Fourier分析入门——第3章——离散函数的Fourier分析
目录
第 3 章 离散函数的Fourier分析
3.1 引言
3.2 在1点采样的函数
3.3 在2点采样的函数
3.4 Fourier分析是一种线性变换
3.5 Fourier分析是一种基向量的变更
3.6 在3点采样的函数
3.7 在D点采样的函数
3.8 整理(tidying up)
3.9 Parseval[pá:zeifa:l]定理
3.10 关联统计
3.11 图像对比和复合光栅(Image Contrast and Compound Gratings)
3.12 闭合曲线形状的Fourier描述符(Fourier Descriptors of the Shape of a Closed Curve)
第 3 章 离散函数的Fourier分析
3.1 引言
Carslaw (1921)在他的经典教材<
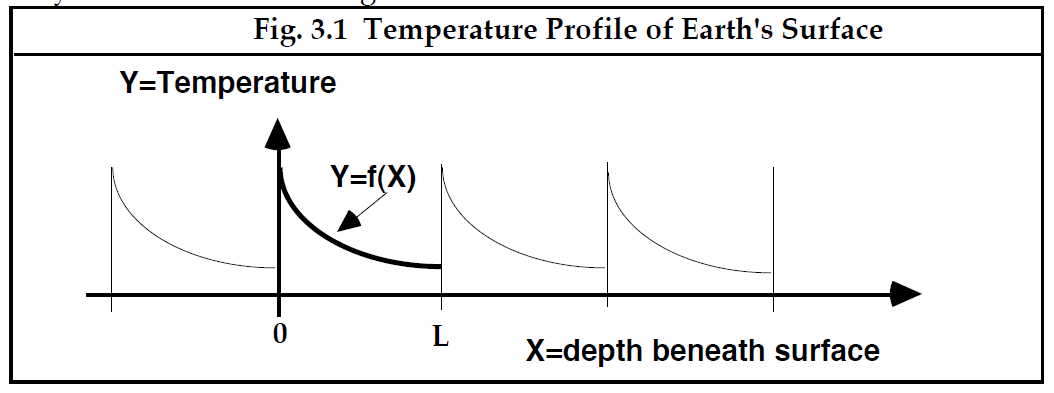
(译注: = 地表以下的深度, = 温度)
------------------------图 3.1地球表面的温度曲线-----------------------------
尽管此示例中的温度分布仅定义为从地球表面 ( = 0) 到深度 = ,但假设我们多次复制给定曲线并将各段首尾相连,如图中的细曲线(light curves)所示。结果将是一个周期为的周期函数,可以在正向 和负向 轴方向上任意拉伸。这种人为制造的周期性旨在提高我们对采用正弦曲线之和表示此类函数成功的期望,正弦曲线覆盖 轴的整个长度。 显然,如果正弦曲线之和适合整个 轴上的周期函数,则它会适合用于区间 (0 - ) 内的原始函数。该图还清楚地表明每个正弦分量的周期必须是 的某个倍数,否则某些间隔将与其他间隔不同,这与周期性的思想不相容。精确重现函数 = f (X) 所需的呈谐波关系的正弦级数的名称就是Fourier级数(series)(译注:Fourier级数就是一系列呈谐波关系的正弦级数,这些正弦函数之间的频率是倍频关系,即都为某个基波频率的整数倍)。
在解决为有限区间上定义的连续函数求Fourier级数这一难题之前,我们将从更简单的问题开始——即当给定函数由沿 轴均匀分布的 值的离散序列组成时所确定的Fourier级数。对于需要分析某些物理变量的一系列离散测量值,或者可能使用计算机以规律的时间间隔对连续过程进行采样的实验者来说,这个问题不仅更容易,而且更具有实际意义。
3.2 在1点采样的函数
考虑一种极端情况,其中函数 ( ) 仅已知 的一个值。例如,在图 3.1 所示的热研究中,假设我们有一个由在 = 0位置采样得到的单个测量值 组成的原始数据集。为了体验未来更具挑战性的案例的味道,设想一下对这个单一的测量值进行建模的函数
Y = f ( X ) = m -------------------------------------------------------[3.1]
其中,m 是一个我们必须确定的数值参数。很明显,这个选择是令 。该问题在图 3.2 中以图形方式说明,问题的解是通过基准点的粗水平线。这条水平线是D = 1个样本这种情况Fourier级数,参数 m 称为Fourier系数(coefficients)。 虽然这是Fourier分析的一个相当简单的例子,但它说明了更通用过程的第一步。
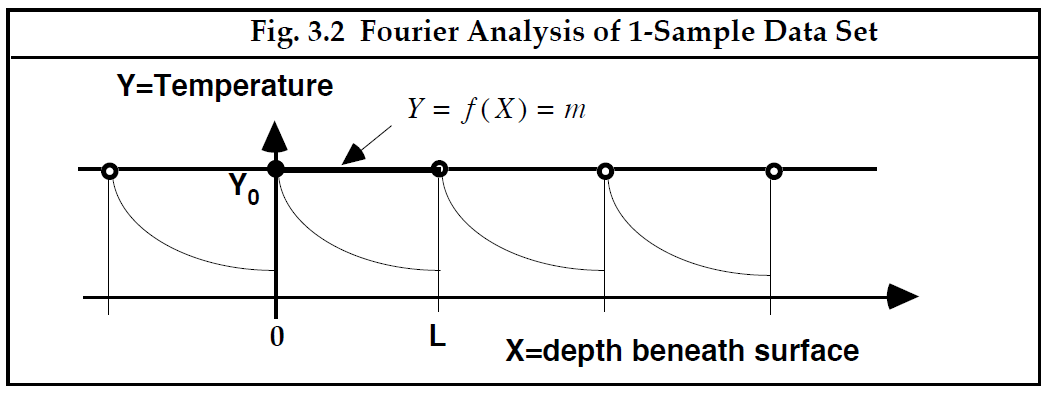
---------------------------图 3.2 一个采样点数据集的Fourier分析-------------------------------------------
如果我们参与复制数据集的过程是为了产生周期函数,则相同的Fourier级数会按预期通过所有复制的数据点。 但是请注意,拟合线(fitted line)对潜在连续曲线的表示非常差。 当然,原因在于我们只提供了一个测量值; 为了更好地适配潜在的函数,我们需要更多样点。
3.3 在2点采样的函数
接下来,假设我们分别在两个深度 和
采样得到两个测量值
和
,如图3.3所示。这些 值对应将整个区间
按 D = 2 等分的前两个子区间。现在我们获得了两个测量值,我们就可以在我们的模型中加入第二个采样值。因此,我们寻求适配数据的Fourier级数为(译注:这个余弦项的引入稍显突兀,如果有个过度过程或许更好)
。------------------------------------------[3.2]
为了确定未知的Fourier系数 m 和 a ,我们使用已有的两个 值来计算方程[3.2]。结果是这一对方程
..........................@ = 0
..........................@ = /2 --------------[3.3 ]
这对方程的解是
-----------------------------------------------------------------------------------------[3.4]
因此,我们总结出这个模型为
-------------------------------------------[3.5]
将正好通过原来的两个数据点,如下图3.3所求。
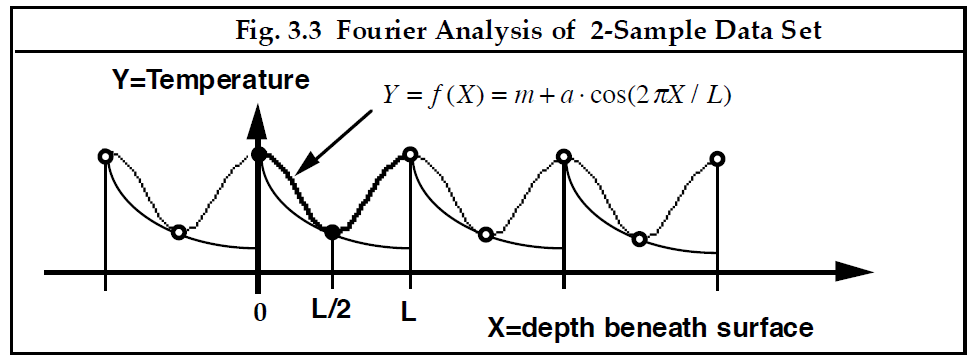
---------------------------图 3.3 一个采样点数据集的Fourier分析-----------------------------------------------
注意,该模型中的余弦项在区间 (0-L) 中经历了一个完整的循环。 换句话说,余弦项的频率与潜在函数的周期波形的频率相同。基于这个原因,这个余弦被称为Fourier级数中的基本谐波项(fundamental harmonic term)(译注:复杂有规律周期波的分量,“谐”指“和声”,“有规律的声音”,相对于杂乱无章的噪声而言,这些分量之间的频率呈整数倍关系)。 与之前只有常数项的模型相比,这个常数加余弦函数的新模型显然更符潜在函数。 另一方面,重要的是要记住,尽管数学模型存在于整个 轴上,但它仅适用于观察区间 (0-L) 内的物理问题,并且在该区间内,模型严格仅适用于实际测量的2个点。在间隔之外,模型是荒谬的,因为有充分的理由期望物理图像不是周期性的。即使在区间内,模型对于实际数据点之间的
值也可能没有意义。为了判断模型作为插值函数(interpolation function)的有用性,我们必须求助于我们对所研究的物理系统的理解。在后面的部分中,我们将扩展此示例以包含 D = 3 个样本,但在此之前,我们需要更深入地了解我们刚刚介绍的Fourier分析过程。
3.4 Fourier分析是一种线性变换
如前例所示,离散函数的Fourier分析产生的模型由正弦曲线的加权和加上一个常数组成。 这些权重或傅立叶系数是模型的未知参数,必须根据数据确定。 上例中用于产生系数值的计算方法是求解两个未知数的两个线性方程。 这表明我们将方程 [3.3] 写成矩阵形式如下
---------------------------------------------------------[3.6]
当按这种方式书写的时候,Fourier分析就像第2章中描述的那种线性变换。即,假如我们将我们的两个采样点 和
看成是二维数据向量 v 的两个分量,则v显然是由Fourier系数 m 和 a 组成的某个其他向量 f 的变换。在矩阵记法中,声明是 v = M.f 。逆变换为
,表明Fourier系数向量 f 是已知数据向量 v 的一个线性变换。为了证明这一点,首先我们求得矩阵M的逆矩阵,然后用这个结果将向量 v 写成下式
--------------------------------------[3.7]
显然,这等价于[3.4],(公因子1/2 已经从这个逆矩阵
的元素中提取出来了。) 在Fourier分析的语言中,等[3.7]描述为数据向量 v 到Fourier系数向量 f 的离散Fourier变换(Discrete Fourier Transform,简记为DFT)。反之,等式[3.6]描述为 f 的逆离散Fourier变换重现数据向量v 。
3.5 Fourier分析是一种基向量的变更
观察Fourier分析的另一种方式在于其自我暗示。如果我们重写等式[3.6]为向量和
---------------------------------------------------------------------------------[3.8]
其中, 是给定采样点计算出来的常量函数 cos(0*2π / ),
是给定采样点计算出来的基本谐波函数 cos(1*2π / ),
-------------------------------------------[3.9]
换言之,这些等式指的是,数据向量 v 是两个其它向量 和
的加权和。注意,向量
和
是正交的(译注:几何上表现起来就是垂直,代数上表现起来就是内积为0),因此也是线性无关的,所以可以为二维向量空间用于表示v提供替代基向量。这种解释如图3.4所示。 以这种观点看待这个问题的优点在于,它提供了一种计算未知参数m的 a的几何解释。这些参数在基向量
和
方向表示 v 的分量。从第 2 章我们知道,这些分量是通过将 v 投影到基向量上而找到的,并且这些投影的长度可以通过内积来计算。因此,我们可通过按如下方式通过计算内积
来求得 m :
------------------------------------------------------------------------------------------[3.10]

---------------------------图 3.4 Fourier分析视作一种基向量的变更------------------------------------------
注意[3.10]中的第二项消掉了,因为这两项具有正交性。重排这个等式,我们得到
-------------------------------------------------------[3.11]
类似地,我们可通过按如下方式通过计算内积 来求得a:
---------------------------------------------------------------------------[3.12]
再次,因为第一项两向量的正交性,消除掉了,从而求得
-------------------------------------------------------[3.13]
数据向量 v 与向量 和
的内积的重复形成表明了(有点非常规的)矩阵表示法
--------------------------------------------------[3.14]
上式与等式[3.7]一样,在等式中,C -> 表示包含余弦波采样点的行向量。
从这个讨论中得出的结论是,如果我们将函数两个采样序列表示为数据向量 v,那么,我们可以通过创建两个正交向量 和
并将数据向量投影到这两个新的基向量的方式,对这个数据向量进行Fourier分析。这些投影的长度可以解释为数据向量中存在的
和
的数量。由于
只是采样常数函数,而
是采样余弦函数,这些投影告诉我们数据中存在多少常数和多少余弦。这就是Fourier分析的全部意义所在!在下一节中,我们将扩展这条推理路径以处理 D = 3 个样本的情况,然后将结果推广到任意数量的样本。
3.6 在3点采样的函数
现在让我们回到测量图 3.2 的温度函数的问题。我们已经看到,如果我们在两个点对温度进行采样,那么具有两个项的Fourier级数将与这两个测量值完全吻合。为了概括这一观察,我们可能期望三个样本将完全符合 3 项Fourier级数,四个样本将符合 4 项Fourier级数,等等。“多少项足够?”这个显而易见的问题。 稍后的章节会处理。目前,我们可以说两件事。首先,要用Fourier模型完美拟合连续函数,需要无限多的项。其次,我们可以想象,如果采样了足够多的点,即如果样本足够靠近,那么使用Fourier模型在点之间进行插值所产生的误差将变得微不足道。 为了进一步明晰这种不确切的表述,我们需要定义“足够多点”所指以及模型的错误何时才“微不足道”的标准。然后,要判断一个特定模型是否满足这些标准,我们最终必须依赖于我们对问题物理学的理解。但在我们解决这些重要问题之前,我们需要开发适用于任意数量样本点的Fourier级数的通用公式。在我们考虑一个更具体的例子,即 D = 3 之后,我们将能够做到这一点。
为了获得图3.2中那样的潜在函数的更好的模型,假设测量值 ,
和
分别在三个深度 = 0 , = /3 和 = 2/3处采样取得,如图3.5所示。这些 值分别对应将整个区间 划分成D = 3 等份后的3个子区间的开始。
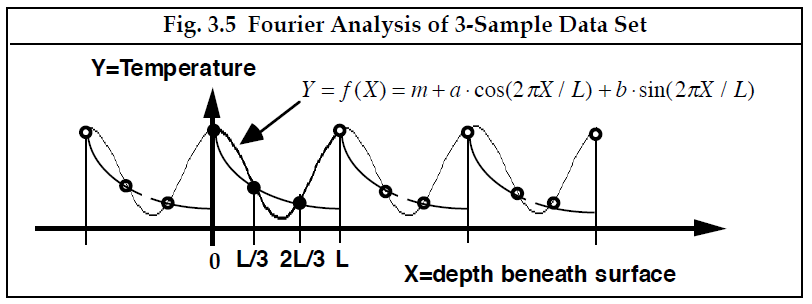
---------------------------图 3.5 3个采样黄河口的Fourier分析---------------------------------------------------
现在我们有了第三个测量值,我们可以向我们的三角模型添加第三项。因此,我们寻求用以下的Fourier级数来适配测量数据
。-------------[3.15]
为了确定3个未知的Fourier系数 m,a 和 b,我们以在三个 值处测得的值来计算方程 [3.15]。结果是3个线性方程组
..........................@ = 0
..................@ = /2
..................@ = /2 -----------[3.16 ]
为了解这个线性方程组,我们首先将它们写成 v = Mf 的矩阵形式如下
------------------------------[3.17]
当按这种方式书写的时候,矩阵 M 的列立即识别为构成我们的Fourier模型的基的采样三角函数的列向量 ,
和
。这预示着更紧凑的记法(使用箭头表示矩阵中的列向量)
----------------------------------------------------------------------------[3.18]
据此,推断出向量v 是基向量的加权和
。----------------------------------------------------------------------[3.19]
换句话说,假如我们想象从3个给定的 值构成一个3维数据向量,则这个向量存在于一个3维空间中,该空间由分布着一组可替代的基向量:采样三角函数。每个向量的数量可应用等式 3.18 计算所得,这种计算称为逆离散Fourier变换(inverse discrete Fourier transform,简记为IDFT)。

------------------------------图3.6 3个点的离散函数向量表示-----------------------------------------------------
因此,我们可以认为数据向量是这些基向量的加权和,相应的权重是我们想要的未知Fourier系数。这个问题的几何观点表明,为了确定Fourier系数,我们应该通过形成内积将数据向量依次投影到每个基向量上。例如,将 v 投影到 给出
-----------------------------------------------------------------------[3.20]
注意,除了一项其它项都消减了,因为其正交性。从练习3.3我们可知, 的平方长度是D(Dimensionality),即问题的维数(本例中为D = 3)。因此,第一个Fourier系数是
-----------------------------------------------------------------------[3.21]
按类似的推理路径,我们求得了另外两个Fourier系数
---------------------------------------------------------------------------[3.22]
这最后两个等式可以结合起来给出矩阵形式(使用箭头表示矩阵中的行向量)
------------------------------[3.23]
可以通过提取公因子 2/D 得到前向离散Fourier变换 (DFT) 来简化
---------------------------------------------[3.24]
总之,等式 [3.16] 到 [3.19] 是表示 D = 3 情况下的逆 DFT 的不同方式。因此,他们告诉我们如何从Fourier系数“重建”测量数据点。但我们需要解决相反的问题:给定测量值,确定未的Fourier系数。换句话说,我们寻求前向DFT, ,这意味着我们必须求得矩阵 M 的逆矩阵。我们的求解方法利用了正交性的优点,通过重复地组成数据向量与每个三角基向量的内积的方式求解。当每个内积除以相应基函数的长度时,其结果在几何上被解释为向量 v 在基向量上的投影的长度。这些长度等于模型中的Fourier系数。
3.7 在D点采样的函数
前面 D = 1、2 和 3 的示例指出了确定适用于任意点数的三角模型的Fourier系数的通用方法。 在第 3.1 节中,我们推断,模型中所有三角函数元素的周期必须是观察区间的某个整数分数。即,周期一定等于 /k ,其中,是k一个整数,我们称之为谐波数(harmonic number)。因此,我们寻求的Fourier级数具有形式
。---------------------------------------------------------[3.25]
假如我们对自变量做一点改变,以此稍微简化一下记法,或许更容易掌握
,
-------------------------------------------------------------- ----------------[3.26]
其中,当 D是偶数的时候,D = 2N , 当 D是奇数的时候,D = 2N + 1 。和以前的思路一样, 我们假设 区间从 0 到 划分成 D 等份,且 值发生在每个这些区间的开始,因此, 。
对于 D 个数据点,有 D 个待确定的未知Fourier系数。如果方程 [3.26] 在我们测量的每个 值进行计算,那么结果是一个 D 线性方程组,当写成矩阵形式时,是
-------------------------------[3.27]
紧凑地写成 f 与列向量矩阵的内积
--------------------------------------------[3.28]
等式[3.27]和[3.28]显示的是当 D是奇数时的逆离散Fourier变换(IDFT)。当是D是偶数的时候,矩阵中最后一列( )和最后的Fourier系数(
)被忽略。
为了获得前向 DFT,我们将 D 数据点设想为 D 维空间中的向量,可以表示为三角基向量的加权和。对应的权重是未知Fourier系数,其计算方法为通过依次将数据向量投影到每个基向量上的方式计算内积而求得。例如,我们将 v 投影到
----------------------------------------------------------------------------------------[3.29]
请注意,由于正交性,扩展内积中除一项外的所有项都消失了。回顾练习3.3, 的平方长度等于 D/2 ,因此,第 k 项 Fourier余弦系数由简单公式
.............................
---------------------------------------------------------------------------------------[3.30]
给出。
同样,第 k 项 Fourier正弦系数由简单公式
............................
---------------------------------------------------------------------------------------[3.31]
给出。
因此,最后两个等式定义了每个傅里叶系数,除了两个不包含因子 2 的特殊例外。缺少该因子的原因是相应基向量的平方长度是 D 而不是 D/2。一个特例是第一个Fourier系数 m,它是均值(mean value),另一个特例是最后一个Fourier系数,当 D 是偶数时,它为 。
注意,这些结果表明,可以在不考虑其他Fourier系数的情况下计算任何特定的Fourier系数。这是采样正弦波正交性的简化结果。这一结果的一个实际意义是,如果只对某些感兴趣,则没有必要计算模型的所有Fourier系数。 另一方面,如果要计算所有的Fourier系数,那么通过如下方式的矩阵乘法一次计算它们会很方便,即
-----------------------------------------[3.32]
提出公因式 2/ D 之后简化为
-----------------------------------------------------------------[3.33]
3.8 整理(tidying up)
虽然刚刚开发的一般方程有效,但有几个在美学上令人不悦的特征,这些特征掩盖了(obscure)Fourier分析的重要几何解释。首先,需要一个特殊的公式来计算平均系数 m(译注:没将其统一起来)。如果我们设置 k = 0,方程 [3.30] 生成的答案恰好是均值的两倍。 即 。 这表明我们只要改变模型中的变量,我们就不需要将常数项视为特例。随着变量的这种变化,模型变为
,
----------------[3.34]
这就是教科书中普遍引用的Fourier级数形式。
接下来,在等式 [3.33] 的矩阵顶部元素中有不协调的(unsightly)因子 2。这种不规则(anormaly)是由于除 外所有三角基向量的平方长度为 D/2 ,而
的平方长度是 D 。这表明,在等式[3.27]中用
乘以
,然后在分子中析出因数
,并将它归入 Fourier级数向量中的
项,如下等式[3.35]所示
---------------------------------------[3.35]
由于现在三角矩阵中的每一列向量都具有长度 ,我们提出这个公因子使得每一列向量都具有单位长度。为了保持等式的整洁性,我们首先定义以下的单位基向量
-----------------------------------------------------------------------------------[3.36]
因此,等式[3.35]现在就变成了
-----------------------[3.37]
写成紧凑记法为
---------------------------------------[3.38]
(逆 DFT)
注意,请记住 f 的第一项,即Fourier系数向量,与之前的用法有个 的差异。另外,需指出,当 D 是偶数时,[3.37]中最后一项Fourier系数是
。
以等式[3.38]的形式表示逆DFT的一个主要优点是三角向量矩阵是标准正交的,这意味着逆矩阵只是转置。 因此,我们可以通过检查立即写出正向 DFT:
-------------------------------------------[3.39]
(前向DFT)
对称的等式对 [3.38] 和 [3.39] 很容易在计算机上编程实现。
这种形式的 DFT 等式的第二个优点是它揭示了Fourier分析的基本几何结构的根本简洁性。由于三角向量矩阵是标准正交的,所以它被识别为旋转矩阵。换言之,数据向量 v 通过旋转和尺度变化(由等式 [3.39] 中的常数乘数 表示) 转换为Fourier向量 f 。 很自然地,数据向量的长度应该是相同的,不管它是在哪个参考系中被计算。这个几何概念在下面被表述为Parseval定理,它也可以在物理上解释为能量守恒的表述。
3.9 Parseval[pá:zeifa:l]定理
为表示数据向量 v 的 D 维空间定义了两组正交基向量后,针对这两个坐标参考系计算 v 的长度以进行比较是大有裨益的。我们之前已经了解到 v 与自身的内积产生向量的平方长度。 然而,在这样的计算中我们必须小心,因为我们已经看到两个参考系的比例不同。 确保这些比例因子被考虑到位的一种方法是——将数据向量表示为指向坐标参考系基准方向(cardinal directions)的单位向量的加权和。换句话说,令
-------------------------------------------------------------[3.40]
其中,单位基向量 对第一个参考坐标系的坐标除了k维之外的每一维都是坐标0 ,而对k维的坐标为1。例如,
-------------------------------------------------------------------------[3.41]
现在形成 v 与自身的内积很容易计算,因为许多项由于基向量的正交性而消失,而其余项包含因子 u•u,它是单位的,因为基向量是单位长度。 因此我们有,
----------------------------------------------------------------------------[3.42]
这就是 D 维空间的Pythagoras定理。请注意,等式 [3.42] 的简化如此显著,因为由于单位基向量 的正交性,扩展形式中的每一行都减少为单个项。
按类似的推理思路,我们求得
--------------------------------------------------------------[3.43]
现在,当 v 在由采样三角函数根据等式[3.38]定义的替代参考坐标系中表示时,如果我们重复上述过程。则结果是
-----------------------------------------------------------------[3.44]
将等式[3.43]和[3.44]的结果组合起来,我们就得到了下面的恒等式
------------------------[3.45]
这被称为Parseval定理。换言之,Parseval定理指出数据向量的长度可以在空间/时间域(第一个参考坐标系)或Fourier域(第二个参考坐标系)中计算。该定理的意义在于它建立了基于数据向量的平方长度的两个域之间的桥梁关系。在以后的章节中,我们将看到,向量的平方长度在许多物理场景下如何可能地被解释为信号中的能量数,以及平方Fourier系数如何可能地被解释为等价于Fourier级数模型项中项的能量数。 从这个意义上讲,Parseval 定理是一个能量守恒定理,因为它指的是,信号包含相同数量的能量,而不管该能量是在空间域/时间域,还是在Fourier域/频率域中计算的。
3.10 关联统计
Parseval 定理的另一种解释与统计有关。如果我们重新排列等式[3.45] 通过将常数项 ( ) 移到左侧,我们得到
------------------------------------------------------------[3.46]
现在,该等式的左侧被识别为正在建模的离散函数中 值的方差(variance)(译注:各个数据与平均数之差的平方的和的平均数),而等式的右侧是三角Fourier系数的振幅平方之和的一半。此外,由于Fourier系数的振幅平方与模型中的能量相关,该等式表明一组数据点的方差也可以被视为是信号中能量数。
一旦数据被视为 D 维空间中的向量,统计学的其他方面也呈现出几何视角。 例如,一组 值和相应的 值之间的相关性由 Pearson[píəsən]相关系数定义为
-------------------------------------------------------------[3.47]
如果我们将 值的集合设想为一个向量 ,那么我们可以通过从 的每个分量中减去平均 值来“归一化(normalize)” ,以产生一个新的向量 ',如下所示
-------------------------------------------------------------------------------------------------[3.48]
如果我们对 值执行相同的操作以生成归一化向量 ',则等式[3.47]分子被认为是 ' 和 ' 的内积。在类似的灵光一闪中,我们注意到这个等式的分母是这两个向量长度的乘积。简而言之,我们看到
------------------------------------------------------------------------------------------------[3.49]
换句话说,( , )数据值样本中两个变量之间的相关性等于D维空间中两个对应的归一化数据向量之间的夹角。在这种几何解释中,相关性是衡量两个数据向量在 D 维空间中指向同一方向的程度。如果向量正交,则数据不相关。
--------------图 3.7 两个数据集 和 之间统计相关性的图形描述 (说明了 D = 2 次测量的情况。两个测量值 绘制为左上面板中的数据向量,两个测量值
绘制在右上面板中。一对辅助轴
和
以样本均值为中心,以显示数据向量
和
。当两组辅助轴叠加时,如图所示,两个数据向量之间夹角 θ 的余弦值等于 Pearson 相关系数 r。) ---------------
类似的推理表明 在 上的最佳拟合线性回归(best-fitting linear regression)的斜率等于
----------------------------------------------------------------------------------------[3.50]
3.11 图像对比和复合光栅(Image Contrast and Compound Gratings)
一些物理量,如光强度,总是正的。 在这种情况下,正弦变化总是伴随着一个附加常数,以防止数量变为负值。 在光学中,光关于平均值的正弦变化的相对量称为“对比度(contrast)”,亮度 L 的正弦空间图案称为光栅(grating)。普遍接受的正弦光栅对比度定义是Michaelson[màikəlsən]公式
------------------------------------------------------------------------------[3.51]
计算对比度所需的各种参数只需通过检查光栅即可获得。为了解与Fourier分析的联系,可将此Michaelson公式重写为
------------------------------------------------------------------------------[3.52]
因此,在Fourier项中,对比度正是幅度(amplitude) m 对均值亮度(luminance) 的比率。
计算离散光学图像对比度的一般方法是基于显示器中所有像素的亮度值的标准偏差(deviation)。将对比度的定义应用于正弦光栅的情况
-----------------------------------------------------------[3.53]
我们调用 Parseval 定理得到
--------------------------------------------------------------------------[3.54]
左边的数量是平方像素强度的平均值,也称为亮度分布的二阶矩(second moment)。重排等式[3.54] 我们发现
---------------------------------------------------------------[3.55]
•(像素标准偏差)/(均值亮度) = Michaelson对比度。
回想一下,分布的方差等于二阶矩——一阶矩的平方,通过对等式 [3.54] 的两边取平方根并将每一边除以平均亮度,我们恢复Michaelson对比度。因此,我们得出结论,正弦光栅的对比度可以计算为像素亮度值的标准偏差,由平均亮度归一化。
如果 n 个不同谐波频率的光栅叠加产生复合光栅,则总和的亮度分布 为
-------------------------------------------------[3.56]
第 k 个分量的Michaelson对比度 , 因此,它的幅度是
。平均亮度等于组成光栅的平均亮度之和,但是我们应该如何定义这个复合光栅的对比度呢? 我们再次根据图像中所有像素的亮度值的标准偏差寻找一些度量,并求助于 Parseval 定理, ---------------------------------------------------------[3.57]
重排等式[3.57]我们得到
------------------------------------------------------[3.58]
左边是复合光栅像素亮度值的方差,右边是分量光栅幅值平方和的一半。
如果我们等式 [3.58] 的第 k 次谐波对比度的定义, ,则结果可以根据对比度向量
和构成复合光栅 L() 的分量光栅的平均亮度
来表示,
---------------------------------------[3.59]
该结果表明,与随机变量一样,当两个光栅加在一起得到复合光栅时,复合光栅的像素方差等于分量光栅的像素方差之和。对等式 [3.59] 的两边取平方根并除以平均亮度给出(在 Matlab 符号中)复合光栅对比度的简单公式,表示为像素值的归一化标准偏差,或作为分量幅度向量的范数,
---------------------------[3.60]
尽管通过执行上面的一维分析简化了问题,但结论也适用于任何方向的二维光栅。Matlab 程序“test_contrast.m”为由不同方向和空间频率的光栅制成的格子提供了图形演示。
3.12 闭合曲线形状的Fourier描述符(Fourier Descriptors of the Shape of a Closed Curve)
平面图形的轮廓形成一条闭合曲线,定义了图形和背景之间的边界。 Fourier分析可用于提供曲线形状的简洁描述(compact description),以及从曲线上的样本点插值(interplolating)平滑边界(smooth boundary)的过程。 这种方法在 John C. Russ(IEEE 出版社)的“图像处理手册(The Image Processing Handbook)”一书中和 Charles T. Zahn 和 Ralph Z. Roskies 的“Fourier Descriptors for Plane Closed Curves(平面闭合曲线的Fourier描述符)”一书中有简要描述,IEEE Transactions on Computers(计算机汇刊), 21卷,第 3 期,1972 年 3 月第269-281页。
Fourier描述符方法的形状描述的关键思想是将对象的边界视为复平面中的曲线。曲线上的每个点都由一个复数或相量指定,实部沿 轴绘制,虚部沿 轴绘制。在这种方法中隐含的是复数 = + i 是某些参数化(parametric)参数(例如时间)的函数。因此,实部 ()和虚部 () 都是 的函数,边界曲线描绘了这两个函数如何共同变化。
举一个简单的例子,如果 ()= a*cos() 和 ()= a*sin() 那么 = cos()+ i * sin()描述了一个在复平面上半径为a 的圆。如果实部和虚部的半径不同,则曲线变为方程描述的椭圆
()= a*cos(), ()= b*sin(), 和 ()= a cos()+ i * b * sin()。---------------[3.61]
其中,a 和 b 是半轴长度。
显然,这些方程是周期性的,因此通常将它们写成更通用的Fourier形式
(θ)= a*cos(θ), (θ)= b*sin(θ), 和 (θ)= a cos(θ)+ i * b * sin(θ)。------------[3.62]
其中,θ = 2πt/L ,L 是周期(即循迹一次路径所需的时间)且0 < θ < 2π 。图3.8所示。
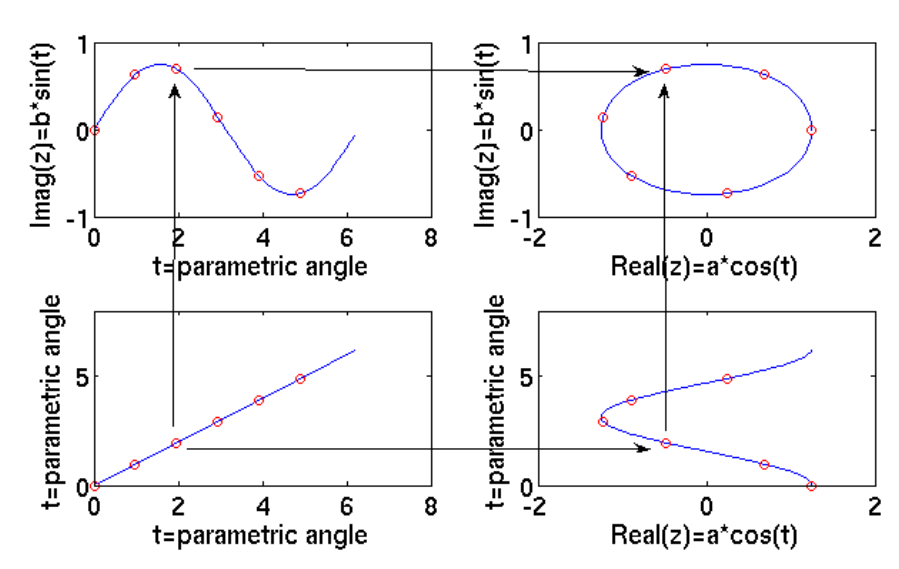
------------图 3.8复平面中椭圆的参数化生成。 连续线显示完整曲线; 6 个等距点的子集用符号表示。 箭头显示椭圆上的给定点与基础正弦曲线的关系-----------------
在这一点上很容易得出结论,参数角 θ 也是相量 的相位角Φ,正如 Matlab 表达式Φ = angle() 所返回的那样。然而,事实并非如此。角度θ和 Φ 之间的关系如图 3.9 所示为 tan(Φ)/tan(θ) = b/a。
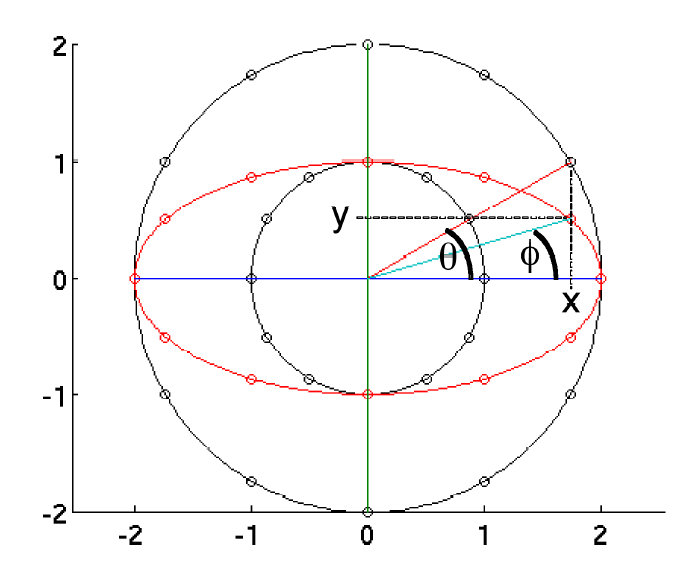
------------图 3.9 参数角θ与相量角 Φ 之间的关系。 外圆的半径为a,内圆的半径为b,椭圆的长半径为a,短半径为b。 椭圆上的点 具有实部 = a*cos(θ) 和虚部 = b*sin(θ )。 然而,其相位角 Φ 由 tan(Φ) = / = (b / a)*tan(θ) 给出。-----------------
这些观察的实际结果是椭圆的长轴(major axe)和短轴(minor axe)的知识对于从角度 Φ 推断角度 θ 是必要的。 我们需要做出这种推断,因为离散曲线 (θ) 的Fourier分析假设我们知道样本点θ 。 此外,要使用 Matlab 的标准 FFT 函数,我们需要样本角度在 0-2π周期内均匀分布。因此,实现椭圆或可能是任何其他曲线的Fourier描述的一个关键问题是——设计一种方法来推断沿对象边界的等距(equally spaced)样本角θ的向量。
在 Russ 的书中声称,等距采样点意味着复平面中采样点之间的距离相等。 这相当于说样本点组成的多边形是等边的。然而,这与图 1 所示的结构不一致,因为图 1 中采样点之间的距离不均匀。这些点在长轴末端附近的间距比在短轴末端附近的间距更近。多边形也不是等角的,因为参数角在长轴端点附近比在短轴端点附近间隔更近。
鉴于上述观察,处理任意图形的第一步似乎必须是椭圆的拟合,以便可以估计半轴 a、b。同时,我们还需要估计长轴的角度倾斜,因为对于一般椭圆,椭圆的参数方程为:
(θ)= a cos(θ + 2α)+ i * b * sin(θ)。----------------------------------[3.63]
其中α是主轴与水平面的夹角。给定一个拟合椭圆,我们可以从等距参数角θ的向量计算出非等距相量角Φ的向量。 然后使用此Φ向量将边界重新采样到一组相对较小的点上,这些点将平滑曲线表示为满足Fourier分析采样要求的多边形 。
等式中 (θ) 的Fourier谱(spectrum)。(3.63) 在 Matlab 中计算为FFT()/length()。 零频系数 给出了图形质心(centroid)的坐标。正基频的系数
和负基频的系数
将长轴(a)、短轴(b) 和倾斜角 (α) 编码为一对复数。椭圆的参数可以从这些复值,即具有下列等式的基本Fourier系数中恢复,这些等式为
,
,
---------------------------------------------[3.64]
综上所述,拟合椭圆的长轴长度 = 基本Fourier系数的大小之和;拟合椭圆的短轴长度 = 基本Fourier系数的大小差;拟合椭圆的倾斜度是两个系数相位角的平均值。高次谐波的系数调制椭圆以形成多边形的形状,并通过插值形成采样曲线的形状。
Fourier描述符的一种用途是量化图形既不是圆形也不是椭圆形的程度。纯圆形图形将由正基频处的单个Fourier系数来描述。纯椭圆形需要两个Fourier系数,分别对应正负基频。有很多方法可以描述椭圆图形偏离圆形的程度。受Fourier描述符启发的椭圆率指数是
椭圆率(Ellipticity) = --------------------------------[3.65]
这个等式可以在几何上解释为两种估算椭圆平均半径的方法的比值。分子是长轴和短轴的几何平均数,等于 (area表示面积) 。 因此,它表示与椭圆面积相同的圆的半径。 分母是长轴和短轴的 RMS(译注:Root Mean Square,均方根),它等于沿外接矩形对角线的椭圆半径。对于圆,a = b 且椭圆度 = 1。
任何非椭圆形状的特征在于在高次谐波处存在非零Fourier描述符。一种量化偏离椭圆率的方法是受 Parseval 定理的启发,该定理指出信号中的总能量由Fourier系数的平方和给出。因此,高次谐波中的平方系数之和除以基频处的平方系数之和,是图形非椭圆度的大小不变和倾斜不变度量。
内容来源:
<< Fourier Analysis for Beginners>> Larry N. Thibos