G1垃圾收集器
1.G1的目的:
Garbage First,也就是垃圾优先原则,也就是空间方面的关注点。同时照顾到停顿时间以及吞吐量。
G1垃圾收集器的设计目的是避免完全回收,但是当并发收集不能足够快地回收内存时,就会发生完全回收GC。G1的完整GC的当前实现使用单线程mark-sweep compact算法。
1.1JDK8为什么不用CMS做为默认垃圾收集器呢
1.CMS单线程或者双线程情况下效率很低
2.CMS会并发失败
3.CMS可中止的预处理会导致极限5S停顿
4.并发失败进入foregroud还会导致进入Full GC,全局MSC整理
5.CMS吞吐的设计并不是很优秀
1.2G1的特点:
内存空间的重新定义
更短的停顿时间,要多短就多短
某种程度上去解决空间碎片
2.内存空间的重新定义:region
G1的一个Region大小可以单独设定,可以1-32M,设置需要已2的n次幂来设置,因为很多算法都是已2的n次幂来计算的,所以Region大小也要按照这个来实现
G1虽然保留了新老年代的概念,但是G1把他们分成了一个一个的Region。
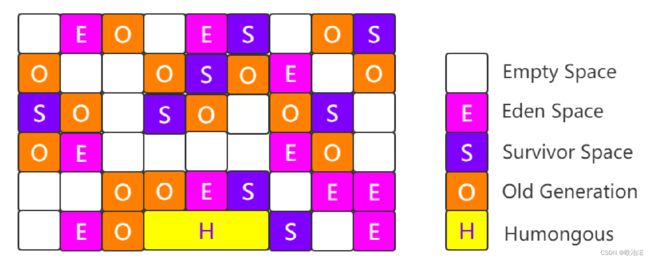
2.1Region的角色:
自由角色FreeTag
新生代分区 YoungHeapRegion,细分为eden分区和survivor分区
大对象分区 HHR,细分为大对象头分区和大对象连续分区
老年代分区 OHR
JDK11之后有一类特殊的分区,叫做归档分区,关闭归档分区以及开放归档分区
3.TLAB(线程本地分配缓冲区 Thread Local Allocation Buffer)
分配空间时,为了提高JVM的运行效率,应当尽量减少临界区范围,避免全局锁。G1的通常的应用场景中,会存在大量的访问器同时执行,为减少锁冲突,JVM引入了TLAB(线程本地分配缓冲区 Thread Local Allocation Buffer)机制。
3.1TLAB作用:
我们知道对象内存分配时最初考虑在新生代的Eden区为对象分配内存,但堆区是线程共享的区域,在多线程环境下多个线程同时操控同一块内存的现象是普遍的,为了保证对象分配时数据的安全性,我们需要用全局锁来解决多线程同时访问同一块内存的问题,但全局锁会降低效率与程序的吞吐量,为了解决该问题TLAB应运而生
在分配线程对象时,从JVM堆中分配一个固定大小的内存区域并将其作为线程的私有缓冲区,这个缓冲区称为TLAB。只有在为每个线程分配TLAB缓冲区时才需要锁定整个JVM堆。
由于TLAB是属于线程的,不同的线程不共享TLAB,当我们尝试分配一个对象时,优先从当前线程的TLAB中分配对象,不需要锁,因此达到了快速分配的目的。
实际上TLAB是Eden区域中的一块内存,不同线程的TLAB都位于Eden区,所有的TLAB内存对所有的线程都是可见的,只不过每个线程有一个TLAB的数据结构,用于保存待分配内存区间的起始地址(start)和结束地址(end),在分配的时候只在这个区间做分配,从而达到无锁分配,快速分配。
虽然TLAB在分配对象空间的时候是无锁分配,但是TLAB空间本身在分配的时候(分配TLAB内存空间)还是需要锁的,G1中使用了CAS来并行分配。
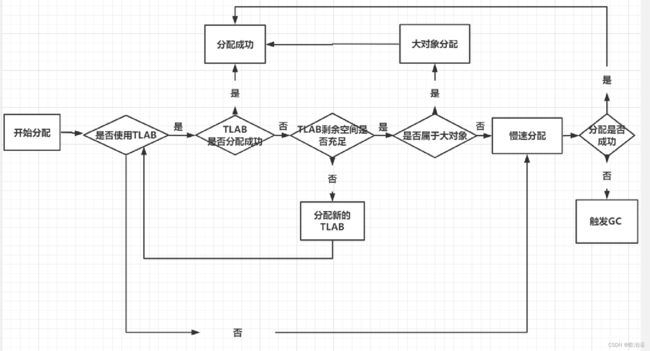
对象的分配实在TLAB中进行,由于每个线程都有一个独立的TLAB,所以可以达到无锁分配,如果失败了就会发生GC
3.2G1对新老年代中的相互引用是怎么处理的?
G1在进行oldGC的时候都会进行youngGC,所以不用管新生代指向老年代的问题
记录引用关系的2中方式
obj1=obj2
out:所有的引用关系都记录在obj1中,我引用了谁
in:所有的引用关系都记录在obj2,谁引用了我,G1使用的这种,但是如果位置不够怎么办,引用集
4.RSet(RemeberSet)引用集
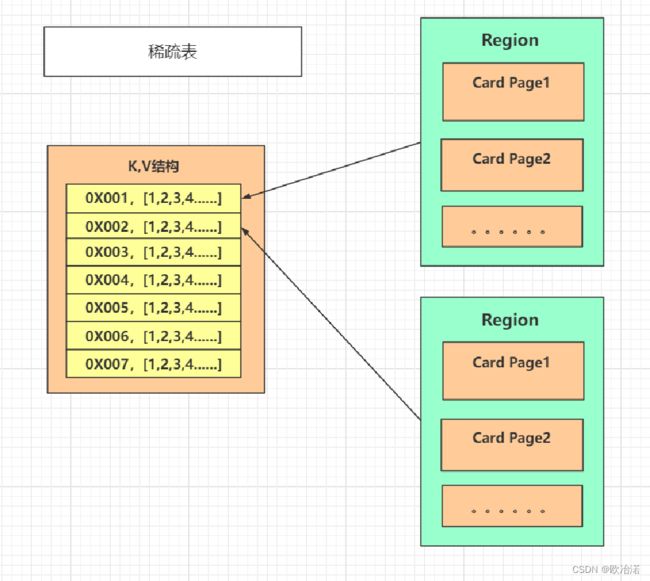
4.1稀疏表
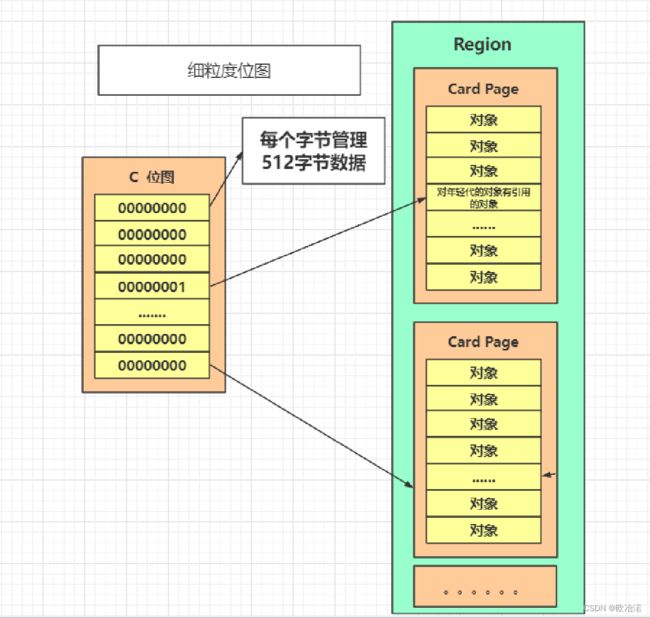
本质上就是一种Hash表,Key是Region的起始地址,Value是一个数组,里面存储的元素是卡页的索引号。将一个Region分成小块,每个小块都是V中的一个值
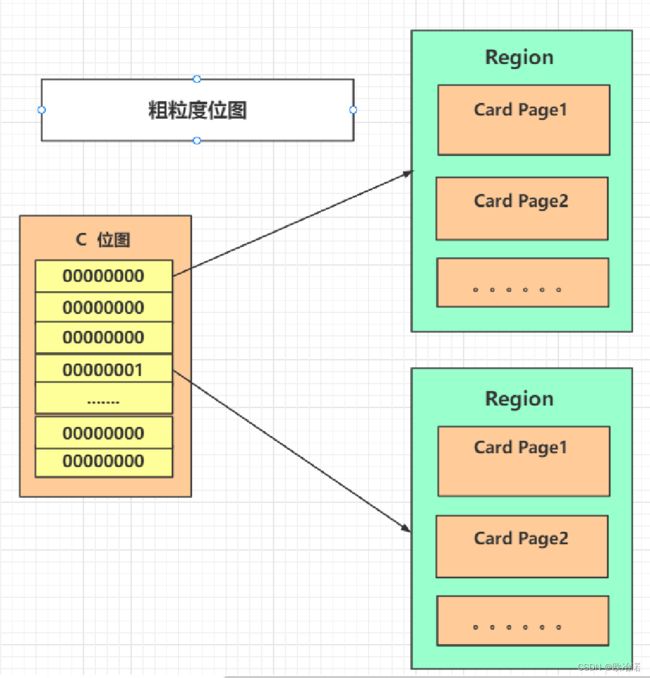
4.2粗粒度位图
当细粒度位图 size超过阈值时,所有region 形成一个 bitMap。如果有region 对当前 Region 有指针指向,就设置其对应的bit 为1,也就是粗粒度位图
一个位图对应一个Region
4.3细粒度位图
就是一个C位图,但是这个位图,可以详细的记录我们的内存变化,包括并发标记修改,对应元素标识等 当稀疏表指定region的card数量超过阈值时,则在细粒度位图中创建一个对应的PerRegionTable对象。一个Region地址链表,维护当前Region中所有card对应的一个BitMap集合。
5.什么是写屏障:
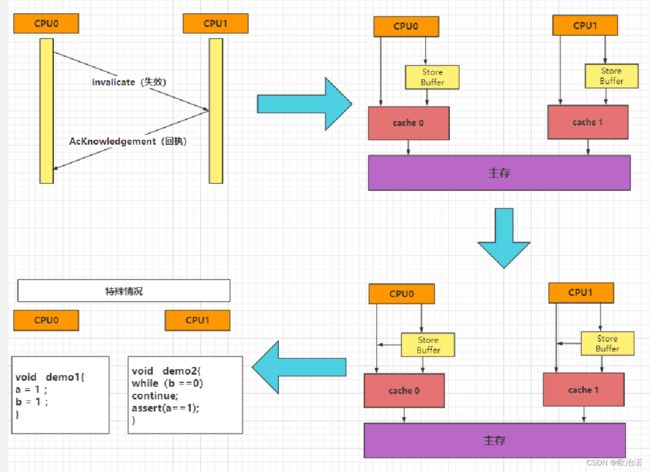
因为Store Buffer导致读写的顺序不一致,而写屏障可以解决这个问题
多核情况下,cpu0与CPU1共享一个数据,如果0修改了数据那么就要将这个数据置为失效,并且通知1,还要等到1的回执才能继续执行,这样就会很慢,这时就加入了Store Buffer,先写入Store Buffer,等到收到AcKnowledgement的时候,再把数据刷入缓存,但是这个时候还有一个问题,写数据走了Store Buffer,如果读取的时候不走Store Buffer直接走cache,不就导致数据不一致了么,所以,读要同时走cache和Store Buffer
StoreBuffer,导致读写不一致
a的值可能因为是Share(共享)先被写入了Store Buffer,并发送通知其他cpu置为Invalid(失效)
b的值,可能因为在cache中已经存在并且是Exclusive(独占)直接被写进cache中。
读取的时候因为先读b的值,b被刷进主存供读取
后面要读a,因为还没收到失效通知,从cache中直接拿到a,断言失败。
5.1写屏障的内存伪共享问题:
如果不同线程对对象引用的更新操作,恰好位于同一个64KB区域内,这将导致同时更新卡表的同一个缓存行,从而造成缓存行的写回、无效化或者同步操作,间接影响程序性能。
5.2解决方案:
不采用无条件的写屏障,而是先检查卡表标记,只有当该卡表项未被标记过才将其标记为dirty。 这就是JDK 7中引入的解决方法,引入了一个新的JVM参数-XX:+UseCondCardMark,
6.G1的Rset同步异步问题:
异步更新操作需要引入DCQS(Dirty Card Queue Set)结构。
G1 DCQS是Dirty Card Queue Set的缩写,它是G1垃圾收集器中的一个组件,用于跟踪堆中对象的修改情况。当一个对象被修改时,它所在的卡片会被标记为脏卡片,这些脏卡片会被添加到G1 DCQS中。在G1垃圾收集器的标记阶段,G1会扫描G1 DCQS中的脏卡片,找到对应的对象并标记为存活对象。在标记阶段结束后,G1会清空G1 DCQS。
G1 DCQS是由多个Dirty Card Queue组成的,每个Dirty Card Queue对应一个Region。当一个对象被修改时,它所在的卡片会被添加到对应Region的Dirty Card Queue中。在标记阶段,G1会扫描每个Dirty Card Queue中的脏卡片,找到对应的对象并标记为存活对象。
JVM声明了一个全局的静态结构G1BarrierSet,其中包含两个Queue Set,DirtyCardQueueSet和G1SATBMarkQueueSet,分别用于处理DCQS和STAB
G1常用参数: -XX: +UseG1GC 开启G1垃圾收集器 -XX: G1HeapReginSize 设置每个Region的大小,是2的幂次,1MB-32MB之间 -XX:MaxGCPauseMillis 最大停顿时间 -XX:ParallelGCThread 并行GC工作的线程数 -XX:ConcGCThreads 并发标记的线程数 -XX:InitiatingHeapOcccupancyPercent 默认45%,代表GC堆占用达到多少的时候开始垃圾收集
7.G1常用参数:
-XX: +UseG1GC 开启G1垃圾收集器
-XX: G1HeapReginSize 设置每个Region的大小,是2的幂次,1MB-32MB之间
-XX:MaxGCPauseMillis 最大停顿时间
-XX:ParallelGCThread 并行GC工作的线程数
-XX:ConcGCThreads 并发标记的线程数
-XX:InitiatingHeapOcccupancyPercent 默认45%,代表GC堆占用达到多少的时候开始垃圾收集
7.G1相对于CMS的的优势:
1.G1在压缩空间方面有优势。
2.G1通过将内存空间分成区域(Region)的方式避免内存碎片问题
3.Eden、Survivor、Old区不再固定,在内存使用率上来说更灵活
4.G1可以通过设置预期停顿时间(Pause Time)来控制垃圾收集时间,避免应用雪崩现象
5.G1在回收内存后会马上同时做合并空闲内存的工作,而CMS默认是在STW(stop the world)的时候做
6.G1会在Young GC中使用,而CMS只能在Old区使用