spark-RDD
Bin/spark-shell码的代码,用Eclipse码一下;(分别使用Java和Scala)
Rdd:容器,多台服务器共享的容器;
算子:transformaction算子和action算子;
- RDD
API文档:Scala:http://spark.apache.org/docs/latest/api/scala/index.html#package
API文档:java:http://spark.apache.org/docs/latest/api/java/index.html
API文档:Python:http://spark.apache.org/docs/latest/api/python/index.html
RDD官方的定义:A Resilient Distributed Dataset:一个弹性分布式的数据集合;
A list of partitions:它是一个partitions的集合(List)
A function for computing each split:用于计算每个拆分的函数;RDD里面的数据如何进行计算;(算子)
A list of dependencies on other RDDs:依赖于其他RDD的列表;一个算子无法实现,需要多个算子相互结合进行完成任务;多个算子是有顺序的;
Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):或者,键值RDD的分区程序(例如,说RDD是哈希分区的);凡是碰到了海量数据,提高查询效率就是两个方法:(树形结构和哈希;)
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):或者,计算每个拆分的首选位置列表(例如,HDFS文件的块位置)
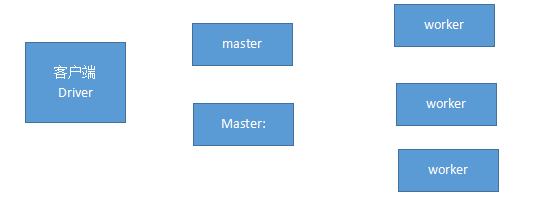
输入文件:数据流的来源;超级大的,大的到一个电脑放不下;它会拆解成多个电脑存储;
输出结果:(数据落地);存储计算的结果
中间的过程叫计算过程:
MR:
角度:是站在客户端角度,期望把数据放到一个无上限的容器中;(RDD),一得到容器就是CRUD;(Javase的容器,sql语句)
- 宽依赖和窄依赖
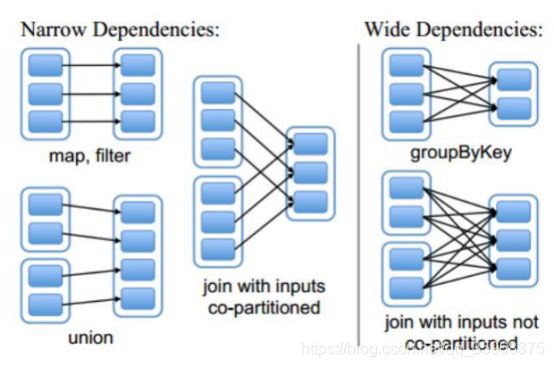
窄依赖:父RDD与子RDD,partition之前的关系是一对一(或者多对一)的;
宽依赖:父RDD与子RDD,partition之前的关系是一对多的;
作用:切割job,划分stage;Application,一个算子或者多个算子拆分(宽依赖和窄依赖)

是碰到一个宽依赖,就会切割一个stage
rdd里面存储的不是数据,而一个代码逻辑
数据只有在stage与stage之间的时候将数据落地,到底数据写到哪个小文件(Reduce输出)中,是由分区器决定的.
stage里面的并行度是由最后一个rdd来决定的. - RDD操作
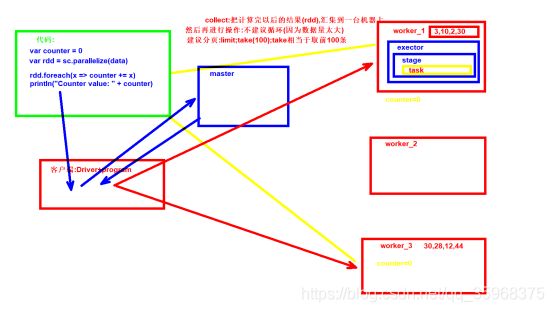
RDD的操作(容器的操作)叫算子;分为两类:transformations(转换)算子和action(行为)算子;如果RDD的返回值还是RDD那就是transformations算子,如果是非RDD那就是action算子;transformations算子直到遇到action算子的时候才会执行,否则永远不执行;(这种情况叫懒)
reduceByKey:action算子,它是Spark新增加的
- 算子
分为三类
RDD里面的元素是一个一个的
RDD里面的元素是一对一对的
RDD与RDD之间的所有操作
transformaction算子(转换,传输);返回值还是集合(RDD);(懒的)(MR中的Mapper)




action算子;返回值是非RDD;(MR中的Reduce)


rdd持久化


- [ ] 共享变量
广播变量
累加器
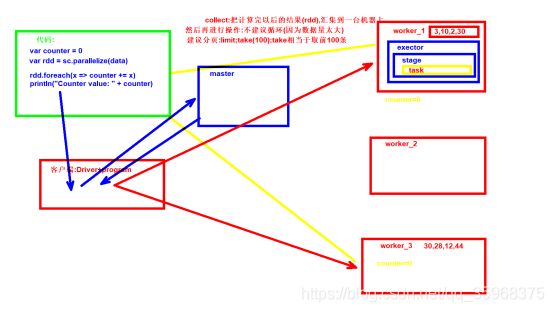
实战


- 代码-hw
java
package com.jinghangzz.spark.java;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.SparkSession;
/**
* RDDhw版本
*
* ~初始化Spark的配置
* ~准备一个输入
* ~做一些rdd的方法(算子);
* ~做一些输出
* ~关闭
* @author Tea-Big
*/
public class RddHw
{
public static void main(String[] args)
{
System.out.println("=====");
/* 告诉Spark,hadoop装到哪了 */
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
SparkConf conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddHw");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
JavaSparkContext jsc = new JavaSparkContext(conf);
/* sparkSession
* 建议新版本使用;
* */
SparkSession sparkSession = new SparkSession(jsc.sc());
/* 做一些操作了 */
/* 提供输入文件
* RDD---List
* */
JavaRDD textFile = jsc.textFile("e:/test/spark_data.txt");
/* action算子 */
long count = textFile.count() ;
System.out.println("--count-->" + count);
/* 取第一个 */
String first = textFile.first() ;
System.out.println("--first-->" + first);
/* filter算子
* 参数是接口
* */
JavaRDD filterRDD = textFile.filter(t -> t.contains("is"));
filterRDD.foreach( t -> System.out.println("==foreach===" + t));
/* map算子
* 原来的类型是String类型,经过map以后,期望变成Integer类型
* */
JavaRDD mapRDD = textFile.map(new Function()
{
@Override
public Integer call(String v1) throws Exception
{
/* 查看单词的数量 */
return v1.split(" ").length;
}
});
/* collect的返回值是List */
List collectList = mapRDD.collect();
/* 循环List */
for (Iterator iterator = collectList.iterator(); iterator.hasNext();)
{
Integer integer = (Integer) iterator.next();
System.out.println("===collect==" + integer);
}
/* lambda如何写,先看到方法的声明,通过匿名先提出来,然后再找成lambda表达式 */
// mapRDD.reduce(new Function2()
// {
// @Override
// public Integer call(Integer v1, Integer v2) throws Exception
// {
// return null;
// }
// });
/* 缩减 */
Integer reduceRes = mapRDD.reduce((t1,t2) -> t1 + t2) ;
System.out.println("===reduceRes==>" + reduceRes);
/* 关闭 */
jsc.stop();
}
}
Scala
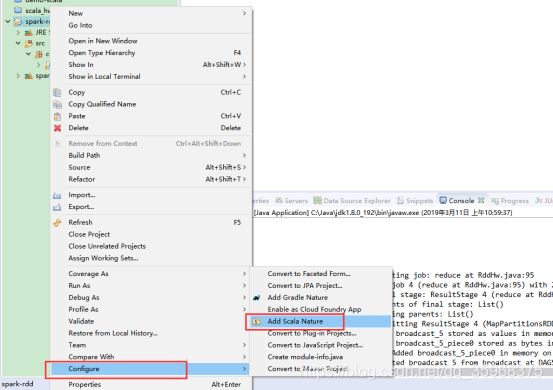
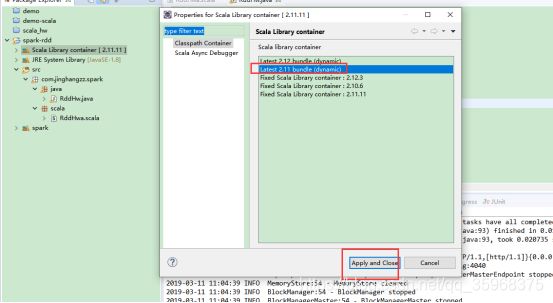
要让eclipse自带的scala版本和spark scala版本一致


package com.jinghangzz.spark.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
/**
* Spark--Scala Hw
*
* ~初始化Spark的配置
* ~准备一个输入
* ~做一些rdd的方法(算子);
* ~做一些输出
* ~关闭
*/
object RddHw {
def main(args: Array[String]): Unit = {
println("=====");
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
var conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddHw");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
var sc = new SparkContext(conf);
/* sparkSession
* 建议新版本使用;
* 一定要把sparkSession和SparkConf关联起来
* */
var sparkSession = SparkSession.builder().config(conf).getOrCreate();
/* 读取一个文件 */
var textFileRdd = sc.textFile("e:/test/spark_data.txt") ;
/* 计算总数 */
var count = textFileRdd.count() ;
println("===count==" + count)
/* 取第一个 */
var first = textFileRdd.first() ;
println("--first-->" + first);
/* filter算子
* filter:方法的参数是函数(方法);
* 函数:参数是String类型,返回值是Boolean类型
* */
var filterRdd = textFileRdd.filter(t => t.contains("is"));
filterRdd.foreach(println(_));
println("===filter=======")
/* map算子:就是把原来数据流的类型(String)变成另外一个类型(Integer) */
var mapRdd = textFileRdd.map(t => t.split(" ").size);
/* 它返回值是一个Integer数组 */
var collectArr = mapRdd.collect() ;
for(temp <- collectArr)
{
println("===collect=======" + temp)
}
println("===mapRdd=======")
println("===reduce=======")
/* 缩减 */
/*var reduceRes = mapRdd.reduce((t1,t2) => t1 + t2 );*/
/* 只适用于参数比较少,代码比较少; */
var reduceRes = mapRdd.reduce(_ + _);
println("===reduce=======" + reduceRes)
/* 要关闭流 */
sc.stop() ;
}
}
- Rdd
Spark输入的结果,和mr的reduce结果文件数量和名字特别像

Scala版本
package com.jinghangzz.spark.scala.rdd
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
/**
* 测试一些scala中的rdd相关的方法
*
* Application>Job>stage>task>partiton(hdfs上面的块block)
*/
object RddTest {
/**
* 测试一些生成RDD相关的方法
*/
def makeRdd(sc:SparkContext,sparksesion: SparkSession)
{
println("===makeRdd====");
/* 根据一个数组来生成RDD */
var arr = Array(4,5,6,7,8);
/* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* */
var arrRDD = sc.parallelize(arr);
println("==arrRDD==" + arrRDD);
/* 打印RDD里面的数据 */
//arrRDD.foreach(println(_));
arrRDD.foreach(t => println("==arrRDD=foreach===" + t))
/**
* 读取的是一个本地文件;
* 如果要是跑在集群上;把我们开发的application程序(代码)都要复制到worker(小弟)上,就意味着小弟的电脑上也得有此文件;
*
* 文件:e:/test/spark_data.txt
* 目录:e:/test/
* 通配符:e:/test/ *.txt
*/
var path = "e:/test/*.txt" ;
/* 一定得是active的namenode */
var hdfsPath = "hdfs://node-1:8020/spark/rdd/input/spark_data.txt" ;
/* 通过外部资源来创建RDD
* 本地文件系统
* hdfs
* hbase
*
* 参数1指的是路径的名字
* 参数2:指的是最小的分区数(partition);默认一个文件会被拆分成多少个块(block,hdfs),一个块对应最少一个分区
* 返回值得是RDD:文件的每一行是RDD的一个元素
*
* textfile文件支持一个目录,或者通配符
* */
var textFileRdd = sc.textFile(path);
textFileRdd.foreach(t => println("==textFileRdd=foreach===" + t))
/* wholeTextFiles:允许读取多个小文件;小文件合并,如果目录下面全部是小文件,建议使用此方法;
* 一个文件名+内容是一个元素
* t_1,_2,说明它是一个tuple;
* */
var wholeTextFileRdd = sc.wholeTextFiles(path);
wholeTextFileRdd.foreach(t => println(t._1 + "==wholeTextFiles=foreach===" + t._2))
/**
* 生成RDD的方法===mr的输入数据
* save方法====mr的输出数据
*/
var tarPath = "e:/test_1/" ;
/* 存储结果,也叫数据落地(mr的输出结果特别像)
* objectFile输出的结果看不懂,
* 输出文件的数量和默认的分区数有关
* */
//textFileRdd.saveAsObjectFile(tarPath);
/*
* 存储的是文本格式
* */
textFileRdd.saveAsTextFile(tarPath);
}
/**
* 测试所有的transformationRDD算子
* 有些我们在java数据流里面已经见过了
*/
def transformationRdd(sc:SparkContext,sparkSession: SparkSession)
{
/* 先生成一个新的RDD */
var list = List(6,2,1,3,8,2);
var list2 = List(2,1,4);
var listStr = List("this is a book","that is a cup");
var listRDD = sc.parallelize(list);
var list2RDD = sc.parallelize(list2);
var listStrRDD = sc.parallelize(listStr);
/* 打印一下rdd里面的数据 */
listRDD.collect().foreach(t => println("==listRDD==循环==" + t));
/* 测试一下map算子
* map算子就是把源rdd里面的元素经过一个函数转换为另外一个RDD,主要是元素的类型会发生变化;
* */
var mapRDD = listRDD.map(t => t + "==经过map新增加的==");
mapRDD.collect().foreach(t => println("==mapRDD==循环==" + t));
/*
* 测试一下Filter算子,
* filter算子是把源rdd里面的元素经过一个函数筛选,如果函数返回true,则留下,否则则删除,
* 此filter的参数是函数,要求只把>5的留下来
* 返回新的RDD;
* */
var filterRDD = listRDD.filter(t => t > 5);
filterRDD.collect().foreach(t => println("==filterRDD==循环==" + t));
/* flatMap:
* 和map类似,但是每一个输入项会映射出0个或者多个输出项
* */
var flatMapRDD = listStrRDD.flatMap(t => t.split(" "));
flatMapRDD.collect().foreach(t => println("==flatMapRDD==循环==" + t));
/* mapPartitions
* 参数是函数,
* 函数的参数是迭代器,输入是String类型,
* 函数的返回值是迭代器,输出U类型(自己定义)
* */
var mapPartitionRDD = listStrRDD.mapPartitions(t => {
/* 只保留包含is的行 */
t.filter(t => t.contains("book"));
});
mapPartitionRDD.collect().foreach(t => println("==mapPartitionRDD==循环==" + t));
/* 抽样:sample
* withReplacement:是否用什么替换
* 它是为RDD里面的每一个元素使用自带的RDD随机数种子,为每一个元素进行打分,
* 会把大于指定分类的元素保留:0.5分;
* */
var sampleRDD = listRDD.sample(false, 0.5);
sampleRDD.collect().foreach(t => println("==sampleRDD==循环==" + t));
/* 将两个RDD里面的元素联合起来,结合起来(并集) */
var unionRDD = listRDD.union(list2RDD);
unionRDD.collect().foreach(t => println("==unionRDD==循环==" + t));
/* intersection交集,重复的留下 */
var intersectionRDD = listRDD.intersection(list2RDD);
intersectionRDD.collect().foreach(t => println("==intersectionRDD==循环==" + t));
/* 去重
* listRDD:去掉此RDD里面的重复元素
* */
var distinctRDD = listRDD.distinct();
distinctRDD.collect().foreach(t => println("==distinctRDD==循环==" + t));
}
/**
* 第二个测试transformationRDD的方法
*/
def transformationRdd2(sc:SparkContext,sparkSession: SparkSession)
{
/* 准备一个RDD */
var listStr = List("this is a book","that is a cup");
var listRDD = sc.parallelize(listStr);
//groupByKey;
/* 准备一个RDD,这里面的元素得是tuple(键值对) */
var flatMapRDD = listRDD.flatMap(t => t.split(" "));
flatMapRDD.collect().foreach(t => println("==flatMapRDD==循环==" + t));
/* 要把这个单词进行处理;
* tuple:key:单词,value:数量
* 这是把原来RDD里面的字符串类型变成了tuple类型
* */
var mapRDD = flatMapRDD.map(t => (t,1));
mapRDD.collect().foreach(t => println("==mapRDD==循环==" + t));
/*------------------------------------------*/
/* 按照键分组;
* 返回值是RDD,类型是tuple:key是单词,值是:Iterator;就是默认值是为1(是我们自己放的)
* 和Mr中的Reduce是一样的
* */
var groupByKeyRDD = mapRDD.groupByKey();
groupByKeyRDD.collect().foreach(t =>
{
/* t:是一个tuple
* key是单词,值是迭代器
* */
var iter = t._2 ;
print(t._1 + "==groupByKey==");
iter.foreach(t => print(t + ","));
println();
});
/* reduceByKey */
var reduceByKeyRDD = mapRDD.reduceByKey( (t1,t2) => t1 + t2);
reduceByKeyRDD.collect().foreach(t => println("==reduceByKeyRDD==循环==" + t));
/* sortByKey
* 按照键排序,是按照ascII码排序的
* I II III IV V VI VII VIII VIIII
* true:升序
* false:降序
* */
var sortByKeyRDD = reduceByKeyRDD.sortByKey(false);
sortByKeyRDD.collect().foreach(t => println("==sortByKeyRDD==循环==" + t));
}
/**
* 第三个测试transformationRDD的方法
*/
def transformationRdd3(sc:SparkContext,sparkSession: SparkSession)
{
/*-------------aggregateByKey-----------*/
/* 准备一个容器,容器里面放的是tuple2;键和值都是整数类型 */
var arr1 = Array( (1,3),(3,5),(3,4),(2,1),(1,10),(2,8) );
/* 变成一个RDD
* parallelize:默认的partition数;2
* */
var arr1RDD = sc.parallelize(arr1,2);
arr1RDD.foreach(t => println("===arr1RDD==" + t))
/* 把每一个分区数给打印出来
* 参数1:是int类型
* 参数2:是Iterator类型
* */
var mapPartitionsWithIndexRDD = arr1RDD.mapPartitionsWithIndex((t1,t2) => {
/* 判断一个变量是什么类型 */
print(t1 + "==mapPartitionsWithIndex==" + t2.getClass.getSimpleName + "===" + t2 + "===");
t2.foreach(t1 => print(t1._1 + "--迭代器--" + t1._2 + ","));
println();
t2 ;
});
mapPartitionsWithIndexRDD.foreach(t => println(t._1 + "--mapPartitionsWithIndexRDD--->" + t._2))
/* 如果只有一个分区数,无效
*
* 调用aggregateByKey
* 第一个参数列表的第一个值是一个整数类型;
* 第二个参数列表的第一个值是一个函数;把RDD里面键相同的元素放到一块,要做一件事情,(最一个最大值);select key,max(value) from table group by key
* 第二个参数列表的第二个值是一个函数;在上面的函数完成以后,进行第二个函数;是每一个分区(partiton,分区的默认是值2)的最大值给相加
* 在下面的代码中,
* 每一个分区;
* 按照键分组,在每一个键中的一堆里面里面找出最大值(也包含初始值),
* 把每一个分区的最大值,相加;如果此分区木有最大值,则忽略
* */
var aggregateByKeyRDD = arr1RDD.aggregateByKey(6)((t1,t2) => Math.max(t1, t2), (t1,t2) => t1 + t2);
aggregateByKeyRDD.foreach(t => println(t._1 + "===aggregateByKeyRDD==" + t._2))
/* 准备两个容器 */
var arr2 = Array( (1,3),(2,5),(3,4) );
var arr3 = Array( (1,"a"),(3,"b"),(3,"c"));
var arr2RDD = sc.parallelize(arr2);
var arr3RDD = sc.parallelize(arr3);
/* 参数可以有多个RDD */
var cogroupRDD = arr2RDD.cogroup(arr3RDD);
/*
* 将两个RDD给连接起来,把键相同的放到一块;
* t:tuple
* t1:整数
* t2:又是tuple;
* t2_1:整数,t2_2是字符串
* */
cogroupRDD.foreach(t => println(t._1 + "==cogroupRDD==>" +
t._2.getClass.getSimpleName + "---" + t._2._1 + "====" + t._2._2)) ;
/*---------cartesian:笛卡尔集-------*/
/*-------repartition:重新打乱RDD里面的数据,再进行分区------*/
/*--------coalesce:聚结:----将两个分区里面的数据合并到一个分区中-----*/
var coalesceRDD = arr2RDD.coalesce(1);
coalesceRDD.foreach(t => println(t._1 + "===coalesceRDD==" + t._2))
}
/**
* 常见的action算子
*/
def actionsRDD(sc: SparkContext, sparkSession: SparkSession) = {
var arr = Array( (1,3),(2,3),(3,3),(2,5),(3,4) );
/* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* */
var arrRDD = sc.parallelize(arr);
/*--------把键相同的合并,并且计算一下每一个键的数量是多少----
* select key , count(*) from table group by key having count(*) > 2 ;
* ------*/
var countByKey = arrRDD.countByKey();
/* map如何循环 */
countByKey.foreach(t => println(t._1 + "--countByKey-->" + t._2))
}
/**
* main方法
*/
def main(args: Array[String]): Unit = {
println("-----");
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
var conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddTest");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
var sc = new SparkContext(conf);
/* sparkSession
* 建议新版本使用;
* 一定要把sparkSession和SparkConf关联起来
* */
var sparkSession = SparkSession.builder().config(conf).getOrCreate();
/* 这个是生成RDD */
//makeRdd(sc,sparkSession);
/* 测试transformation算子 */
//transformationRdd(sc, sparkSession);
//transformationRdd2(sc, sparkSession);
//transformationRdd3(sc, sparkSession);
actionsRDD(sc, sparkSession);
}
}
java版本
package com.jinghangzz.spark.java.rdd;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
/**
* 测试一些java的rdd常见的方法
*
* 将scala代码换成Java代码,一旦碰到了RDD里面的元素是键和值,(tuple),group,reduce一旦碰到了ByKey,就要把RDD换成JavaPairRDD
* @author Tea-Big
*
*/
public class RddTest
{
/**
* 生成RDD
*/
public static void makeRdd(JavaSparkContext sc,SparkSession sparkSession)
{
System.out.println("===makeRdd==");
/* 准备一个数组 */
List list = Arrays.asList(4,5,6,7,8);
/**
* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* 提供了两个方法,这叫重载
*/
JavaRDD arrRDD = sc.parallelize(list);
/* 循环RDD */
System.out.println("==arrRDD==>" + arrRDD);
arrRDD.foreach(t -> System.out.println("==arrRDD循环==" + t));
String path = "e:/test/spark_data.txt" ;
/* 一定得是active的namenode */
String hdfsPath = "hdfs://node-1:8020/spark/rdd/input/spark_data.txt" ;
/* 通过外部资源来创建RDD
* 本地文件系统
* hdfs
* hbase
*
* 参数1指的是路径的名字
* 参数2:指的是最小的分区数(partition)
* 返回值得是RDD:文件的每一行是RDD的一个元素
* */
JavaRDD textFileRdd = sc.textFile(path);
textFileRdd.foreach(t -> System.out.println("==textFileRdd=foreach===" + t)) ;
/* wholeTextFiles:允许读取多个小文件;小文件合并,如果目录下面全部是小文件,建议使用此方法;
* 一个文件名+内容是一个元素
* t_1,_2,说明它是一个tuple;
* tuple:总共有22个类
* */
JavaPairRDD wholeTextFiles = sc.wholeTextFiles(path);
wholeTextFiles.foreach(new VoidFunction>()
{
@Override
public void call(Tuple2 t) throws Exception
{
System.out.println(t._1 + "=接口==wholeTextFiles===>" + t._2);
}
});
wholeTextFiles.foreach(t -> System.out.println(t._1 + "==textFileRdd=foreach===" + t._2));
/**
* 生成RDD的方法===mr的输入数据
* save方法====mr的输出数据
*/
String tarPath = "e:/test_1/" ;
/* 存储结果,也叫数据落地(mr的输出结果特别像)
* objectFile输出的结果看不懂,
* 输出文件的数量和默认的分区数有关
* */
//textFileRdd.saveAsObjectFile(tarPath);
/*
* 存储的是文本格式
* */
textFileRdd.saveAsTextFile(tarPath);
}
/**
* 测试所有的transformationRDD算子
* 有些我们在java数据流里面已经见过了
* @param sc
* @param sparkSession
*/
public static void transformationRDD(JavaSparkContext sc, SparkSession sparkSession)
{
List list = Arrays.asList(6,2,1,3,8,2);
List list2 = Arrays.asList(2,1,4);
List listStr = Arrays.asList("this is a book","that is a cup");
JavaRDD listRDD = sc.parallelize(list);
JavaRDD list2RDD = sc.parallelize(list2);
JavaRDD listStrRDD = sc.parallelize(listStr);
/* 打印一下rdd里面的数据 */
listRDD.collect().forEach(t -> System.out.println("==listRDD==循环==" + t));
/* 测试一下map算子
* map算子就是把源rdd里面的元素经过一个函数转换为另外一个RDD,主要是元素的类型会发生变化;
* */
//JavaRDD mapRDD = listRDD.map(t -> t + "==经过map新增加的==");
JavaRDD mapRDD = listRDD.map(new Function()
{
@Override
public String call(Integer t) throws Exception
{
return t + "==经过map新增加的==";
}
});
mapRDD.collect().forEach(t -> System.out.println("==mapRDD==循环==" + t));
/*
* 测试一下Filter算子,
* filter算子是把源rdd里面的元素经过一个函数筛选,如果函数返回true,则留下,否则则删除,
* 此filter的参数是函数,要求只把>5的留下来
* 返回新的RDD;
* */
JavaRDD filterRDD = listRDD.filter(t -> t > 5);
filterRDD.collect().forEach(t -> System.out.println("==filterRDD==循环==" + t));
/* flatMap:
* 和map类似,但是每一个输入项会映射出0个或者多个输出项
* */
/*JavaRDD flatMapRDD = listStrRDD.flatMap(t ->
{
String [] strs = t.split(" ");
return Arrays.asList(strs).iterator();
});*/
JavaRDD flatMapRDD = listStrRDD.flatMap(new FlatMapFunction()
{
@Override
public Iterator call(String t) throws Exception
{
String [] strs = t.split(" ");
return Arrays.asList(strs).iterator();
}
});
flatMapRDD.collect().forEach(t -> System.out.println("==flatMapRDD==循环==" + t));
/* mapPartitions
* 参数是函数,
* 函数的参数是迭代器,输入是String类型,
* 函数的返回值是迭代器,输出U类型(自己定义)
* */
// TODO 这有问题,下节课说
JavaRDD mapPartitionRDD = listStrRDD.mapPartitions(new FlatMapFunction, String>()
{
@Override
public Iterator call(Iterator t) throws Exception
{
String value = t.next() ;
// if(!value.contains("book"))
// {
// /* 移除掉 */
// t.remove();
// }
return t;
}
});
// var mapPartitionRDD = listStrRDD.mapPartitions(t -> {
// /* 只保留包含is的行 */
// t.filter(t -> t.contains("book"));
// });
mapPartitionRDD.collect().forEach(t -> System.out.println("==mapPartitionRDD==循环==" + t));
/* 抽样:sample
* withReplacement:是否用什么替换
* 它是为RDD里面的每一个元素使用自带的RDD随机数种子,为每一个元素进行打分,
* 会把大于指定分类的元素保留:0.5分;
* */
JavaRDD sampleRDD = listRDD.sample(false, 0.5);
sampleRDD.collect().forEach(t -> System.out.println("==sampleRDD==循环==" + t));
/* 将两个RDD里面的元素联合起来,结合起来(并集) */
JavaRDD unionRDD = listRDD.union(list2RDD);
unionRDD.collect().forEach(t -> System.out.println("==unionRDD==循环==" + t));
/* intersection交集,重复的留下 */
JavaRDD intersectionRDD = listRDD.intersection(list2RDD);
intersectionRDD.collect().forEach(t -> System.out.println("==intersectionRDD==循环==" + t));
/* 去重
* listRDD:去掉此RDD里面的重复元素
* */
JavaRDD distinctRDD = listRDD.distinct();
distinctRDD.collect().forEach(t -> System.out.println("==distinctRDD==循环==" + t));
}
/**
* 测试所有的transformationRDD算子
* 有些我们在java数据流里面已经见过了
*
* RDD里面的元素是一对一对的,要用mapToPair
* @param sc
* @param sparkSession
*/
public static void transformationRDD2(JavaSparkContext sc, SparkSession sparkSession)
{
/* 准备一个RDD */
List listStr = Arrays.asList("this is a book","that is a cup");
JavaRDD listRDD = sc.parallelize(listStr);
//groupByKey;
/* 准备一个RDD,这里面的元素得是tuple(键值对) */
JavaRDD flatMapRDD = listRDD.flatMap(t -> Arrays.asList(t.split(" ")).iterator());
flatMapRDD.collect().forEach(t -> System.out.println("==flatMapRDD==循环==" + t));
/* 要把这个单词进行处理;
* tuple:key:单词,value:数量
* 这是把原来RDD里面的字符串类型变成了tuple类型
* */
//JavaRDD> mapRDD = flatMapRDD.map(t -> new Tuple2(t,1));
/* 在JAVA中,map==map
* Pair:是一对一对的意思
* JavaPairRDD泛型是Tuple的泛型
* */
JavaPairRDD mapRDD = flatMapRDD.mapToPair(t -> new Tuple2(t,1));
mapRDD.collect().forEach(t -> System.out.println("==mapRDD==循环==" + t));
/*------------------------------------------*/
/* 按照键分组;
* 返回值是RDD,类型是tuple:key是单词,值是:Iterator;就是默认值是为1(是我们自己放的)
* 和Mr中的Reduce是一样的
* */
JavaPairRDD> groupByKeyRDD = mapRDD.groupByKey();
groupByKeyRDD.collect().forEach(t ->
{
/* t:是一个tuple
* key是单词,值是迭代器
* */
Iterable iter = t._2 ;
System.out.print(t._1 + "==groupByKey==");
for (Iterator iterator = iter.iterator(); iterator.hasNext();)
{
Integer inter = (Integer) iterator.next();
System.out.print(inter + ",");
}
//iter.foreach(t -> print(t + ","));
System.out.println();
});
/* reduceByKey */
JavaPairRDD reduceByKeyRDD = mapRDD.reduceByKey( (t1,t2) -> t1 + t2);
reduceByKeyRDD.collect().forEach(t -> System.out.println("==reduceByKeyRDD==循环==" + t));
//
// /* sortByKey
// * 按照键排序,是按照ascII码排序的
// * I II III IV V VI VII VIII VIIII
// * true:升序
// * false:降序
// * */
JavaPairRDD sortByKeyRDD = reduceByKeyRDD.sortByKey(false);
sortByKeyRDD.collect().forEach(t -> System.out.println("==sortByKeyRDD==循环==" + t));
}
/**
* 测试所有的transformationRDD算子
* 有些我们在java数据流里面已经见过了
* @param sc
* @param sparkSession
*/
public static void transformationRDD3(JavaSparkContext sc, SparkSession sparkSession)
{
/*-------------aggregateByKey-----------*/
/* 准备一个容器,容器里面放的是tuple2;键和值都是整数类型 */
//var arr1 = Array( (1,3),(3,5),(3,4),(2,1),(1,10),(2,8) );
List> arr1 = Arrays.asList(
new Tuple2(1,3),
new Tuple2(3,5),
new Tuple2(3,4),
new Tuple2(2,1),
new Tuple2(1,10),
new Tuple2(2,8)
);
/* 变成一个RDD
* parallelize:默认的partition数;2
* */
JavaRDD> arr1RDD = sc.parallelize(arr1,2);
arr1RDD.foreach(t -> System.out.println("===arr1RDD==" + t));
/*
* maptoPair==Scala中的map方法
* map:把一个元素换成另外一个元素
* */
JavaPairRDD maptoPairRDD = arr1RDD.mapToPair(t -> t);
/* 把每一个分区数给打印出来
* 参数1:是int类型,第几个分区;
* 参数2:是Iterator类型;把第几个分区的所有整数列出来
* */
JavaRDD> mapPartitionsWithIndexRDD = arr1RDD.mapPartitionsWithIndex((t1,t2) -> {
/* 判断一个变量是什么类型 */
System.out.print(t1 + "==mapPartitionsWithIndex==" + t2.getClass().getSimpleName() + "===" + t2 + "===");
//t2.foreach(t1 -> print(t1._1 + "--迭代器--" + t1._2 + ","));
for (Iterator iterator = t2; iterator.hasNext();)
{
Tuple2 tuple2 = (Tuple2) iterator.next();
System.out.print(tuple2._1 + "--迭代器--" + tuple2._2 + ",");
}
System.out.println();
return t2 ;
},false);
mapPartitionsWithIndexRDD.foreach(t -> System.out.println(t._1 + "--mapPartitionsWithIndexRDD--->" + t._2));
/* 如果只有一个分区数,无效
*
* 调用aggregateByKey
* 第一个参数列表的第一个值是一个整数类型;
* 第二个参数列表的第一个值是一个函数;把RDD里面键相同的元素放到一块,要做一件事情,(最一个最大值);select key,max(value) from table group by key
* 第二个参数列表的第二个值是一个函数;在上面的函数完成以后,进行第二个函数;是每一个分区(partiton,分区的默认是值2)的最大值给相加
* 在下面的代码中,
* 每一个分区;
* 按照键分组,在每一个键中的一堆里面里面找出最大值(也包含初始值),
* 把每一个分区的最大值,相加;如果此分区木有最大值,则忽略
* */
JavaPairRDD aggregateByKeyRDD = maptoPairRDD.aggregateByKey(6 , (t1,t2) -> Math.max(t1, t2), (t1,t2) -> t1 + t2);
aggregateByKeyRDD.foreach(t -> System.out.println(t._1 + "===aggregateByKeyRDD==" + t._2)) ;
/* 准备两个容器 */
// var arr2 = Array( (1,3),(2,5),(3,4) );
// var arr3 = Array( (1,"a"),(3,"b"),(3,"c"));
List> arr2 = Arrays.asList(
new Tuple2(1,3),
new Tuple2(2,5),
new Tuple2(3,4)
);
List> arr3 = Arrays.asList(
new Tuple2(1,"a"),
new Tuple2(3,"b"),
new Tuple2(3,"c")
);
JavaRDD> arr2RDD = sc.parallelize(arr2);
JavaRDD> arr3RDD = sc.parallelize(arr3);
JavaPairRDD maptoPair2RDD = arr2RDD.mapToPair(t -> t);
JavaPairRDD maptoPair3RDD = arr3RDD.mapToPair(t -> t);
/* 参数可以有多个RDD
* cogroup:共享
* */
JavaPairRDD, Iterable>> cogroupRDD = maptoPair2RDD.cogroup(maptoPair3RDD);
/*
* 将两个RDD给连接起来,把键相同的放到一块;
* t:tuple
* t1:整数
* t2:又是tuple;
* t2_1:整数,t2_2是字符串
* */
cogroupRDD.foreach(t -> System.out.println(t._1 + "==cogroupRDD==>" +
t._2.getClass().getSimpleName() + "---" + t._2._1 + "====" + t._2._2)) ;
// /*---------cartesian:笛卡尔集-------*/
// /*-------repartition:重新打乱RDD里面的数据,再进行分区------*/
// /*--------coalesce:聚结:----将两个分区里面的数据合并到一个分区中-----*/
JavaRDD> coalesceRDD = arr2RDD.coalesce(1);
coalesceRDD.foreach(t -> System.out.println(t._1 + "===coalesceRDD==" + t._2)) ;
}
/**
* 常见的action算子
* @param sc
* @param sparkSession
*/
public static void actionsRDD(JavaSparkContext sc, SparkSession sparkSession)
{
//var arr = Array( (1,3),(2,3),(3,3),(2,5),(3,4) );
List> arr = Arrays.asList(
new Tuple2(1,3),
new Tuple2(2,3),
new Tuple2(3,3),
new Tuple2(2,5),
new Tuple2(3,4)
);
/* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* */
JavaRDD> arrRDD = sc.parallelize(arr);
JavaPairRDD maptoPairRDD = arrRDD.mapToPair(t -> t);
/*--------把键相同的合并,并且计算一下每一个键的数量是多少----
* select key , count(*) from table group by key having count(*) > 2 ;
* ------*/
Map countByKey = maptoPairRDD.countByKey();
/* map如何循环 */
countByKey.forEach((t1,t2) -> System.out.println(t1 + "--countByKey-->" + t2));
}
public static void main(String[] args)
{
System.out.println("==main===");
/* 告诉Spark,hadoop装到哪了 */
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
SparkConf conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddHw");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
JavaSparkContext jsc = new JavaSparkContext(conf);
/* sparkSession
* 建议新版本使用;
* */
SparkSession sparkSession = new SparkSession(jsc.sc());
/* 调用生成RDD相关的方法 */
//makeRdd(jsc,sparkSession);
/* 调用一些常见的transformation算子 */
//transformationRDD(jsc, sparkSession);
//transformationRDD2(jsc, sparkSession);
//transformationRDD3(jsc, sparkSession);
actionsRDD(jsc, sparkSession);
/* 多线程 */
/*new Thread(() -> {
for(int i = 0 ; i < 10 ; i ++)
{
System.out.println(i + "----->" + Thread.currentThread().getName());
try
{
Thread.sleep(100);
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
}).start();
System.out.println("===main方法结束===");*/
}
}
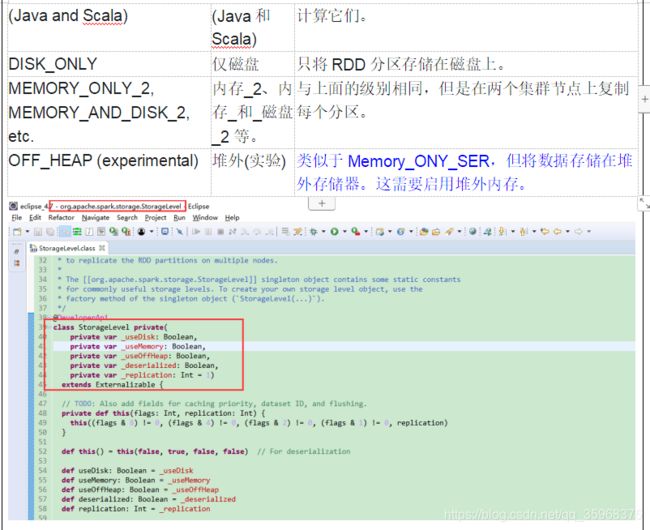
- 缓存级别
scala版本
package com.jinghangzz.spark.scala.rdd
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
/**
* ~数据量得超级大
*/
object RddPersist {
/**
* 木有使用RDD持久化
* 耗时性能对比
*/
def rddPersistNo(sc:SparkContext,sparksesion: SparkSession)
{
var arrRDD = sc.textFile("e:/test/spark_data.txt");
//arrRDD.foreach(t => println("===arrRDD==" + t));
/* 先调用一下action算子 */
println("=arrRDD.count()===" + arrRDD.count()) ;
/* 程序执行耗时多久 */
/* currentTimeMillis:是获取当前的时间戳 */
var st = System.currentTimeMillis() ;
/* 调用两次 */
println("=arrRDD.count()===" + arrRDD.count()) ;
var ed = System.currentTimeMillis() ;
println("===rddPersistNo==耗时(毫秒)==" + (ed -st)) ;
}
/**
* 使用了RDD持久化
*/
def rddPersistYes(sc:SparkContext,sparksesion: SparkSession)
{
/* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* */
var arrRDD = sc.textFile("e:/test/spark_data.txt");
//arrRDD.foreach(t => println("===arrRDD==" + t));
/* 存储RDD
* 选择的存储级别是内存和磁盘
* */
arrRDD = arrRDD.persist(StorageLevel.MEMORY_ONLY);
/* 存储的直接调用cache;只往内存中放;相当于StorageLevel.MEMORY_ONLY */
//arrRDD = arrRDD.cache() ;
/* 先调用一下action算子 */
println("=arrRDD.count()===" + arrRDD.count()) ;
/* 程序执行耗时多久 */
/* currentTimeMillis:是获取当前的时间戳 */
var st = System.currentTimeMillis() ;
/* 调用两次 */
println("=arrRDD.count()===" + arrRDD.count()) ;
var ed = System.currentTimeMillis() ;
println("==rddPersistYes==耗时(毫秒)==" + (ed -st)) ;
}
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
var conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddTest");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
var sc = new SparkContext(conf);
/* sparkSession
* 建议新版本使用;
* 一定要把sparkSession和SparkConf关联起来
* */
var sparkSession = SparkSession.builder().config(conf).getOrCreate();
/* 测试缓存要单独执行,因为两个一块执行Spark内部会有缓存机制 */
/* 50毫秒;17M,148毫秒 */
rddPersistNo(sc, sparkSession);
/* 39毫秒;17M,40毫秒 */
//rddPersistYes(sc, sparkSession);
}
}
java版本
package com.jinghangzz.spark.java.rdd;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.storage.StorageLevel;
/**
* RDD持久化
* @author Tea-Big
*/
public class RddPersist
{
/**
* 木有使用RDD持久化 耗时性能对比
*/
public static void rddPersistNo(JavaSparkContext sc,SparkSession sparkSession)
{
JavaRDD arrRDD = sc.textFile("e:/test/spark_data - 副本.txt");
//arrRDD.foreach(t => println("===arrRDD==" + t));
/* 先调用一下action算子 */
System.out.println("=arrRDD.count()===" + arrRDD.count()) ;
/* 程序执行耗时多久 */
/* currentTimeMillis:是获取当前的时间戳 */
long st = System.currentTimeMillis();
/* 调用两次 */
System.out.println("=arrRDD.count()===" + arrRDD.count());
long ed = System.currentTimeMillis();
System.out.println("===rddPersistNo==耗时(毫秒)==" + (ed - st));
}
/**
* 木有使用RDD持久化 耗时性能对比
*/
public static void rddPersistYes(JavaSparkContext sc,SparkSession sparkSession)
{
/*
* 并行化生成RDD 参数2:为分区数;默认值是2个
*/
JavaRDD arrRDD = sc.textFile("e:/test/spark_data - 副本.txt");
// arrRDD.foreach(t => println("===arrRDD==" + t));
/*
* 存储RDD 选择的存储级别是内存和磁盘
* scala原来是属性,在java中是一个方法
*/
arrRDD = arrRDD.persist(StorageLevel.MEMORY_AND_DISK());
/* 存储的直接调用cache;只往内存中放;相当于StorageLevel.MEMORY_ONLY */
// arrRDD = arrRDD.cache() ;
/* 先调用一下action算子 */
System.out.println("=arrRDD.count()===" + arrRDD.count());
/* 程序执行耗时多久 */
/* currentTimeMillis:是获取当前的时间戳 */
long st = System.currentTimeMillis();
/* 调用两次 */
System.out.println("=arrRDD.count()===" + arrRDD.count());
long ed = System.currentTimeMillis();
System.out.println("==rddPersistYes==耗时(毫秒)==" + (ed - st));
}
/**
* 主函数,入口函数
* @param args
*/
public static void main(String[] args)
{
System.out.println("=====");
System.out.println("==main===");
/* 告诉Spark,hadoop装到哪了 */
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
SparkConf conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddHw");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
JavaSparkContext jsc = new JavaSparkContext(conf);
/* sparkSession
* 建议新版本使用;
* */
SparkSession sparkSession = new SparkSession(jsc.sc());
/* 调用两个方法 */
rddPersistNo(jsc, sparkSession);
rddPersistYes(jsc, sparkSession);
}
}
- 广播变量
Scala版本
package com.jinghangzz.spark.scala.rdd
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
/**
* 共享变量
* 广播变量
* 累加器
*/
object RddShareVar {
/**
* 测试存储级别
*/
def rddPersistSave(sc:SparkContext,sparksesion: SparkSession)
{
var arr = Array(4,5,6,7,8);
/* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* */
var arrRDD = sc.parallelize(arr);
var i = 10 ;
/* 广播变量:通知;广播变量不能修改 */
var broadcast = sc.broadcast(200);
/* 累加器:就是为了让你修改值的,让worker修改值的 */
var longAccumulator = sc.longAccumulator("test");
arrRDD.foreach(t => {
println(i + "===arrRDD==" + t)
i = i + 20 ;
/* 广播变量不能修改; */
/* 修改累加器的值 */
longAccumulator.add(1);
/* 在RDD worker读取的值是不正确的,
* 因为有多个分区,有多个worker,但是在客户端或者最终结束的时候是正确的 */
println("==foreach==" + longAccumulator.value);
});
/* 如果只定义一个变量,在foreatch修改,在外面重新打印是看不到的; */
println(broadcast.value + "=====" + broadcast.id + "--打印值--" + i )
/* 打印累加器的值 */
println("===longAccumulator==" + longAccumulator.value);
}
/**
* 获取数据;
*/
def rddPersistLoad(sc:SparkContext,sparksesion: SparkSession)
{
}
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
var conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddTest");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
var sc = new SparkContext(conf);
/* sparkSession
* 建议新版本使用;
* 一定要把sparkSession和SparkConf关联起来
* */
var sparkSession = SparkSession.builder().config(conf).getOrCreate();
/* 保存 */
rddPersistSave(sc, sparkSession);
}
}
Java版本
package com.jinghangzz.spark.java.rdd;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.util.LongAccumulator;
/**
* RDD持久化
* @author Tea-Big
*/
public class RddShareVar
{
/**
* 测试共享变量
* 广播变量:不能修改
* 累加器;
*/
public static void rddPersistSave(JavaSparkContext sc,SparkSession sparkSession)
{
/*var arr = Array(4,5,6,7,8);*/
List arr = Arrays.asList(4,5,6,7,8);
/* 并行化生成RDD
* 参数2:为分区数;默认值是2个
* */
JavaRDD arrRDD = sc.parallelize(arr);
final int i = 10 ;
/* 广播变量:通知;广播变量不能修改 */
Broadcast broadcast = sc.broadcast(200);
/* 累加器:就是为了让你修改值的,让worker修改值的 */
LongAccumulator longAccumulator = sc.sc().longAccumulator();
/**
* lambda表达是匿名类的简写方式,执行的是接口中的某一个抽象方法;
* 在匿名类规定,如果使用类外部的变量必须加final;(不可能更改)
* 而我们的这个例子就是要在匿名类中修改变量值
*/
arrRDD.foreach(t -> {
System.out.println(i + "===arrRDD==" + t) ;
//i = i + 20 ;
/* 广播变量不能修改; */
/* 修改累加器的值 */
longAccumulator.add(1);
/* 在RDD worker读取的值是不正确的,
* 因为有多个分区,有多个worker,但是在客户端或者最终结束的时候是正确的 */
System.out.println(broadcast.value() + "==foreach==" + longAccumulator.value());
});
/* 如果只定义一个变量,在foreatch修改,在外面重新打印是看不到的; */
System.out.println(broadcast.value() + "=====" + broadcast.id() + "--打印值--" + i ) ;
/* 打印累加器的值 */
System.out.println("===longAccumulator==" + longAccumulator.value());
}
/**
* 主函数,入口函数
* @param args
*/
public static void main(String[] args)
{
System.out.println("=====");
System.out.println("==main===");
/* 告诉Spark,hadoop装到哪了 */
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
SparkConf conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddHw");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
JavaSparkContext jsc = new JavaSparkContext(conf);
/* sparkSession
* 建议新版本使用;
* */
SparkSession sparkSession = new SparkSession(jsc.sc());
/* 调用两个方法 */
rddPersistSave(jsc, sparkSession);
}
}
- RDD例子
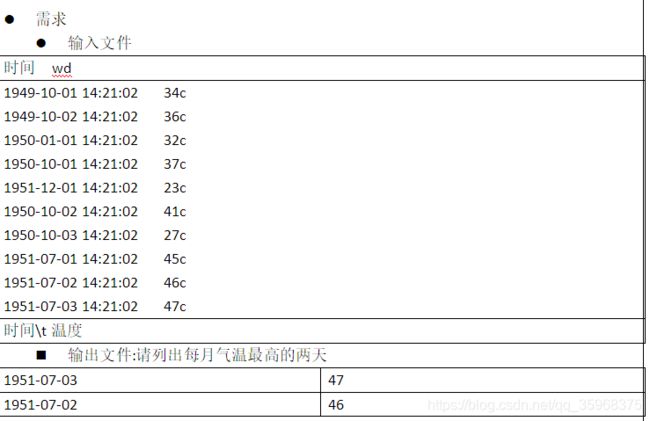
代码:
package com.jinghangzz.spark.java.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
/**
* 天气的例子:需求参见MR的第二个例子
* 回忆词频MR的开发流程;
* ~确认输入文件
* ~确认输出文件
* ~尽量的将输入文件的内容往输出文件的内容上靠;
*
* ~搭建MR的流程主框架;
* ~Mapper里面的代码:取到文件的一行内容,然后拆分,mapper输出键是词频,输出值是1;
* ~shuffler:把mapper输出结果,把key相同的合并;(洗牌);(洗牌是系统自动的)
* ~reduce:把shuffler的结果,key相同,所有的键是一个迭代器,取到所有的值,看情况进行处理;相加
* ~reduce的结果直接输出到一个hdfs的文件路径上
*
* ~什么时候把天整丢了
* ~Tuple2:groupByKey,key肯定得是年+月,值:变成一个tuple2,或者是Map
*
* ~最后一个:打印的时候需要的是有三个元素,一个是年月,温度,年月日;
* Tuple2,tuple3;因为map2PairRDD这里面只有两个泛型;
* 只能选择Tuple2里面套了一个Tuple2;
* @author Tea-Big
*/
public class WeatherDemo
{
/**
* 计算天气的流程
* @param jsc
* @param sparkSession
*/
private static void weatherRdd(JavaSparkContext sc, SparkSession sparkSession)
{
String path = "e:/test/weather.txt" ;
/*=========将文本文件中的内容读到RDD中==========*/
JavaRDD textFileRDD = sc.textFile(path);
textFileRDD.foreach(t -> System.out.println("==textFileRDD==" + t));
/*=======Mapper的输出:========
* 键:自定义类,年+月(我们要按照它分组);
* 值:温度
* 第三个:年月日
*
* 要把原来的一行内容变成键和值
*
* mapRDD:里面装的是一个Tuple2,它的第二个元素里面放的也是Tuple2
* */
JavaRDD>> mapRDD = textFileRDD.map(t ->
{
/*
* t=====1949-10-01 14:21:02 34c;
* 如何取年,月
* */
String[] lines = t.split("\t");
/*
* lines[0]===1949-10-01 14:21:02
* lines[1]===温度;34c
* */
String date = lines[0].split(" ")[0];
int hot = Integer.valueOf(lines[1].substring(0, lines[1].indexOf("c"))) ;
String key = date.substring(0, date.lastIndexOf("-"));
//System.out.println(key + "====>" + date + "=====>" + hot);
/* 键是年+月
* 值是:温度
* */
return new Tuple2>(key, new Tuple2(hot, date));
});
mapRDD.foreach(t -> System.out.println("==mapRDD==" + t));
/*----------分组(按照键分组)--------*/
JavaPairRDD> mapToPairRDD = mapRDD.mapToPair(t -> t);
JavaPairRDD>> groupByKeyRDD = mapToPairRDD.groupByKey() ;
/*
* (1949-10,[34, 36])
* (1950-10,[37, 41, 27])
* */
groupByKeyRDD.foreach(t -> System.out.println("==groupByKeyRDD==" + t));
/* 按照键排序 */
JavaPairRDD>> sortByKeyRDD = groupByKeyRDD.sortByKey() ;
/* 温度降序
* 前题:每一个月份的温度最多有多少个?(最多31个);数据量不会太多,或者一个JDK,虚拟机就可以放下
* ~先把每个月的温度放到一个集合中(最多31个)
* ~利用Collections的方法,将List中的元素排序;(降序)
* ~排序后的List循环,取两个放到一个新的集合中
* ~返回的元素,键是年-月,值:新的命令(两个最高温度的迭代器)
* */
JavaPairRDD>> mapToPair2RDD = sortByKeyRDD.mapToPair(t ->
{
/* 对每一个组多个值,进行排序 */
String key = t._1 ;
Iterable> iter = t._2 ;
/* 为了实现key对应的值排序,把所有的值放到一个集合中 */
List> arrList = new ArrayList>();
//System.out.print(key + "===mapToPair==>");
for (Iterator iterator = iter.iterator(); iterator.hasNext();)
{
Tuple2 hot = (Tuple2) iterator.next();
//System.out.print(hot + ",");
/* 把所有的温度放到一个集合中 */
arrList.add(hot);
}
//System.out.println();
//System.out.println("==排序之前==" + arrList);
/* 集合里面有一个方法叫排序
* 两个参数:
* 第二个参数是比较器,将集合中两个元素进行比较,返回值:0相等,大于0,o1大,小于0,o2大
* int compare(T o1, T o2);
* 要取用tuple2的_1,因为这里面放提温度
* */
Collections.sort(arrList,(t1,t2) -> t2._1 - t1._1);
//System.out.println("==排序之后==" + arrList);
/* 复制集合元素
* 参数1:dest:目标
* 参数2:src:来源
* */
List> list = new ArrayList>();
int i = 0 ;
for (Iterator iterator = arrList.iterator(); iterator.hasNext();)
{
Tuple2 hotTemp = (Tuple2) iterator.next();
list.add(hotTemp);
if( i >= 1)
{
break ;
}
i ++ ;
}
//System.out.println("==取前两个==" + list);
return new Tuple2>>(key, list.iterator());
});
mapToPair2RDD.foreach(t ->
{
// StringBuffer sb = new StringBuffer();
// for (; t._2.hasNext();)
// {
// Integer type = (Integer) t._2.next();
// sb.append(type + ",") ;
// }
// System.out.println(t._1 + "==mapToPair2RDD==" + sb);
for (; t._2.hasNext();)
{
Tuple2 type = (Tuple2) t._2.next();
System.out.println(t._1 + "--最终结果->" + type._1 + "---->" + type._2);
}
});
/* 存储结果,聚合以后的结果 */
mapToPair2RDD.saveAsTextFile("e:/test/weather");
}
public static void main(String[] args)
{
System.out.println("==明代宗(朱祁钰)(景泰)==");
/* 告诉Spark,hadoop装到哪了 */
System.setProperty("hadoop.home.dir", "E:\\帮助文档\\大数据\\hadoop");
/* 初始化一个Spark相关的配置信息 */
SparkConf conf = new SparkConf() ;
/* 为一个应用程序(application)起一个名字,名字建议是英文
* 名字一般和包含main方法的类名一样;
* bin/spark-submit --name后面的内容
* */
conf.setAppName("RddHw");
/*
* bin/spark-submit --master后面的内容;
* 可以是:local[5,2],spark://node-1:7077,yarn,mesos,
*/
conf.setMaster("local[2]");
/* 初始化Spark
* 参数是SparkConf;这里面存储了一些和Spark配置相关的信息
* JavaSparkContext:建议老版本使用
* */
JavaSparkContext jsc = new JavaSparkContext(conf);
/* sparkSession
* 建议新版本使用;
* */
SparkSession sparkSession = new SparkSession(jsc.sc());
weatherRdd(jsc,sparkSession);
}
``
- 总结
spark支持三种客户链接(代码编写);多个编程语言语法不一样,思路是一样的