CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION
CONTROLLING VISION-LANGUAGE MODELS FOR MULTI-TASK IMAGE RESTORATION (Paper reading)
Ziwei Luo, Uppsala University, ICLR under review(6663), Cited:None, Stars: 350+, Code, Paper.
1. 前言
像CLIP这样的视觉语言模型已经显示出对零样本或无标签预测的各种下游任务的巨大影响。然而,当涉及到图像恢复等低水平视觉时,由于输入损坏,它们的性能会急剧下降。在本文中,我们提出了一种退化感知视觉语言模型(DA-CLIP),以更好地将预训练的视觉语言模型转移到低级视觉任务中,作为图像恢复的多任务框架。更具体地说,DA-CLIP训练一个额外的控制器,该控制器调整固定的CLIP图像编码器以预测高质量的特征嵌入。通过交叉关注将嵌入集成到图像恢复网络中,我们能够引导模型学习高保真度图像重建。控制器本身还将输出与输入的实际损坏相匹配的退化特征,从而为不同的退化类型生成自然分类器。此外,我们构建了一个具有合成字幕的混合退化数据集,用于DA-CLIP训练。我们的方法在退化特定和统一的图像恢复任务上都取得了最先进的性能,显示了用大规模预训练的视觉语言模型促进图像恢复的有前途的方向。
2. 整体思想
ALL in one的图像复原模型,可以用分类器对不同输入图像做分类,然后分类得到的一些输出作为条件来指导One这个模型对特定类型任务复原。这篇文章的思想也是一样的。他们使用类似于ControlNet的方法,对CLIP做微调,使CLIP可以根据输入LQ图像,得到HQ的内容编码和预测LQ的降质类型编码。这两个编码作为其他模型的条件实现All in one。思想是很老旧的,方法也是ControlNet的,但是确实work。具体的其他疑问见第6小节。
3. 介绍
现有的大规模预训练的视觉语言模型(VLM)对图像恢复(IR)等low-level视觉任务的影响有限,可能是因为它们没有捕捉到“模糊”和“噪声”等图像退化类型之间的细粒度差异。因此,现有的VLM经常使图像特征与退化文本不对齐。这并不奇怪,考虑到VLM通常在不同的网络规模数据集上进行训练,而大多数图像恢复模型是在相对较小的数据集上训练的,这些数据集是为特定任务策划的,没有相应的图像-文本对。
传统图像恢复方法通常只是简单地学习逐像素生成图像,而不利用任务知识,这通常需要对特定退化类型的同一模型进行重复训练。然而,最近的一项工作集中在统一图像恢复上,在混合退化数据集上训练单个模型,并隐式地对恢复过程中的退化类型进行分类。虽然结果令人印象深刻,但它们仍然局限于少数退化类型和与之相关的特定数据集。特别是,它们没有利用VLM中嵌入的大量信息。
在本文中,我们将大规模预训练的视觉语言模型CLIP与图像恢复网络相结合,提出了一个可应用于退化特定和统一图像恢复问题的多任务框架。具体来说,为了解决损坏的输入和干净的captions之间的特征不匹配问题,我们提出了一种图像控制器(Image Controller),该控制器调整VLM的图像编码器,以输出与干净的caption对齐的高质量(HQ)内容嵌入。同时,控制器本身也预测退化嵌入以匹配真实退化类型。这种新的框架,我们称之为退化感知CLIP(DA-CLIP),将VLM的人类级知识融入到通用网络中,从而提高图像恢复性能并实现统一的图像恢复。
为了训练DA-CLIP从低质量(LQ)输入中学习高质量特征和退化类型,我们为十个不同的图像恢复任务构建了一个大型混合退化数据集。具体来说,我们使用BLIP,一个自举的视觉语言框架,为所有HQ图像生成合成字幕,然后将LQ图像与字幕和相应的退化类型匹配为图像-文本退化对。一旦经过训练,我们的DA-CLIP就可以准确地对十种不同的退化类型进行分类,并可以很容易地集成到现有的恢复模型中,帮助在不同的退化中产生视觉上吸引人的结果,如图1所示。
4. 方法
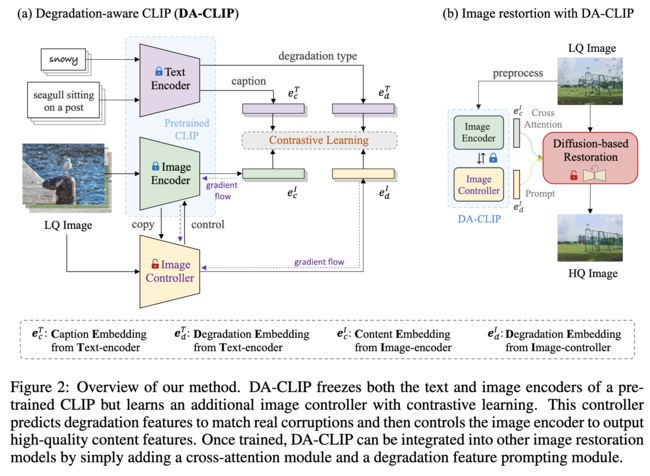
4.1 退化感知CLIP( DA-CLIP)
我们方法的核心是控制预训练的CLIP模型,以从损坏的图像中输出高质量的图像特征,同时预测退化类型。如图2所示,图像内容嵌入 e c I e^I_c ecI与干净的标题嵌入 e c T e^T_c ecT相匹配。此外,由控制器预测的图像退化嵌入 e d I e^I_d edI指定输入的损坏类型,即来自文本编码器的相应退化嵌入 e d T e^T_d edT。然后可以将这些特征集成到其他图像恢复模型中,以提高它们的性能。
我们原本的CLIP是清晰图像匹配本文,但是你现在输入的是损坏图像,这就会导致你的潜在图像内容无法正确匹配GT文本,这里用Image Controller对CLIP的图像编码器微调,使之适应损坏图像。此外,你CLIP的额外输入还有一个降质类型,这个是Image Controller来额外预测的。
4.2 Image Controller

图像控制器是CLIP图像编码器的副本,但使用一些零初始化连接进行包装,以向编码器添加控制。它操纵所有编码器块的输出以控制图像编码器的预测。在本文中,我们使用ViT作为编码器和控制器的默认主干。图3(a)说明了控制过程,其中控制器的输出由两部分组成:图像退化嵌入 e d I e_d^I edI和隐藏控件 h c h_c hc。注意,后者包含来自变换器块的所有输出,这些输出随后被添加到相应的编码器块以控制它们的预测。变换器块之间的连接是简单的密集神经网络,所有参数都初始化为零,这在训练过程中逐渐影响图像编码器。由于与VLM中使用的网络规模数据集相比,我们的训练数据集很小,因此这种控制策略在保持原始图像编码器能力的同时减轻了过拟合。
我们冻结预训练的CLIP模型的所有权重,只微调图像控制器。为了使退化嵌入空间具有判别性和良好的分离性,我们使用对比目标来学习嵌入匹配过程。设N表示训练批中成对嵌入(来自文本编码器和图像编码器/控制器)的数量。对比损失定义为:

然后为了优化内容和降质嵌入,我们使用以下共同目标:
L c ( w ) = L c o n ( e c I , e c T ; w ) + L c o n ( e d I , e d T ; w ) L_c(w) = L_{con}(e^I_c, e^T_c;w) + L_{con}(e^I_d, e^T_d;w) Lc(w)=Lcon(ecI,ecT;w)+Lcon(edI,edT;w)
这个损失函数的意思就是,先让CLIP的文本编码器对GT描述和降质类型编码得到 e c T e_c^T ecT和 e d T e_d^T edT,然后图二中的输入LQ得到输出 e c I e_c^I ecI和 e d I e_d^I edI。他们做对比学习进行对齐,就可以实验LQ输入匹配HQ的captions和types的编码。
4.3 DA-CLIP用于图像复原
简单介绍下IR- SDE,它是一个专用于复原的扩散模型,对于不同任务都需要从头训练一个特定的模型。主要思想和这篇文章一模一样,但是IR- SDE更早点。
我们使用IR-SDE(如上图)作为图像恢复的基本框架。它采用了类似于DDPM的U-Net架构,但删除了所有自注意层。为了将干净的内容嵌入注入扩散过程,我们引入了一种交叉注意力机制,从预先训练的VLM中学习语义指导。考虑到图像恢复任务中输入大小的变化以及将注意力应用于高分辨率特征的成本的增加,为了提高样本效率,我们只在U-Net的底部块中使用交叉注意力。
另一方面,预测的退化嵌入对于统一图像恢复是有用的,其中目标是用单个模型处理多种退化类型的低质量图像。如图1所示,我们的DA-CLIP准确地对不同数据集和各种退化类型的退化进行了分类,这对于统一的图像恢复至关重要。此外,为了利用这些退化嵌入,我们将它们与即时学习模块相结合,以进一步改进结果,如图3(b)所示。这里的prompt应该就是content embedding。
5. 实验
·数据集的选择

·benchmark数据集上的对比

·可视化实验


6. 讨论
这篇文章好像就做了这么个事:找到一个图像复原的模型,LQ编码并加在crossattn中,从头训练这个模型。审稿意见请看这里。
CLIP是否有必要?或者说直接用分类器是否可以?或者content有用吗?
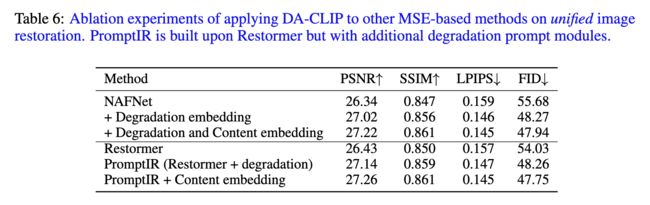
这是作者的消融实验,其实Content对性能影响不大我感觉,因为你的模型只需要根据不同的conditions调用参数完成特定任务就可以了,degradation embedding已经可以做到分类不同任务了,而且你的模型以及不是生成模型了,content确实是多余,在消融实验中LPIPS和FID的提升简直微不足道。此外,degradation embedding是否有必要呢?分类器不可以吗?如果用CLIP没必要,那就相当于作者什么也没做。。