Redis 安装学习
1. Redis是什么
Redis遵循BSD协议,是使用ANSI C语言编写, 基于内存并支持持久化高性能的Key-Value的NoSQL数据库,起源LLOOGG记录日志,为解决负载问题
2、Reids支持何种数据结构类型
redis支持:
- 字符串string
- 散列hash
- 列表list
- 集合set
- 有序集合
3、Redis有何应用
- 缓存
- 数据库
- 消息中间件
类似的有Memcached(支持string类型value)
4、Redis具备的功能
- 持久化功能 内存中的数据保存到硬盘,保证数据安全
- 发布与订阅功能 消息转发
- 分布式事务 原子操作,乐观锁,保证数据处理的安全性
- 主从复制 Sentinel哨兵,故障转移
5、安装redis
-
解压安装包
>>tar -zvxf redis-6.2.6.tar.gz- 安装GCC
yum install gcc tcl -y - 编译
>>cd redis-6.2.6
>>make- 安装
#安装在/usr/local/redis
>>make PREFIX=/usr/local/redis install安装完成, 在/usr/local/redis/bin下生成以下文件
redis-benchmark
redis-check-rdb
redis-check-aof
redis-sentinel
redis-cli
redis-server- 设置环境变量将bin中内容加入到环境变量中
>>vim ~/.bash_profile
export REDIS_HOME=/usr/local/redis
export PATH=$PATH:$REDIS_HOME/bin
#保存修改
>>source ~/.bash_profile这时一些bin下的命令就可以直接使用如:
>>redis-server -v - 将redis注册为服务
在源码包utils下有脚本 install_server.sh
>>./install_server.sh CentOS 7 报错:
This systems seems to use systemd.
Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!
解决方法:注释掉install_server.sh 如下内容:
#bail if this system is managed by systemd
#_pid_1_exe="$(readlink -f /proc/1/exe)"
#if [ "${_pid_1_exe##*/}" = systemd ]
#then
# echo "This systems seems to use systemd."
# echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
# exit 1
#fi
#unset _pid_1_exe
- 执行,设置端口,log,data等配置
- 设置服务的名称
>> cd /etc/init.d/
mv redis_6379 redisd6、 启动redis
service redisd start - 启动
service redisd restart - 重启
连接redis
7、 Redis初识
7.1 Redis可存储的类型
- 字符串数据类型 string, msg 'h'|'e'|'l'|'l'|'o'|'w'
- number , 1003
- bits ,10010101 二进制
- 浮点数 3,14
7.2 Redis帮助及命令
#查看命令
>>help set
#查看string的函数
>>help @string 设置Key-Value
- 不存在,则设置
>>set msg "dfsdf" nx - 不存在,不允许设置
>>set msg "fsdf" xx - 设置过期时间为10秒
>>set msg "temp" ex 10 - 设置及获取多个Key-Value
>>mset key1 value1 key2 value2...
>>mget key1 key2 key3- 不存在则设置
该命令具有原子性, 如果至少有一个存在,则msetnx不执行任何操作
>>msetnx key1 value1 key2 value2 - 先取得旧值,再设置新值
>>getset key newval- 将value插入到字符串key已存储内容的末尾
>>append key value- 返回key对应的value的长度
>>strlen key - 返回所有key
>>keys *7.3 字符串处理
字符串的正向字符索引以0开始, 最后一个字符的索引为N-1
字符串还有负数索引,负数索引, 以-1开始,从字符串的结尾向字符串的开头依次递减,
如图所示: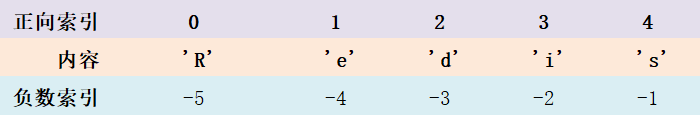
字符串基本操作
- 从字符串1下标开始设置替换
>>setrange msg 1 "newval"- 获取子串,若超过字符串实际长度,只返回到字符串末尾
如果开始的下标越界, 则返回空串 ""
>>getrange msg 1 3- 获取全部字符串
>>getrange msg 0 -1
7.4 数字处理
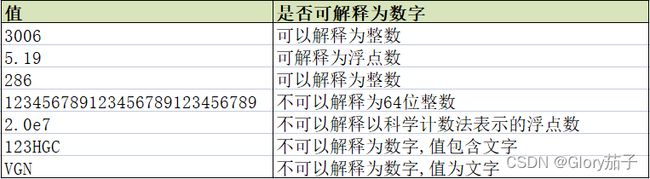
数字操作
- INCRBY
对于一个键是字符串的key,值是数字的, 可以使用INCRBY 命令增加值
value可以是正值,也可以是负值
>>INCRBY key value- INCR
只增加1, 如果不是整数,则报错不是个整数,或越界
>>INCR key - DECRBY
减少值, value可以是正值,也可以是负值
>>DECRBY key value- DECR
只减1
>>DECR key- INCRBYFLOAT
浮点数运算, 精度不好,小数位可能不是0, 如果减,可以传负数
>>INCRBYFLOAT key 5.68数字也可以使用append,strlen,setrange,getrange, redis会将数字值转为字符串,再执行命令
7.5 Redis的key
redis keys是二进制安全的, 可用任何二进制序列作为key, 空字符串也可以是有效的key值
key的取值原则
- 键值不需要太长,消耗内存, 且在数据中查找这类键值得计算成本高
- 键值不宜过短,可读性较差
- 一个字符串类型的值,最多能存512M字节的内容
- 设置key的过期时间
>>expire key seconds- 删除过期
>>persist key - key剩余存活时间
>>TTL key- key存在,但没有设置TTL, 返回-1
- key,存在,设置了TTL, 返回秒
- key曾经存在,但已经消亡返回-2
- TYPE key 所对应类型
- 是否存在
>>exist key- 重命名key
>>rename key newKey
7.6 位图
- 设置某一位上的值
# offset 偏移量 从0开始
>>SETBIT key offset value
- 获取某一位上的值
>>GETBIT key offset- 返回指定值0或1在指定区间上第一次出现的位置
BITPOS key bit [start] [end]
- 位操作, operation可以是AND,OR,NOT,XOR,这四种操作中的任意一种
# 对一个或者多个key求逻辑并,并将结果保存到 destkey
BITOP AND destkey key[key...]# 对一个或者多个key求逻辑或,并将结果保存到 desteky
BITOP OR destkey key[key...]# 对一个或者多个key求逻辑异或,并将结果保存到 destkey中
BITOP XOR destkey key[key...]# 对给定的key求逻辑非,并将结果保存到 destkey
BITOP NOT destkey key# 统计指定位区间上值1的个数
# 从左向右从0开始,从右向左从-1开始,注意官方start end是位, 测试后是字节
BITCOUNT key [start] [end]
e.g: BITCOUNT myKey 0 0 (开始-结束)
# 表示从索引为0个字节到索引为0个字节,就是第一个字节的统计
BITCOUNT mykey 0 -1,等同于BITCOUNT testkey
# 最常用的就是BITCOUNT mykey实例1:网站用户上线次数统计
用户ID为key,天作为offset,上线置为1
ID为500的用户,今年第1天上线,第30天上线
SETBIT U500 1 1
SETBIT U500 30 1
BITCOUNT U500 实例2:如果是按照天统计网站活跃用户
天作为key,用户ID为offset,上线置为1, 求一段时间内活跃用户数
SETBIT 20160602 15 1
SETBIT 20160601 123 1
SETBIT 20160606 123 1
求6月1日到6月10日的活跃用户
(只要时间区间内上线过,可以认为是活跃用户,可以用OR)
BITOP OR 20160601-10 20160601 20160602 20160606
BITCOUNT 20160601-10
结果为 27.7 库操作
- 登录不同库
redis-cli -n 2- 清除当前库数据
FLUSHDB- 清除所有库中的数据
FLUSHALL7.8 列表
- 基于LinkedList实现
- 元素是字符串类型
- 列表头尾增删快,中间增删慢,增删元素是常态
- 元素可以重复重现
- 最多包含2^32 - 1 元素
- 列表的索引从左至右从0开始,从右至左从-1开始
列表命令注意点:
- B 开头 block块,阻塞命令
- L left 左
- R right 右
- X exist 存在
- 左右或者头尾压入元素
LPUSH key value[value...]
LPUSHX key value , key不存在时失效
RPUSH key value[value...]
RPUSHX key value , key不存在时失效- 左右或者头尾弹出元素
LPOP key
RPOP key- 从一个列表尾部弹出元素, 压入另一个列表头部
RPOPLPUSH source destination- 返回列表中指定范围元素
LRANGE key start stop
LRANGE key 0 -1 返回所有元素- 获取指定位置的元素
LINDEX key index- 设置指定位置元素的值
LSET key index value- 列表长度,元素个数
LLEN key- 从列表头部开始删除值等于value的元素count次
LREM key count value
(1) count > 0 从表头向表尾搜索
移除于value相等的元素,数量为count
(2) count < 0 从表尾开始向表头搜索
移除于value相等的元素,数量为count的绝对值
(3) count =0 移除表中所有与value相等的值- 截取
ltrim key start stop - 在列表中某个存在的值(pivot)前或后插入元素
LINSERT key BEFORE|AFTER pivot value
key和pivot不存在,不进行任何操作- 阻塞操作
(1)如果弹出的列表不存在或者为空就会阻塞
(2)超时时间设置为0,就是永久阻塞,直到有数据可以弹出
(3)如果多个客户端阻塞在同一个列表上, 使用First In First Server 先到先服务原则
- 左右或者头尾阻塞弹出元素
BLPOP key[key...] timeout
BRPOP key[key...] timeout - 从一个列表尾部阻塞弹出元素压入到另一个列表的头部
BRPOPLPUSH source destination timeout 7.9 哈希散列
- 由field和关联的value组成的map键值对
- field和value是字符串类型
- 一个hash中最多包含2^32 - 1键值对
| person: | field | value |
|---|---|---|
| _ | id | u2022500 |
| _ | name | Tom |
| _ | age | 25 |
| _ | address | 深圳宝安 |
| _ | gender | 男 |
:
- 设置单个字段
HSET key field value
key的field不存在的情况下执行, key不存在直接创建
HSETNX key field value
- 设置多个字段
HMSET key field value[field value...]- 返回字段个数
HLEN key- 判断字段是否存在
HEXISTS key field
key或者field不存在,返回0- 返回字段值
HGET key field
返回多个字段值
HMGET key filed[field...]- 返回所有键值对
HGETALL key - 返回所有字段名
HKEYS key - 返回所有值
HVALS key - 在字段对应的值是哪个进行整数的增量计算
HINCRBY key field increment- 在字段对应的值上进行浮点数的增量计算
HINCRBYFLOAT key field increment- 删除指定的字段
HDEL key field[field...]- 举例:
HINCRBY mynum val 600
HINCRBY mynum val -86
HINCRBYFLOAT mynum val 3.56
HDEL mynum val - hash的用途
(1)节约内存空间
(2)每创建一个键,他都会为这个键存储
(3)一些附件的管理信息(如键类型,键最后一次被访问的时间等等), 所以数据库里面的键越
多,redis数据库服务器在存储附加管理信息方面,耗费的内存就越多花在管理数据库键上的CPU
也会越多- 不适合hash的情况
1、使用二进制位操作的命令
因为Redis目前支持对字符串键进行SETBIT,GETBIT,BITOP等操作
如果你想使用这些操作,那么只能使用字符串键, 虽然散列也能保存二进制数据
2、使用过期键功能
Redis的键过期功能目前只能对键进行过期操作
而不能对散列的字段进行过期操作, 因此如果你要对键值对数据使用过期功能的话
那么只能把键值对存储在字符串里面8.0集合
Redis 集合
- set集合
- 无序的,去重的
- 元素是字符串类型
- 最多包含2^32 -1 个元素
集合操作
- 增加一个或多个元素,如果元素已经存在,则自动忽略
SADD key member[member...]- 移除一个或者多个元素,元素不存在,自动忽略
SREM key member[member...]- 返回集合中所有元素
SMEMBERS key- 检查给定元素是否存在于集合中
SISMEMBER key member- 随机返回集合中指定个数的元素
SRANDMEMBER key [count]
(1)count > 0 ,且小于集合基数,那么命令返回一个
包含count个元素的数组
数组中的元素各不相同
(2)如果count大于等于集合基数
那么返回整个集合
(3)count<0,命令返回一个数组
数组中的元素可能会重复多次
而数组的长度为count的绝对值
(4)如果count为0,返回空
(5)count不写则默认返回一个- 返回集合中元素个数
SCARD key- 随机从集合中移除并返回这个被移除的元素
SPOP key- 把元素从源集合移动到目标集合
SMOVE source dest memberSet的集合操作
- 差集
SDIFF key[key...]
从第一个key的集合中去除其他集合和自己交集的部分
SDIFFSTORE destination key[key...]
将差集结果存储在目标key中
SADD aset 1 2 3 4 5
SADD bset 2 3 5 6
SDIFF aset bset : 1 4- 交集
SINTER key[key...] 取所有集合交集部分
SINTERSTORE destination key[key...]
将交集结果存储在目标key中
SINTER aset bset : 2 3 5- 并集
SUNION key[key...]取所有集合并集
SUNIONSTORE destination key[key...]
将并集结果存储在目标key中
SUNION aset bset : 1 2 3 4 5 6有序集合
- 有序的、去重的
- 元素是字符串类型
- 每一个元素都关联着一个浮点数分值score
- 顺序排列集合中的元素,分值可以相同
- 最多包含2^32 - 1 元素
有序集合操作
- 增加
ZADD key score member[score member...]
如果元素已经存在,则使用新的score
举例:
ZADD animals 3.1 大象
ZADD animals 2.5 猴子
ZADD animals 2.6 狮子 2.8猎豹- 移除一个或者多个元素,元素不存在,自动忽略
ZREM key member[member...]- 显示分值
zscore key member- 增加或者减少分值,increment为负数就是减少
ZINCRBY key increment member - 返回元素的排名(索引)
0开始
ZRANK key member
例:zrank animals sheep- 返回元素的逆序排名
即score最大的排第一个
ZREVRANK key member- 返回指定索引区间元素
ZRANGE key start stop[WITHSCORES]
如果score相同,则按照字典序排列
默认按照score从小到大| 正数索引 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 负数索引 | -5 | -4 | -3 | -2 | -1 |
| score | 2.0 | 3.0 | 4.0 | 5.0 | 6.0 |
| 元素 | e1 | e2 | e3 | e4 | e5 |
- 返回指定分值区间元素
ZRANGEBYSCORE Key min max [WITHSCORES][LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score升序排列
score相同字典序
LIMIT 中offset代表跳过多少元素,count是返回几个,类似于Mysql
使用小括号,修改区间为开区间
例如(5 10, (10 5)
-inf和+inf表示负无穷和正无穷
ZRANGEBYSCORE animals 2.0 5.0
ZRANGEBYSCORE animals(4 7
ZRANGEBYSCORE animals -inf +inf
- 降序返回指定分值区间元素
ZREVRANGEBYSCORE Key min max [WITHSCORES][LIMIT offset count]
返回score默认属于[min,max]之间,元素按照score降序排列
score相同字典降序
LIMIT 中offset代表跳过多少元素,count是返回几个,类似于Mysql
使用小括号,修改区间为开区间
例如(5 10、 (10、 5)
-inf和+inf表示负无穷和正无穷
ZREVRANGEBYSCORE animals 5.0 2.0
ZREVRANGEBYSCORE animals 7 (4
ZREVRANGEBYSCORE animals +inf -inf - 移除指定排名范围的元素
ZREMRANGEBYSCORE key min max
返回指定范围内元素的个数
ZCOUNT key min max
ZCOUNT animals 4 10
ZCOUNT animals (4 10 - 有序集合并集
ZUNIONSTORE destination numkeys key[key...][WEIGHTS weight]
[AGGREGATE SUM|MIN|MAX ]
numkeys指定key的数量必须
WEIGHT选项,与前面设定的key对应,对应key中每一个score都要
乘以这个权重
AGGREGATE选项,指定并集结果的聚合方式
SUM :将所有集合中某一元素的score值之和作为结果集中该
成员的score值
MIN:将所有集合中某一元素的score值中最小值作为结果集中
该成员的score值
MAX:将所有集合中某一元素的score值中最大值作为结果集中
该成员的score值
示例:
zadd myz1 2.0 a 3.0 b 4.0 c 5.0 d
zadd myz2 2.0 a 3.0 b 4.0 c1 5.0 d1
zunionstore result 2 myz1 myz2
返回值为6
zrange result 0 -1 withscores| Key | 元素 | score |
|---|---|---|
| result | "a" | "4" |
| ... | "c" | "4" |
| ... | "c1" | "4" |
| ... | "d" | "5" |
| ... | "d1" | "5" |
| ... | "b" | "6" |
默认权重为1,取交集后score相加作为新的score
指定权重
zunionstore result1 2 myz1 myz2 weights 1 0.5 aggregate sum
zrange result1 0 -1 withscores- 有序集合交集
ZINTERSTORE destination numkeys key[key...] WEIGHT2 weight
AGGREGATE SUM|MIN|MAX
numkeys指定key的数量,必须
WEIGHTS选项与前面设定的key对应,对应key中每一个score都要乘以这个权重
AGGREGATE选项,指定交集结果的聚合方式
SUM:将所有集合中某一个元素的score值之和作为结果集中该成员的score值
MIN:将所有集合中某一元素的score值中最小值作为结果集中该成员的score值
MAX:将所有集合中某一元素的score值中最大值作为结果集中该成员的score值
示例:
zinterstore result2 2 myz1 myz2 WEIGHTS 1 0.5 aggregate sum
返回值为2
zrange result2 0 -1 withscores
"a" "3"
"b" "4.5"
示例:音乐排行榜
按照天进行打分,进而统计周,月排名
微博翻页
使用时间戳作为score
ZADD blog 1407000000 '微博内容'
ZREVRANGE blog 0 10
商品条目过滤
不同筛选条件的set取交集8.1 Redis持久化
将数据从掉电易失的内存存放到能够持久存储的设备上
Reids为什么需要持久化
- 基于内存的
- 缓存穿透
如果缓存服务器挂了后端数据库一瞬间压力过大
Redis持久化方式
- RDB(Redis DB) 对应配置项为 dbfilename dump.rdb
1、RDB持久化功能可以将服务器包含的所有数据库
数据以二进制文件的形式保存到硬盘里面
2、通过服务器启动时载入RDB文件,服务器可以根据RDB
文件的内容,还原服务器原有的数据库数据- AOF(AppendOnlyFile)默认不开启
appendonly no
appendfilename appendonly.aof 创建RDB文件
1、服务器执行客户端发送的save命令
执行save命令的过程中,redis服务器将被阻塞,无法处理客户端发送的命令请求
只有在save执行完毕,服务器才会重新开始处理客户端发送的命令请求
如果RDB文件已经存在,那么服务器将自动使用新的RDB文件去替代旧的RDB文件
2、服务器执行客户端发送的BGSAVE命令
执行BGSAVE同样可以创建一个新的RDB文件
这个命令和save的区别是,BGSAVE不会造成redis服务器阻塞,在执行BGSAVE过程中redis服务器仍然可以
正常的处理其他客户端发送的命令请求
BGSAVE不会造成服务器阻塞的原因:
当redis服务器接收到BGSAVE命令的时候,他不会自己来创建RDB文件,而是通过fork()来生成一个子进程
然后由子进程来负责创建RDB文件,而自己继续处理客户端的命令请求
当子进程创建好RDB文件并退出时,他会向父进程(也即是负责处理命令请求的redis服务器)
发送一个信号,告知他RDB文件已经创建完毕,最后redis服务器(父进程)接手子进程创建的
RDB文件BGSAVE执行完毕
客户端 -> BGSAVE ->Redis服务器 ->fork ->子进程 ->创建RDB文件
默认dump.rdb会写到/var/lib/redis/6379下
3、使用save配置项配置的自动保存条件被满足,服务器自动执行BGSAVE
save 300 10
距离上一次创建RDB文件已经过去300秒,并且服务器的所有数据库总共发生了不少于
10次的修改,那么执行BGSAVE命令
用户还可以通过设置多个save选项来设置多个自动保存条件,当任意一个条件被满足时
服务器就会自动执行BGSAVE使用RDB持久化的缺点
创建RDB需要将所有数据库的数据都保存起来,这是一个非常耗费资源和时间的操作
所以服务器需要隔一段时间才创建一个新的RDB文件,也就是说创建RDB文件的操作不能
执行得过于频繁否则就会严重影响服务器性能
- AOF持久化
AOF持久化保存数据的方法是:每当有修改数据库的命令被执行时,服务器就会将执行的命令写入到
AOF文件的末尾
因为AOF文件里面存储了服务器执行的所有数据库修改的命令,所以给定一个AOF文件,服务器只要重新执行一遍AOF文件里面包含的所有命令,就可以达到还原数据库的目的
示例:
AOF文件
...
SET mykey "mycontent"
INCR mynum
SADD myset "s1"AOF 安全性问题
系统调用write函数,会先将内容,写到内存缓冲区buffer里面, 等到缓冲区被填满或者用户执行
fsync调用和fdatasync调用时才会将存储在缓冲区里的内容真正的写入到硬盘里
为控制redis服务器在遇到意外停机丢失数据, redis为AOF持久化提供了appendfsync选项值:
always,everysec或者no
always
服务器每写入一个命令就调用一次fdatasync将缓冲区里面的命令写入到磁盘
everysec
服务器每一秒重调用一个fdatasync,将缓冲区里的命令写入到磁盘最多丢失一秒钟内执行的命令
no
服务器不主动调用fdatasync,由操作系统决定任何将缓冲区里面的命令写入到磁盘里
服务宕机,丢失的命令数不定
运行速度:
always速度慢、
everysec和no都很快
默认值为 appendfsync everysec解决AOF文件过大
redis提供了AOF重写功能,产生一个新的AOF文件,比原AOF文件体积小的多,AOF重写期间,服务器不会被阻塞, 可以正常处理客户端发送的命令请求
如何触发AOF重写
1、客户端向服务器发送BGREWRITEAOF命令
aof文件默认放置于 /var/lib/redis/6379下
2、配置auto-aof-rewrite-min-size size(默认为64M)
AOF文件体积大于等于size,才会重写8.2 Redis集群
Redis主从
- 一个Redis服务可以有多个该服务的复制,这个redis服务成为Master,其他复制品成为Slaves
- 只要网络连接正常,Master会一直将自己的,数据更新同步给Slave,保持主从同步
- 只有Master可以执行写命令,slave只能执行读命令,降低Master的读压力
启动设置为slave
1、启动时设置slave的master
redis-server --port 6389 --slaveof 127.0.0.1 6379
redis-cli -p 6389 -n 0
slave如果执行写命令报错:
(error)READONLY You can't write against a read only replica
2、启动服务后指定其master
redis-server -p 6389
slaveof 127.0.0.7 6379
3、变为master
slaveof no one
4、配置方式设为slave
slaveof masterip masterport
例如: slaveof 127.0.0.1 6379
port 6380高可用Sentinel
以上设置slave都是手动的,需要实现自动需要sentinel哨兵,实现故障转移
官方提供的高可用方案,可以用它管理多个Redis服务实例,编译后产生redis-sentinel程序文件
redis sentinel是一个分布式系统,可以在一个架构中运行多个sentinel进程
启动Sentinel
- 将src目录下产生的redis-sentinel程序文件,复制到$REDIS_HOME/bin
- 启动一个运行在Sentinel模式下的redis服务实例 redis-sentinel 或redis-server /path/to/sentinel.conf -- sentinel
- Sentinel会不断检查master和slave是否正常,每一个sentinel可以监控任意多个master和该master下的slaves
Sentinel网络
监控同一个master的sentinel会自动连接 ,组成一个分布式的sentinel网络,互相通信并交换彼此关于被监控服务器的信息
Sentinel配置文件
sentinel monitor mymaster 127.0.0.1 6379 2
主服务判断为下线失效至少需要2个sentinel同意,如果多数sentinel同意才会执行故障转移
sentinel会根据master的配置自动发现master的slaves,sentinel默认端口号为26379sentinel配置举例
执行命令,创建两个监视主服务器的sentinel实例
redis-sentinel sentinel1.conf
redis-sentinel sentinel2.conf
其中sentinel1.conf的内容为:
port 26379
sentinel monitor s1 127.0.0.1 6379 2
sentinel2.conf的内容为:
port 26380
sentinel monitor s1 127.0.0.1 6379 2 主从+哨兵的优缺点
- 优点: 能解决大部分的场景
- 缺点:只有主可写,写压力都在主节点上
Redis集群
- 支持度:3.0支持
- 由多个Redis服务器组成的分布式网络服务集群
- 每一个Redis服务成为节点Node,节点间相互通信,两两相连
- Redis集群无中心节点
集群示例
Reis001 —— Redis002
| |
Redis 003问题
Redis服务器过多时, 服务器多台间的网络IO比较多
Redis集群的每个节点角色
- 主节点master node
- 从节点slave node
- 其中主节点用于存储数据,而从节点则是某个主节点的复制品
当用户需要处理更多读请求时,添加从节点
可以扩展系统的读性能,因为Redis集群
重用了单机Redis复制特性的代码
所以集群的复制行为和单机复制特性的行为
是完全一样的Redis集群自带哨兵机制
如果主挂掉,则自动将slave提升为主
Redis集群的分片
Redis集群将整个数据库分为16384个槽位slot
所有key都属于这些slot中的一个,key的槽位计算公式为slot number = crc16(key)%16384
crc16为16位的循环冗余校验和函数
集群中的每个主节点都可以处理0个至16384个槽,
当16384个槽都有某个节点在负责处理时,集群进入上线状态
并开始处理客户端发送的命令请求
示例:
三个主节点:001,002,003平均分片16384个slot槽位
节点001指派的槽位为0-5460
节点002指派的槽位为5461-10922
节点003指派的槽位为10923到16383Redis集群Redirect转向
由于Redis集群无中心节点,请求会发给任意主节点
主节点只会处理自己负责槽位的命令请求,其他槽位的命令请求,该主节点会返回客户端
一个转向错误
客户端根据错误中包含的地址和端口,重新转向正确的负责的主节点发起命令请求
示例:
客户端 ----> SET mykey "mycontent" -> 001
001 --> 客户端 moved 6257 127.0.0.1 002
客户端-->SET mykey "mycontent" -> 002Redis集群搭建
- 创建多个主节点,为每一个节点指派slot,将多个节点连接起来,组成一个集群
- 槽位分片完成后,集群进入上线状态
- 2n个节点, n个主节点,每一个主节点都有一个从节点
配置文件
redis.conf
cluster-enabled yes
port 7000[7001...]启动
配置了多少个节点7000[...]就启动多少个
redis-server redis.conf创建集群
槽位分配通过redis-trib这个ruby脚本来分配
安装rubygem
yum install ruby rubygems -y
gem install redis 分片
进入redis src目录下执行命令
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 ...
1代表一个副本,也就是说端口为7000的有一个从节点,往后依次类推连接
redis-cli -p 7002 -c
-c参数指的是连接cluster问题
如果一台主+副都宕机的话, 整个集群是宕掉的,无法提供服务
因为该(主+副)对应的槽没有了
结语
Redis基本内容,后续补充