现代机器学习算法:优势和劣势
【翻译 Modern Machine Learning Algorithms: Strengths and Weaknesses】
在本指南中,我们将对现代机器学习算法进行实用、简洁的介绍。虽然存在其他此类列表,但它们并没有真正解释每种算法的实际权衡,我们希望在这里这样做。我们将根据我们的经验讨论每种算法的优缺点。
对机器学习算法进行分类是很棘手的,有几种合理的方法;它们可以分为生成/判别、参数/非参数、监督/无监督等。
例如,Scikit-Learn 的文档页面按算法的学习机制对算法进行分组。 这将产生以下类别:
- 广义线性模型
- 支持向量机
- 最近邻
- 决策树
- 神经网络
- 等等…
然而,根据我们的经验,这并不总是对算法进行分组的最实用方法。这是因为对于应用机器学习,你通常不会想,“天哪,我今天想训练一台支持向量机!
相反,您通常有一个最终目标,例如预测结果或对观察结果进行分类。
因此,我们想介绍另一种对算法进行分类的方法,即通过机器学习任务。
天下没有免费的午餐
在机器学习中,有一种叫做“没有免费午餐”的定理。简而言之,它指出没有一种算法最适合每个问题,它与监督学习(即预测建模)尤其相关。
例如,你不能说神经网络总是比决策树好,反之亦然。有许多因素在起作用,例如数据集的大小和结构。
因此,您应该为您的问题尝试许多不同的算法,同时使用保留的“测试集”数据来评估性能并选择获胜者。

当然,您尝试的算法必须适合您的问题,这就是选择正确的机器学习任务的用武之地。打个比方,如果你需要打扫房子,你可能会使用吸尘器、扫帚或拖把,但你不会掏出铲子开始挖掘。
机器学习任务
这是本系列的第 1 部分。在这一部分中,我们将介绍“三大”机器学习任务,这是迄今为止最常见的任务。他们是:
- 回归
- 分类
- 聚类
在第 2 部分:降维算法中,我们将介绍:
- 功能选择
- 特征提取
在继续之前,有两点注意事项:
- 我们不会介绍特定领域的改编,例如自然语言处理。
- 我们不会涵盖所有算法。太多了,无法一一列举,而且新的总是弹出。但是,此列表将为您提供每个任务的成功当代算法的代表性概述。
1. 回归
回归是用于建模和预测连续数值变量的监督学习任务。示例包括预测房地产价格、股票价格走势或学生考试成绩。
回归任务的特征是具有数字目标变量的标记数据集。换句话说,每个观测值都有一些“真实值”值,可用于监督算法。

1.1. (正则化)线性回归
线性回归是回归任务中最常用的算法之一。在最简单的形式中,它试图将直线超平面拟合到您的数据集(即,当您只有 2 个变量时,一条直线)。正如您可能猜到的那样,当数据集中的变量之间存在线性关系时,它效果很好。
在实践中,简单线性回归通常被其正则化对应物(LASSO、Ridge 和 Elastic-Net)所取代。正则化是一种为了避免过拟合而对大系数进行惩罚的技术,应调整惩罚的强度。
- 优势: 线性回归易于理解和解释,并且可以正则化以避免过度拟合。此外,使用随机梯度下降法可以很容易地使用新数据更新线性模型。
- 缺点: 当存在非线性关系时,线性回归性能不佳。它们天生不够灵活,无法捕获更复杂的模式,添加正确的交互项或多项式可能既棘手又耗时。
- 实现: Python / R
1.2. 回归树(Ensembles)
回归树(又称决策树)通过重复将数据集拆分为单独的分支,以分层方式学习,从而最大限度地提高每个拆分的信息增益。这种分支结构允许回归树自然地学习非线性关系。
集成方法(如随机森林 (RF) 和梯度提升树 (GBM))结合了来自许多单个树的预测。我们不会在这里讨论它们的基本机制,但在实践中,射频通常开箱即用,性能非常好,而 GBM 更难调整,但往往具有更高的性能上限。
- 优势: 决策树可以学习非线性关系,并且对异常值相当鲁棒。Ensembles 在实践中表现出色,赢得了许多经典(即非深度学习)机器学习竞赛。
- 弱点: 不受约束的单个树容易过度拟合,因为它们可以保持分支,直到它们记住训练数据。但是,这可以通过使用集成来缓解。
- 实现: 随机森林 – Python / R,梯度提升树 – Python / R
1.3. 深度学习
深度学习是指可以学习极其复杂模式的多层神经网络。它们在输入和输出之间使用“隐藏层”,以便对其他算法无法轻松学习的数据的中间表示进行建模。
它们有几个重要的机制,如卷积和 drop-out,使它们能够有效地从高维数据中学习。然而,与其他算法相比,深度学习仍然需要更多的数据来训练,因为这些模型需要估计的参数要多几个数量级。
- 优势: 深度学习是某些领域(例如计算机视觉和语音识别)的最新技术。深度神经网络在图像、音频和文本数据上表现非常出色,并且可以使用批量传播轻松更新新数据。它们的架构(即层的数量和结构)可以适应多种类型的问题,并且它们的隐藏层减少了对特征工程的需求。
- 弱点: 深度学习算法通常不适合作为通用算法,因为它们需要非常大量的数据。事实上,对于经典的机器学习问题,它们通常被树集成所超越。此外,它们的训练是计算密集型的,并且需要更多的专业知识来调整(即设置架构和超参数)。
- 实现: Python / R
1.4 最近邻算法
最近邻算法是「基于实例的」,这就意味着其需要保留每一个训练样本观察值。最近邻算法通过搜寻最相似的训练样本来预测新观察样本的值。
而这种算法是内存密集型,对高维数据的处理效果并不是很好,并且还需要高效的距离函数来度量和计算相似度。在实践中,基本上使用正则化的回归或树型集成方法是最好的选择。
2. 分类方法
分类是用于对分类变量进行建模和预测的监督学习任务。示例包括预测员工流失、垃圾邮件、财务欺诈或学生信成绩。
正如你所看到的,许多回归算法都有对应的分类算法。这些算法适用于预测一个类(或类概率)而不是实数。
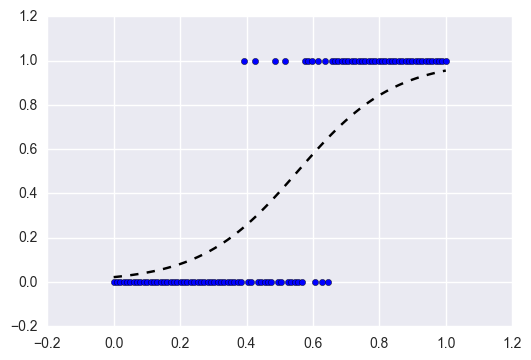
2.1. (正则化)逻辑回归
逻辑回归是线性回归的分类对应物。通过逻辑函数将预测映射到介于 0 和 1 之间,这意味着预测可以解释为类概率。
模型本身仍然是“线性的”,因此当您的类是线性可分离的(即它们可以由单个决策曲面分隔)时,它们会很好地工作。逻辑回归也可以通过惩罚具有可调惩罚强度的系数来正则化。
- **优势:**输出具有很好的概率解释,并且算法可以正则化以避免过度拟合。使用随机梯度下降,可以使用新数据轻松更新逻辑模型。
- 弱点: 当存在多个或非线性决策边界时,逻辑回归往往表现不佳。它们不够灵活,无法自然地捕捉更复杂的关系。
- 实现: Python / R
2.2. 分类树(集成方法)
分类树是回归树的分类对应物。它们通常被称为“决策树”或总称“分类和回归树 (CART)”。
- 优势: 与回归一样,分类树集成在实践中也表现非常出色。它们对异常值具有鲁棒性、可扩展性,并且由于其分层结构,能够自然地对非线性决策边界进行建模。
- 弱点: 不受约束的单个树容易出现过拟合,但这可以通过集成方法缓解。
- 实现: 随机森林 – Python / R,梯度提升树 – Python / R
2.3. 深度学习
为了延续这一趋势,深度学习也很容易适应分类问题。事实上,分类往往是深度学习更常见的用途,例如在图像分类中。
- 优势: 深度学习在对音频、文本和图像数据进行分类时表现非常出色。
- 弱点: 与回归一样,深度神经网络需要大量的数据来训练,因此它不被视为通用算法。
- 实现: Python / R
2.4. 支持向量机
支持向量机 (SVM) 使用一种称为核的机制,该机制实质上计算两个观测值之间的距离。然后,SVM 算法找到一个决策边界,该边界使不同类的最近成员之间的距离最大化。
例如,具有线性内核的 SVM 类似于逻辑回归。因此,在实践中,支持向量机的优势通常来自使用非线性核对非线性决策边界进行建模。
- 优势: SVM 可以对非线性决策边界进行建模,并且有许多内核可供选择。它们对过拟合也相当鲁棒,尤其是在高维空间中。
- 弱点: 但是,SVM 占用大量内存,由于选择正确内核的重要性,调整起来更棘手,并且不能很好地扩展到更大的数据集。目前在业界,随机森林通常比 SVM 更受欢迎。
- 实现: Python / R
2.5 朴素贝叶斯
朴素贝叶斯 (NB) 是一种非常简单的算法,基于条件概率和计数。从本质上讲,您的模型实际上是一个通过训练数据进行更新的概率表。要预测新的观测值,您只需根据其特征值在“概率表”中“查找”类概率即可。
它之所以被称为“朴素”,是因为它的核心假设是条件独立性的(即所有输入特征都彼此独立)在现实世界中很少成立。
优势:尽管条件独立性假设很少成立,但 NB 模型实际上在实践中表现得出奇地好,尤其是因为它们非常简单。它们易于实现,并且可以随数据集一起扩展。
弱点:由于其纯粹的简单性,NB 模型经常被使用前面列出的算法进行适当训练和调整的模型击败。
实现:Python / R
3. 聚类
聚类是一项无监督学习任务,用于根据数据集中的固有结构查找观测值的自然分组(即聚类)。示例包括客户细分、对电子商务中的类似项目进行分组以及社交网络分析。
由于聚类是无监督的(即没有“正确答案”),因此通常使用数据可视化来评估结果。如果有一个“正确答案”(即你的训练集中有预先标记的聚类),那么分类算法通常更合适。

3.1. K-means
K-Means 是一种通用算法,它根据点之间的几何距离(即坐标平面上的距离)进行聚类。这些簇围绕质心分组,使它们呈球状且大小相似。
这是我们推荐给初学者的算法,因为它简单但足够灵活,可以为大多数问题获得合理的结果。
- 优势: K-Means 无疑是最流行的聚类算法,因为如果您预处理数据并设计有用的功能,它快速、简单且非常灵活。
- 弱点: 用户必须指定集群的数量,这并不总是那么容易做到。此外,如果数据中真正的基础聚类不是球状的,则 K-Means 将生成较差的聚类。
- 实现: Python / R
3.2. 近邻传播聚类
近邻传播聚类是一种相对较新的聚类技术,它基于点之间的图距离进行聚类。簇往往较小且大小不均匀。
- 优势: 用户不需要指定聚类的数量(但需要指定“样本首选项”和“阻尼”超参数)。
- 弱点: 近邻传播聚类的主要缺点是速度非常慢且占用大量内存,因此难以扩展到更大的数据集。此外,它还假设真正的底层星团是球状的。
- 实现: Python / R
3.3. 层次/聚类
层次聚类,又名集聚类,是一套基于相同思想的算法:(1)从其自身聚类中的每个点开始。(2)对于每个集群,根据某个标准将其与另一个集群合并。(3) 重复,直到只剩下一个集群,并且您只剩下集群的层次结构。
- 优势: 分层聚类的主要优点是不假定聚类是球状的。此外,它可以很好地扩展到更大的数据集。
- 弱点: 与K-Means非常相似,用户必须选择集群的数量(即算法完成后要“保留”的层次结构级别)。
- 实现: Python / R
3.4. DBSCAN扫描
DBSCAN是一种基于密度的算法,用于为点的密集区域创建聚类。最近还有一项名为HDBSCAN的新开发,它允许不同密度的集群。
- 优势: DBSCAN不假定为球状集群,其性能是可扩展的。此外,它不需要将每个点都分配给集群,从而减少了集群的噪音(这可能是一个弱点,具体取决于您的用例)。
- 弱点: 用户必须调整定义聚类密度的超参数“epsilon”和“min_samples”。DBSCAN对这些超参数非常敏感。
- 实现: Python / R
临别赠言
我们刚刚旋风式地介绍了“三大”机器学习任务的现代算法:回归、分类和聚类。
在第 2 部分:降维算法中,我们将介绍特征选择和特征提取的算法。
但是,根据我们的经验,我们想给您几句建议:
- 第一。。。练习,练习,再练习。 阅读有关算法的文章可以帮助您在一开始就找到立足点,但真正的掌握来自实践。当你通过项目和/或比赛工作时,你将发展出实用的直觉,从而解锁了学习几乎任何算法并有效应用它的能力。
- 第二。。。掌握基础知识。 这里有几十种算法,我们无法一一列举,其中一些算法在特定情况下可能非常有效。但是,几乎所有算法都是对此列表中的算法进行的一些改编,这将为您提供应用机器学习的坚实基础。
- 最后,请记住,更好的数据胜过更高级的算法。 在应用机器学习中,算法是商品,因为您可以根据问题轻松地切换它们。但是,有效的探索性分析、数据清理和特征工程可以显著提高您的结果。