hadoop安装
简介
Hadoop是一个开源的分布式存储和计算框架,最初由Apache软件基金会开发。它的发展背景可以追溯到Google的MapReduce和Google File System(GFS)的论文,这两篇论文启发了Hadoop的设计。Hadoop的主要应用场景包括大数据存储、处理和分析,特别是在需要处理海量数据的互联网和企业环境中。它被广泛用于日志分析、数据挖掘、机器学习、图像处理等领域。 Hadoop的生态系统还包括许多相关项目,如Hive、HBase、Spark等,为大数据处理提供了丰富的工具和技术。
虽然当前提出hadoop的缺点以及弊端,但是当前hadoop的全功能性还是能解决大型项目的大多数问题。学习hadoop变较为必要。
安装以及环境配置
| hostname:ipaddr | 应用 | 属性 |
| vm02:10.0.0.102 | hadoop+jdk+zookeeper | 主节点(DataNode+主NameNode+ResourceManager) |
| vm03:10.0.0.103 | hadoop+jdk+zookeeper | 从节点(Datanode+备用Namenode+备ResourceManager) |
| vm04:10.0.0.104 | hadoop+jdk+zookeeper | 从节点(Datanode) |
下载JDK、zookeeper以往文章中已经做了解释本文不再累述
hadoop进入官网选择最新版本下载。
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz解压压缩包
[hadoop@vm03 ~]$ tar -zxf hadoop-3.3.6.tar.gz
[hadoop@vm03 ~]$ ln -s hadoop-3.3.6 hadoop
[hadoop@vm03 ~]$ rm -rf hadoop-3.3.6.tar.gz
设置软连接,方便后期hadoop升级,做替换
hadoop-env.sh配置
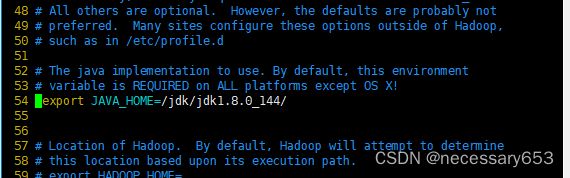
hadoop-env.sh文件主要配置与Hadoop环境相关的变量,文件放置在hadoop/etc/hadoop/目录下,主要配置jdk的目录。
[hadoop@vm03 hadoop]$ echo $JAVA_HOME
/jdk/jdk1.8.0_144/
[hadoop@vm03 hadoop]$ vim hadoop-env.sh
core-site.xml配置
dfs.blocksize
134217728
dfs.replication
3
hadoop.tmp.dir
/home/hadoop/data
fs.defaultFS
hdfs://mycluster
ha.zookeeper.quorum
vm02:2181,vm03:2181,vm04:2181
hdfs-site.xml配置
hdfs-site.xml文件主要配置和HDFS相关的属性, 同样位于hadoop/etc/hadoop路径下
dfs.namenode.name.dir
file://${hadoop.tmp.dir}/name
dfs.datanode.data.dir
file://${hadoop.tmp.dir}/data
dfs.journalnode.edits.dir
${hadoop.tmp.dir}/jn
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
vm02:8020
dfs.namenode.rpc-address.mycluster.nn2
vm03:8020
dfs.namenode.http-address.mycluster.nn1
vm02:9870
dfs.namenode.http-address.mycluster.nn2
vm03:9870
dfs.namenode.shared.edits.dir
qjournal://vm02:8485;vm03:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
mapred-site.xml配置
mapreduce.framework.name
yarn
yarn-site.xml配置
yarn.resourcemanager.connect.max-wait.ms
2000
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enable
true
yarn.resourcemanager.ha.automatic-failover.embedded
true
yarn.resourcemanager.cluster-id
yarn-rm-cluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
vm02
yarn.resourcemanager.hostname.rm2
vm03
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.zk.state-store.address
vm02:2181,vm03:2181,vm04:2181
yarn.resourcemanager.address.rm1
vm02:8032
yarn.resourcemanager.scheduler.address.rm1
vm02:8034
yarn.resourcemanager.webapp.address.rm1
vm02:8088
yarn.resourcemanager.address.rm2
vm03:8032
yarn.resourcemanager.scheduler.address.rm2
vm03:8034
yarn.resourcemanager.webapp.address.rm2
vm03:8088
yarn.resourcemanager.zk-address
vm02:2181,vm03:2181,vm04:2181
yarn.log-aggregation-enable
true
hadoop.zk.address
vm02:2181,vm02:2181,vm02:2181
yarn.nodemanager.aux-sevices
mapreduce_shuffle
yarn.nodemanager.aux-sevices.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandle
workers文件配置
workers文件的名称是在hadoop-env.sh 文件中指定的。在 hadoop-env.sh 文件中,可以找到一个环境变量 HADOOP_WORKERS,它指定了workers 文件的路径。通常情况下,HADOOP_WORKERS 的默认值是 ${HADOOP_CONF_DIR}/workers ,其中 ${HADOOP_CONF_DIR} 是指向 Hadoop 配置文件目录的环境变量。
注意:旧版本这里使用的是slaves
[hadoop@vm02 ~]$ cd hadoop/etc/hadoop/
[hadoop@vm02 hadoop]$ vim workers
vm02
vm03
vm04 此文件配置集群中的所有hostname。
注:所有节点配置内容保持一致
试运行
启动Zookeeper集群
所有节点都需启动
[hadoop@vm03 ~]$ zkServer.sh restart
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@vm03 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
启动JournalNode集群
在Hadoop中,JournalNode集群用于存储NameNode的编辑日志。它们帮助确保在NameNode发生故障时不会丢失数据,并支持NameNode的高可用性和故障转移。 JournalNode集群是Hadoop分布式文件系统(HDFS)的关键组件,用于维护持久化的NameNode编辑日志,以便在发生故障时进行恢复。
在集群所有节点分别启动JournalNode服务
hadoop/sbin/hadoop-daemon.sh start journalnode[hadoop@vm03 ~]$ hadoop/sbin/hadoop-daemon.sh start journalnode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
WARNING: /home/hadoop/hadoop-3.3.6/logs does not exist. Creating.
[hadoop@vm03 ~]$ jps
7936 JournalNode
7780 QuorumPeerMain
7975 Jps
格式化主节点NameNode
## 在vm02节点(NameNode主节点)上,使用以下命令对 NameNode进行格式化
hadoop/bin/hdfs namenode -format
hadoop/bin/hdfs zkfc -formatZK
hadoop/bin/hdfs namenode
##在备用节点vm03进行同步主节点的元数据
hadoop/bin/hadoop namenode -bootstrapStandby
##所有节点关闭zookeeper集群
zkServer.sh stop
##所有节点关闭 journalnode集群
hadoop/sbin/hadoop-daemon.sh stop journalnode
##所有节点启动zookeeper集群
zkServer.sh start
#主节点vm02启动集群
hadoop/sbin/start-all.sh

格式化ZooKeeper中与故障转移控制器(Failover Controller)相关的数据。这个命令通常在设置故障转移控制器时使用,以确保ZooKeeper中的相关数据处于正确的状态。
hadoop/bin/hdfs zkfc -formatZK
所有节点启动zookeeper集群
vm02启动HDFS集群
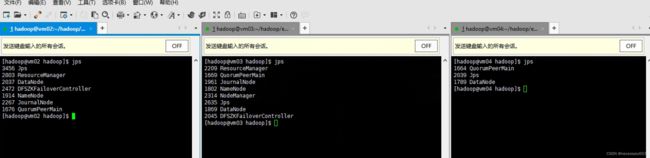
验证
通过jps查看namenode进程所在节点,通过web进行访问
[hadoop@vm03 ~]$ jps
1666 QuorumPeerMain
2727 DFSZKFailoverController
2315 DataNode
1820 JournalNode
2125 NameNode
3294 Jps
[hadoop@vm03 ~]$ ip addr
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:f1:d6:3e brd ff:ff:ff:ff:ff:ff
inet 10.0.0.103/24 brd 10.0.0.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fef1:d63e/64 scope link
valid_lft forever preferred_lft forever
打开网页输入以下namenode的ip地址
http://10.0.0.103:9870
http://10.0.0.102:9870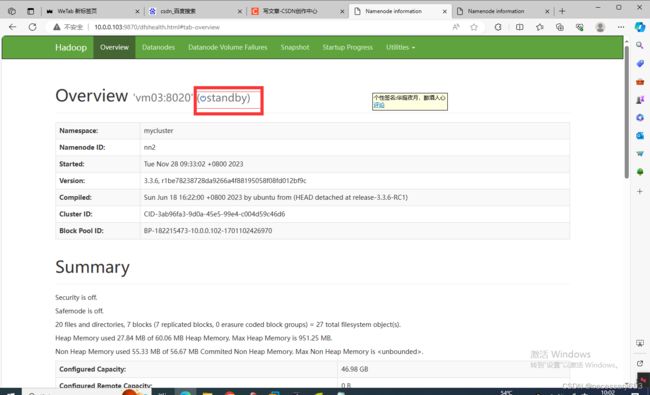
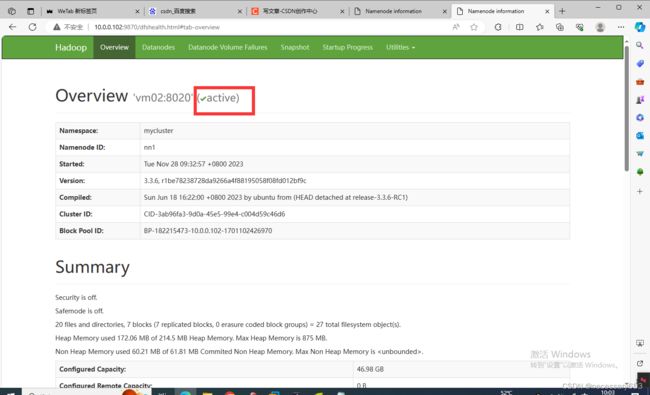
此时namenode节点都是可以通过web节点上线的,vm03作为备用节点。