广电大数据可视化项目
一. 读取与清洗广播电视数据
-
# 代码6-1 import pandas as pd data_raw = pd.read_csv('../data/media_index.csv', encoding='gbk', header='infer') payevents = pd.read_csv('../data/mmconsume_payevents.csv', sep=',', encoding='gbk', header='infer') print(data_raw.shape, payevents.shape) # 代码6-2 media = pd.read_csv('../data/media_index.csv', encoding='gbk', header='infer') # 将“-高清”替换为空 media['station_name'] = media['station_name'].str.replace('-高清', '') # 过滤特殊线路、政企用户 media = media.loc[(media.owner_code != 2)&(media.owner_code != 9)& (media.owner_code != 10), :] print('查看过滤后的特殊线路的用户:', media.owner_code.unique()) media = media.loc[(media.owner_name != 'EA级')&(media.owner_name != 'EB级')& (media.owner_name != 'EC级')&(media.owner_name != 'ED级')& (media.owner_name != 'EE级'), :] print('查看过滤后的政企用户:', media.owner_name.unique()) # 对开始时间进行拆分 # 检查数据类型 type(media.loc[0, 'origin_time']) # 转化为时间类型 media['end_time'] = pd.to_datetime(media['end_time']) media['origin_time'] = pd.to_datetime(media['origin_time']) # 提取秒 media['origin_second'] = media['origin_time'].dt.second media['end_second'] = media['end_time'].dt.second # 筛选数据 ind1 = (media['origin_second'] == 0) & (media['end_second'] == 0) media1 = media.loc[~ind1, :] # 基于开始时间和结束时间的记录去重 media1.end_time = pd.to_datetime(media1.end_time) media1.origin_time = pd.to_datetime(media1.origin_time) media1 = media1.drop_duplicates(['origin_time', 'end_time']) # 隔夜处理 # 去除开始时间,结束时间为空值的数据 media1 = media1.loc[media1.origin_time.dropna().index, :] media1 = media1.loc[media1.end_time.dropna().index, :] # 创建星期特征列 media1['星期'] = media1.origin_time.apply(lambda x: x.weekday()+1) dic = {1:'星期一', 2:'星期二', 3:'星期三', 4:'星期四', 5:'星期五', 6:'星期六', 7:'星期日'} for i in range(1, 8): ind = media1.loc[media1['星期'] == i, :].index media1.loc[ind, '星期'] = dic[i] # 查看有多少观看记录是隔天的,隔天的进行隔天处理 a = media1.origin_time.apply(lambda x :x.day) b = media1.end_time.apply(lambda x :x.day) sum(a != b) media2 = media1.loc[a != b, :].copy() # 需要做隔天处理的数据 def geyechuli_xingqi(x): dic = {'星期一':'星期二', '星期二':'星期三', '星期三':'星期四', '星期四':'星期五', '星期五':'星期六', '星期六':'星期日', '星期日':'星期一'} return x.apply(lambda y: dic[y.星期], axis=1) media1.loc[a != b, 'end_time'] = media1.loc[a != b, 'end_time'].apply(lambda x: pd.to_datetime('%d-%d-%d 23:59:59'%(x.year, x.month, x.day))) media2.loc[:, 'origin_time'] = pd.to_datetime(media2.end_time.apply(lambda x: '%d-%d-%d 00:00:01'%(x.year, x.month, x.day))) media2.loc[:, '星期'] = geyechuli_xingqi(media2) media3 = pd.concat([media1, media2]) media3['origin_time1'] = media3.origin_time.apply(lambda x: x.second + x.minute * 60 + x.hour * 3600) media3['end_time1'] = media3.end_time.apply(lambda x: x.second + x.minute * 60 + x.hour * 3600) media3['wat_time'] = media3.end_time1 - media3.origin_time1 # 构建观看总时长特征 # 清洗时长不符合的数据 # 剔除下次观看的开始时间小于上一次观看的结束时间的记录 media3 = media3.sort_values(['phone_no', 'origin_time']) media3 = media3.reset_index(drop=True) a = [media3.loc[i+1, 'origin_time'] < media3.loc[i, 'end_time'] for i in range(len(media3)-1)] a.append(False) aa = pd.Series(a) media3 = media3.loc[~aa, :] # 去除小于4S的记录 media3 = media3.loc[media3['wat_time'] > 4, :] # 保存贴标签用 media3.to_csv('../tmp/media3.csv', na_rep='NaN', header=True, index=False) # 查看连续观看同一频道的时长是否大于3h # 发现这2000个用户不存在连续观看大于3h的情况 media3['date'] = media3.end_time.apply(lambda x :x.date()) media_group = media3['wat_time'].groupby([media3['phone_no'], media3['date'], media3['station_name']]).sum() media_group = media_group.reset_index() media_g = media_group.loc[media_group['wat_time'] >= 10800, ] media_g['time_label'] = 1 o = pd.merge(media3, media_g, left_on=['phone_no', 'date', 'station_name'], right_on=['phone_no', 'date', 'station_name'], how='left') oo = o.loc[o['time_label'] == 1, :] # 代码6-3 payevents = pd.read_csv('../data/mmconsume_payevents.csv', sep=',', encoding='gbk', header='infer') payevents.columns = ['phone_no', 'owner_name', 'event_time', 'payment_name', 'login_group_name', 'owner_code'] # 过滤特殊线路、政企用户 payevents = payevents.loc[(payevents.owner_code != 2 )&(payevents.owner_code != 9 )&(payevents.owner_code != 10), :] # 去除特殊线路数据 print('查看过滤后的特殊线路的用户:', payevents.owner_code.unique()) payevents = payevents.loc[(payevents.owner_name != 'EA级' )&(payevents.owner_name != 'EB级' )&(payevents.owner_name != 'EC级' )&(payevents.owner_name != 'ED级' )&(payevents.owner_name != 'EE级'), :] print('查看过滤后的政企用户:', payevents.owner_name.unique()) payevents.to_csv('../tmp/payevents2.csv', na_rep='NaN', header=True, index=False)
二.绘制可视化图形
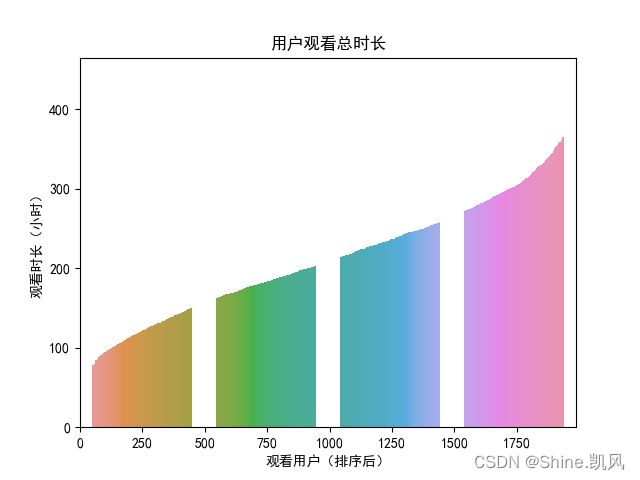
# 代码6-4 import pandas as pd import matplotlib.pyplot as plt import matplotlib.ticker as ticker import seaborn as sns import re plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为SimHei显示中文 plt.rcParams['axes.unicode_minus'] = False # 设置正常显示符号 media3 = pd.read_csv('../tmp/media3.csv', header='infer') # 用户观看总时长 m = pd.DataFrame(media3['wat_time'].groupby([media3['phone_no']]).sum()) m = m.sort_values(['wat_time']) m = m.reset_index() m['wat_time'] = m['wat_time'] / 3600 m['id'] = m.index ax = sns.barplot(x='id', y='wat_time', data=m) ax.xaxis.set_major_locator(ticker.MultipleLocator(250)) ax.xaxis.set_major_formatter(ticker.ScalarFormatter()) plt.xlabel('观看用户(排序后)') plt.ylabel('观看时长(小时)') plt.title('用户观看总时长') plt.show()
# 代码6-5 # 所有收视频道名称的观看时长与观看次数 media3.station_name.unique() pindao = pd.DataFrame(media3['wat_time'].groupby([media3.station_name]).sum()) pindao = pindao.sort_values(['wat_time']) pindao = pindao.reset_index() pindao['wat_time'] = pindao['wat_time'] / 3600 pindao_n = media3['station_name'].value_counts() pindao_n = pindao_n.reset_index() pindao_n.columns = ['station_name', 'counts'] a = pd.merge(pindao, pindao_n, left_on='station_name', right_on ='station_name', how='left') fig, ax1 = plt.subplots() ax2 = ax1.twinx() # 构建双轴 sns.barplot(a.index, a.iloc[:, 1], ax=ax1) sns.lineplot(a.index, a.iloc[:, 2], ax=ax2, color='r') ax1.set_ylabel('观看时长(小时)') ax2.set_ylabel('观看次数') ax1.set_xlabel('频道号(排序后)') plt.xticks([]) plt.title('所有收视频道名称的观看时长与观看次数') plt.show()

# 收视前15频道名称的观看时长,由于pindao已排序,取后15条数据 sns.barplot(x='station_name', y='wat_time', data=pindao.tail(15)) plt.xticks(rotation=45) plt.xlabel('频道名称') plt.ylabel('观看时长(小时)') plt.title('收视前15的频道名称') plt.show()

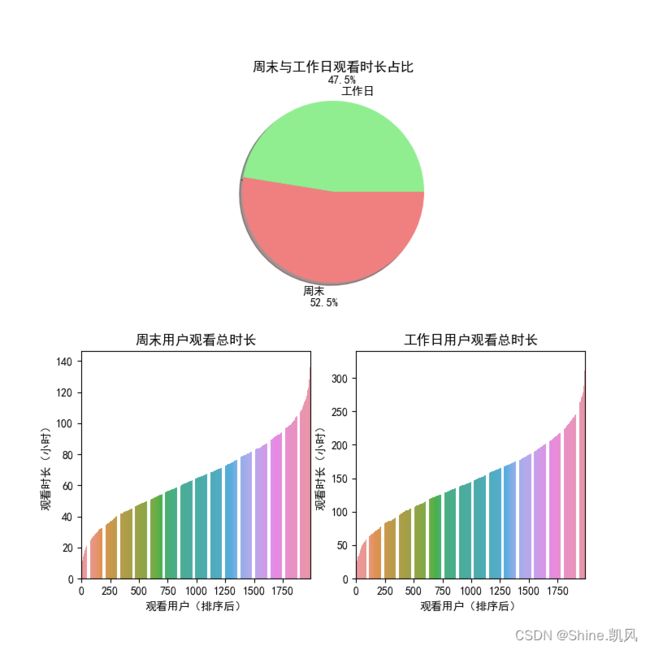
# 代码6-6 # 工作日与周末的观看时长比例 ind = [re.search('星期六|星期日', str(i)) != None for i in media3['星期']] freeday = media3.loc[ind, :] workday = media3.loc[[ind[i]==False for i in range(len(ind))], :] m1 = pd.DataFrame(freeday['wat_time'].groupby([freeday['phone_no']]).sum()) m1 = m1.sort_values(['wat_time']) m1 = m1.reset_index() m1['wat_time'] = m1['wat_time'] / 3600 m2 = pd.DataFrame(workday['wat_time'].groupby([workday['phone_no']]).sum()) m2 = m2.sort_values(['wat_time']) m2 = m2.reset_index() m2['wat_time'] = m2['wat_time'] / 3600 w = sum(m2['wat_time']) / 5 f = sum(m1['wat_time']) / 2 plt.figure(figsize=(8, 8)) plt.subplot(211) # 参数为:行,列,第几项 subplot(numRows, numCols, plotNum) colors = 'lightgreen','lightcoral' plt.pie([w, f], labels = ['工作日', '周末'], colors=colors, shadow=True, autopct='%1.1f%%', pctdistance=1.23) plt.title('周末与工作日观看时长占比') plt.subplot(223) ax1 = sns.barplot(m1.index, m1.iloc[:, 1]) # 设置坐标刻度 ax1.xaxis.set_major_locator(ticker.MultipleLocator(250)) ax1.xaxis.set_major_formatter(ticker.ScalarFormatter()) plt.xlabel('观看用户(排序后)') plt.ylabel('观看时长(小时)') plt.title('周末用户观看总时长') plt.subplot(224) ax2 = sns.barplot(m2.index, m2.iloc[:, 1]) # 设置坐标刻度 ax2.xaxis.set_major_locator(ticker.MultipleLocator(250)) ax2.xaxis.set_major_formatter(ticker.ScalarFormatter()) plt.xlabel('观看用户(排序后)') plt.ylabel('观看时长(小时)') plt.title('工作日用户观看总时长') plt.show()
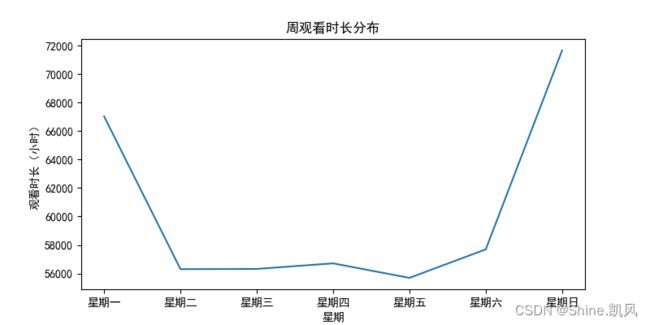
# 代码6-7 # 周观看时长分布 n = pd.DataFrame(media3['wat_time'].groupby([media3['星期']]).sum()) n = n.reset_index() n = n.loc[[0, 2, 1, 5, 3, 4, 6], :] n['wat_time'] = n['wat_time'] / 3600 plt.figure(figsize=(8, 4)) sns.lineplot(x='星期', y='wat_time', data=n) plt.xlabel('星期') plt.ylabel('观看时长(小时)') plt.title('周观看时长分布') plt.show()
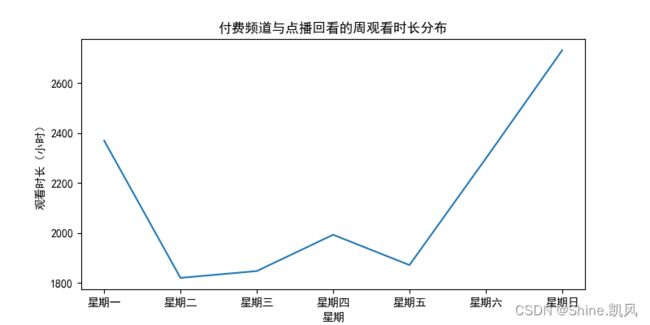
# 付费频道与点播回看的周观看时长分布 media_res = media3.loc[media3['res_type'] == 1, :] ffpd_ind = [re.search('付费', str(i)) != None for i in media3.loc[:, 'station_name']] media_ffpd = media3.loc[ffpd_ind, :] z = pd.concat([media_res, media_ffpd], axis=0) z = z['wat_time'].groupby(z['星期']).sum() z = z.reset_index() z = z.loc[[0, 2, 1, 5, 3, 4, 6], :] z['wat_time'] = z['wat_time'] / 3600 plt.figure(figsize=(8, 4)) sns.lineplot(x='星期', y='wat_time', data=z) plt.xlabel('星期') plt.ylabel('观看时长(小时)') plt.title('付费频道与点播回看的周观看时长分布') plt.show()
# 代码6-8 # 设置Matplotlib正常显示中文和负号 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False # 读取csv文件 pay = pd.read_csv('../tmp/payevents2.csv') sns.countplot(x='payment_name', data=pay) plt.xticks(rotation=80) plt.xlabel('支付方式') plt.ylabel('总数') plt.title('用户支付方式总数对比') plt.show()

三.撰写项目分析报告
https://www.aliyundrive.com/s/MLe5yYA1ggp
提取码:x3u2