【论文阅读】【综述】Deep Learning for 3D Point Clouds: A Survey
文章目录
- Survey
-
- 3D Shape Classification
-
- Projection based
-
- Multi-view
- Voxel
- Point based
-
- Pointwise MLP network
- Convolution-based Networks
- Graph based
- Data Indexing based
- 3D Object Detection
-
- Region Proposal-based Methods
-
- Multi-view Methods
- Segmentation-based Methods
- Frustum-based Methods
- Single Shot Methods
- 接下来就是我并不是很了解的部分
- 3D Tracking
- 3D Scene Flow Estimation
- 3D Point Cloud Segmentation
-
- 3D Semantic Segmentation
-
- Projection based
- Point-based networks
- Instance Segmentation
- Part Segmentation
本文是最新的使用深度学习处理点云的综述文章,本文所提及的方法非常全,可以作为一个文章索引来看,而且本论文对方法的分类也很有意义。但是作为综述性文章,本文每章节的结论有点弱,并没有通过对文章的综述产生太多指导性的结论。但总体来说,这篇文章对于读者,起到了查缺补漏和搭建知识框架的作用。
对于做点云的同学,我还是非常建议阅读以下本文的。
本博客与其他有关该survey的博客的区别在于,本博客不翻译该survey,而是细节讲述一些其中提到的方法,和总结一些我的理解。
Survey
1、数据集有:
- ModelNet [6]
- ShapeNet [7]
- ScanNet [8]
- Semantic3D [9]
- KITTI Vision Benchmark Suite [10]
还有一些自动驾驶的数据集也包含了3D object detection & tracking的问题。
2、3D问题的分类与图像中的基本是一样的:
- 3D shape classification
- 3D object detection and tracking
- 3D point cloud segmentation
3、所有的方法按照解决的问题,使用的方法按照如下分类:

3D Shape Classification
该问题对应图像中的图像分类问题,是最简单的问题。按照图像处理的发展过程,可以认为,这部分提出来的网络将是Object Detection,Tracking和Segmentation方法的主干网络。
ModelNet40是一个普遍使用的数据集,排名可以在官网找到
Projection based
作者把Voxel的方法解归入到了Projection based的方法中,认为体素的构建过程是点云向3D栅格的投影过程。
Multi-view
典型的方法就是MVCNN[15],将pointcloud投影到不同的视角下,其网络框架如下:
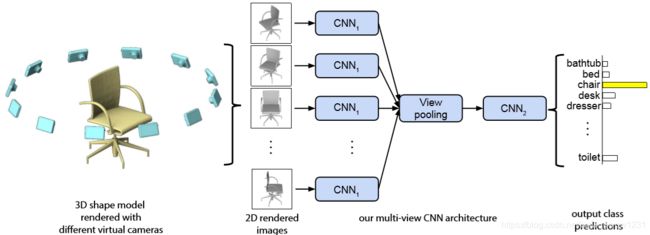
本文漏掉了目前ModelNet40精度最高的方法RotationNet,也是Multi-view类型的。相比于MVCNN,RotationNet使用了更多的视角,并在处理了每个视角的关系。其网络结构如下:

Multi-View的方法有以下几个特点:
- 理解简单,就是将点云投影到不同的view
- 网络结构已有,投影到2D平面之后,就可以用处理图像的CNN处理
- 精度高:RotationNet已有体现
- 处理速度慢:要处理多幅图像
- 对于一般场景不适用:因为要获取multi-view,例如智能车场景,就不可能获取多个view的投影
Voxel
典型方法以VoxNet[22]为例,就是把点云投影为占据栅格,然后使用3D convolution进行计算,具体结构如下图:
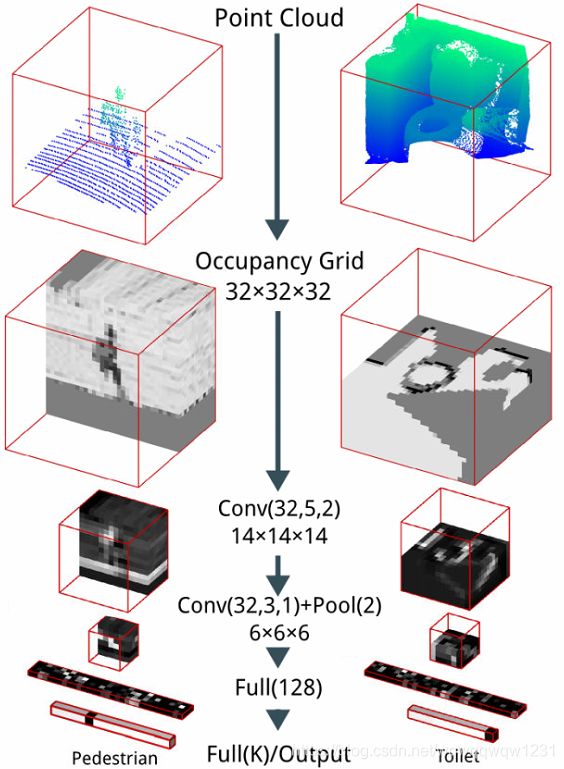
Voxel的方法在Object Detection的网络中也广泛使用,而其主干网络拿出来就可以作为Classification的网络使用,不同的代表有使用3D卷积的VoxelNet,使用2D卷积的PIXOR,使用Pointwise的feature构建Voxel的PointPillar等
Voxel的有以下特点:
- 理解容易,就是栅格化然后使用3D或者2D卷积
- 速度慢,占用内存大:内存占用和计算量都是与分辨率的立方有关
- 在体素化的过程中容易丢失信息,分辨率(精度)与计算效率的trade-off明显
Point based
Pointwise MLP network
这类方法以PointNet和PointNet++为主要代表,也是目前影响力最大的方法,Object Detection中Point based的主干网络大多用此网络搭建。典型结构如下:
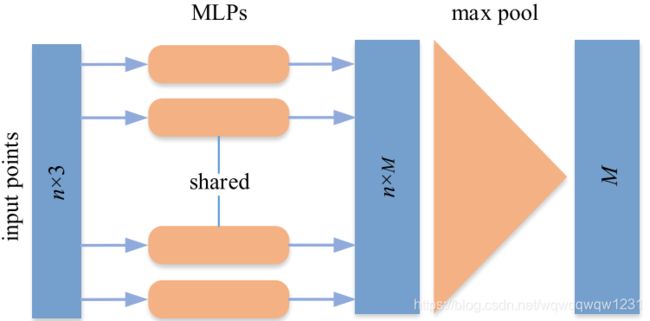
PontNet++的网络详解
在Pointnet++的基础上,又出现了一些改进方法。
Pointwise MLP network类方法的特点如下:
在计算过程中,每个点都对应一个feature,计算每个点的feature都是使用MLP计算,MLP的输入时某个点的feature,输出是这个点的新的feature。对应图像处理中的理解就是,都使用1x1的卷积核,每个像素的feature的计算过程只与自身的feature有关。
Convolution-based Networks
相比于Pointwise MLP的方法来说,Convolution-based方法在于一个点的feature在计算的时候使用了其他点的feature,类比于图像处理中,使用的卷积核不再是1x1,而是出现了3x3这种的卷积核。
而这类方法又分为两种,一种是3D Continuous Convolution Networks(3D连续卷积网络),一种是3D Discrete Convolution Networks(3D离散卷积网络)。理解这两者的区别可以先参考一下图像处理中的RoI Pooling与RoI Align,Conv和Deformable Conv。RoI Pooling和Conv都是对bin处理的,也就是说,认为feature map是与像素一样,分成栅格的。而后者RoI Align和Deformable Conv则认为特征在空间内是连续的,而feature map只不过是离散的采样,通过差值可以较好的恢复特征空间内任意一点的特征。由于认为特征空间是连续的,那么相对于权重空间也是连续的。用KPconv文中的话说:
“we believe that that having a consistent domain for g helps the network to learn meaningful representations.”
其中g是指卷积核。
理解了上述区别,就可以看懂下面一张图:

b)认为特征空间是连续的,c)认为特征空间是离散的。具体的细节需要看具体的论文。
Continuous Convolution Network
这里详细介绍RS-CNN和KP-CNN,来理解Continuous Convolution Networks的内容。
Discrete Convolution Network
这里详细介绍Pointwise Convolutional Neural Network[49]和PointCNN[52],来理解Discrete Convolution Networks的内容。
Graph based
这块内容我看的不多,也只看了Graph-based Methods in Spatial Domain,这里只介绍一下典型的DGCNN[60]
DGCNN的关键公式为如下:
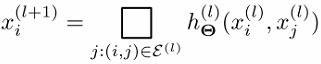
x i x_i xi的新feature是由邻域内的点 x j x_j xj与 x i x_i xi的关系,通过 h θ ( ⋅ ) h_\theta(·) hθ(⋅)(由MLP实现)处理,然后经过aggregated(sum or max)得到。
其中,DGCNN使用的 h θ ( x i , x j ) = M L P ( x i , x j − x i ) h_\theta(x_i,x_j)= MLP(x_i, x_j-x_i) hθ(xi,xj)=MLP(xi,xj−xi)。另外一个是, x i x_i xi的邻域计算不光通过点与点之间的距离,而是包括feature的距离,引用原文:
"Our experiments suggests that it is possible and actually beneficial to recompute the graph using nearest neighbors in the features space produces by each layer. This is a crucial distinction of our method from graph CNNs working on a fixed input graph. Such a dynamic graph update is the reason for the name of our architecture, the Dynamic Graph CNN (DGCNN). "
另外值得文章中提到了Pointnet系列等网络的关系,这里我也来梳理一下:
1)文章中提到了PointNet系列是Graph CNN的特例,也就是Pointnet使用了 h θ ( x i , x j ) = M L P ( x i ) h_\theta(x_i,x_j)=MLP(x_i) hθ(xi,xj)=MLP(xi),PointNet++中的SA层中得特征提取过程则是 h θ ( x i , x j ) = M L P ( x j − x i ) h_\theta(x_i,x_j)= MLP(x_j-x_i) hθ(xi,xj)=MLP(xj−xi)
2)这里再对比一下DGCNN与RS-CNN,下图为RS-Conv的主要公式:
![]() M ( h i j ) M(h_{ij}) M(hij)是与DGCNN中的 h θ ( ⋅ ) h_\theta(·) hθ(⋅)类似, σ ( A ( ) ) \sigma(A()) σ(A())则是DGCNN中的 □ \square □类似,而区别在于RS-Conv中后面相乘 f x j f_{x_j} fxj,也就是 M ( h i j ) M(h_{ij}) M(hij)相当于是权重,而DGCNN中生成直接是feature。这个是由于RS-Conv输入的 x j x_j xj只是点的坐标,而DGCNN中则包含了feature。具体的相似程度,你品,你细品!!
M ( h i j ) M(h_{ij}) M(hij)是与DGCNN中的 h θ ( ⋅ ) h_\theta(·) hθ(⋅)类似, σ ( A ( ) ) \sigma(A()) σ(A())则是DGCNN中的 □ \square □类似,而区别在于RS-Conv中后面相乘 f x j f_{x_j} fxj,也就是 M ( h i j ) M(h_{ij}) M(hij)相当于是权重,而DGCNN中生成直接是feature。这个是由于RS-Conv输入的 x j x_j xj只是点的坐标,而DGCNN中则包含了feature。具体的相似程度,你品,你细品!!
Data Indexing based
有的用Kd-tree,有的用Hash,这里就说一下Kd-Net。Kd-Net的结构如下:

Kd-tree本身是用来组织点云的一种数据结构,是一棵二叉树,叶节点是点云中的点,每一层的兄弟节点都有相邻关系。上图的圆点表示feature,箭头是MLP。
其实也能找到DGCNN与Kd-Net之间的联系:如果把DGCNN中的邻域内找点变成用kd-tree找,k临近点变成1个临近点,则变成Kd-Net。Kd-Net是点云处理早期的一个成果,但其代表了这一类型,我认为这一类型要被convolution或者graph based的方法所取代。
3D Object Detection
3D Object Detection的论文的详解可以看我另外一篇博客,这个survey中提到的我很多都有讲到,也有一些本survey没有提到的。这里就强调一下本篇文章中对分类方法。
Region Proposal-based Methods
就是我们常说的Two-Stage方法,先要生成Proposal,然后根据Proposal内部的特征,再对Proposal进行修成。对应到图像领域典型的就是Faster-RCNN。而通过生成Proposal的不同,可以分为以下三种方式。
Multi-view Methods
说是Multi-view Methods,但其实Proposal的生成方法基本是在BEV(俯视图)中生成。在BEV中生成Proposal有个好处就是:
- Proposal在俯视图中本身就是分离存在的,而不像前视图中很有可能存在重叠。
- 前视图存在透视效应,同一类的Proposal在远近不同的时候Proposal存在尺度上的不同,而俯视图就不存在这个问题。
既然Multi-view的方法要用到BEV,那就少不了对点云进行栅格化(或者叫做体素化),所以Multi-view的方法基本上是使用Grid Convolution,例如2D Convolution和3D Convolution。
Multi-view既然叫Multi-view,自然需要考虑Multi-view特征的融合,所以有一些文章就在讨论如何进行Multi-view的融合。而前视图本身又是相机视角,所以何不在前视图中引入RGB这个特征?这就是本survey中Multi-view Methods中的First所讨论的事情。
Multi-view Methods中的Second所讨论的则是如何增强网络的表示性能,因为用了2D Convolution,所以很多增强手段就可以借鉴图像中得,例如Second中提到的SCANet,这篇文章细看下来,与CBAM就很像啊。
Segmentation-based Methods
上面已经提到了,Multi-view其实是和栅格化(体素化)相联系的,这就相对于第一部分3D Shape Classification中的Projection based的方法。那么Point Based的方法是否也能用到Object Detection的问题中呢?
这里再次借用一下RS-CNN中与图像识别中的网络的对比,其间的相似性可以由前三行表示,那么第四、五行的推出则是自然而然的事情:
| Image Classification | 3D Shape Classification |
|---|---|
| 像素 | 点 |
| 特征图 | 点云中每个点的特征的集合 |
| 特征图的降采样 | 点的降采样 |
| 由特征图的中的一个cell的特征回归box的参数 | 由点云中的点的特征回归box的参数 |
| 由特征图的中的一个cell的特征分类该cell是否对应一个box | 由点云中的点的特征分类该点是否对应一个box |
这也就是Segmentation-based Methods的内在思想。先通过特征提取,得到点的特征,然后用点的特征预测box的参数。
Frustum-based Methods
相机和激光雷达融合的另外一种方法,能不能借鉴已有的2D Object Detection的成果呢?使用2D Object Detection在图像中检测车辆,然后在通过透视,将2D方框变成一个3D的棱台。在棱台中再进行检测,这部分的方法与Segmentation-based Methods类似。
这类方法典型的代表就是Frustum-Net,但这也是早期的一种方法。目前主流方法已经大量使用在BEV中生成Proposal,RGB图像只是用于提取特征了。
Single Shot Methods
我觉得这这一块的分类有问题。该survey把Single Shot Methods分为BEV-based Methods和Point Cloud-based Methods。
先说说为什么我觉得问题,我们一步一步来理解:
1)可以把这两种方法分别对应到Region Proposal-based Methods中的Multi-View Methods和Segmentation-based Methods。因为我在上面已经阐述了,Multi-View Methods基本是在BEV中生成Proposal,所以其处理方法是与BEV-based的方法是一样的,无非是一个Two-stage和One-Stage的问题。Segmentation-based Methods则是使用Point生成Proposal,与Point Cloud-based Methods这个名字对应。
2)那么如果按照这个理解方法,那么原文中对Point Cloud-based Methods的定义就出现了问题:*“These methods convert a point cloud into a regular representation (e.g., 2D map), and then apply CNN to predict both categories and 3D boxes of objects.”*所以说白了,其实这个regular representation和2D map其实也是栅格化(体素化)的一种,无非是在高度上,只有一层栅格而已。3)再看Point Cloud-based Methods中所列举的方法,基本也是用了栅格化的手段(栅格化的高度也并非都是1层,也就是说并不是都变成了2D map),然后很使用CNN。看框架而言,这就是BEV-based Methods啊。
再说说我理解的Point Cloud-based Methods的是什么:
1)先说一下图像处理中的2D Object Detection的问题,如果细看RetinaNet和Faster RCNN,可以看出来其实RetinaNet非常像Faster RCNN的RPN。这就是图像中的One-stage和Two-stage的联系。
2)对比到3D Object Detection,我认为的Point Cloud-based Methods更像是PointRCNN的RPN阶段。但类似于这种的方法我没有看到,可能是因为效果不够好的缘故吧。
我不是说survey中的这种分类方法是错误的,而是说这种分法的气的名称有问题,而且我认为分成这两个类没有太大必要。
接下来就是我并不是很了解的部分
Tracking,Flow Estimation和Segmentation我了解的并不多,相关的论文看的很少,我会更多的记录一下我从该survey中学到的东西。
3D Tracking
3D Tracking是与3D Object Detection有关的,都需要关注物体的box。而survey中提到的3D Tracking提到的与2D Tracking的不同点有 “occlusion, illumination and scale”。但这些2D Tracking存在的问题,在3D Tracking中似乎变得更容易解决一些:
- occlusion:在自动驾驶场景,要tracking的3D box本身就是在三维空间内不互相遮挡的。尤其是在俯视图中,box都是分离的。
- illumination:激光雷达的使用,直接解决了illumination的问题。
- scale:同样,在俯视图中,物体的scale并不随着位置变化
而box的检测在3D Object Detection中解决了,然而后面的时候各种滤波器进行跟踪啊啥的思想山应该和2D是一样的。
3D Scene Flow Estimation
这个问题可以类比到图像中的预测光流的问题。这个问题可以理解为不再是对Object做Tracking,而是要对一个场景中的每个点做Tracking,这个问题就更难了。在这其中,我只看过FlowNet这篇文章,本survey中针对该文章中提到的一个问题就是,动态的场景(尤其是以动态障碍物为主的场景,例如密集的车流中,某个车在上一帧还是看到的是车头,这一帧已经完成了错车,看到的是车尾)的解决方法还是一个开放问题。而且在这个问题上的准确率,还不是很高。
3D Point Cloud Segmentation
Semantic Segmentation最基本的想法就是使用3D Shape Classification的网络作为主干网络,然后设计Encoder-Decoder的网络结构,每个input中的element都能得到一个特征,然后通过特征计算Segmentation的mask。
Instance Segmentation
3D Semantic Segmentation
根据上述所说的基本思想,所以3D Semantic Segmentation的方法也可以按照3D Shape Classification的分类方式进行分类。现在很多文章,提出一个3D Shape Classification的网络时,都会相对应的加上Decoder做一下Semantic Segmentation的测试,以证明网络的效果。
Projection based
Projection based包括以下方法:
- Multi-view:将Point Cloud投影到Multi-view的2D Image上面,然后使用2D Semantic Segmentation的方法,然后再综合Multi-view的结果获取Point Cloud的Segmentation的结果。这种方法的缺点是:1)计算量大,2)结果与选择的视角敏感。
- Spherical Representation:主要是做自动驾驶场景的Semantic Segmentation,这是由于采集设备激光雷达的工作原理所致,具体想法与Multi-view差不多,只不过是只用了一个view。
- Voxel:面临着同样的困难,在从Point转到Voxel的过程中会丢失信息,分辨率越高,丢失信息越少,但计算量也会越大。但好处就是:Good scalability is one of the remarkable advantages of volumetric representation. Specifically, volumetric-based networks are free to be trained and tested in point clouds with different spatial sizes.
- Permutohedral Lattice Representation:不了解,没读过
Point-based networks
同样,分为:
- Point-wise MLP
- Convoution-based
- Graph based