(六)starGAN论文笔记与实战
(六)starGAN论文笔记与实战
-
-
-
- 一、网络架构与目标函数
- 二、完整代码
-
-
一、网络架构与目标函数
starGAN的提出是为了解决多数据集在多域间图像转换的问题,starGAN可以接受多个不同域的训练数据,并且只需要训练一个生成器,就可以拟合所有可用域中的数据。

假如想实现四个域内图像风格的相互转换,要实现这个目标,通过cycleGAN需要创建12个生成器(如图a)。而starGAN的直观构造如图b,只需要一个生成器即可。
StarGAN的大致训练流程:
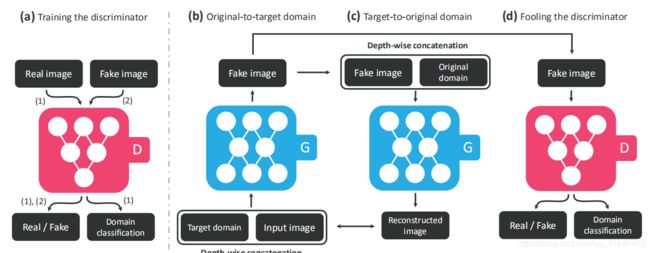
i)如图a,训练判别器,将 real_img 和 fake_img 分别传递给判别器,判别器会判别图像的真假,同时它还会判别该图像来自哪个域(只对real_img 的label做判别)。
ii)如图b,训练生成器,与CGAN类似,这里除了输入图像外,还要输入该图像想转换的目标域,这个目标域类似于约束条件,它要求生成器尽可能去生成该目标域中的图像。
iii)如图c,表示循环一致性的过程,如果只是单纯的使用条件去控制生成器生成,那么生成器就会生成满足条件但可能与输入图像无关的数据,为了避免这种情况,便使用循环一致性的思想,即将生成的图像加上输入图像所在的域作为生成器的输入,希望获得的输出与原输入图像越接近越好。
iiii)表示训练判别器,即将生成器生成的图片交给判别器,让判别器判别图像的真假以及图像所在的域是否正确。
一、对抗性损失
L a d v L_{adv} Ladv = E x [ l o g D s r c ( x ) ] E_x[logD_{src}(x)] Ex[logDsrc(x)] + E x , c [ l o g ( 1 − D s r c ( G ( x , c ) ) ) ] E_{x,c}[log(1-D_{src}(G(x,c)))] Ex,c[log(1−Dsrc(G(x,c)))]
x x x 表示输入, c c c 表示域 label
为了训练过程的稳定以及生成更高质量的图片,论文中采用了WGAN-GP的损失函数,所以对抗性损失写为:
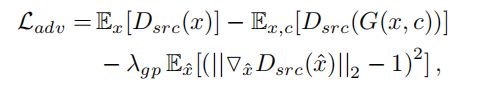
其中 λ g p \lambda_{gp} λgp = 10
二、循环一致性损失
L r e c L_{rec} Lrec = E x , c , c ‘ [ ∣ ∣ x − G ( G ( x , c ) , c ’ ) ∣ ∣ 1 ] E_{x, c, c^‘}[|| x - G(G(x, c), c^’) ||_1] Ex,c,c‘[∣∣x−G(G(x,c),c’)∣∣1]
c c c 表示目标域标签, c ’ c^’ c’ 表示原始输入图像的域标签
三、Domain Classfication Loss(这段还是看论文原文比较好)

将上面几个损失函数组合一下,就可以得到判别器和生成器的最终目标函数。
判别器和生成器的最终目标函数分别为:

其中 λ c l s \lambda_{cls} λcls = 1 and λ r e c \lambda_{rec} λrec = 10
Training with Multiple Datasets(多数据集训练)
starGAN的一大优势就是它可以同时用多个数据集进行训练,但是这会存在一个问题:就CelebA和RaFD这两个数据集而言,前者包含头发颜色和性别等属性, 但它不包含任何的面部表情,同理后者相反。这会造成一个问题也就是:the complete information on the label vector c′ is required when reconstructing the input image x from the translated image G(x, c)
解决办法: Mask Vector
Mask Vector 让模型可以忽略未知的标签以及只关注特定数据集提供的标签, 我们首先引入一个 m 维的 mask vector ,在starGAN中使用一个 n 维的 one-hot 向量来表示 m , 其中 n 是数据集的数目
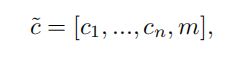
c i c_i ci 表示 第 i 个数据集的标签 label 向量, 已知的向量 c i c_i ci 能够用一个二进制向量或者一个one-hot向量来表示, 而剩下的 n - 1 个 label, 我们可以给其赋予0值。
二、完整代码
import argparse
import torch
import torchvision
import os
import numpy as np
import time
import itertools
import datetime
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader, Dataset
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import glob
import random
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
parser = argparse.ArgumentParser()
parser.add_argument("--epoch", type=int, default=0, help="epoch to start training from")
parser.add_argument("--conv_dim", type=int, default=64)
parser.add_argument("--n_epochs", type=int, default=20, help="number of epochs of training")
parser.add_argument("--dataset_name", type=str, default="img_align_celeba", help="name of the dataset")
parser.add_argument("--batch_size", type=int, default=16, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0001, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--decay_epoch", type=int, default=10, help="epoch from which to start lr decay")
parser.add_argument("--img_height", type=int, default=128, help="size of image height")
parser.add_argument("--img_width", type=int, default=128, help="size of image width")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between saving generator samples")
parser.add_argument("--checkpoint_interval", type=int, default=1, help="interval between model checkpoints")
parser.add_argument("--residual_blocks", type=int, default=6, help="number of residual blocks in generator")
parser.add_argument("--n_critic", type=int, default=5, help="number of training iterations for WGAN discriminator")
parser.add_argument(
"--selected_attrs",
"--list",
nargs="+", # 表示读取的命令行参数的个数, ‘+’表示读取一个或多个, ‘*’表示0个或多个
help="selected attributes for the CelebA dataset",
default=["Black_Hair", "Blond_Hair", "Brown_Hair", "Male", "Young"],
)
opt = parser.parse_args(args=[])
print(opt)
random.seed(22)
torch.manual_seed(22)
os.makedirs('Model/starGAN', exist_ok=True)
os.makedirs('runs/starGAN', exist_ok=True)
os.makedirs('Picture/starGAN', exist_ok=True)
cuda = True if torch.cuda.is_available() else False
c_dim = len(opt.selected_attrs)
input_shape = [opt.channels, opt.img_height, opt.img_width]'''数据集类'''
class CelebADataset(Dataset):
def __init__(self, root, transforms_ = None, mode = 'train', attributes = None):
'''
root: 数据集根路径; attributes: selected_attrs
'''
self.transform = transforms.Compose(transforms_)
self.selected_attrs = attributes
self.files = sorted(glob.glob('{}/*.jpg'.format(root))) # 得到所有图片的路径
# 后面2000张图片作为测试集
self.files = self.files[:-2000] if mode == 'train' else self.files[-2000:]
self.label_path = glob.glob('{}/*.txt'.format(root))[0] # 获得img_align_celeba.txt(标签文本)的路径
self.annotations = self.get_annotations() # 获得所有图片指定特征的标签
def get_annotations(self):
"""Extracts annotations for CelebA"""
annotations = {}
# Python rstrip() 删除 string 字符串末尾的指定字符(默认为空格)
lines = [line.rstrip() for line in open(self.label_path, 'r')] # txt文件是一行一行读取
# str.split(str="", num=string.count(str)). 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
# str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。num -- 分割次数。默认为 -1, 即分隔所有
# 返回分割后的字符串列表。
self.label_names = lines[1].split()
for _, line in enumerate(lines[2:]):
filename, *values = line.split()
labels = []
for attr in self.selected_attrs:
idx = self.label_names.index(attr) # 得到索引
labels.append(1 * (values[idx] == '1'))
annotations[filename] = labels
return annotations
def __getitem__(self, index):
'''需要返回图片以及对应的特征标签'''
filepath = self.files[index % len(self.files)] # 例如:'../dataset/celeba/img_align_celeba\\000001.jpg'
filename = filepath.split('/')[-1] # ‘img_align_celeba\\000001.jpg’
filename = filename.split('\\')[-1] # '000001.jpg'
img = self.transform(Image.open(filepath)) # transform 传入图片
label = self.annotations[filename]
label = torch.FloatTensor(np.array(label))
return img, label
def __len__(self):
return len(self.files)
'''自定义学习率类'''
class LambdaLR:
def __init__(self, n_epochs, offset, decay_start_epoch):
assert n_epochs > decay_start_epoch, 'Decay must start before the training session ends!'
self.n_epochs = n_epochs
self.offset = offset
self.decay_start_epoch = decay_start_epoch
def step(self, epoch):
return 1.0 - (epoch + self. offset - self.decay_start_epoch)/(self.n_epochs - self.decay_start_epoch)
'''读取数据集'''
train_transform = [
transforms.Resize(int(1.12 * opt.img_height), Image.BICUBIC),
transforms.RandomCrop(opt.img_height),
transforms.RandomHorizontalFlip(), # 随机水平反转, p默认为0.5
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
val_transform = [
transforms.Resize((opt.img_height, opt.img_width), Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
dataloader=DataLoader(CelebADataset('../dataset/celeba/img_align_celeba',train_transform,'train',opt.selected_attrs),
batch_size=opt.batch_size,shuffle=True, num_workers=0)
val_dataloader=DataLoader(CelebADataset('../dataset/celeba/img_align_celeba',val_transform,'test',
opt.selected_attrs), batch_size = 10,shuffle = True, num_workers = 0)
'''网络结构'''
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, 'bias') and m.bias is not None:
torch.nn.init.constant_(m.bias.data, 0.0)
elif classname.find('InstanceNorm2d') != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
##############################
# RESNET
##############################
class ResidualBlock(nn.Module):
def __init__(self , in_features):
super(ResidualBlock, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_features, in_features, kernel_size=3, stride=1, padding=1, bias=False),
# 这里我没搞懂为什么要把affine和track_running_stats都设置为True
nn.InstanceNorm2d(in_features, affine=True, track_running_stats=True),
nn.ReLU(True),
nn.Conv2d(in_features, in_features, 3,1,1,bias=False),
nn.InstanceNorm2d(in_features,affine=True, track_running_stats=True),
)
def forward(self, x):
return x + self.model(x) # 这里不知道为什么结果不需要再经过一层ReLU激活层
##############################
# Generator
##############################
class Generator(nn.Module):
def __init__(self, conv_dim = 64, c_dim = 5, res_blocks = 6):
super(Generator, self).__init__()
layers = []
# input layer 输入shape [b, 3+5, 128, 128]
layers.append(nn.Conv2d(3+c_dim, conv_dim, 7, 1, 3, bias=False)) # --> [b, 64, 128, 128]
layers.append(nn.InstanceNorm2d(conv_dim, affine=True, track_running_stats=True))
layers.append(nn.ReLU(True))
# Down-sampling layers.
curr_dim = conv_dim
for _ in range(2):
# --> [b, 128, 64, 64] -->[b, 256, 32, 32]
layers.append(nn.Conv2d(curr_dim, curr_dim*2, 4, 2, 1, bias=False))
layers.append(nn.InstanceNorm2d(curr_dim*2, affine=True, track_running_stats=True))
layers.append(nn.ReLU(True))
curr_dim = curr_dim * 2
# Residual blocks
for _ in range(res_blocks): #->[b, 256, 32, 32] 保持不变
layers.append(ResidualBlock(curr_dim))
# Up-sampling layers.
for _ in range(2): #->[b, 128, 64, 64] ->[b, 64, 128, 128]
layers.append(nn.ConvTranspose2d(curr_dim, curr_dim//2, 4, 2, 1, bias = False))
layers.append(nn.InstanceNorm2d(curr_dim//2, affine=True, track_running_stats=True)),
layers.append(nn.ReLU(True))
curr_dim = curr_dim//2
# Output layer -->[b, 3, 128, 128]
layers.append(nn.Conv2d(curr_dim, 3, 7, 1, 3, bias = False))
layers.append(nn.Tanh())
self.model = nn.Sequential(*layers)
def forward(self, x, c):
# Replicate spatially and concatenate domain information.
# Note that this type of label conditioning does not work at all if we use reflection padding in Conv2d.
# This is because instance normalization ignores the shifting (or bias) effect.
c = c.view(c.size(0), c.size(1), 1, 1) # --> [b, c_dim, 1, 1]
c = c.repeat(1, 1, x.size(2), x.size(3)) # --> [b, c_dim, 128, 128]
x = torch.cat((x, c), 1)
return self.model(x)
##############################
# Discriminator
##############################
class Discriminator(nn.Module):
"""Discriminator network with PatchGAN. 不使用InstanceNorm2d层"""
def __init__(self, img_size = 128, conv_dim = 64, c_dim = 5, repeat_num = 6):
super(Discriminator, self).__init__()
layers = [] # 输入shape [b, 3, 128, 128]
layers.append(nn.Conv2d(3, conv_dim, 4, 2, 1)) # --> [b, 64, 64, 64]
layers.append(nn.LeakyReLU(0.01))
curr_dim = conv_dim
for i in range(1, repeat_num):
#->[b,128,32,32]->[b,256,16,16]->[b,512,8,8]->[b,1024,4,4]->[b,2048,2,2]
layers.append(nn.Conv2d(curr_dim, curr_dim*2, 4, 2, 1))
layers.append(nn.LeakyReLU(0.01))
curr_dim = curr_dim * 2
self.main = nn.Sequential(*layers)
# Output 1: PatchGAN
self.out1 = nn.Conv2d(curr_dim, 1, 3, 1, 1, bias = False) # --> [b, 1, 2, 2]
# Output 2: Class prediction
kernel_size = img_size//2**repeat_num # 128//2**6 = 2
self.out2 = nn.Conv2d(curr_dim, c_dim, kernel_size = kernel_size, bias=False)#->[b, 5, 1, 1]
def forward(self, img):
h = self.main(img)
out_adv = self.out1(h)
out_cls = self.out2(h)
return out_adv, out_cls.view(out_cls.size(0), out_cls.size(1))
def print_network(model):
num = 0
for p in model.parameters():
num += p.numel() # numel()返回数组中元素个数
print(model)
print("The number of parameters: {}".format(num))
generator = Generator(conv_dim=opt.conv_dim,c_dim=c_dim, res_blocks=opt.residual_blocks)
discriminator = Discriminator(img_size=opt.img_height, conv_dim=opt.conv_dim, c_dim=c_dim, repeat_num=6)
print_network(generator)
print_network(discriminator) writer = SummaryWriter('runs/starGAN')
'''训练'''
# Loss Function
criterion_cycle = torch.nn.L1Loss()
def criterion_cls(logit, target):
return F.binary_cross_entropy_with_logits(logit, target)
# Loss weight
lambda_cls = 1
lambda_rec = 10
lambda_gp = 10
# if cuda:
# generator.cuda()
# discriminator.cuda()
# criterion_cycle.cuda()
if opt.epoch != 0:
# Load pretrained models
generator.load_state_dict(torch.load('Model/starGAN/generator_{}.pth'.format(opt,epoch)))
discriminator.load_state_dict(torch.load('Model/starGAN/discriminator_{}.pth'.format(opt.epoch)))
else:
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr = opt.lr, betas=(opt.b1,opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(),lr = opt.lr, betas=(opt.b1, opt.b2))
# Learning rate update schedulers
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch,
opt.decay_epoch).step)
lr_scheduler_D = torch.optim.lr_scheduler.LambdaLR(optimizer_D, lr_lambda=LambdaLR(opt.n_epochs,opt.epoch,
opt.decay_epoch).step)
# Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
Tensor = torch.FloatTensor
def compute_gradient_penlty(D, real_img, fake_img):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_img.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_img + (1 - alpha) * fake_img).requires_grad_(True)
d_interpolates, _ = D(interpolates)
grad_Tensor = Variable(Tensor(np.ones(d_interpolates.shape)), requires_grad = False)
# Get gradient w.r.t. interpolates
gradients = torch.autograd.grad(
outputs = d_interpolates,
inputs = interpolates,
grad_outputs = grad_Tensor,
create_graph = True,
retain_graph = True,
only_inputs = True
)[0]
gradients = gradients.view(gradients.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim = 1) - 1) ** 2).mean()
return gradient_penalty
# ["Black_Hair", "Blond_Hair", "Brown_Hair", "Male", "Young"]
label_changes = [
((0,1), (1,0), (2,0)), # Set to black hair
((0,0), (1,1), (2,0)), # Set to blond hair
((0,0), (1,0), (2,1)), # Set to brown hair
((3,-1),), # Flip gender
((4,-1),) # Age flip
]
def save_images(batches_done):
"""Saves a generated sample of domain translations"""
val_imgs, val_labels = next(iter(val_dataloader))
val_imgs = Variable(val_imgs.type(Tensor))
val_labels = Variable(val_labels.type(Tensor))
img_samples = None
for i in range(10):
generator.eval() # 设置为测试模式
img, label = val_imgs[i], val_labels[i] # img、label (torch.Size([3, 128, 128]), torch.Size([5]))
# Repeat for number of label changes
# 这里就是将img和label分别复制到一共c_dim份,每一份对应一种变化
imgs = img.repeat(c_dim, 1, 1, 1) # -> [c_dim, 3, 128, 128]
labels = label.repeat(c_dim, 1) # ->[c_dim, 5]
# Make changes to labels
for index, changes in enumerate(label_changes):
for x, y in changes:
labels[index, x] = 1 - labels[index, x] if y == -1 else y
# Generate translations
gen_imgs = generator(imgs, labels)
# Concatenate images by width
gen_imgs = torch.cat([x for x in gen_imgs.data], -1)
img_sample = torch.cat((img.data, gen_imgs), -1)
# Add as row to generated samples
img_samples = img_sample if img_samples is None else torch.cat((img_samples, img_sample), -2)
save_image(img_samples, 'Picture/starGAN/{}.png'.format(batches_done))
# ----------
# Training
# ----------
start_time = time.time()
for epoch in range(opt.epoch, opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
# Model inputs
imgs = Variable(imgs.type(Tensor))
labels = Variable(labels.type(Tensor))
# Sample labels as generator inputs
sample_c = Variable(Tensor(np.random.randint(0, 2, size = (imgs.size(0), c_dim))))
# Generate fake batch of images
fake_imgs = generator(imgs, sample_c)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# real image
real_validity, pred_cls = discriminator(imgs)
# fake image
fake_validity, _ = discriminator(fake_imgs.detach())
# Gradient penalty
gradient_penalty = compute_gradient_penlty(discriminator, imgs, fake_imgs) # !!!!!!!!!!!!!!!!!!!!!!
# Adversarial loss
loss_D_adv = -torch.mean(real_validity) + torch.mean(fake_validity) + lambda_gp * gradient_penalty
# cls loss
loss_D_cls = criterion_cls(pred_cls, labels)
# total loss
loss_D = loss_D_adv + loss_D_cls * lambda_cls
loss_D.backward()
optimizer_D.step()
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Every n_critic times update generator
if i % opt.n_critic == 0:
# Translate and reconstruct image
gen_imgs = generator(imgs, sample_c)
recov_imgs = generator(gen_imgs, labels)
# Discriminator evaluates translated image
fake_validity, pred_cls = discriminator(gen_imgs)
# Adversarial loss
loss_G_adv = -torch.mean(fake_validity)
# cls loss
loss_G_cls = criterion_cls(pred_cls, sample_c)
# Reconstruction loss
loss_G_rec = criterion_cycle(recov_imgs, imgs)
# total loss
loss_G = loss_G_adv + lambda_cls * loss_G_cls + lambda_rec * loss_G_rec
loss_G.backward()
optimizer_G.step()
# --------------
# Log Progress
# --------------
# Determine approximate time left
batches_done = epoch * len(dataloader) + i
batches_left = opt.n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds = batches_left * (time.time() - start_time) / (batches_done+1))
if i % opt.n_critic == 0:
# print log
print(
'[Epoch {}/{} [Batch {}/{}] [D:{:.3f} adv:{:.3f},cls:{:.3f}] [G:{:.3f} adv:{:.3f} cls:{:.3f} cyc:{:.3f}]] ETA: {}'
.format(epoch,opt.n_epochs,i,len(dataloader),loss_D.item(),loss_D_adv.item(),
loss_D_cls.item(),loss_G.item(),loss_G_adv.item(),loss_G_cls.item(),loss_G_rec.item(),time_left)
)
writer.add_scalar('LOSS/G', loss_G, i)
writer.add_scalar('LOSS/D', loss_D, i)
# If at sample interval sample and save image
if batches_done % opt.sample_interval == 0 :
save_images(batches_done)
lr_scheduler_G.step()
lr_scheduler_D.step()
if opt.checkpoint_interval != -1 and epoch % opt.checkpoint_interval == 0:
# Save model checkpoints
torch.save(generator.state_dict(), "Model/starGAN/generator_%d.pth" % epoch)
torch.save(discriminator.state_dict(), "Model/starGAN/discriminator_%d.pth" % epoch)