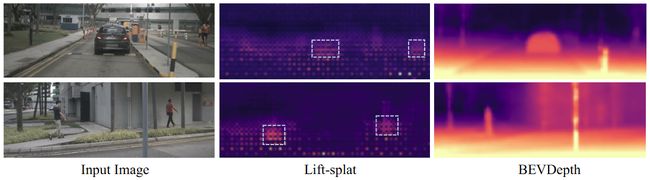
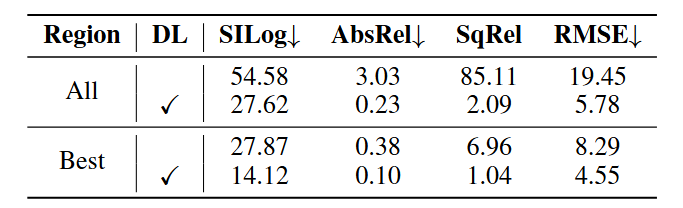
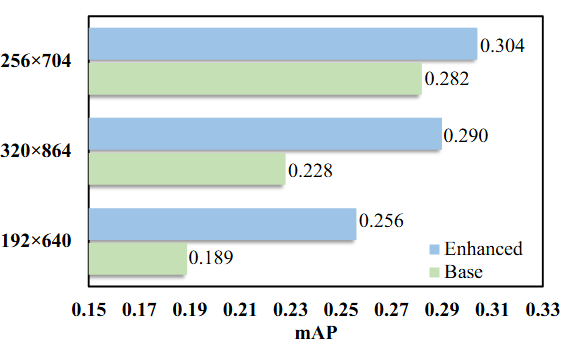
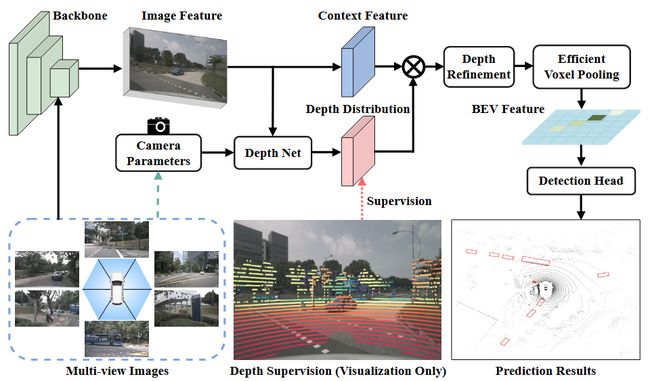
- 论文阅读:2025 arxiv Qwen3 Technical Report
https://arxiv.org/pdf/2505.09388https://www.doubao.com/chat/9918384373236738文章目录论文翻译Qwen3技术报告摘要1引言论文翻译Qwen3技术报告Qwen团队摘要在这项工作中,我们介绍了Qwen模型家族的最新版本Qwen3。Qwen3包含一系列大型语言模型(LLM),旨在提升性能、效率和多语言能力。Qwen3系列包括密集型
- [论文阅读] 软件工程 | 探索软件生态系统中的开发者体验关键因素
探索软件生态系统中的开发者体验关键因素:从研究到实践引文格式@article{Zacarias2025,title={ExploringDeveloperExperienceFactorsinSoftwareEcosystems},author={Zacarias,RodrigoOliveiraandAntunes,L{\'e}oCarvalhoRamosandBarros,M{\'a}rciod
- Fast Image Deconvolution using Hyper-Laplacian Priors论文阅读
青铜锁00
#退化论文阅读论文阅读图像处理
FastImageDeconvolutionusingHyper-LaplacianPriors1.论文的研究目标与实际意义2.论文的创新方法2.1核心框架:交替最小化(AlternatingMinimization)2.2x子问题:频域FFT加速2.3w子问题:高效求解的核心创新2.3.1问题形式2.3.2查找表法(LUT)2.3.3解析解法(特定α\alphaα)2.3.4通用α\alphaα
- [论文阅读] 人工智能 + 软件工程 | AI 与敏捷开发的破局之路:从挫败到成功的工作坊纪实
张较瘦_
前沿技术论文阅读人工智能软件工程
AI与敏捷开发的破局之路:从挫败到成功的工作坊纪实论文信息arXiv:2506.20159AIandAgileSoftwareDevelopment:FromFrustrationtoSuccess–XP2025WorkshopSummaryTomasHerda,VictoriaPichler,ZheyingZhang,PekkaAbrahamsson,GeirK.HanssenSubjects:
- Diff-Retinex: Rethinking Low-light Image Enhancement with A Generative Diffusion Model 论文阅读
钟屿
论文阅读人工智能深度学习学习图像处理计算机视觉
Diff-Retinex:用生成式扩散模型重新思考低光照图像增强摘要本文中,我们重新思考了低光照图像增强任务,并提出了一种物理可解释的生成式扩散模型,称为Diff-Retinex。我们的目标是整合物理模型和生成网络的优点。此外,我们希望通过生成网络补充甚至推断低光照图像中缺失的信息。因此,Diff-Retinex将低光照图像增强问题表述为Retinex分解和条件图像生成。在Retinex分解中,我
- 【论文阅读】人工智能在直升机航空电子系统中的应用
肥鼠路易
论文阅读人工智能航空电子系统应用
人工智能在直升机航空电子系统中的应用论文摘要文章结构参考文献论文摘要论文摘要:在现代战争形势日趋信息化、智能化的背景下,将人工智能应用于武器装备已经是大势所趋。针对直升机飞行任务的特征,对其发展状况进行了描述,并对其作业能力进行了分析,探索了人工智能技术在直升机航电系统中的应用方向,为推进人工智能在直升机上的转化与应用奠定基础。通过对国外先进直升机智能技术的运用现状及对其作业能力的要求进行分析,探
- [论文阅读] 人工智能+软件工程 | 用大语言模型架起软件需求形式化的桥梁
张较瘦_
前沿技术人工智能论文阅读软件工程
用大语言模型架起软件需求形式化的桥梁:一篇ACM调查草案的深度解读论文信息arXiv:2506.14627ACMSurveyDraftonFormalisingSoftwareRequirementswithLargeLanguageModelsArshadBeg,DiarmuidO’Donoghue,RosemaryMonahanComments:22pages.6summarytablesSu
- Reti-Diff: Illumination Degradation Image Restoration with Retinex-based Latent Diffusion Model论文阅读
青铜锁00
深度学习论文阅读#退化论文阅读
Reti-Diff:IlluminationDegradationImageRestorationwithRetinex-basedLatentDiffusionModel1.研究目标与实际意义1.1研究目标1.2实际意义2.创新方法与模型设计2.1整体框架2.2RetinexPriorExtraction(RPE)模块2.2.1Retinex分解2.2.2先验压缩2.3Retinex-guide
- SIMPL论文阅读
ZHANG8023ZHEN
论文阅读
论文链接:https://arxiv.org/pdf/2402.02519文章还没细看,但主要贡献点应该是SymmetricFusionTransformer和Bezier-basedMotionDecoder.对Bezier-basedMotionDecoder比较感兴趣,之后对这块细看一下
- 【论文阅读笔记】《CodeS: Towards Building Open-source Language Models for Text-to-SQL 》
柠石榴
text2sql论文论文阅读笔记语言模型
文章目录一、论文基本信息1.文章标题2.所属刊物/会议3.发表年份4.作者列表5.发表单位二、摘要三、解决问题四、创新点五、自己的见解和感想六、研究背景七、研究方法模型实验数据评估指标八、总结九、相关重要文献一、论文基本信息1.文章标题CodeS:TowardsBuildingOpen-sourceLanguageModelsforText-to-SQL2.所属刊物/会议未明确标注(会议缩写为“C
- agentformer论文阅读
ZHANG8023ZHEN
论文阅读
参考了这篇博文:https://zhuanlan.zhihu.com/p/512764984主要有这几个部分a.map_encoderi.对地图进行CNNb.ContextEncoderi.timeencoder–将时间信息用transformer和positionemb进行融合,加入到特征中ii.agent-awareattention–self和selfattentionother和other
- 【论文阅读】DynamicControl :一种新的controlnet多条件控制方法
prinTao
pytorchDiffusion论文阅读
背景现有方法要么处理条件效率低下,要么使用固定数量的条件,这并不能完全解决多个条件的复杂性及其潜在冲突。这强调了需要创新方法来有效管理多种条件,以实现更可靠和详细的图像合成。为了解决这个问题,我们提出了一个新的框架DynamicControl,它支持不同控制信号的动态组合,允许自适应选择不同数量和类型的条件。本文方法从一个双循环控制器开始,它通过利用预先训练的条件生成模型和判别模型为所有输入条件生
- 论文阅读:2018 arxiv CrowdHuman: A Benchmark for Detecting Human in a Crowd
CSPhD-winston-杨帆
论文阅读
https://www.doubao.com/chat/9226473480559618https://arxiv.org/pdf/1805.00123CrowdHuman:ABenchmarkforDetectingHumaninaCrowd文章目录论文翻译CrowdHuman:用于检测人群中人体的基准摘要1.引言2.相关工作2.1.人体检测数据集2.2.人体检测框架。论文翻译CrowdHuma
- 论文阅读:arxiv 2025 OThink-R1: Intrinsic Fast/Slow Thinking Mode Switching for Over-Reasoning Mitigation
CSPhD-winston-杨帆
论文阅读
总目录大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328https://www.doubao.com/chat/8815924393371650https://arxiv.org/pdf/2506.02397#page=17.09OThink文章目录速览研究背景与问题核心思路与方法实验结果结论与意义速览这篇论文聚焦于
- 论文阅读:arxiv 2025 Not All Tokens Are What You Need In Thinking
总目录大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328https://arxiv.org/pdf/2505.17827https://www.doubao.com/chat/8814790364572162文章目录速览研究背景提出的解决方案:条件token选择(CTS)实验结果核心贡献研究局限总结速览这篇论文主要探
- [论文阅读]PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers
颜笑晏晏
论文阅读
1.摘要双分支网络结构已显示出其对实时语义分割任务的效率性和有效性。然而,低级细节和高级语义的直接融合将导致细节特征容易被周围上下文信息淹没,即本文中的超调(overshoot),这限制了现有两个分支模型的准确性的提高。在本文中,我们在卷积神经网络(CNN)和比例积分微分(PID)控制器之间架起了桥梁,并揭示了双分支网络只是一个比例积分(PI)控制器,当然也会存在类似的超调问题。为了解决这个问题,
- [论文阅读] 人工智能+软件工程 | 用 LLM + 静态代码分析自动化提升代码质量
张较瘦_
前沿技术论文阅读人工智能软件工程
用LLM+静态代码分析自动化提升代码质量论文信息AugmentingLargeLanguageModelswithStaticCodeAnalysisforAutomatedCodeQualityImprovements@article{abtahi2025augmenting,title={AugmentingLargeLanguageModelswithStaticCodeAnalysisfo
- 经典论文阅读《A Framework for Unifying Reordering Transformations》《统一重排序变换的框架》
好好学习啊天天向上
自动性能优化
1)摘要我们提出了一个用于统一迭代重排序变换的框架,这些变换包括循环交换、循环分布、倾斜、分块、索引集拆分和语句重排序。该框架基于这样一种思想:变换可以表示为将原始迭代空间映射到新迭代空间的调度。框架旨在为变换提供一种统一的表示和推理方式。作为框架的一部分,我们提供了辅助构建和使用调度的算法,特别是用于检验调度合法性、对齐调度以及为调度生成优化代码的算法。2)优化编译器会对语句的迭代进行重新排序,
- [论文阅读] 系统架构 | 零售 IT 中的微服务与实时处理:开源工具链与部署策略综述
张较瘦_
前沿技术论文阅读大数据零售
零售IT中的微服务与实时处理:开源工具链与部署策略综述论文信息MicroservicesandReal-TimeProcessinginRetailIT:AReviewofOpen-SourceToolchainsandDeploymentStrategiesAaditaaVashisht(DepartmentofInformationScienceandEngineering,RVCollege
- [论文阅读]人工智能 | CoMemo:给大视觉语言模型装个“图像记忆”
张较瘦_
前沿技术人工智能论文阅读语言模型
【论文速览】CoMemo:给大视觉语言模型装个“图像记忆”论文信息Liu,S.,Su,W.,Zhu,X.,Wang,W.,&Dai,J.(2025).CoMemo:LVLMsNeedImageContextwithImageMemory.arXivpreprintarXiv:2506.06279.一、研究背景:当LVLMs遇到“视觉健忘症”想象一下,你在阅读一本图文并茂的小说时,随着文字篇幅越来越
- [论文阅读] 人工智能+软件工程 | 结对编程中的知识转移新图景
张较瘦_
前沿技术人工智能软件工程结对编程
当AI成为编程搭档:结对编程中的知识转移新图景论文信息论文标题:FromDeveloperPairstoAICopilots:AComparativeStudyonKnowledgeTransfer(从开发者结对到AI副驾驶:知识转移的对比研究)作者及机构:AlisaWelter等来自德国萨尔兰大学,ChristofTinnes同时隶属于西门子公司发表平台:arXiv预印本平台发表时间:2025年
- 【论文阅读笔记】HaDes幻觉检测benchmark
zsq
论文分享论文阅读笔记NLP大语言模型幻觉
0论文信息题目:AToken-levelReference-freeHallucinationDetectionBenchmarkforFree-formTextGeneration作者:TianyuLiu,YizheZhang,ChrisBrockett,YiMao,ZhifangSui,WeizhuChen,BillDolan会议:ACL,2022链接:https://arxiv.org/ab
- 论文阅读:Enhancing Retrieval and Managing Retrieval: A Four-Module Synergy for Improved Quality and Ef
clvsit
RAG论文阅读LLM
检索增强生成(RAG)技术利用大型语言模型(LLM)的上下文学习能力,生成更准确、更相关的响应。RAG框架起源于简单的“检索-阅读”方法,现已发展成为高度灵活的模块化范式。其中一个关键组件——查询重写模块,通过生成搜索友好的查询来增强知识检索。这种方法能使输入问题与知识库更紧密地结合起来。作者的研究发现了将QueryRewriter模块增强为QueryRewriter+的机会,即通过生成多个查询来
- 论文阅读:HySCDG生成式数据处理流程
论文地址:TheChangeYouWantToDetect:SemanticChangeDetectionInEarthObservationWithHybridDataGenerationAbstract摘要内容介绍问题背景“Bi-temporalchangedetectionatscalebasedonVeryHighResolution(VHR)imagesiscrucialforEarth
- [论文阅读] 人工智能 | 搜索增强LLMs的用户偏好与性能分析
张较瘦_
前沿技术人工智能论文阅读
【论文解读】SearchArena:搜索增强LLMs的用户偏好与性能分析论文信息作者:MihranMiroyan,Tsung-HanWu,LoganKing等标题:SearchArena:AnalyzingSearch-AugmentedLLMs来源:arXivpreprintarXiv:2506.05334v1,2025一、研究背景:当LLMs需要“上网查资料”时,我们如何评估它?想象你在问AI
- [论文阅读] 人工智能 | 如何快速检测LLM生成的代码?这篇论文提出了一个巧妙的方法
张较瘦_
前沿技术人工智能论文阅读
如何快速检测LLM生成的代码?这篇论文提出了一个巧妙的方法论文引文格式@misc{ashkenazi2025zero,title={Zero-ShotDetectionofLLM-GeneratedCodeviaApproximatedTaskConditioning},author={MaorAshkenaziandOfirBrennerandTalFurmanShohetandEranTrei
- [论文阅读] 人工智能+软件工程 | 理解GitGoodBench:评估AI代理在Git中表现的新基准
张较瘦_
前沿技术论文阅读人工智能软件工程
理解GitGoodBench:评估AI代理在Git中表现的新基准论文信息GitGoodBench:ANovelBenchmarkForEvaluatingAgenticPerformanceOnGitTobiasLindenbauer,EgorBogomolov,YaroslavZharovCiteas:arXiv:2505.22583[cs.SE]研究背景:当AI走进开发者的协作工具箱在软件开发
- [论文阅读] 人工智能+软件工程(软件测试) | 当大语言模型遇上APP测试:SCENGEN如何让手机应用更靠谱
张较瘦_
前沿技术人工智能论文阅读软件工程
当大语言模型遇上APP测试:SCENGEN如何让手机应用更靠谱?一、论文基础信息论文标题:LLM-GuidedScenario-basedGUITesting(《大语言模型引导的基于场景的GUI测试》)作者及机构:ShengchengYu等(德国慕尼黑工业大学、南京大学、同济大学等)发表来源:IEEETransactionsonSoftwareEngineering(IEEE软件工程汇刊)发表时间
- [论文阅读] 人工智能+软件工程 | 用大模型优化软件性能
张较瘦_
前沿技术论文阅读人工智能软件工程
用大模型优化软件性能?这篇论文让代码跑出新速度!arXiv:2506.01249SysLLMatic:LargeLanguageModelsareSoftwareSystemOptimizersHuiyunPeng,ArjunGupte,RyanHasler,NicholasJohnEliopoulos,Chien-ChouHo,RishiMantri,LeoDeng,KonstantinLäuf
- Enhanced Sparse Model for Blind Deblurring论文阅读
青铜锁00
#退化论文阅读论文阅读图像处理
EnhancedSparseModelforBlindDeblurring1.研究目标与意义1.1研究目标1.2实际意义与产业价值2.论文提出的新思路、方法及模型2.1增强稀疏模型(EnhancedSparseModel,lel_ele)模型定义与数学表达闭式解与稀疏性增强机制2.2改进的噪声建模策略噪声拟合函数的构建空间随机性建模2.3整体优化框架与半二次分裂法目标函数设计优化步骤拆分参数设置与
- apache 安装linux windows
墙头上一根草
apacheinuxwindows
linux安装Apache 有两种方式一种是手动安装通过二进制的文件进行安装,另外一种就是通过yum 安装,此中安装方式,需要物理机联网。以下分别介绍两种的安装方式
通过二进制文件安装Apache需要的软件有apr,apr-util,pcre
1,安装 apr 下载地址:htt
- fill_parent、wrap_content和match_parent的区别
Cb123456
match_parentfill_parent
fill_parent、wrap_content和match_parent的区别:
1)fill_parent
设置一个构件的布局为fill_parent将强制性地使构件扩展,以填充布局单元内尽可能多的空间。这跟Windows控件的dockstyle属性大体一致。设置一个顶部布局或控件为fill_parent将强制性让它布满整个屏幕。
2) wrap_conte
- 网页自适应设计
天子之骄
htmlcss响应式设计页面自适应
网页自适应设计
网页对浏览器窗口的自适应支持变得越来越重要了。自适应响应设计更是异常火爆。再加上移动端的崛起,更是如日中天。以前为了适应不同屏幕分布率和浏览器窗口的扩大和缩小,需要设计几套css样式,用js脚本判断窗口大小,选择加载。结构臃肿,加载负担较大。现笔者经过一定时间的学习,有所心得,故分享于此,加强交流,共同进步。同时希望对大家有所
- [sql server] 分组取最大最小常用sql
一炮送你回车库
SQL Server
--分组取最大最小常用sql--测试环境if OBJECT_ID('tb') is not null drop table tb;gocreate table tb( col1 int, col2 int, Fcount int)insert into tbselect 11,20,1 union allselect 11,22,1 union allselect 1
- ImageIO写图片输出到硬盘
3213213333332132
javaimage
package awt;
import java.awt.Color;
import java.awt.Font;
import java.awt.Graphics;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imagei
- 自己的String动态数组
宝剑锋梅花香
java动态数组数组
数组还是好说,学过一两门编程语言的就知道,需要注意的是数组声明时需要把大小给它定下来,比如声明一个字符串类型的数组:String str[]=new String[10]; 但是问题就来了,每次都是大小确定的数组,我需要数组大小不固定随时变化怎么办呢? 动态数组就这样应运而生,龙哥给我们讲的是自己用代码写动态数组,并非用的ArrayList 看看字符
- pinyin4j工具类
darkranger
.net
pinyin4j工具类Java工具类 2010-04-24 00:47:00 阅读69 评论0 字号:大中小
引入pinyin4j-2.5.0.jar包:
pinyin4j是一个功能强悍的汉语拼音工具包,主要是从汉语获取各种格式和需求的拼音,功能强悍,下面看看如何使用pinyin4j。
本人以前用AscII编码提取工具,效果不理想,现在用pinyin4j简单实现了一个。功能还不是很完美,
- StarUML学习笔记----基本概念
aijuans
UML建模
介绍StarUML的基本概念,这些都是有效运用StarUML?所需要的。包括对模型、视图、图、项目、单元、方法、框架、模型块及其差异以及UML轮廓。
模型、视与图(Model, View and Diagram)
&
- Activiti最终总结
avords
Activiti id 工作流
1、流程定义ID:ProcessDefinitionId,当定义一个流程就会产生。
2、流程实例ID:ProcessInstanceId,当开始一个具体的流程时就会产生,也就是不同的流程实例ID可能有相同的流程定义ID。
3、TaskId,每一个userTask都会有一个Id这个是存在于流程实例上的。
4、TaskDefinitionKey和(ActivityImpl activityId
- 从省市区多重级联想到的,react和jquery的差别
bee1314
jqueryUIreact
在我们的前端项目里经常会用到级联的select,比如省市区这样。通常这种级联大多是动态的。比如先加载了省,点击省加载市,点击市加载区。然后数据通常ajax返回。如果没有数据则说明到了叶子节点。 针对这种场景,如果我们使用jquery来实现,要考虑很多的问题,数据部分,以及大量的dom操作。比如这个页面上显示了某个区,这时候我切换省,要把市重新初始化数据,然后区域的部分要从页面
- Eclipse快捷键大全
bijian1013
javaeclipse快捷键
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)Ctrl+D: 删除当前行 Ctrl+Alt+↓ 复制当前行到下一行(复制增加)Ctrl+Alt+↑ 复制当前行到上一行(复制增加)Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)Alt+↑ 当前行和上面一行交互位置(同上)Alt+← 前一个编辑的页面Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)Alt+En
- js 笔记 函数
征客丶
JavaScript
一、函数的使用
1.1、定义函数变量
var vName = funcation(params){
}
1.2、函数的调用
函数变量的调用: vName(params);
函数定义时自发调用:(function(params){})(params);
1.3、函数中变量赋值
var a = 'a';
var ff
- 【Scala四】分析Spark源代码总结的Scala语法二
bit1129
scala
1. Some操作
在下面的代码中,使用了Some操作:if (self.partitioner == Some(partitioner)),那么Some(partitioner)表示什么含义?首先partitioner是方法combineByKey传入的变量,
Some的文档说明:
/** Class `Some[A]` represents existin
- java 匿名内部类
BlueSkator
java匿名内部类
组合优先于继承
Java的匿名类,就是提供了一个快捷方便的手段,令继承关系可以方便地变成组合关系
继承只有一个时候才能用,当你要求子类的实例可以替代父类实例的位置时才可以用继承。
在Java中内部类主要分为成员内部类、局部内部类、匿名内部类、静态内部类。
内部类不是很好理解,但说白了其实也就是一个类中还包含着另外一个类如同一个人是由大脑、肢体、器官等身体结果组成,而内部类相
- 盗版win装在MAC有害发热,苹果的东西不值得买,win应该不用
ljy325
游戏applewindowsXPOS
Mac mini 型号: MC270CH-A RMB:5,688
Apple 对windows的产品支持不好,有以下问题:
1.装完了xp,发现机身很热虽然没有运行任何程序!貌似显卡跑游戏发热一样,按照那样的发热量,那部机子损耗很大,使用寿命受到严重的影响!
2.反观安装了Mac os的展示机,发热量很小,运行了1天温度也没有那么高
&nbs
- 读《研磨设计模式》-代码笔记-生成器模式-Builder
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 生成器模式的意图在于将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示(GoF)
* 个人理解:
* 构建一个复杂的对象,对于创建者(Builder)来说,一是要有数据来源(rawData),二是要返回构
- JIRA与SVN插件安装
chenyu19891124
SVNjira
JIRA安装好后提交代码并要显示在JIRA上,这得需要用SVN的插件才能看见开发人员提交的代码。
1.下载svn与jira插件安装包,解压后在安装包(atlassian-jira-subversion-plugin-0.10.1)
2.解压出来的包里下的lib文件夹下的jar拷贝到(C:\Program Files\Atlassian\JIRA 4.3.4\atlassian-jira\WEB
- 常用数学思想方法
comsci
工作
对于搞工程和技术的朋友来讲,在工作中常常遇到一些实际问题,而采用常规的思维方式无法很好的解决这些问题,那么这个时候我们就需要用数学语言和数学工具,而使用数学工具的前提却是用数学思想的方法来描述问题。。下面转帖几种常用的数学思想方法,仅供学习和参考
函数思想
把某一数学问题用函数表示出来,并且利用函数探究这个问题的一般规律。这是最基本、最常用的数学方法
- pl/sql集合类型
daizj
oracle集合typepl/sql
--集合类型
/*
单行单列的数据,使用标量变量
单行多列数据,使用记录
单列多行数据,使用集合(。。。)
*集合:类似于数组也就是。pl/sql集合类型包括索引表(pl/sql table)、嵌套表(Nested Table)、变长数组(VARRAY)等
*/
/*
--集合方法
&n
- [Ofbiz]ofbiz初用
dinguangx
电商ofbiz
从github下载最新的ofbiz(截止2015-7-13),从源码进行ofbiz的试用
1. 加载测试库
ofbiz内置derby,通过下面的命令初始化测试库
./ant load-demo (与load-seed有一些区别)
2. 启动内置tomcat
./ant start
或
./startofbiz.sh
或
java -jar ofbiz.jar
&
- 结构体中最后一个元素是长度为0的数组
dcj3sjt126com
cgcc
在Linux源代码中,有很多的结构体最后都定义了一个元素个数为0个的数组,如/usr/include/linux/if_pppox.h中有这样一个结构体: struct pppoe_tag { __u16 tag_type; __u16 tag_len; &n
- Linux cp 实现强行覆盖
dcj3sjt126com
linux
发现在Fedora 10 /ubutun 里面用cp -fr src dest,即使加了-f也是不能强行覆盖的,这时怎么回事的呢?一两个文件还好说,就输几个yes吧,但是要是n多文件怎么办,那还不输死人呢?下面提供三种解决办法。 方法一
我们输入alias命令,看看系统给cp起了一个什么别名。
[root@localhost ~]# aliasalias cp=’cp -i’a
- Memcached(一)、HelloWorld
frank1234
memcached
一、简介
高性能的架构离不开缓存,分布式缓存中的佼佼者当属memcached,它通过客户端将不同的key hash到不同的memcached服务器中,而获取的时候也到相同的服务器中获取,由于不需要做集群同步,也就省去了集群间同步的开销和延迟,所以它相对于ehcache等缓存来说能更好的支持分布式应用,具有更强的横向伸缩能力。
二、客户端
选择一个memcached客户端,我这里用的是memc
- Search in Rotated Sorted Array II
hcx2013
search
Follow up for "Search in Rotated Sorted Array":What if duplicates are allowed?
Would this affect the run-time complexity? How and why?
Write a function to determine if a given ta
- Spring4新特性——更好的Java泛型操作API
jinnianshilongnian
spring4generic type
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- CentOS安装JDK
liuxingguome
centos
1、行卸载原来的:
[root@localhost opt]# rpm -qa | grep java
tzdata-java-2014g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
[root@localhost
- 二分搜索专题2-在有序二维数组中搜索一个元素
OpenMind
二维数组算法二分搜索
1,设二维数组p的每行每列都按照下标递增的顺序递增。
用数学语言描述如下:p满足
(1),对任意的x1,x2,y,如果x1<x2,则p(x1,y)<p(x2,y);
(2),对任意的x,y1,y2, 如果y1<y2,则p(x,y1)<p(x,y2);
2,问题:
给定满足1的数组p和一个整数k,求是否存在x0,y0使得p(x0,y0)=k?
3,算法分析:
(
- java 随机数 Math与Random
SaraWon
javaMathRandom
今天需要在程序中产生随机数,知道有两种方法可以使用,但是使用Math和Random的区别还不是特别清楚,看到一篇文章是关于的,觉得写的还挺不错的,原文地址是
http://www.oschina.net/question/157182_45274?sort=default&p=1#answers
产生1到10之间的随机数的两种实现方式:
//Math
Math.roun
- oracle创建表空间
tugn
oracle
create temporary tablespace TXSJ_TEMP
tempfile 'E:\Oracle\oradata\TXSJ_TEMP.dbf'
size 32m
autoextend on
next 32m maxsize 2048m
extent m
- 使用Java8实现自己的个性化搜索引擎
yangshangchuan
javasuperword搜索引擎java8全文检索
需要对249本软件著作实现句子级别全文检索,这些著作均为PDF文件,不使用现有的框架如lucene,自己实现的方法如下:
1、从PDF文件中提取文本,这里的重点是如何最大可能地还原文本。提取之后的文本,一个句子一行保存为文本文件。
2、将所有文本文件合并为一个单一的文本文件,这样,每一个句子就有一个唯一行号。
3、对每一行文本进行分词,建立倒排表,倒排表的格式为:词=包含该词的总行数N=行号