行取交集如下:
import pandas as pd
df1 = pd.DataFrame({
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']}
)
df2 = pd.DataFrame({
'a': ['B4', 'B5', 'B6'],
'B': ['C4', 'C5', 'C6'],
'C': ['D4', 'D5', 'D6']}
)
df = pd.concat([df1, df2],axis=1)
print(df)
join():两个表列方向的拼接操作,默认左连接
#'inner'表示只保留两个DataFrame都有的行或列,'outer'表示保留两个DataFrame中所有的行或列,'left'表示保留左边的DataFrame中所有的行或列,'right'表示保留右边的DataFrame中所有的行或列。
如果两个表中没有重复列名字,直接使用left.join(right),如下:
import pandas as pd
import numpy as np
#样集1
df1=pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
print(df1)
#样集2
df2=pd.DataFrame({'e':[15,6],'f':[1,11],'g':[0,6]})
print('\n',df2)
pf=df1.join(df2)
print('\n',pf)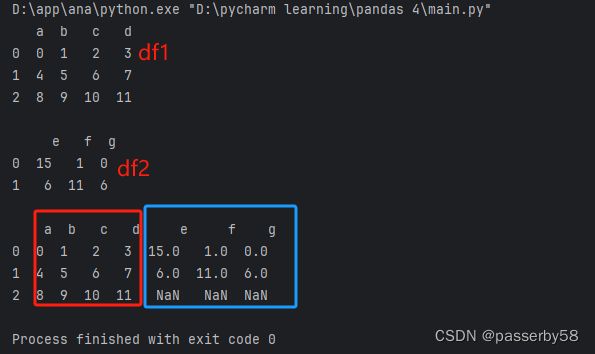
如果两个表中有重复列名字,需指定lsuffix, rsuffix参数,使用left.join(right,lsuffix='_l', rsuffix='_r'),如下:
import pandas as pd
import numpy as np
#样集1
df1=pd.DataFrame(np.arange(12).reshape(3,4),columns=['a','b','c','d'])
print(df1)
#样集2
df2=pd.DataFrame({'b':[15,6],'d':[1,11],'a':[0,6]})
print('\n',df2)
#用join合并表df1和表df2,需指定lsuffix, rsuffix参数,标识两个表的重复列名
pf=df1.join(df2, lsuffix='_l', rsuffix='_r')
print('\n',pf)