Meltdown: Reading Kernel Memory from User Space论文翻译
Meltdown: Reading Kernel Memory from User Space翻译
摘要(Abstract)
The security of computer systems fundamentally relies on memory isolation, e.g., kernel address ranges are marked as non-accessible and are protected from user access. In this paper, we present Meltdown. Meltdown exploits side effects of out-of-order execution on modern processors to read arbitrary kernel-memory locations including personal data and passwords. Out-of-order execution is an indispensable performance feature and present in a wide range of modern processors. The attack is independent of the operating system, and it does not rely on any software vulnerabilities. Meltdown breaks all security assumptions given by address space isolation as well as paravirtualized environments and, thus, every security mechanism building upon this foundation. On affected systems, Meltdown enables an adversary to read memory of other processes or virtual machines in the cloud without any permissions or privileges, affecting millions of customers and virtually every user of a personal computer. We show that the KAISER defense mechanism for KASLR [8] has the important (but inadvertent) side effect of impeding Meltdown. We stress that KAISER must be deployed immediately to prevent large-scale exploitation of this severe information leakage.
内存隔离是计算机系统安全的基础,例如:内核空间的地址段往往是标记为受保护的,用户态程序读写内核地址则会触发异常,从而阻止其访问。在这篇文章中,我们会详细描述这个叫Meltdown的硬件漏洞。Meltdown是利用了现代处理器上乱序执行(out-of-order execution)的副作用(side effect),使得用户态程序也可以读出内核空间的数据,包括个人私有数据和密码。由于可以提高性能,现代处理器广泛采用了乱序执行特性。利用Meltdown进行攻击的方法和操作系统无关,也不依赖于软件的漏洞。地址空间隔离带来的安全保证被Meltdown给无情的打碎了(半虚拟化环境也是如此),因此,所有基于地址空间隔离的安全机制都不再安全了。在受影响的系统中,Meltdown可以让一个攻击者读取其他进程的数据,或者读取云服务器中其他虚拟机的数据,而不需要相应的权限。这份文档也说明了KAISER(本意是解决KASLR不能解决的问题)可以防止Meltdown攻击。因此,我们强烈建议必须立即部署KAISER,以防止大规模、严重的信息泄漏。
1.简介(Introduction)
A central security feature of today’s operating systems is memory isolation. Operating systems ensure that user applications cannot access each other’s memories and prevent user applications from reading or writing kernel memory. This isolation is a cornerstone of our computing environments and allows running multiple applications on personal devices or executing processes of multiple users on a single machine in the cloud.
当今操作系统的核心安全特性之一是内存隔离。所谓内存隔离就是操作系统要确保用户应用程序不能访问彼此的内存,此外,它也要阻止用户应用程序对内核空间的访问。在个人设备上,多个进程并行运行,我们需要隔离彼此。在云计算环境中,共享同一台物理主机的多个用户(虚拟机)的多个进程也是共存的,我们也不能让某个用户(虚拟机)的进程能够访问到其他用户(虚拟机)的进程数据。因此,这种内核隔离是我们计算环境的基石。
On modern processors, the isolation between the kernel and user processes is typically realized by a supervisor bit of the processor that defines whether a memory page of the kernel can be accessed or not. The basic idea is that this bit can only be set when entering kernel code and it is cleared when switching to user processes. This hardware feature allows operating systems to map the kernel into the address space of every process and to have very efficient transitions from the user process to the kernel, e.g., for interrupt handling. Consequently, in practice, there is no change of the memory mapping when switching from a user process to the kernel.
在现代处理器上,内核和用户地址空间的隔离通常由处理器控制寄存器中的一个bit实现(该bit被称为supervisor bit,标识当前处理器处于的模式),该bit定义了是否可以访问kernel space的内存页。基本的思路是:当执行内核代码的时候才设置此位等于1,在切换到用户进程时清除该bit。有了这种硬件特性的支持,操作系统可以将内核地址空间映射到每个进程。在用户进程执行过程中,往往需要从用户空间切换到内核空间,例如用户进程通过系统调用请求内核空间的服务,或者当在用户空间发生中断的时候,需要切换到内核空间执行interrupt handler,以便来处理外设的异步事件。考虑到从用户态切换内核态的频率非常高,如果在这个过程中地址空间不需要切换,那么系统性能就不会受到影响。
In this work, we present Meltdown1. Meltdown is a novel attack that allows overcoming memory isolation completely by providing a simple way for any user process to read the entire kernel memory of the machine it executes on, including all physical memory mapped in the kernel region. Meltdown does not exploit any software vulnerability, i.e., it works on all major operating systems. Instead, Meltdown exploits side-channel information available on most modern processors, e.g., modern Intel microarchitectures since 2010 and potentially on other CPUs of other vendors.
While side-channel attacks typically require very specific knowledge about the target application and are tailored to only leak information about its secrets, Meltdown allows an adversary who can run code on the vulnerable processor to obtain a dump of the entire kernel address space, including any mapped physical memory. The root cause of the simplicity and strength of Meltdown are side effects caused by out-of-order execution.
在这项工作中,我们提出了利用meltdown漏洞进行攻击的一种全新的方法,通过这种方法,任何用户进程都可以攻破操作系统对地址空间的隔离,通过一种简单的方法读取内核空间的数据,这里就包括映射到内核地址空间的所有的物理内存。Meltdown并不利用任何的软件的漏洞,也就是说它对任何一种操作系统都是有效的。相反,它是利用大多数现代处理器(例如2010年以后的Intel微架构(microarchitectural),其他CPU厂商也可能潜伏这样的问题)上的侧信道(side-channel)信息来发起攻击。一般的侧信道攻击(side-channel attack)都需要知道攻击目标的详细信息,然后根据这些信息指定具体的攻击方法,从而获取秘密数据。Meltdown攻击方法则不然,它可以dump整个内核地址空间的数据(包括全部映射到内核地址空间的物理内存)。Meltdown攻击力度非常很大,其根本原因是利用了乱序执行的副作用(side effect)。
Out-of-order execution is an important performance feature of today’s processors in order to overcome latencies of busy execution units, e.g., a memory fetch unit needs to wait for data arrival from memory. Instead of stalling the execution, modern processors run operations out-of-order i.e., they look ahead and schedule subsequent operations to idle execution units of the processor. However, such operations often have unwanted side-effects, e.g., timing differences [28, 35, 11] can leak information from both sequential and out-of-order execution.
有时候CPU执行单元在执行的时候会需要等待操作结果,例如加载内存数据到寄存器这样的操作。为了提高性能,CPU并不是进入stall状态,而是采用了乱序执行的方法,继续处理后续指令并调度该指令去空闲的执行单元去执行。然而,这种操作常常有不必要的副作用,而通过这些执行指令时候的副作用,例如时序方面的差异[ 28, 35, 11 ],我们可以窃取到相关的信息。
From a security perspective, one observation is particularly significant: Out-of-order; vulnerable CPUs allow an unprivileged process to load data from a privileged (kernel or physical) address into a temporary CPU register. Moreover, the CPU even performs further computations based on this register value, e.g., access to an array based on the register value. The processor ensures correct program execution, by simply discarding the results of the memory lookups (e.g., the modified register states), if it turns out that an instruction should not have been executed. Hence, on the architectural level (e.g., the abstract definition of how the processor should perform computations), no security problem arises.
虽然性能提升了,但是从安全的角度来看却存在问题,关键点在于:在乱序执行下,被攻击的CPU可以运行未授权的进程从一个需要特权访问的地址上读出数据并加载到一个临时的寄存器中。CPU甚至可以基于该临时寄存器的值执行进一步的计算,例如,基于该寄存器的值来访问数组。当然,CPU最终还是会发现这个异常的地址访问,并丢弃了计算的结果(例如将已经修改的寄存器值)。虽然那些异常之后的指令被提前执行了,但是最终CPU还是力挽狂澜,清除了执行结果,因此看起来似乎什么也没有发生过。这也保证了从CPU体系结构角度来看,不存在任何的安全问题。
However, we observed that out-of-order memory lookups influence the cache, which in turn can be detected through the cache side channel. As a result, an attacker can dump the entire kernel memory by reading privileged memory in an out-of-order execution stream, and transmit the data from this elusive state via a microarchitectural covert channel (e.g., Flush+Reload) to the outside world. On the receiving end of the covert channel, the register value is reconstructed. Hence, on the microarchitectural level (e.g., the actual hardware implementation), there is an exploitable security problem.
然而,我们可以观察乱序执行对cache的影响,从而根据这些cache提供的侧信道信息来发起攻击。具体的攻击是这样的:攻击者利用CPU的乱序执行的特性来读取需要特权访问的内存地址并加载到临时寄存器,程序会利用保存在该寄存器的数据来影响cache的状态。然后攻击者搭建隐蔽通道(例如,Flush+Reload)把数据传递出来,在隐蔽信道的接收端,重建寄存器值。因此,在CPU微架构(和实际的CPU硬件实现相关)层面上看的确是存在安全问题。
Meltdown breaks all security assumptions given by the CPU’s memory isolation capabilities. We evaluated the attack on modern desktop machines and laptops, as well as servers in the cloud. Meltdown allows an unprivileged process to read data mapped in the kernel address space, including the entire physical memory on Linux and OS X, and a large fraction of the physical memory on Windows. This may include physical memory of other processes, the kernel, and in case of kernel-sharing sandbox solutions (e.g., Docker, LXC) or Xen in paravirtualization mode, memory of the kernel (or hypervisor), and other co-located instances. While the performance heavily depends on the specific machine, e.g., processor speed, TLB and cache sizes, and DRAM speed, we can dump kernel and physical memory with up to 503KB/s. Hence, an enormous number of systems are affected.
CPU苦心经营的内核隔离能力被Meltdown轻而易举的击破了。我们对现代台式机、笔记本电脑以及云服务器进行了攻击,并发现在Linux和OS X这样的系统中,meltdown可以让用户进程dump所有的物理内存(由于全部物理内存被映射到了内核地址空间)。而在Window系统中,meltdown可以让用户进程dump大部分的物理内存。这些物理内存可能包括其他进程的数据或者内核的数据。在共享内核的沙箱(sandbox)解决方案(例如Docker,LXC)或者半虚拟化模式的Xen中,dump的物理内存数据也包括了内核(即hypervisor)以及其他的guest OS的数据。根据系统的不同(例如处理器速度、TLB和高速缓存的大小,和DRAM的速度),dump内存的速度可以高达503kB/S。因此,Meltdown的影响是非常广泛的。
The countermeasure KAISER [8], originally developed to prevent side-channel attacks targeting KASLR, inadvertently protects against Meltdown as well. Our evaluation shows that KAISER prevents Meltdown to a large extent. Consequently, we stress that it is of utmost importance to deploy KAISER on all operating systems immediately. Fortunately, during a responsible disclosure window, the three major operating systems (Windows, Linux, and OS X) implemented variants of KAISER and will roll out these patches in the near future.
我们提出的对策是KAISER[ 8 ],KAISER最初是为了防止针对KASLR的侧信道攻击,不过无意中也意外的解决了Meltdown漏洞。我们的评估表明,KAISER在很大程度上防止了Meltdown,因此,我们强烈建议在所有操作系统上立即部署KAISER。幸运的是,三大操作系统(Windows、Linux和OS X)都已经实现了KAISER变种,并会在不久的将来推出这些补丁。
Meltdown is distinct from the Spectre Attacks [19] in several ways, notably that Spectre requires tailoring to the victim process’s software environment, but applies more broadly to CPUs and is not mitigated by KAISER.
熔断(Meltdown)与幽灵(Spectre)攻击[19] 有几点不同,最明显的不同是发起幽灵攻击需要了解受害者进程的软件环境并针对这些信息修改具体的攻击方法。不过在更多的CPU上存在Spectre漏洞,而且KAISER对Spectre无效。
Contributions. The contributions of this work are:
- We describe out-of-order execution as a new, extremely powerful, software-based side channel.
- We show how out-of-order execution can be combined with a microarchitectural covert channel to
transfer the data from an elusive state to a receiver on the outside. - We present an end-to-end attack combining out-oforder execution with exception handlers or TSX, to read arbitrary physical memory without any permissions or privileges, on laptops, desktop machines,
and on public cloud machines. - We evaluate the performance of Meltdown and the effects of KAISER on it.
这项工作的贡献包括:
1、 我们首次发现可以通过乱序执行这个侧信道发起攻击,攻击力度非常强大
2、 我们展示了如何通过乱序执行和处理器微架构的隐蔽通道来传输数据,泄露信息。
3、 我们展示了一种利用乱序执行(结合异常处理或者TSX)的端到端的攻击方法。通过这种方法,我们可以在没有任何权限的情况下读取了笔记本电脑,台式机和云服务器上的任意物理内存。
4、 我们评估了Meltdown的性能以及KAISER对它的影响
Outline. The remainder of this paper is structured as follows: In Section 2, we describe the fundamental problem which is introduced with out-of-order execution. In Section 3, we provide a toy example illustrating the side channel Meltdown exploits. In Section 4, we describe the building blocks of the full Meltdown attack. In Section 5, we present the Meltdown attack. In Section 6, we evaluate the performance of the Meltdown attack on several different systems. In Section 7, we discuss the effects of the software-based KAISER countermeasure and propose solutions in hardware. In Section 8, we discuss related work and conclude our work in Section 9.
本文概述:本文的其余部分的结构如下:在第2节中,我们描述了乱序执行带来的基本问题,在第3节中,我们提供了一个简单的示例来说明Meltdown利用的侧信道。在第4节中,我们描述了Meltdown攻击的方块结构图。在第5节中,我们展示如何进行Meltdown攻击。在第6节中,我们评估了几种不同系统上的meltdown攻击的性能。在第7节中,我们讨论了针对meltdown的软硬件对策。软件解决方案主要是KAISER机制,此外,我们也提出了硬件解决方案的建议。在第8节中,我们将讨论相关工作,并在第9节给出我们的结论。
2.背景介绍(Background)
In this section, we provide background on out-of-order execution, address translation, and cache attacks.
这一小节,我们将描述乱序执行、地址翻译和缓存攻击的一些基本背景知识。
2.1乱序执行(Out-of-order execution)
Out-of-order execution is an optimization technique that allows to maximize the utilization of all execution units of a CPU core as exhaustive as possible. Instead of processing instructions strictly in the sequential program order, the CPU executes them as soon as all required resources are available. While the execution unit of the current operation is occupied, other execution units can run ahead. Hence, instructions can be run in parallel as long as their results follow the architectural definition.
乱序执行是一种优化技术,通过该技术可以尽最大可能的利用CPU core中的执行单元。和顺序执行的CPU不同,支持乱序执行的CPU可以不按照program order来执行代码,只要指令执行的资源是OK的(没有被占用),那么就进入执行单元执行。如果当前指令涉及的执行单元被占用了,那么其他指令可以提前运行(如果该指令涉及的执行单元是空闲的话)。因此,在乱序执行下,只要结果符合体系结构定义,指令可以并行运行。
In practice, CPUs supporting out-of-order execution support running operations speculatively to the extent that the processor’s out-of-order logic processes instructions before the CPU is certain whether the instruction will be needed and committed. In this paper, we refer to speculative execution in a more restricted meaning, where it refers to an instruction sequence following a branch, and use the term out-of-order execution to refer to any way of getting an operation executed before the processor has committed the results of all prior instructions.
在实际中,CPU的乱序执行和推测执行(speculative execution)捆绑在一起的。在CPU无法确定下一条指令是否一定需要执行的时候往往会进行预测,并根据预测的结果来完成乱序执行。在本文中,speculative execution被认为是一个受限的概念,它特指跳转指令之后的指令序列的执行。而乱序执行这个术语是指处理器在提交所有前面指令操作结果之前,就已经提前执行了当前指令。
In 1967, Tomasulo [33] developed an algorithm [33] that enabled dynamic scheduling of instructions to allow out-of-order execution. Tomasulo [33] introduced a unified reservation station that allows a CPU to use a data value as it has been computed instead of storing it to a register and re-reading it. The reservation station renames registers to allow instructions that operate on the same physical registers to use the last logical one to solve read-after-write (RAW), write-after-read (WAR) and write-after-write (WAW) hazards. Furthermore, the reservation unit connects all execution units via a common data bus (CDB). If an operand is not available, the reservation unit can listen on the CDB until it is available and then directly begin the execution of the instruction.
1967,Tomasulo设计了一种算法[ 33 ] [ 33 ],实现了指令的动态调度,从而允许了乱序执行。Tomasulo [ 33 ]为CPU执行单元设计了统一的保留站(reservation station)。在过去,CPU执行单元需要从寄存器中读出操作数或者把结果写入寄存器,现在,有了保留站,CPU的执行单元可以使用它来读取操作数并且保存操作结果。我们给出一个具体的RAW(read-after-write)的例子:
R2 <- R1 + R3
R4 <- R2 + R3
第一条指令是计算R1+R3并把结果保存到R2,第二条指令依赖于R2的值进行计算。在没有保留站的时候,第一条指令的操作结果提交到R2寄存器之后,第二条指令才可以执行,因为需要从R2寄存器中加载操作数。如果有了保留站,那么我们可以在保留站中重命名寄存器R2,我们称这个寄存器是R2.rename。这时候,第一条指令执行之后就把结果保存在R2.rename寄存器中,而不需要把最终结果提交到R2寄存器中,这样第二条指令就可以直接从R2.rename寄存器中获取操作数并执行,从而解决了RAW带来的hazard。WAR和WAW类似,不再赘述。(注:上面这一句的翻译我自己做了一些扩展,方便理解保留站)。此外,保留站和所有的执行单元通过一个统一的CDB(common data bus)相连。如果操作数尚未准备好,那么执行单元可以监听CDB,一旦获取到操作数,该执行单元会立刻开始指令的执行。
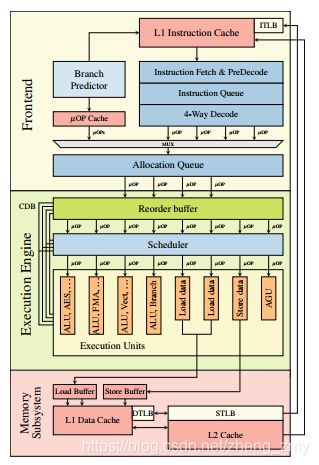
Figure 1: Simplified illustration of a single core of the Intel’s Skylake microarchitecture. Instructions are decoded into uOPs and executed out-of-order in the execution engine by individual execution units.
[图1 Intel的Skylake微体系结构单核的简化示意图,指令已经解码成uOPs,并在执行引擎中由单个执行单元乱序执行]
On the Intel architecture, the pipeline consists of the front-end, the execution engine (back-end) and the memory subsystem [14]. x86 instructions are fetched by the front-end from the memory and decoded to microoperations (μOPs) which are continuously sent to the execution engine. Out-of-order execution is implemented within the execution engine as illustrated in Figure 1. The Reorder Buffer is responsible for register allocation, register renaming and retiring. Additionally, other optimizations like move elimination or the recognition of zeroing idioms are directly handled by the reorder buffer. The μOPs are forwarded to the Unified Reservation Station that queues the operations on exit ports that are connected to Execution Units. Each execution unit can perform different tasks like ALU operations, AES operations, address generation units (AGU) or memory loads and stores. AGUs as well as load and store execution units are directly connected to the memory subsystem to process its requests.
在英特尔CPU体系结构中,流水线是由前端、执行引擎(后端)和内存子系统组成[14]。前端模块将x86指令从存储器中读取出来并解码成微操作(μOPS,microoperations),uOPS随后被发送给执行引擎。在执行引擎中实现了乱序执行,如上图所示。重新排序缓冲区(Reorder Buffer)负责寄存器分配、寄存器重命名和将结果提交到软件可见的寄存器(这个过程也称为retirement)。此外,reorder buffer还有一些其他的功能,例如move elimination 、识别zeroing idioms等。uOPS被发送到统一保留站中,并在该保留站的输出端口上进行排队,而保留站的输出端口则直接连接到执行单元。每个执行单元可以执行不同的任务,如ALU运算,AES操作,地址生成单元(AGU)、memory load和memory store。AGU、memory load和memory store这三个执行单元会直接连接到存储子系统中以便处理内存请求。
Since CPUs usually do not run linear instruction streams, they have branch prediction units that are used to obtain an educated guess of which instruction will be executed next. Branch predictors try to determine which direction of a branch will be taken before its condition is actually evaluated. Instructions that lie on that path and do not have any dependencies can be executed in advance and their results immediately used if the prediction was correct. If the prediction was incorrect, the reorder buffer allows to rollback by clearing the reorder buffer and re-initializing the unified reservation station.
由于CPU并非总是运行线性指令流,所以它有分支预测单元。该单元可以记录过去程序跳转的结果并用它来推测下一条可能被执行的指令。分支预测单元会在实际条件被检查之前确定程序跳转路径。如果位于该路径上的指令没有任何依赖关系,那么这些指令可以提前执行。如果预测正确,指令执行的结果可以立即使用。如果预测不正确,reorder buffer可以回滚操作结果,而具体的回滚是通过清除重新排序缓冲区和初始化统一保留站来完成的。
Various approaches to predict the branch exist: With static branch prediction [12], the outcome of the branch is solely based on the instruction itself. Dynamic branch prediction [2] gathers statistics at run-time to predict the outcome. One-level branch prediction uses a 1-bit or 2-bit counter to record the last outcome of the branch [21]. Modern processors often use two-level adaptive predictors [36] that remember the history of the last n outcomes allow to predict regularly recurring patterns. More recently, ideas to use neural branch prediction [34, 18, 32] have been picked up and integrated into CPU architectures [3].
分支预测有各种各样的方法:使用静态分支预测[ 12 ] 的时候,程序跳转的结果完全基于指令本身。动态分支预测[ 2 ] 则是在运行时收集统计数据来预测结果。一级分支预测使用1位或2位计数器来记录跳转结果[ 21 ]。现代处理器通常使用两级自适应预测器[36],这种方法会记住最后n个历史跳转结果,并通过这些历史跳转记过来寻找有规律的跳转模式。最近,使用神经分支预测[ 34, 18, 32 ]的想法被重新拾起并集成到CPU体系结构中[ 3 ]。
2.2地址空间(address space)
To isolate processes from each other, CPUs support virtual address spaces where virtual addresses are translated to physical addresses. A virtual address space is divided into a set of pages that can be individually mapped to physical memory through a multi-level page translation table. The translation tables define the actual virtual to physical mapping and also protection properties that are used to enforce privilege checks, such as readable, writable, executable and user-accessible. The currently used translation table that is held in a special CPU register. On each context switch, the operating system updates this register with the next process’ translation table address in order to implement per process virtual address spaces. Because of that, each process can only reference data that belongs to its own virtual address space. Each virtual address space itself is split into a user and a kernel part. While the user address space can be accessed by the running application, the kernel address space can only be accessed if the CPU is running in privileged mode. This is enforced by the operating system disabling the user accessible property of the corresponding translation tables. The kernel address space does not only have memory mapped for the kernel’s own usage, but it also needs to perform operations on user pages, e.g., filling them with data. Consequently, the entire physical memory is typically mapped in the kernel. On Linux and OS X, this is done via a direct-physical map, i.e., the entire physical memory is directly mapped to a pre-defined virtual address (cf. Figure 2).
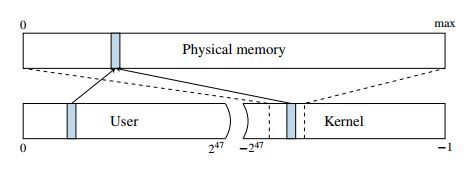
为了相互隔离进程,CPU支持虚拟地址空间,但是CPU向总线发出的是物理地址,因此程序中的虚拟地址需要被转换为物理地址。虚拟地址空间被划分成一个个的页面,这些页面又可以通过多级页表映射到物理页面。除了虚拟地址到物理地址的映射,页表也定义了保护属性,如可读的、可写的、可执行的和用户态是否可访问等。当前使用页表保存在一个特殊的CPU寄存器中(对于X86,这个寄存器就是cr3,对于ARM,这个寄存器是TTBR系列寄存器)。在上下文切换中,操作系统总是会用下一个进程的页表地址来更新这个寄存器,从而实现了进程虚拟地址空间的切换。因此,每个进程只能访问属于自己虚拟地址空间的数据。每个进程的虚拟地址空间本身被分成用户地址空间和内核地址空间部分。当进程运行在用户态的时候只可以访问用户地址空间,只有在内核态下(CPU运行在特权模式),才可以访问内核地址空间。操作系统会disable内核地址空间对应页表中的用户是否可访问属性,从而禁止了用户态对内核空间的访问。内核地址空间不仅为自身建立内存映射(例如内核的正文段,数据段等),而且还需要对用户页面进行操作,例如填充数据。因此,整个系统中的物理内存通常会映射在内核地址空间中。在Linux和OS X上,这是通过直接映射(direct-physical map)完成的,也就是说,整个物理内存直接映射到预定义的虚拟地址(参见上图)。
Instead of a direct-physical map, Windows maintains a multiple so-called paged pools, non-paged pools, and the system cache. These pools are virtual memory regions in the kernel address space mapping physical pages to virtual addresses which are either required to remain in the memory (non-paged pool) or can be removed from the memory because a copy is already stored on the disk (paged pool). The system cache further contains mappings of all file-backed pages. Combined, these memory pools will typically map a large fraction of the physical memory into the kernel address space of every process.
Windows中的地址映射机制,没有兴趣了解。
The exploitation of memory corruption bugs often requires the knowledge of addresses of specific data. In order to impede such attacks, address space layout randomization (ASLR) has been introduced as well as nonexecutable stacks and stack canaries. In order to protect the kernel, KASLR randomizes the offsets where drivers are located on every boot, making attacks harder as they now require to guess the location of kernel data structures. However, side-channel attacks allow to detect the exact location of kernel data structures [9, 13, 17] or derandomize ASLR in JavaScript [6]. A combination of a software bug and the knowledge of these addresses can lead to privileged code execution.
利用memory corruption(指修改内存的内容而造成crash)bug进行攻击往往需要知道特定数据的地址(因为我们需要修改该地址中的数据)。为了阻止这种攻击,内核提供了地址空间布局随机化(ASLR)、非执行堆栈和堆栈溢出检查三种手段。为了保护内核,KASLR会在驱动每次开机加载的时候将其放置在一个随机偏移的位置,这种方法使得攻击变得更加困难,因为攻击者需要猜测内核数据结构的地址信息。然而,攻击者可以利用侧信道攻击手段获取内核数据结构的确定位置[ 9, 13, 17 ]或者在JavaScript中对ASLR 解随机化[ 6 ]。结合本节描述的两种机制,我们可以发起攻击,实现特权代码的执行。
2.3缓存攻击(Cache Attacks)
In order to speed-up memory accesses and address translation, the CPU contains small memory buffers, called caches, that store frequently used data. CPU caches hide slow memory access latencies by buffering frequently used data in smaller and faster internal memory. Modern CPUs have multiple levels of caches that are either private to its cores or shared among them. Address space translation tables are also stored in memory and are also cached in the regular caches.
为了加速内存访问和地址翻译过程,CPU内部包含了一些小的内存缓冲区,我们称之为cache,用来保存近期频繁使用的数据,这样,CPU cache实际上是隐藏了底层慢速内存的访问延迟。现代CPU有多个层次的cache,它们要么是属于特定CPU core的,要么是在多个CPU core中共享的。地址空间的页表存储在内存中,它也被缓存在cache中(即TLB)。
Cache side-channel attacks exploit timing differences that are introduced by the caches. Different cache attack techniques have been proposed and demonstrated in the past, including Evict+Time [28], Prime+Probe [28, 29], and Flush+Reload [35]. Flush+Reload attacks work on a single cache line granularity. These attacks exploit the shared, inclusive last-level cache. An attacker frequently flushes a targeted memory location using the clflush instruction. By measuring the time it takes to reload the data, the attacker determines whether data was loaded into the cache by another process in the meantime. The Flush+Reload attack has been used for attacks on various computations, e.g., cryptographic algorithms [35, 16, 1], web server function calls [37], user input [11, 23, 31], and kernel addressing information [9].
缓存侧信道攻击(Cache side-channel attack)是一种利用缓存引入的时间差异而进行攻击的方法,在访问memory的时候,已经被cache的数据访问会非常快,而没有被cache的数据访问比较慢,缓存侧信道攻击就是利用了这个时间差来偷取数据的。各种各样的缓存攻击技术已经被提出并证明有效,包括Evict+Time [ 28 ],Prime+Probe [ 28, 29 ],Flush+Reload [ 35 ]。Flush+Reload方法在单个缓存行粒度上工作。缓存侧信道攻击主要是利用共享的cache(包含的最后一级缓存)进行攻击。攻击者经常使用CLFLUSH指令将目标内存位置的cache刷掉。然后读目标内存的数据并测量目标内存中数据加载所需的时间。通过这个时间信息,攻击者可以获取另一个进程是否已经将数据加载到缓存中。Flush+Reload攻击已被用于攻击各种算法,例如,密码算法[ 35, 16, 1 ],Web服务器函数调用[ 37 ],用户输入[ 11, 23, 31 ],以及内核寻址信息[ 9 ]。
A special use case are covert channels. Here the attacker controls both, the part that induces the side effect, and the part that measures the side effect. This can be used to leak information from one security domain to another, while bypassing any boundaries existing on the architectural level or above. Both Prime+Probe and Flush+Reload have been used in high-performance covert channels [24, 26, 10].
缓存侧信道攻击一个特殊的使用场景是构建隐蔽通道(covert channel)。在这个场景中,攻击者控制隐蔽通道的发送端和接收端,也就是说攻击者会通过程序触发产生cache side effect,同时他也会去量测这个cache side effect。通过这样的手段,信息可以绕过体系结构级别的边界检查,从一个安全域泄漏到外面的世界,。Prime+Probe 和 Flush+Reload这两种方法都已被用于构建高性能隐蔽通道[ 24, 26, 10 ]。
3.简单示例(A toy example)
In this section, we start with a toy example, a simple code snippet, to illustrate that out-of-order execution can change the microarchitectural state in a way that leaks information. However, despite its simplicity, it is used as a basis for Section 4 and Section 5, where we show how this change in state can be exploited for an attack.
在这一章中,我们给出一个简单的例子,并说明了在乱序执行的CPU上执行示例代码是如何改变CPU的微架构状态并泄露信息的。尽管它很简单,不过仍然可以作为第4章和第5章的基础(在这些章节中,我们会具体展示meltdown攻击)。
Listing 1 shows a simple code snippet first raising an (unhandled) exception and then accessing an array. The property of an exception is that the control flow does not continue with the code after the exception, but jumps to an exception handler in the operating system. Regardless of whether this exception is raised due to a memory access, e.g., by accessing an invalid address, or due to any other CPU exception, e.g., a division by zero, the control flow continues in the kernel and not with the next user space instruction.

上面的列表显示了一个简单的代码片段:首先触发一个异常(我们并不处理它),然后访问probe_array数组。异常会导致控制流不会执行异常之后的代码,而是跳转到操作系统中的异常处理程序去执行。不管这个异常是由于内存访问而引起的(例如访问无效地址),或者是由于其他类型的CPU异常(例如除零),控制流都会转到内核中继续执行,而不是停留在用户空间,执行对probe_array数组的访问。
Thus, our toy example cannot access the array in theory, as the exception immediately traps to the kernel and terminates the application. However, due to the out-of-order execution, the CPU might have already executed the following instructions as there is no dependency on the exception. This is illustrated in Figure 3. Due to the exception, the instructions executed out of order are not retired and, thus, never have architectural effects.
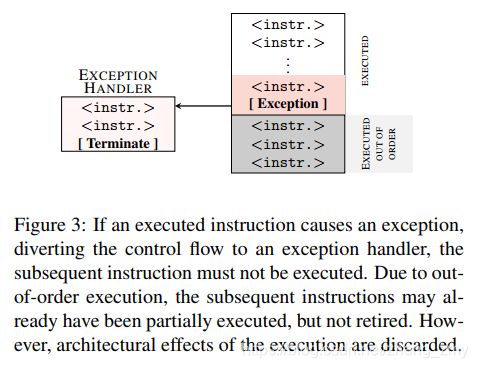
因此,我们给出的示例代码在理论上不会访问probe_array数组,毕竟异常会立即陷入内核并终止了该应用程序。但是由于乱序执行,CPU可能已经执行了异常指令后面的那些指令,要知道异常指令和随后的指令没有依赖性。如上图所示。虽然异常指令后面的那些指令被执行了,但是由于产生了异常,那些指令并没有提交(注:instruction retire,instruction commit都是一个意思,就是指将指令执行结果体现到软件可见的寄存器或者memory中,不过retire这个术语翻译成中文容易引起误会,因此本文统一把retire翻译为提交或者不翻译),因此从CPU 体系结构角度看没有任何问题(也就是说软件工程师从ISA的角度看不到这些指令的执行)。
Although the instructions executed out of order do not have any visible architectural effect on registers or memory, they have microarchitectural side effects. During the out-of-order execution, the referenced memory is fetched into a register and is also stored in the cache. If the out-of-order execution has to be discarded, the register and memory contents are never committed. Nevertheless, the cached memory contents are kept in the cache. We can leverage a microarchitectural side-channel attack such as Flush+Reload [35], which detects whether a specific memory location is cached, to make this microarchitectural state visible. There are other side channels as well which also detect whether a specific memory location is cached, including Prime+Probe [28, 24, 26], Evict+ Reload [23], or Flush+Flush [10]. However, as Flush+ Reload is the most accurate known cache side channel and is simple to implement, we do not consider any other side channel for this example.
虽然违反了program order,在CPU上执行了本不应该执行的指令,但是实际上从寄存器和memory上看,我们不能捕获到任何这些指令产生的变化(也就是说没有architecture effect)。不过,从CPU微架构的角度看确实是有副作用。在乱序执行过程中,加载内存值到寄存器同时也会把该值保存在cache中。如果必须要丢弃掉乱序执行的结果,那么寄存器和内存值都不会commit。但是,cache中的内容并没有丢弃,仍然在cache中。这时候,我们就可以使用微架构侧信道攻击(microarchitectural side-channel attack)的方法,例如Flush+Reload [35],来检测是否指定的内存地址被cache了,从而让这些微架构状态信息变得对用户可见。我们也有其他的方法来检测内存地址是否被缓存,包括:Prime+Probe [28, 24, 26], Evict+ Reload [23], 或者Flush+Flush [10]。不过Flush+ Reload是最准确的感知cache side channel的方法,并且实现起来非常简单,因此在本文中我们主要介绍Flush+ Reload。
Based on the value of data in this toy example, a different part of the cache is accessed when executing the memory access out of order. As data is multiplied by 4096, data accesses to probe array are scattered over the array with a distance of 4 kB (assuming an 1 B data type for probe array). Thus, there is an injective mapping from the value of data to a memory page, i.e., there are no two different values of data which result in an access to the same page. Consequently, if a cache line of a page is cached, we know the value of data. The spreading over different pages eliminates false positives due to the prefetcher, as the prefetcher cannot access data across page boundaries [14].
我们再次回到上面列表中的示例代码。probe_array是一个按照4KB字节组织的数组,变化data变量的值就可以按照4K size来遍历访问该数组。如果在乱序执行中访问了data变量指定的probe_array数组内的某个4K内存块,那么对应页面(指的是probe_array数组内的4K内存块)的数据就会被加载到cache中。因此,通过程序扫描probe_array数组中各个页面的cache情况可以反推出data的数值(data数值和probe_array数组中的页面是一一对应的)。在Intel处理器中,prefetcher不会跨越page的边界,因此page size之间的cache状态是完全独立的。而在程序中把cache的检测分散到若干个page上主要是为了防止prefetcher带来的误报。
Figure 4 shows the result of a Flush+Reload measurement iterating over all pages, after executing the out-oforder snippet with data = 84. Although the array access should not have happened due to the exception, we can clearly see that the index which would have been accessed is cached. Iterating over all pages (e.g., in the exception handler) shows only a cache hit for page 84 This shows that even instructions which are never actually executed, change the microarchitectural state of the CPU. Section 4 modifies this toy example to not read a value, but to leak an inaccessible secret.

上图是通过Flush+Reload 方法遍历probe_array数组中的各个page并计算该page数据的访问时间而绘制的坐标图。横坐标是page index,共计256个,纵坐标是访问时间,如果cache miss,那么访问时间大概是400多个cycle,如果cache hit,访问时间大概是200个cycle以下,二者有显著的区别。从上图我们可以看出,虽然由于异常,probe_array数组访问不应该发生,不过在data=84上明显是cache hit的,这也说明了在乱序执行下,本不该执行的指令也会影响CPU微架构状态,在下面的章节中,我们将修改示例代码,去窃取秘密数据。
4.Meltdown攻击架构图(Building block of attack)
The toy example in Section 3 illustrated that side-effects of out-of-order execution can modify the microarchitectural state to leak information. While the code snippet reveals the data value passed to a cache-side channel, we want to show how this technique can be leveraged to leak otherwise inaccessible secrets. In this section, we want to generalize and discuss the necessary building blocks to exploit out-of-order execution for an attack.
上一章中我们通过简单的示例代码展示了乱序执行的副作用会修改微架构状态,从而造成信息泄露。通过代码片段我们已经看到了data变量值已经传递到缓存侧通道上,下面我们会详述如何利用这种技术来泄漏受保护的数据。在本章中,我们将概括并讨论利用乱序执行进行攻击所需要的组件。
The adversary targets a secret value that is kept somewhere in physical memory. Note that register contents are also stored in memory upon context switches, i.e., they are also stored in physical memory. As described in Section 2.2, the address space of every process typically includes the entire user space, as well as the entire kernel space, which typically also has all physical memory (inuse) mapped. However, these memory regions are only accessible in privileged mode (cf. Section 2.2).
攻击者的目标是保存在物理内存中的一个秘密值。注意:寄存器值也会在上下文切换时保存在物理内存中。根据2.2节所述,每个进程的地址空间通常包括整个用户地址空间以及整个内核地址空间(使用中的物理内存都会映射到该空间中),虽然进程能感知到内核空间的映射。但是这些内存区域只能在特权模式下访问(参见第2.2节)。
In this work, we demonstrate leaking secrets by bypassing the privileged-mode isolation, giving an attacker full read access to the entire kernel space including any physical memory mapped, including the physical memory of any other process and the kernel. Note that Kocher et al. [19] pursue an orthogonal approach, called Spectre Attacks, which trick speculative executed instructions into leaking information that the victim process is authorized to access. As a result, Spectre Attacks lack the privilege escalation aspect of Meltdown and require tailoring to the victim process’s software environment, but apply more broadly to CPUs that support speculative execution and are not stopped by KAISER.
在这项工作中,我们绕过了地址空间隔离机制,让攻击者可以对整个内核空间进行完整的读访问,这里面就包括物理内存直接映射部分。而通过直接映射,攻击者可以访问任何其他进程和内核的物理内存。注意:Kocher等人[ 19 ]正在研究一种称为幽灵(spectre)攻击的方法,它通过推测执行(speculative execution)来泄漏目标进程的秘密信息。因此,幽灵攻击不涉及Meltdown攻击中的特权提升,并且需要根据目标进程的软件环境进行定制。不过spectre会影响更多的CPU(只要支持speculative execution的CPU都会受影响),另外,KAISER无法阻挡spectre攻击。
The full Meltdown attack consists of two building blocks, as illustrated in Figure 5. The first building block of Meltdown is to make the CPU execute one or more instructions that would never occur in the executed path. In the toy example (cf. Section 3), this is an access to an array, which would normally never be executed, as the previous instruction always raises an exception. We call such an instruction, which is executed out of order, leaving measurable side effects, a transient instruction. Furthermore, we call any sequence of instructions containing at least one transient instruction a transient instruction sequence.

完整的meltdown攻击由两个组件构成,如上图所示。第一个组件是使CPU执行一个或多个在正常路径中永远不会执行的指令。在第三章中的简单示例代码中,对数组的访问指令按理说是不会执行,因为前面的指令总是触发异常。我们称这种指令为瞬态指令(transient instruction),瞬态指令在乱序执行的时候被CPU执行(正常情况下不会执行),留下可测量的副作用。此外,我们把任何包含至少一个瞬态指令的指令序列称为瞬态指令序列。
In order to leverage transient instructions for an attack, the transient instruction sequence must utilize a secret value that an attacker wants to leak. Section 4.1 describes building blocks to run a transient instruction sequence with a dependency on a secret value.
为了使用瞬态指令来完成攻击,瞬态指令序列必须访问攻击者想要获取的秘密值并加以利用。第4.1节将描述一段瞬态指令序列,我们会仔细看看这段指令会如何使用受保护的数据。
The second building block of Meltdown is to transfer the microarchitectural side effect of the transient instruction sequence to an architectural state to further process the leaked secret. Thus, the second building described in Section 4.2 describes building blocks to transfer a microarchitectural side effect to an architectural state using a covert channel.
Meltdown的第二个组件主要用来检测在瞬态指令序列执行完毕之后,在CPU微架构上产生的side effect。并将其转换成软件可以感知的CPU体系结构的状态,从而将数据泄露出来。因此,在4.2节中描述的第二个组件主要是使用隐蔽信道来把CPU微架构的副作用转换成CPU architectural state。
4.1执行瞬态指令(executing transient instructions)
The first building block of Meltdown is the execution of transient instructions. Transient instructions basically occur all the time, as the CPU continuously runs ahead of the current instruction to minimize the experienced latency and thus maximize the performance (cf. Section 2.1). Transient instructions introduce an exploitable side channel if their operation depends on a secret value. We focus on addresses that are mapped within the attacker’s process, i.e., the user-accessible user space addresses as well as the user-inaccessible kernel space addresses. Note that attacks targeting code that is executed
within the context (i.e., address space) of another process are possible [19], but out of scope in this work, since all physical memory (including the memory of other processes) can be read through the kernel address space anyway.
Meltdown的第一个组件是执行瞬态指令。其实瞬态指令是时时刻刻都在发生的,因为CPU在执行当前指令之外,往往会提前执行当前指令之后的那些指令,从而最大限度地提高CPU性能(参见第2.1节的描述)。如果瞬态指令的执行依赖于一个受保护的值,那么它就引入一个可利用的侧信道。另外需要说明的是:本文主要精力放在攻击者的进程地址空间中,也就是说攻击者在用户态访问内核地址空间的受保护的数据。实际上攻击者进程访问盗取其他进程地址空间的数据也是可能的(不过本文并不描述这个场景),毕竟攻击者进程可以通过内核地址空间访问系统中所有内存,而其他进程的数据也就是保存在系统物理内存的某个地址上。
Accessing user-inaccessible pages, such as kernel pages, triggers an exception which generally terminates the application. If the attacker targets a secret at a user inaccessible address, the attacker has to cope with this exception. We propose two approaches: With exception handling, we catch the exception effectively occurring after executing the transient instruction sequence, and with exception suppression, we prevent the exception from occurring at all and instead redirect the control flow after executing the transient instruction sequence. We discuss these approaches in detail in the following.
运行于用户态时访问特权页面,例如内核页面,会触发一个异常,该异常通常终止应用程序。如果攻击者的目标是一个内核空间地址中保存的数据,那么攻击者必须处理这个异常。我们提出两种方法:一种方法是设置异常处理函数,在发生异常的时候会调用该函数(这时候已经完成了瞬态指令序列的执行)。第二种方法是抑制异常的触发,下面我们将详细讨论这些方法。
Exception handling. A trivial approach is to fork the attacking application before accessing the invalid memory location that terminates the process, and only access the invalid memory location in the child process. The CPU executes the transient instruction sequence in the child process before crashing. The parent process can then recover the secret by observing the microarchitectural state, e.g., through a side-channel.
程序自己定义异常处理函数。
一个简单的方法是在访问内核地址(这个操作会触发异常并中止程序的执行)之前进行fork的操作,并只在子进程中访问内核地址,触发异常。在子进程crash之前,CPU已经执行了瞬态指令序列。在父进程中可以通过观察CPU微架构状态来盗取内核空间的数据。
It is also possible to install a signal handler that will be executed if a certain exception occurs, in this specific case a segmentation fault. This allows the attacker to issue the instruction sequence and prevent the application from crashing, reducing the overhead as no new process has to be created.
当然,你也可以设置信号处理函数。异常触发后将执行该信号处理函数(在这个场景下,异常是segmentation fault)。这种方法的好处是应用程序不会crash,不需要创建新进程,开销比较小。
Exception suppression.
这种方法和Transactional memory相关,有兴趣的同学可以自行阅读原文。
4.2构建隐蔽通道(building covert channel)
The second building block of Meltdown is the transfer of the microarchitectural state, which was changed by the transient instruction sequence, into an architectural state (cf. Figure 5). The transient instruction sequence can be seen as the sending end of a microarchitectural covert channel. The receiving end of the covert channel receives the microarchitectural state change and deduces the secret from the state. Note that the receiver is not part of the transient instruction sequence and can be a different thread or even a different process e.g., the parent process in the fork-and-crash approach.
第二个Meltdown组件主要是用来把执行瞬态指令序列后CPU微架构状态变化的信息转换成相应的体系结构状态(参考上图)。瞬态指令序列可以认为是微架构隐蔽通道的发端,通道的接收端用来接收微架构状态的变化信息,从这些状态变化中推导出被保护的数据。需要注意的是:接收端并不是瞬态指令序列的一部分,可以来自其他的线程甚至是其他的进程。例如上节我们使用fork的那个例子中,瞬态指令序列在子进程中,而接收端位于父进程中
We leverage techniques from cache attacks, as the cache state is a microarchitectural state which can be reliably transferred into an architectural state using various techniques [28, 35, 10]. Specifically, we use Flush+Reload [35], as it allows to build a fast and low-noise covert channel. Thus, depending on the secret value, the transient instruction sequence (cf. Section 4.1) performs a regular memory access, e.g., as it does in the toy example (cf. Section 3).
我们可以利用缓存攻击(cache attack)技术,通过对高速缓存的状态(是微架构状态之一)的检测,我们可以使用各种技术[ 28, 35, 10 ]将其稳定地转换成CPU体系结构状态。具体来说,我们可以使用Flush+Reload技术 [35],因为该技术允许建立一个快速的、低噪声的隐蔽通道。然后根据保密数据,瞬态指令序列(参见第4.1节)执行常规的存储器访问,具体可以参考在第3节给出的那个简单示例程序中所做的那样。
After the transient instruction sequence accessed an accessible address, i.e., this is the sender of the covert channel; the address is cached for subsequent accesses. The receiver can then monitor whether the address has been loaded into the cache by measuring the access time to the address. Thus, the sender can transmit a ‘1’-bit by accessing an address which is loaded into the monitored cache, and a ‘0’-bit by not accessing such an address.
在隐蔽通道的发送端,瞬态指令序列会访问一个普通内存地址,从而导致该地址的数据被加载到了cache(为了加速后续访问)。然后,接收端可以通过测量内存地址的访问时间来监视数据是否已加载到缓存中。因此,发送端可以通过访问内存地址(会加载到cache中)传递bit 1的信息,或者通过不访问内存地址(不会加载到cache中)来发送bit 0信息。而接收端可以通过监视cache的信息来接收这个bit 0或者bit 1的信息。
Using multiple different cache lines, as in our toy example in Section 3, allows to transmit multiple bits at once. For every of the 256 different byte values, the sender accesses a different cache line. By performing a Flush+Reload attack on all of the 256 possible cache lines, the receiver can recover a full byte instead of just one bit. However, since the Flush+Reload attack takes much longer (typically several hundred cycles) than the transient instruction sequence, transmitting only a single bit at once is more efficient. The attacker can simply do that by shifting and masking the secret value accordingly.
使用一个cacheline可以传递一个bit,如果使用多个不同的cacheline(类似我们在第3章中的简单示例代码一样),就可以同时传输多个比特。一个Byte(8-bit)有256个不同的值,针对每一个值,发送端都会访问不同的缓存行,这样通过对所有256个可能的缓存行进行Flush+Reload攻击,接收端可以恢复一个完整字节而不是一个bit。不过,由于Flush+Reload攻击所花费的时间比执行瞬态指令序列要长得多(通常是几百个cycle),所以只传输一个bit是更有效的。攻击者可以通过shift和mask来完成保密数据逐个bit的盗取。
Note that the covert channel is not limited to microarchitectural states which rely on the cache. Any microarchitectural state which can be influenced by an instruction (sequence) and is observable through a side channel can be used to build the sending end of a covert channel. The sender could, for example, issue an instruction (sequence) which occupies a certain execution port such as the ALU to send a ‘1’-bit. The receiver measures the latency when executing an instruction (sequence) on the same execution port. A high latency implies that the sender sends a ‘1’-bit, whereas a low latency implies that sender sends a ‘0’-bit. The advantage of the Flush+ Reload cache covert channel is the noise resistance and the high transmission rate [10]. Furthermore, the leakage can be observed from any CPU core [35], i.e., rescheduling events do not significantly affect the covert channel.
需要注意的是:隐蔽信道并非总是依赖于缓存。只要CPU微架构状态会被瞬态指令序列影响,并且可以通过side channel观察这个状态的改变,那么该微架构状态就可以用来构建隐蔽通道的发送端。例如,发送端可以执行一条指令(该指令会占用相关执行单元(如ALU)的端口),来发送一个“1”这个bit。接收端可以在同一个执行单元端口上执行指令,同时测量时间延迟。高延迟意味着发送方发送一个“1”位,而低延迟意味着发送方发送一个“0”位。Flush+ Reload隐蔽通道的优点是抗噪声和高传输速率[ 10 ]。此外,我们可以从任何cpu core上观察到数据泄漏[ 35 ],即调度事件并不会显著影响隐蔽信道。
5.熔断(Meltdown)
In this section, present Meltdown, a powerful attack allowing to read arbitrary physical memory from an unprivileged user program, comprised of the building blocks presented in Section 4. First, we discuss the attack setting to emphasize the wide applicability of this attack. Second, we present an attack overview, showing how Meltdown can be mounted on both Windows and Linux on personal computers as well as in the cloud. Finally, we discuss a concrete implementation of Meltdown allowing to dump kernel memory with up to 503KB/s.
在这一章我们将向您展示meltdown的威力:通过一个普通的用户程序读取系统中任意位置的物理内存。整个攻击过程的框架图已经在第4章描述。首先,我们讨论攻击设置,通过设置我们可以看出meltdown这种攻击具有非常广泛的适用性。其次,我们对meltdown攻击进行概述,并展示了它如何对安装Windows和Linux的个人计算机上以及云服务器展开攻击。最后,我们讨论了一个具体的实现,该Meltdown的实现允许以503kB/s的速度dump内核空间的内存。

Attack setting.
In our attack, we consider personal computers and virtual machines in the cloud. In the attack scenario, the attacker has arbitrary unprivileged code execution on the attacked system, i.e., the attacker can run any code with the privileges of a normal user. However, the attacker has no physical access to the machine. Further, we assume that the system is fully protected with state-of-the-art software-based defenses such as ASLR and KASLR as well as CPU features like SMAP, SMEP, NX, and PXN. Most importantly, we assume a completely bug-free operating system, thus, no software vulnerability exists that can be exploited to gain kernel privileges or leak information. The attacker targets secret user data, e.g., passwords and private keys, or any other valuable information.
攻击设定如下:
我们考虑个人计算机和云服务器上的虚拟机两种应用场景。在攻击过程中,攻击者只使用未授权的代码来攻击系统,也就是说攻击者只能以一个普通用户的权限来运行代码。另外,攻击者没有对机器进行物理访问。进一步,我们假设我们准备攻击的系统是已经有了非常好的基于软件的防御措施,例如ASLR和KASLR,同时CPU也包含了像SMAP,SMEP,NX,和PXN的功能。最重要的是,我们假设被攻击系统是一个完全无bug的操作系统,没有软件漏洞可以被利用来获得root权限或泄露信息。攻击者的目标是用户的秘密数据,例如密码和私钥,或任何其他有价值的信息。
5.1概述
Meltdown combines the two building blocks discussed in Section 4. First, an attacker makes the CPU execute a transient instruction sequence which uses an inaccessible secret value stored somewhere in physical memory (cf. Section 4.1). The transient instruction sequence acts as the transmitter of a covert channel (cf. Section 4.2), ultimately leaking the secret value to the attacker.
Meltdown使用了第4章中讨论攻击架构图。首先,攻击者让CPU执行一个瞬态指令序列,该指令序列会操作保存在物理内存中不可访问的秘密数据(参见第4.1节)。瞬态指令序列充当隐蔽通道的发送端(参见第4.2节),最终将秘密数据泄漏给攻击者。
Meltdown consists of 3 steps:
Step 1 The content of an attacker-chosen memory location,which is inaccessible to the attacker, is loaded into a register.
Step 2 A transient instruction accesses a cache line based on the secret content of the register.
Step 3 The attacker uses Flush+Reload to determine the accessed cache line and hence the secret stored at the chosen memory location.
By repeating these steps for different memory locations, the attacker can dump the kernel memory, including the entire physical memory.
Meltdown攻击包括3个步骤:
步骤1:攻击者访问秘密数据所在的内存位置(该内存是攻击者没有权限访问的),并加载到一个寄存器中。
步骤2,瞬态指令基于寄存器中保存的秘密数据内容访问cache line。
步骤3:攻击者使用Flush+Reload来确定在步骤2中访问的cache line,从而恢复在步骤1中读取的秘密数据。
在不同的内存地址上不断重复上面的步骤,攻击者可以dump整个内核地址空间的数据,这也就包括了整个物理内存。
Listing 2 shows the basic implementation of the transient instruction sequence and the sending part of the covert channel, using x86 assembly instructions. Note that this part of the attack could also be implemented entirely in higher level languages like C. In the following, we will discuss each step of Meltdown and the corresponding code line in Listing 2.
clip_image012
上面的列表显示了瞬态指令序列和隐蔽通道发送部分的基本实现(使用x86汇编指令)。需要注意的是:这部分攻击的代码也可以完全用C这样的高级语言来实现。在随后的文章中,我们会讨论列表中的每一行代码是如何完成meltdown攻击的。
Step 1: Reading the secret. To load data from the main memory into a register, the data in the main memory is referenced using a virtual address. In parallel to translating a virtual address into a physical address, the CPU also checks the permission bits of the virtual address, i.e., whether this virtual address is user accessible or only accessible by the kernel. As already discussed in Section 2.2, this hardware-based isolation through a permission bit is considered secure and recommended by the hardware vendors. Hence, modern operating systems always map the entire kernel into the virtual address space of every user process.
步骤1:读内存中的秘密数据。为了将数据从主存储器加载到寄存器中,我们使用虚拟地址来访问主存中的数据。在将虚拟地址转换为物理地址的同时,CPU还会检查虚拟地址的权限位:这个虚拟地址可否被用户态访问,还是只能在内核态中访问。正如在第2.2节中已经讨论过的那样,我们都认为这个基于硬件的地址空间隔离是安全的,并且硬件厂商也推荐使用这种隔离方法。因此,现代操作系统总是将整个内核地址空间映射到每个用户进程的虚拟地址空间。
As a consequence, all kernel addresses lead to a valid physical address when translating them, and the CPU can access the content of such addresses. The only difference to accessing a user space address is that the CPU raises an exception as the current permission level does not allow to access such an address. Hence, the user space cannot simply read the contents of such an address. However, Meltdown exploits the out-of-order execution of modern CPUs, which still executes instructions in the small time window between the illegal memory access and the raising of the exception.
访问内核地址空间的时候,只要创建了虚拟地址的映射(即可以通过页表翻译出一个有效的物理地址),CPU都可以访问这些地址的内容。和访问用户地址空间唯一不同是会进行权限检查,由于当前CPU权限级别不够而访问内核空间地址的时候会触发异常。因此,用户空间不能简单地通过读取内核地址的内容来获得秘密数据。然而,乱序执行的特性允许CPU在一个很小的时间窗口内(从执行了非法内存访问的指令到触发异常),仍然会继续执行指令。Meltdown就是利用了乱序执行的特性完成了攻击。
In line 4 of Listing 2, we load the byte value located at the target kernel address, stored in the RCX register, into the least significant byte of the RAX register represented by AL. As explained in more detail in Section 2.1, the MOV instruction is fetched by the core, decoded into μOPs, allocated, and sent to the reorder buffer. There, architectural registers (e.g., RAX and RCX in Listing 2) are mapped to underlying physical registers enabling out-of-order execution. Trying to utilize the pipeline as much as possible, subsequent instructions (lines 5-7) are already decoded and allocated as μOPs as well. The μOPs are further sent to the reservation station holding the μOPs while they wait to be executed by the corresponding execution unit. The execution of a μOP can be delayed if execution units are already used to their corresponding capacity or operand values have not been calculated yet.
在上面代码列表中的第4行,我们访问了位于内核地址空间的memory(地址保存在RCX寄存器),获取了一个字节的数据,保存在AL寄存器(即RAX寄存器的8个LSB比特)。根据2.1节中的描述,MOV指令由CPU core取指,解码成μOPS,分配并发送到重排序缓冲区。在那里,architectural register(软件可见的寄存器,例如RAX和RCX)会被映射成底层的物理寄存器以便实现乱序执行。为了尽可能地利用流水线,随后的指令(5-7的代码)已经解码并分配为uOPs。该uOPs会进一步送到保留站(暂存uOPs),在保留站中,uOPs会等待相应的执行单元空闲,如果执行单元准备好,该uOPs会立刻执行,如果执行单元已经达到了容量的上限(例如有3个加法器,那么可以同时进行3个加法运算,第四个加法uOPs就需要等待了)或uOPs操作数值尚未计算出来,uOPs则被延迟执行。
When the kernel address is loaded in line 4, it is likely that the CPU already issued the subsequent instructions as part of the out-or-order execution, and that their corresponding μOPs wait in the reservation station for the content of the kernel address to arrive. As soon as the fetched data is observed on the common data bus, the μOPs can begin their execution.
当在程序第4行加载内核地址到寄存器的时候,由于乱序执行,很可能CPU已经把后续指令发射出去,并且它们相应的μOPs会在保留站中等待内核地址的内容到来。一旦在公共数据总线上观察到所获取的内核地址数据,这些μOPs就会立刻开始执行。
When the μOPs finish their execution, they retire in order, and, thus, their results are committed to the architectural state. During the retirement, any interrupts and exception that occurred during the execution of the instruction are handled. Thus, if the MOV instruction that loads the kernel address is retired, the exception is registered and the pipeline is flushed to eliminate all results of subsequent instructions which were executed out of order. However, there is a race condition between raising this exception and our attack step 2 which we describe below.
当μOPs执行完毕后,它们就按顺序进行retire(这个术语叫做retire,很难翻译,这里就不翻译了,但是和commit是一个意思),因此,μOPs的结果会被提交并体现在体系结构状态上。在提交过程中,在执行指令期间发生的任何中断和异常都会被处理。因此,在提交MOV指令的时候发现该指令操作的是内核地址,这时候会触发异常。这时候CPU流水线会执行flush操作,由于乱序执行而提前执行的那些指令(Mov指令之后)结果会被清掉。然而,在触发这个异常和我们执行的攻击步骤2之间有一个竞争条件(race condition),我们在下面描述。
As reported by Gruss et al. [9], prefetching kernel addresses sometimes succeeds. We found that prefetching the kernel address can slightly improve the performance of the attack on some systems.
根据Gruss等人的研究[ 9 ],预取内核地址有时成功。我们发现:预取内核地址可以略微改善某些系统的攻击性能。
Step 2: Transmitting the secret. The instruction sequence from step 1 which is executed out of order has to be chosen in a way that it becomes a transient instruction sequence. If this transient instruction sequence is executed before the MOV instruction is retired (i.e., raises the exception), and the transient instruction sequence performed computations based on the secret, it can be utilized to transmit the secret to the attacker.
步骤2:传送秘密数据
在步骤1中乱序执行的指令序列能否成为瞬态指令序列是需要条件的。如果的确是瞬态指令序列,那么它必须要在MOV指令retirement之前被执行(即在触发异常之前),而且瞬态指令序列会基于秘密数据进行计算,而这个计算的副作用可以用来向攻击者传递秘密数据。
As already discussed, we utilize cache attacks that allow to build fast and low-noise covert channel using the CPU’s cache. Thus, the transient instruction sequence has to encode the secret into the microarchitectural cache state, similarly to the toy example in Section 3.
正如之前已经讨论过的,我们利用缓存攻击,即利用CPU的高速缓存建立快速和低噪声的隐蔽通道。然后,瞬态指令序列必须要把秘密数据编码在微架构缓存状态中。这个过程类似于第三节中的那个简单示例程序。
We allocate a probe array in memory and ensure that no part of this array is cached. To transmit the secret, the transient instruction sequence contains an indirect memory access to an address which is calculated based on the secret (inaccessible) value. In line 5 of Listing 2 the secret value from step 1 is multiplied by the page size, i.e., 4 KB. The multiplication of the secret ensures that accesses to the array have a large spatial distance to each other. This prevents the hardware prefetcher from loading adjacent memory locations into the cache as well. Here, we read a single byte at once, hence our probe array is 256×4096 bytes, assuming 4KB pages.
我们在内存中分配一个探测数组,并确保该数组的所有内存都没有被cached。为了传递秘密数据,瞬态指令序列包含对探测数组的间接内存访问,具体的访问地址是基于那个秘密数据的(该秘密数据是用户态不可访问的)。具体可以参考上面列表中的第5行代码:第1步获取的秘密数据会乘以页面大小,即4 KB(代码使用了移位操作,是一样的意思)。这个乘法操作确保了对数组的访问具有较大的空间距离。这可以防止硬件prefetcher把相邻存储单元的数据加载到缓存中。在这示例中,由于一次只读出一个字节,所以我们的探测数组是256×4096字节(假设页面大小是4KB)。
Note that in the out-of-order execution we have a noise-bias towards register value ‘0’. We discuss the reasons for this in Section 5.2. However, for this reason, we introduce a retry-logic into the transient instruction sequence. In case we read a ‘0’, we try to read the secret again (step 1). In line 7, the multiplied secret is added to the base address of the probe array, forming the target address of the covert channel. This address is read to cache the corresponding cache line. Consequently, our transient instruction sequence affects the cache state based on the secret value that was read in step 1.
注意:在乱序执行中,我们对寄存器值“0”有一个噪声偏置(noise-bias)。我们在第5.2节讨论了具体的原因。正是由于这个原因,我们在瞬态指令序列中引入了重试逻辑。如果我们读到了“0”值,我们试着重新读这个秘密数据(第1步)。在代码的第7行中,将秘密数据乘以4096并累加到探测数组的基地址中,从而形成隐蔽信道的目标地址。读取该目标地址可以将数据加载到对应的cacheline中。因此,瞬态指令序列根据第1步中读取的秘密数据修改了探测数组对应的缓存状态。
Since the transient instruction sequence in step 2 races against raising the exception, reducing the runtime of step 2 can significantly improve the performance of the attack. For instance, taking care that the address translation for the probe array is cached in the TLB increases the attack performance on some systems.
由于步骤2中的瞬态指令序列需要和异常的触发相竞争,因此减少步骤2的运行时间可以显著提高攻击的性能。例如:把探测数组的地址翻译预先缓存在TLB中。
Step 3: Receiving the secret. In step 3, the attacker recovers the secret value (step 1) by leveraging a microarchitectural side-channel attack (i.e., the receiving end of a microarchitectural covert channel) that transfers the cache state (step 2) back into an architectural state. As discussed in Section 4.2, Meltdown relies on Flush+Reload to transfer the cache state into an architectural state.
步骤3:接收秘密数据。
在步骤3中,攻击者利用微架构侧信道攻击(即微架构隐蔽信道的接收端)将cache state转换成了软件可以感知的体系结构状态(architectural state),从而恢复了秘密数据。正如第4.2节中所讨论的,meltdown依赖于Flush+Reload来将缓存状态转换为CPU体系结构状态。
When the transient instruction sequence of step 2 is executed, exactly one cache line of the probe array is cached. The position of the cached cache line within the probe array depends only on the secret which is read in step 1. Thus, the attacker iterates over all 256 pages of the probe array and measures the access time for every first cache line (i.e., offset) on the page. The number of the page containing the cached cache line corresponds directly to the secret value.
在步骤2中执行的瞬态指令序列时,整个探测数组只有一个页面的cacheline被加载了。具体加载的cacheline的在探测数组中的位置仅取决于步骤1中读取的秘密数据。因此,攻击者遍历所有探测数组中的256个页面,测试每个页面第一个cacheline的访问时间,已经预先加载了cacheline的那个page index就直接对应着秘密数据的数值。
Dumping the entire physical memory. By repeating all 3 steps of Meltdown, the attacker can dump the entire memory by iterating over all different addresses. However, as the memory access to the kernel address raises an exception that terminates the program, we use one of the methods described in Section 4.1 to handle or suppress the exception.
Dump整个物理内存:
通过重复上面的3个步骤,同时修改不同的攻击地址,攻击者可以dump所有内存。但是,由于对内核地址的内存访问引发了一个终止程序的异常,所以我们使用第4.1节中描述的方法来处理或抑制这个异常。
As all major operating systems also typically map the entire physical memory into the kernel address space (cf. Section 2.2) in every user process, Meltdown is not only limited to reading kernel memory but it is capable of reading the entire physical memory of the target machine.
在目前所有的主流操作系统中,我们通常会把整个物理内存映射到内核地址空间(参见第2.2节),而每个用户进程中又包括内核地址空间部分。因此Meltdown不仅能读取内核地址空间的内存值,而且能够读取整个系统的物理内存。
5.2优化和限制(optimizations and limitations)
The case of 0. If the exception is triggered while trying to read from an inaccessible kernel address, the register where the data should be stored, appears to be zeroed out. This is reasonable because if the exception is unhandled, the user space application is terminated, and the value from the inaccessible kernel address could be observed in the register contents stored in the core dump of the crashed process. The direct solution to fix this problem is to zero out the corresponding registers. If the zeroing out of the register is faster than the execution of the subsequent instruction (line 5 in Listing 2), the attacker may read a false value in the third step. To prevent the transient instruction sequence from continuing with a wrong value, i.e., ‘0’, Meltdown retries reading the address until it encounters a value different from ‘0’ (line 6). As the transient instruction sequence terminates after the exception is raised, there is no cache access if the secret value is 0. Thus, Meltdown assumes that the secret value is indeed ‘0’ if there is no cache hit at all.
读出数值是0的场景。
根据前面的描述,在instruction commit阶段,当检测到用户态访问内核地址的时候,除了触发异常,CPU还会清除指令的操作结果,也就是说AL寄存器会被清零。如果瞬态指令序列在和异常的竞争中失败了(寄存器清零早于上面程序列表中第五行代码执行),那么很可能从内核地址读出的并非其真是值,而是清零后的数值。对寄存器清零也是合理的,因为如果异常没有被处理,用户空间的应用程序会终止,该进程的core dump文件中会保留寄存器的内容,如果不清零,那么内核空间的数据可以通过core dump文件泄露出去。清零可以修正这个issue,保证内核空间数据的安全。为了防止瞬态指令序列继续操作错误的“0”值,Meltdown会重读地址直到读出非“0”值(第6行代码)。
你可能会问:如果秘密数据就是0怎么办?其实当异常触发后,瞬态指令序列终止执行,如果秘密数据确实等于0,则不存在任何cacheline被加载。因此,meltdown在进行探测数据cacheline扫描过程中,如果没有任何cacheline命中,那么秘密数据实际上就是“0”。
The loop is terminated by either the read value not being ‘0’ or by the raised exception of the invalid memory access. Note that this loop does not slow down the attack measurably, since, in either case, the processor runs ahead of the illegal memory access, regardless of whether ahead is a loop or ahead is a linear control flow. In either case, the time until the control flow returned from exception handling or exception suppression remains the same with and without this loop. Thus, capturing read ‘0’s beforehand and recovering early from a lost race condition vastly increases the reading speed.
无论是读出数值非“0”或无效地址访问触发了异常,代码中的循环逻辑都会终止。注意,这个循环不会降低攻击的性能,因为,在上面两种情况中,CPU会提前允许非法内存访问指令之后的代码指令,而CPU并不关心这些指令是一个循环控制或是一个线性的控制流。无论哪一种情况,从异常处理函数(或者异常抑制)返回的时间都是一样的,和有没有循环控制是无关的。因此,尽早发现读出值是“0”,也就是说尽早发现自己在和异常的竞争中失败并恢复,可以大大提高了读取速度。
Single-bit transmission :
In the attack description in Section 5.1, the attacker transmitted 8 bits through the covert channel at once and performed 28 = 256 Flush+Reload measurements to recover the secret. However, there is a clear trade-off between running more transient instruction sequences and performing more Flush+Reload measurements. The attacker could transmit an arbitrary number of bits in a single transmission through the covert channel, by either reading more bits using a MOV instruction for a larger data value. Furthermore, the attacker could mask bits using additional instructions in the transient instruction sequence. We found the number of additional instructions in the transient instruction sequence to have a negligible influence on the performance of the attack.
单个bit数据的发送:
在第5.1节的描述中,攻击者通过隐蔽通道一次可以传输8个bit,接收端执行2^8=256 次Flush+Reload命令来恢复秘密数据。不过,我们需要在运行更多的瞬态指令序列和执行更多的Flush+Reload测量之间进行平衡。攻击者可以通过隐蔽通道在一次传输中发送任意比特的数据,当然这需要使用MOV指令去读取更多bit的秘密数据。此外,攻击者可以在瞬态指令序列中增加mask的操作(这样可以传送更少的bit,从而减少接收端Flush+Reload的次数)。我们发现在瞬态指令序列中增加的指令数对攻击的性能影响是微不足道的。
The performance bottleneck in the generic attack description above is indeed, the time spent on Flush+Reload measurements. In fact, with this implementation, almost the entire time will be spent on Flush+Reload measurements. By transmitting only a single bit, we can omit all but one Flush+Reload measurement, i.e., the measurement on cache line 1. If the transmitted bit was a ‘1’, then we observe a cache hit on cache line 1. Otherwise, we observe no cache hit on cache line 1.
上面描述的meltdown攻击中的性能瓶颈主要是在通过Flush+Reload恢复秘密数据上所花费的时间。实际上在本章中的meltdown代码实现中,几乎所有的时间都将花费在Flush+Reload上了。如果只发送一个bit,那么除了一次Flush+Reload测量时间,其他的我们都可以忽略。在这种情况下,我们只需要检测一个cacheline的状态,如果cache hit,那么传输的bit是“1”,如果cache miss,那么传输的bit是“0”。
Transmitting only a single bit at once also has drawbacks. As described above, our side channel has a bias towards a secret value of ‘0’. If we read and transmit multiple bits at once, the likelihood that all bits are ‘0’ may quite small for actual user data. The likelihood that a single bit is ‘0’ is typically close to 50 %. Hence, the number of bits read and transmitted at once is a tradeoff between some implicit error-reduction and the overall transmission rate of the covert channel.
一次只传输一个比特也有缺点。如上所述,我们的侧通道更偏向于“0”值。如果我们一次读取多个比特的秘密数据并发送出去,那么所有bit都是“0”的可能性应该说是相当小。单个bit等于“0”的可能性通常接近50%。因此,一次传输的比特数是需要在隐蔽信道的总传输速率和减少差错之间进行平衡。
However, since the error rates are quite small in either case, our evaluation (cf. Section 6) is based on the single-bit transmission mechanics.
不过,由于两种情况下的错误率都很小,因此我们的评估(参见第6节)是基于单比特传输机制的。
Exception Suppression using Intel TSX.
和Intel的TSX相关,暂时没有兴趣了解。
Dealing with KASLR.
In 2013, kernel address space layout randomization (KASLR) had been introduced to the Linux kernel (starting from version 3.14 [4]) allowing to randomize the location of the kernel code at boot time. However, only as recently as May 2017, KASLR had been enabled by default in version 4.12 [27]. With KASLR also the direct-physical map is randomized and, thus, not fixed at a certain address such that the attacker is required to obtain the randomized offset before mounting the Meltdown attack. However, the randomization is limited to 40 bit.
处理KASLR。
2013年,内核地址空间布局随机化(KASLR)已被合并到Linux内核中(从3.14版开始[ 4 ]),这个特性允许在开机的时候把内核代码加载到一个随机化地址上去。在最近的(2017年5月)4.12版的内核中,KASLR已经被默认启用[ 27 ]。并且直接映射部分的地址也是随机的,并非固定在某个地址上。因此,在利用meltdown漏洞对内核进行攻击之前,攻击者需要需要获得一个40-bit的随机偏移值。
Thus, if we assume a setup of the target machine with 8GB of RAM, it is sufficient to test the address space for addresses in 8GB steps. This allows to cover the search space of 40 bit with only 128 tests in the worst case. If the attacker can successfully obtain a value from a tested address, the attacker can proceed dumping the entire memory from that location. This allows to mount Meltdown on a system despite being protected by KASLR within seconds.
假设目标机有8GB内存,那么我们其实是可以使用8G的步长来进行地址空间的探测。即便是在最坏的情况下也只有128次就可以确定这个40-bit的随机偏移值。攻击者一旦能够成功地攻击某个测试地址,那么他也可以继续从该位置dump整个内存。尽管系统受到KASLR的保护,实际上利用meltdown漏洞,攻击者也可以在几秒钟内完成攻击。
6.评估(Evaluation)
In this section, we evaluate Meltdown and the performance of our proof-of-concept implementation 2. Section 6.1 discusses the information which Meltdown can leak, and Section 6.2 evaluates the performance of Meltdown, including countermeasures. Finally, we discuss limitations for AMD and ARM in Section 6.4.
在本章中,我们将评估meltdown的影响以及我们POC(proof-of-concept)实现的性能。6.1节讨论了meltdown可能泄漏的信息,6.2节评估了meltdown的性能和对策。最后在6.4节中,我们讨论了在AMD和ARM处理器上meltdown的局限性。
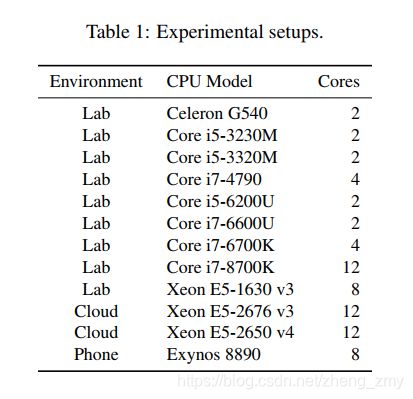
Table 1 shows a list of configurations on which we successfully reproduced Meltdown. For the evaluation of Meltdown, we used both laptops as well as desktop PCs with Intel Core CPUs. For the cloud setup, we tested Meltdown in virtual machines running on Intel Xeon CPUs hosted in the Amazon Elastic Compute Cloud as well as on DigitalOcean. Note that for ethical reasons we did not use Meltdown on addresses referring to physical memory of other tenants.
clip_image014
在上面列表显示的系统中,我们都成功地利用meltdown漏洞进行了攻击。我们在使用英特尔CPU的笔记本电脑和台式机上进行了meltdown的评估。对于云服务器,我们测试Amazon Elastic Compute Cloud和DigitalOcean的虚拟机,CPU是英特尔的Xeon处理器。出于道德的原因,我们没有使用meltdown去获取真实用户物理内存地址上的数据。
6.1各种环境下的信息泄露( Leakage and Environments)
We evaluated Meltdown on both Linux (cf. Section 6.1.1) and Windows 10 (cf. Section 6.1.3). On both operating systems, Meltdown can successfully leak kernel memory. Furthermore, we also evaluated the effect of the KAISER patches on Meltdown on Linux, to show that KAISER prevents the leakage of kernel memory (cf. Section 6.1.2). Finally, we discuss the information leakage when running inside containers such as Docker (cf. Section 6.1.4).
我们在Linux(参见第6.1.1)和Windows 10(参见第6.1.3)这两个操作系统上评估了meltdown漏洞,结果表明它们都可以成功地泄漏内核信息。此外,我们还测试了KAISER补丁在Linux上的效果,结果表明KAISER补丁可以防止内核信息泄漏(参见第6.1.2)。最后,我们讨论了在容器环境下(例如Docker)的信息泄漏(参见第6.1.4)。
6.1.1Linux
We successfully evaluated Meltdown on multiple versions of the Linux kernel, from 2.6.32 to 4.13.0. On all these versions of the Linux kernel, the kernel address space is also mapped into the user address space. Thus, all kernel addresses are also mapped into the address space of user space applications, but any access is prevented due to the permission settings for these addresses. As Meltdown bypasses these permission settings, an attacker can leak the complete kernel memory if the virtual address of the kernel base is known. Since all major operating systems also map the entire physical memory into the kernel address space (cf. Section 2.2), all physical memory can also be read.
我们成功地对多个版本的Linux内核(从2.6.32到4.13.0)进行了Meltdown评估。在Linux内核的所有这些版本中,内核地址空间都映射到了用户进程地址空间中。但由于权限设置,任何来自用户空间的内核数据访问都被阻止。Meltdown可以绕过这些权限设置,并且只要攻击者知道内核虚拟地址,都可以发起攻击,从而泄露内核数据。由于所有主要操作系统都将整个物理内存映射到内核地址空间(参见第2.2节),因此利用meltdown漏洞可以读取所有物理内存的数据。
Before kernel 4.12, kernel address space layout randomization (KASLR) was not active by default [30]. If KASLR is active, Meltdown can still be used to find the kernel by searching through the address space (cf. Section 5.2). An attacker can also simply de-randomize the direct-physical map by iterating through the virtual address space. Without KASLR, the direct-physical map starts at address 0xffff 8800 0000 0000 and linearly maps the entire physical memory. On such systems, an attacker can use Meltdown to dump the entire physical memory, simply by reading from virtual addresses starting at 0xffff 8800 0000 0000.
在4.12内核之前,内核地址空间布局随机化(KASLR)不是默认启用的[ 30 ]。如果启动KASLR这个特性,meltdown仍然可以用来找到内核的映射位置(这是通过搜索地址空间的方法,具体参见5.2节)。攻击者也可以通过遍历虚拟地址空间的方法来找到物理内存直接映射的信息。没有KASLR,Linux内核会在0xffff 8800 0000 0000开始的线性地址区域内映射整个物理内存。在这样的系统中,攻击者可以用meltdown轻松dump整个物理内存,因为攻击者已经清楚的知道物理内存的虚拟地址是从0xffff 8800 0000 0000开始的。
On newer systems, where KASLR is active by default, the randomization of the direct-physical map is limited to 40 bit. It is even further limited due to the linearity of the mapping. Assuming that the target system has at least 8GB of physical memory, the attacker can test addresses in steps of 8 GB, resulting in a maximum of 128 memory locations to test. Starting from one discovered location, the attacker can again dump the entire physical memory.
在新的linux系统中,KASLR是默认启动的,因此物理内存的虚拟地址并非从0xffff 8800 0000 0000开始,而是需要累加一个40-bit的随机偏移。由于物理内存的映射是线性的,KASLR阻挡meltdown攻击的效果进一步受到限制。假设目标系统有8GB内存,攻击者可以按照8 GB的步长来破解40-bit的随机偏移,最多128次尝试就可以推出这个随机偏移。一旦攻破了随机偏移值,攻击者可以再次dump整个物理内存。
Hence, for the evaluation, we can assume that the randomization is either disabled, or the offset was already retrieved in a pre-computation step.
因此,在本节的meltdown评估中,我们可以假设KASLR是禁用的,或者随机偏移量已经在预先计算出来了。
6.1.2带有KAISER补丁的Linux(Linux with KAISER patch)
The KAISER patch by Gruss et al. [8] implements a stronger isolation between kernel and user space.
KAISER does not map any kernel memory in the user space, except for some parts required by the x86 architecture (e.g., interrupt handlers). Thus, there is no valid mapping to either kernel memory or physical memory (via the direct-physical map) in the user space, and such addresses can therefore not be resolved. Consequently, Meltdown cannot leak any kernel or physical memory except for the few memory locations which have to be mapped in user space.
Gruss发布的KAISER补丁[ 8 ]实现了内核和用户空间之间更强的隔离。KAISER根本不把内核地址空间映射到用户进程空间中去。除了x86架构所需的某些部分代码之外(如中断处理程序),在用户空间中根本看不到物理内存的直接映射,也看不到内核地址空间的任何信息。没有有效的映射,因此用户空间根本不能解析这些地址。因此,除了少数必须在用户空间中映射的物理内存或者内核地址外,meltdown不能泄漏任何数据。
We verified that KAISER indeed prevents Meltdown, and there is no leakage of any kernel or physical memory.
我们验证了KAISER确实解决了meltdown漏洞,没有任何内核或物理内存数据的泄漏。
Furthermore, if KASLR is active, and the few remaining memory locations are randomized, finding these memory locations is not trivial due to their small size of several kilobytes. Section 7.2 discusses the implications of these mapped memory locations from a security perspective.
此外,如果启用了KASLR,虽然有部分内核地址空间的映射是用户态可见的,但是这些内核地址的位置是随机的,而且由于这段内存区域只有几KB,发现这些内存位置不是一件简单的事情。7.2节从安全的角度讨论了映射这一小段内存的含义。
6.1.3Microsoft Windows
We successfully evaluated Meltdown on a recent Microsoft Windows 10 operating system, last updated just before patches against Meltdown were rolled out. In line with the results on Linux (cf. Section 6.1.1), Meltdown also can leak arbitrary kernel memory on Windows. This is not surprising, since Meltdown does not exploit any software issues, but is caused by a hardware issue.
我们在最新的Mi crosoft Windows 10操作系统上成功评估了Meltdown,该操作系统在推出针对Meltdown的补丁程序之前进行了最新更新。与Linux上的结果一致(请参阅第6.1.1节),Meltdown还会泄漏Windows上的任意内核内存。这并不奇怪,因为Meltdown不会利用任何软件问题,但是由硬件问题引起的。
In contrast to Linux, Windows does not have the concept of an identity mapping, which linearly maps the physical memory into the virtual address space. Instead, a large fraction of the physical memory is mapped in the paged pools, non-paged pools, and the system cache. Furthermore, Windows maps the kernel into the address space of every application too. Thus, Meltdown can read kernel memory which is mapped in the kernel address space, i.e., any part of the kernel which is not swapped out, and any page mapped in the paged and non-paged pool, and the system cache.
与Linux相比,除了身份映射之外Windows没有缺点,身份映射将物理内存线性映射到虚拟地址空间。而是将很大一部分物理内存映射到页面缓冲池,非页面缓冲池和系统缓存中。此外,Windows还将内核映射到每个应用程序的地址空间。因此,Meltdown可以读取映射在内核地址空间中的内核内存,即未交换掉的内核的任何部分,以及在分页和非分页池中映射的任何页面,以及系统缓存。
Note that there are physical pages which are mapped in one process but not in the (kernel) address space of another process, i.e., physical pages which cannot be attacked using Meltdown. However, most of the physical memory will still be accessible through Meltdown.
请注意,有些物理页面是在一个进程中映射的,而不是在另一个进程的(内核)地址空间中映射的,即无法使用Meltdown定位的物理页面。然而,大多数物理内存仍然可以通过Meltdown访问。
We were successfully able to read the binary of the Windows kernel using Meltdown. To verify that the leaked data is actual kernel memory, we first used the Windows kernel debugger to obtain kernel addresses containing actual data. After leaking the data, we again used the Windows kernel debugger to compare the leaked data with the actual memory content, confirming that Meltdown can successfully leak kernel memory.
我们能够使用Meltdown成功读取Windows内核的二进制文件。为了验证泄漏的数据是实际的内核内存,我们首先使用Windows内核调试器获取包含实际数据的内核地址。泄漏数据后,我们再次使用Windows内核调试器将泄漏的数据与实际内存内容进行比较,确认Meltdown可以成功泄漏内核内存。
6.1.4Android
We successfully evaluated Meltdown on a Samsung Galaxy S7 mohile phone running LineageOS Android 14.1 with a Linux kernel 3.18.14. The device is equipped with a Samsung Exynos 8 Octa 8890 SoC consisting of a ARM Cortex-A53 CPU with 4 cores as well as an Exynos M1 ”Mongoose” CPU with 4 cores [6]. While we were not able to mount the attack on the CortexA53 CPU, we successfully mounted Meltdown on Samsung’s custom cores. Using exception suppression described in Section 4.1, we successfully leaked a predefined string using the direct-physical map located at the virtual address 0xffff ffbf c000 0000.
我们在运行LineageOS Android 14.1和Linux内核3.18.14的Samsung Galaxy S7 Mohile手机上成功评估了Meltdown。该设备配备了三星Exynos 8 Octa 8890 SoC,该芯片由具有4个内核的ARM Cortex-A53 CPU以及一个具有4个内核的Exynos M1“猫鼬” CPU [6]。虽然我们无法在Cortex上发起攻击A53 CPU,我们成功将Meltdown安装在三星的定制内核上。使用第4.1节中描述的异常抑制,我们使用位于虚拟地址0xffff ffbf c000 0000的直接物理映射成功泄漏了预定义的字符串。
6.1.5容器(Containers)
We evaluated Meltdown running in containers sharing a kernel, including Docker, LXC, and OpenVZ, and found that the attack can be mounted without any restrictions. Running Meltdown inside a container allows to leak information not only from the underlying kernel, but also from all other containers running on the same physical host.
我们评估了容器环境下(共享一个内核)的meltdown,包括Docker,LXC,和OpenVZ,结果发现meltdown可以没有任何限制发起攻击。在容器中运行执行meltdown攻击不仅可以泄漏底层内核信息,还可以泄漏同一物理主机上其他容器上的信息。
The commonality of most container solutions is that every container uses the same kernel, i.e., the kernel is shared among all containers. Thus, every container has a valid mapping of the entire physical memory through the direct-physical map of the shared kernel. Furthermore, Meltdown cannot be blocked in containers, as it uses only memory accesses. Especially with Intel TSX, only unprivileged instructions are executed without even trapping into the kernel.
大多数容器解决方案都是使用相同的内核,即内核是在所有容器中共享的。因此,每个容器中都有对整个物理内存的直接映射。由于只涉及内存访问,在容器中并不能阻止meltdown攻击。特别是在使用英特尔TSX特性的情况下,攻击根本不需要陷入内核执行,只有非特权指令的执行。
Thus, the isolation of containers sharing a kernel can be fully broken using Meltdown. This is especially critical for cheaper hosting providers where users are not separated through fully virtualized machines, but only through containers. We verified that our attack works in such a setup, by successfully leaking memory contents from a container of a different user under our control.
因此,共享内核的容器隔离可以轻松地被meltdown攻破。对于那些提供廉价主机托管服务的提供商来说,这个问题更严重,因为在那种情况下,用户不能通过完全虚拟化的物理机器进行隔离,而只能通过容器进行隔离。我们验证了在这样的环境中,meltdown的确是起作用的,我们可以成功地从其他用户容器中盗取内存信息。
6.1.6 未缓存和不可缓存的内存(Uncached and Uncacheable Memory)
In this section, we evaluate whether it is a requirement for data to be leaked by Meltdown to reside in the L1 data cache [33]. Therefore, we constructed a setup with two processes pinned to different physical cores. By flushing the value, using the clflush instruction, and only reloading it on the other core, we create a situation where the target data is not in the L1 data cache of the attacker core. As described in Section 6.2, we can still leak the data at a lower reading rate. This clearly shows that data presence in the attacker’s L1 data cache is not a requirement for Meltdown. Furthermore, this observation has also been confirmed by other researchers [7, 35, 5].
在本节中,我们评估是否需要将Meltdown泄漏的数据保留在L1数据缓存中[33]。因此,我们构建了一个将两个进程固定到不同物理核心的设置。通过使用clflush指令刷新该值,并仅在另一个内核上重新加载它,我们造成了一种情况,即目标数据不在攻击者内核的L1数据高速缓存中。如第6.2节所述,我们仍然可以较低的读取速率泄漏数据。这清楚地表明,攻击者的L1数据缓存中没有数据,这并不是Meltdown的必要条件。此外,该观察结果其他研究者也证实了这一点[7,35,5]。
The reason why Meltdown can leak uncached memory may be that Meltdown implicitly caches the data. We devise a second experiment, where we mark pages as uncacheable and try to leak data from them. This has the consequence that every read or write operation to one of those pages will directly go to the main memory, thus, bypassing the cache. In practice, only a negligible amount of system memory is marked uncacheable. We observed that if the attacker is able to trigger a legitimate load of the target address, e.g., by issuing a system call (regular or in speculative execution [40]), on the same CPU core as the Meltdown attack, the attacker can leak the content of the uncacheable pages. We suspect that Meltdown reads the value from the line fill buffers. As the fill buffers are shared between threads running on the same core, the read to the same address within the Meltdown attack could be served from one of the fill buffers allowing the attack to succeed. However, we leave further investigations on this matter open for future work.
Meltdown可能泄漏未缓存的内存的原因可能是Meltdown隐式缓存了数据。我们设计了第二个实验,在该实验中,我们将页面标记为不可缓存,并尝试从中泄漏数据。结果是,对那些页面之一的每次读或写操作都将直接进入主内存,从而绕过缓存。实际上,只有微不足道的系统内存被标记为不可缓存。我们观察到,如果攻击者能够(例如,通过在与Meltdown攻击相同的CPU内核上发出系统调用(常规或推测执行[40])来触发目标地址的合法加载,则攻击者可能会泄漏不可缓存页面的内容。我们怀疑Meltdown从行填充缓冲区读取了该值。如填充缓冲区在同一内核上运行的线程之间共享,读取到Melt中的同一地址可以从填充缓冲区之一提供向下攻击允许攻击成功。但是,我们将进一步调查此事留待将来工作。
A similar observation on uncacheable memory was also made with Spectre attacks on the System Management Mode [10]. While the attack works on memory set uncacheable over Memory-Type Range Registers, it does not work on memory-mapped I/O regions, which is the expected behavior as accesses to memory-mapped I/O can always have architectural effects.
通过对System Manage的Spectre攻击,对不可缓存的内存也有类似模式[10]的观察。虽然攻击针对无法通过“内存类型范围寄存器”缓存的内存集,但它不适用于内存映射的I / O区域,这是预期的行为,因为访问内存映射的I / O始终会产生体系结构影响。
6.2meltdown性能
To evaluate the performance of Meltdown, we leaked known values from kernel memory. This allows us to not only determine how fast an attacker can leak memory, but also the error rate, i.e., how many byte errors to expect. We achieved average reading rates of up to 503KB/s with an error rate as low as 0.02% when using exception suppression. For the performance evaluation, we focused on the Intel Core i7-6700K as it supports Intel TSX, to get a fair performance comparison between exception handling and exception suppression.
为了评估meltdown的性能,我们事先在准备攻击的内核内存中设定了指定的数值。这使我们不仅能够确定攻击者盗取内存数据的速度,而且还可以确定错误率(即有多少字节的错误)。在使用异常抑制(需要TSX支持)的情况下,我们实现了503kB / s的数据泄露速度,而错误率低于0.02%。对于性能评估,我们集中在英特尔的Core i7-6700k处理器,因为它支持TSX。这样我们可以在一个公平环境中(同一个CPU)比较异常处理和异常抑制两种方法下meltdown的性能。
For all tests, we use Flush+Reload as a covert channel to leak the memory as described in Section 5. We evaluated the performance of both exception handling and exception suppression (cf. Section 4.1). For exception handling, we used signal handlers, and if the CPU supported it, we also used exception suppression using Intel TSX. An extensive evaluation of exception suppression using conditional branches was done by Kocher et al. [19] and is thus omitted in this paper for the sake of brevity.
对于所有的测试,我们使用Flush+Reload作为一个隐蔽通道来泄漏内存信息,具体可以参考第5章的描述。我们评估了异常处理和异常抑制这两种方法下meltdown的性能(参见第4.1节)。对于异常处理,我们设置信号处理函数。如果CPU支持,我们也可以利用英特尔TSX来完成异常抑制。使用条件分支来完成异常抑制的评估是由Kocher等人完成的[ 19 ]。为了简洁起见,本文省略了这部分的内容。
(1)异常处理
Exception handling is the more universal implementation, as it does not depend on any CPU extension and can thus be used without any restrictions. The only requirement for exception handling is operating system support to catch segmentation faults and continue operation afterwards. This is the case for all modern operating systems, even though the specific implementation differs between the operating systems. On Linux, we used signals, whereas, on Windows, we relied on the Structured Exception Handler.
异常处理的方法更通用一些,因为它不依赖于任何CPU扩展特性,从而可以不受任何限制地在各种处理器上使用。异常处理的唯一要求是操作系统支持捕捉segmentation fault并继续操作。基本上所有现代操作系统都支持这个特性,不过具体的实现会有所不同。在Linux上,我们使用信号,而在Windows上,我们依赖Structured Exception Handler。
With exception handling, we achieved average reading speeds of 123KB/s when leaking 12MB of kernel memory. Out of the 12MB kernel data, only 0.03%were read incorrectly. Thus, with an error rate of 0.03 %, the channel capacity is 122KB/s.
在使用异常处理的情况下,我们实现了以123kB / s的平均速度完成了12MB内核数据的泄漏。在12MB的内核数据中,错误率只有0.03%。因此信道容量是122kB/s。
(2)异常抑制
和Intel处理器相关,忽略之。
3、Meltdown实战
这个小节展示了几个具体的meltdown攻击效果,忽略之。
6.3AMD和ARM处理器上的限制
We also tried to reproduce the Meltdown bug on several ARM and AMD CPUs. However, we did not manage to successfully leak kernel memory with the attack described in Section 5, neither on ARM nor on AMD. The reasons for this can be manifold. First of all, our implementation might simply be too slow and a more optimized version might succeed. For instance, a more shallow out-of-order execution pipeline could tip the race condition towards against the data leakage. Similarly, if the processor lacks certain features, e.g., no re-order buffer, our current implementation might not be able to leak data. However, for both ARM and AMD, the toy example as described in Section 3 works reliably, indicating that out-of-order execution generally occurs and instructions past illegal memory accesses are also performed.
我们还试图在几款ARM和AMD CPU上重现meltdown漏洞。然而无论是在ARM上还是在AMD处理器上,我们都没有成功地使用第5章中描述的攻击方法来盗取到内核内存。造成这种情况的原因是多方面的。首先,我们的实现可能太慢,一个更优化的版本可能会成功。例如,一个更浅的乱序执行流水线可能会让数据泄漏变得更困难一些。类似地,如果处理器缺少某些特性,例如没有重新排序缓冲区(re-order buffer),那么我们当前的代码实现可能根据无法造成泄漏数据。不过,对于ARM和AMD处理器来说,第3章中描述的简单示例仍然可以可靠的工作,这表明在那些CPU上也发生了乱序执行,即非法内存访问的指令之后的指令也提前被执行。
7.对策
In this section, we discuss countermeasures against the Meltdown attack. At first, as the issue is rooted in the hardware itself, we want to discuss possible microcode updates and general changes in the hardware design. Second, we want to discuss the KAISER countermeasure that has been developed to mitigate side-channel attacks against KASLR which inadvertently also protects against Meltdown.
在这一章中,我们讨论了如何应对meltdown攻击。由于这个issue本身是源于硬件设计,因此我们首先讨论如何通过更新硬件设计来修复这个漏洞。其次,我们讨论如何用KAISER来减轻meltdown,虽然KAISER最初的设计是为了防止KASLR侧信道攻击的。
7.2硬件策略(Hardware)
Meltdown bypasses the hardware-enforced isolation of security domains. There is no software vulnerability involved in Meltdown. Hence any software patch (e.g., KAISER [8]) will leave small amounts of memory exposed (cf. Section 7.2). There is no documentation whether such a fix requires the development of completely new hardware, or can be fixed using a microcode update.
Meltdown并不涉及软件漏洞,它是直接绕过硬件隔离机制。因此,任何软件补丁(例如,KAISER[8])都会暴露出少量的内存区域(参见第7.2节)。是否需要开发全新的硬件或使用微码更新来修复meltdown,没有文件说明这一点。
As Meltdown exploits out-of-order execution, a trivial countermeasure would be to completely disable out-of-order execution. However, the performance impacts would be devastating, as the parallelism of modern CPUs could not be leveraged anymore. Thus, this is not a viable solution.
由于meltdown利用了乱序执行,一个简单的对策就是完全禁用乱序执行。不过这对性能的影响将是毁灭性的,因为我们将无法再利用现代CPU的并行性了。因此,这个解决方案不可行。
Meltdown is some form of race condition between the fetch of a memory address and the corresponding permission check for this address. Serializing the permission check and the register fetch can prevent Meltdown, as the memory address is never fetched if the permission check fails. However, this involves a significant overhead to every memory fetch, as the memory fetch has to stall until the permission check is completed.
Meltdown是“获取内存地址数据”和“权限检查”之间的一种竞态条件(race condition)。严格在获取地址数据之前进行权限检查可以防止meltdown,即在不能通过权限检查时候,CPU根本没有办法把受保护的内存数据加载到寄存器。然而,这给每一个内存访问增加了很大的开销,因为在完成权限检查之前,内存访问的动作只能stall。
A more realistic solution would be to introduce a hard split of user space and kernel space. This could be enabled optionally by modern kernels using a new hard split bit in a CPU control register, e.g., CR4. If the hard split bit is set, the kernel has to reside in the upper half of the address space, and the user space has to reside in the lower half of the address space. With this hard split, a memory fetch can immediately identify whether such a fetch of the destination would violate a security boundary, as the privilege level can be directly derived from the virtual address without any further lookups. We expect the performance impacts of such a solution to be minimal. Furthermore, the backwards compatibility is ensured, since the hard-split bit is not set by default and the kernel only sets it if it supports the hard-split feature.
一个更现实的解决方案是从硬件层面区分用户空间和内核空间。这可以通过CPU寄存器(例如cr4)的一个bit(称之hard-split bit)来开启。如果该bit设置为1,则内核地址必须在地址空间的上半部分,而用户空间必须位于地址空间的下半部分。有了这种硬件机制,违反权限的内存读取可以被立刻识别,这是因为所需特权级别可以直接从虚拟地址推导出来而不需要任何进一步的查找。我们认为这种解决方案对性能的影响是最小的。此外,向后兼容性也得到保证,因为默认情况下我们不设置hard-split bit,而内核仅在硬件支持的时候才设置它。
Note that these countermeasures only prevent Meltdown, and not the class of Spectre attacks described by Kocher et al. [19]. Likewise, several countermeasures presented by Kocher et al. [19] have no effect on Meltdown. We stress that it is important to deploy countermeasures against both attacks.
请注意,这些对策只能防止meltdown,对Kocher等人发现的幽灵攻击无效[ 19 ]。同样,由Kocher等人提出的解决spectre漏洞[ 19 ] 的对策,对meltdown也没有效果。我们这里再次强调一下:针对这两种攻击部署相关的对策是非常重要的。
7.2KAISER
As hardware is not as easy to patch, there is a need for software workarounds until new hardware can be deployed. Gruss et al. [8] proposed KAISER, a kernel modification to not have the kernel mapped in the user space. This modification was intended to prevent side-channel attacks breaking KASLR [13, 9, 17]. However, it also prevents Meltdown, as it ensures that there is no valid mapping to kernel space or physical memory available in user space. KAISER will be available in the upcoming releases of the Linux kernel under the name kernel page-table isolation (KPTI) [25]. The patch will also be backported to older Linux kernel versions. A similar patch was also introduced in Microsoft Windows 10 Build 17035 [15]. Also, Mac OS X and iOS have similar features [22].
硬件修复漏洞没有那么快,因此我们还是要到在新的硬件可以部署之前,提供软件绕过的方案。Gruss等人[ 8 ]建议了KAISER方案,该方案对内核进行修改,以便在用户进程地址空间中根本看不到内核地址的映射。这个补丁是为了防止侧信道攻击方法攻破KASLR [ 13, 9, 17 ]。然而,因为它确保了在用户空间没有有效的内核空间映射或物理内存映射,因此KAISER也能解决meltdown问题。KAISER将会出现在即将发布的Linux内核中,名字改成了KPTI(kernel page-table isolation)[ 25 ],同时该补丁也将移植到旧的Linux内核版本。微软Windows 10也提供了类似的补丁[ 15 ]。另外,Mac OS X和iOS也有类似的功能[ 22 ]。
Although KAISER provides basic protection against Meltdown, it still has some limitations. Due to the design of the x86 architecture, several privileged memory locations are required to be mapped in user space [8]. This leaves a residual attack surface for Meltdown, i.e., these memory locations can still be read from user space. Even though these memory locations do not contain any secrets, such as credentials, they might still contain pointers. Leaking one pointer can be enough to again break KASLR, as the randomization can be calculated from the pointer value.
虽然KAISER提供了基本的保护以防止meltdown,但它仍然有一些局限性。由于x86架构的设计,需要在用户空间中映射一小段内核地址空间[ 8 ],因此这些内存位置仍然可以从用户空间读取,这为meltdown攻击留下伏笔。即使这些内存位置不包含任何机密数据,它们仍然可能包含指针。其实一个指针的数据就足够攻破KASLR,因为随机偏移可以根据指针的值推导出来。
Still, KAISER is the best short-time solution currently available and should therefore be deployed on all systems immediately. Even with Meltdown, KAISER can avoid having any kernel pointers on memory locations that are mapped in the user space which would leak information about the randomized offsets. This would require trampoline locations for every kernel pointer, i.e., the interrupt handler would not call into kernel code directly, but through a trampoline function. The trampoline function must only be mapped in the kernel. It must be randomized with a different offset than the remaining kernel. Consequently, an attacker can only leak pointers to the trampoline code, but not the randomized offsets of the remaining kernel. Such trampoline code is required for every kernel memory that still has to be mapped in user space and contains kernel addresses. This approach is a trade-off between performance and security which has to be assessed in future work.
不过,KAISER仍然是目前最好的短期解决方案,并且应该立即部署到所有系统上。即便是CPU存在meltdown漏洞,KAISER补丁避免了在用户空间映射的内存位置上保存内核的指针,这样可以避免泄露随机偏移的信息。为了达到这个目标,我们需要为每一个内核指针建立trampoline code,例如:中断处理程序不会直接调用内核代码,而是通过trampoline函数。trampoline函数只会映射到内核空间,但是和其余部分的内核应该在不同的随机偏移上。因此,攻击者只能获取trampoline code的内核地址,而不能破解剩余内核的随机偏移。每一个进程地址空间仍然映射了trampoline code这段内存,而这段内存中也包括了内核的地址,存在一定的风险,但是这种方法是性能和安全性之间进行平衡,也是我们必须在今后的工作进一步研究的课题。
8.讨论
Meltdown fundamentally changes our perspective on the security of hardware optimizations that manipulate the state of microarchitectural elements. The fact that hardware optimizations can change the state of microarchitectural elements, and thereby imperil secure soft-ware implementations, is known since more than 20 years [20]. Both industry and the scientific community so far accepted this as a necessary evil for efficient computing. Today it is considered a bug when a cryptographic algorithm is not protected against the microarchitectural leakage introduced by the hardware optimizations. Meltdown changes the situation entirely. Meltdown shifts the granularity from a comparably low spatial and temporal granularity, e.g., 64-bytes every few hundred cycles for cache attacks, to an arbitrary granularity, allowing an attacker to read every single bit. This is nothing any (cryptographic) algorithm can protect itself against. KAISER is a short-term software fix, but the problem we uncovered is much more significant.
通过调整CPU微架构状态,CPU设计者可以优化硬件的性能,由此引入的安全问题并没有引起足够的重视,Meltdown从根本上改变了这一点,即CPU设计者必须直面安全问题。20多年以来,CPU设计者很清楚的知道这样一个事实:硬件优化可以改变CPU微架构的状态,从而给安全软件的实现带来风险[ 20 ]。但是到目前为止,工业界和科学界都认为这是高效计算所必需面对的一个问题,你不得不接受它。现在,当一个加密算法不能保护微架构状态的泄露(由于硬件优化而引入),我们认为这是一个软件bug。Meltdown彻底改变了现状。原来的攻击在空间和时间粒度上是相对较小,例如,缓存攻击的空间粒度是64个字节,时间粒度是大概几百个周期。有了meltdown,空间和时间粒度可以任意指定,允许攻击者读取每一个比特位,这不是什么(加密)算法可以保护了的。KAISER是一个短期的软件解决方案,但我们揭示的问题更为重要(即不能为了性能而忽略安全性)。
We expect several more performance optimizations in modern CPUs which affect the microarchitectural state in some way, not even necessarily through the cache. Thus, hardware which is designed to provide certain security guarantees, e.g., CPUs running untrusted code, require a redesign to avoid Meltdown- and Spectre-like attacks. Meltdown also shows that even error-free software, which is explicitly written to thwart side-channel attacks, is not secure if the design of the underlying hardware is not taken into account.
我们期待更多的性能优化出现在现代CPU上,这些优化可能以某种方式影响微架构的状态(未必一定是影响缓存状态,可能是其他的CPU微架构单元)。不过只要CPU硬件的设计需求中包含了安全性,那么CPU设计者就需要重新设计以避免meltdown和spectre的攻击。Meltdown还表明:即便是软件没有bug,而且也小心的设计以避免侧信道攻击,如果不仔细思考底层硬件的安全性,那么它也是不安全的。
With the integration of KAISER into all major operating systems, an important step has already been done to prevent Meltdown. KAISER is also the first step of a paradigm change in operating systems. Instead of always mapping everything into the address space, mapping only the minimally required memory locations appears to be a first step in reducing the attack surface. However, it might not be enough, and an even stronger isolation may be required. In this case, we can trade flexibility for performance and security, by e.g., forcing a certain virtual memory layout for every operating system. As most modern operating system already use basically the same memory layout, this might be a promising approach.
随着KAISER集成到目前所有的主流操作系统中,我们在防止meltdown上已经迈出了重要的一步。KAISER也改变了操作系统中地址映射的设计思路。原来我们总是将所有地址(包括内核和用户)映射到整个进程地址空间,现在,在用户态执行的时候只是映射必要的地址空间。这的确是减少攻击范围。然而,这可能是不够的,我们可能需要更强烈的隔离。在这种情况下,我们需要在性能和安全性上进行平衡,例如,强制每个操作系统符合特定的虚拟内存布局。由于大多数现代操作系统使用了基本相同的内存布局,这可能是一种很有前途的方法。
Meltdown also heavily affects cloud providers, especially if the guests are not fully virtualized. For performance reasons, many hosting or cloud providers do not have an abstraction layer for virtual memory. In such environments, which typically use containers, such as Docker or OpenVZ, the kernel is shared among all guests. Thus, the isolation between guests can simply be circumvented with Meltdown, fully exposing the data of all other guests on the same host. For these providers, changing their infrastructure to full virtualization or using software workarounds such as KAISER would both increase the costs significantly.
Meltdown也严重影响了云服务提供商,特别是在客户机没有完全虚拟化的场景中。出于性能方面的原因,许多云服务提供商没有虚拟内存的抽象层。在这样的环境中(通常是使用容器,如Docker或OpenVZ),内核在所有的guest os中共享。因此,虽然存在guest os之间的隔离,但是我们可以利用Meltdown,将其他guest os的数据(在同一个主机)暴露出来。对于这些供应商,改变他们的基础设施,变成全虚拟化或使用软件解决方法(如KAISER)都会增加成本。
Even if Meltdown is fixed, Spectre [19] will remain an issue. Spectre [19] and Meltdown need different defenses. Specifically mitigating only one of them will leave the security of the entire system at risk. We expect that Meltdown and Spectre open a new field of research to investigate in what extent performance optimizations change the microarchitectural state, how this state can be translated into an architectural state, and how such attacks can be prevented.
即使meltdown被修复了,spectre[ 19 ]仍然是一个问题。Spectre和meltdown需要不同的防御策略。只是解决其中一个并不能解决整个系统的安全问题。我们期待meltdown和spectre可以打开一个新的研究领域,让大家一起探讨CPU设计的相关问题,包括改变微架构的状态如何可以优化CPU性能,微架构状态如何转化为CPU体系结构状态,以及如何阻止这样的攻击。
9.结论
In this paper, we presented Meltdown, a novel softwarebased side-channel attack exploiting out-of-order execution on modern processors to read arbitrary kernel- and physical-memory locations from an unprivileged user space program. Without requiring any software vulnerability and independent of the operating system, Meltdown enables an adversary to read sensitive data of other processes or virtual machines in the cloud with up to 503KB/s, affecting millions of devices. We showed that the countermeasure KAISER [8], originally proposed to protect from side-channel attacks against KASLR, inadvertently impedes Meltdown as well. We stress that KAISER needs to be deployed on every operating system as a short-term workaround, until Meltdown is fixed in hardware, to prevent large-scale exploitation of Meltdown.
在本文中,我们描述了一个新型的CPU漏洞meltdown,一种利用现代处理器上的乱序执行特性,通过侧信道攻击读取任意内核地址和物理内存数据的方法。不需要利用软件漏洞,也和具体操作系统无关,利用Meltdown漏洞,普通用户空间程序可以以503KB/s的速度读其他进程或虚拟机的敏感数据,这影响了数以百万计的设备。我们发现针对meltdown的对策是KAISER [ 8 ],KAISER最初是为了防止侧信道攻击KASLR而引入的,但是无意中也可以防止meltdown漏洞。我们建议:一个短期的解决办法是在每一个操作系统上都部署KAISER,直到解决meltdown issue的硬件出现。
致谢
We would like to thank Anders Fogh for fruitful discussions at BlackHat USA 2016 and BlackHat Europe 2016, which ultimately led to the discovery of Meltdown. Fogh [5] already suspected that it might be possible to abuse speculative execution in order to read kernel memory in user mode but his experiments were not successful. We would also like to thank Jann Horn for comments on an early draft. Jann disclosed the issue to Intel in June. The subsequent activity around the KAISER patch was the reason we started investigating this issue. Furthermore, we would like Intel, ARM, Qualcomm, and Microsoft for feedback on an early draft.
我们感谢Anders Fogh在BlackHat USA 2016和BlackHat Europe 2016上富有成果的讨论,这些讨论最终导致meltdown的发现。Anders Fogh [ 5 ]已经怀疑利用推测执行可以在用户模式下读取内核数据,但他的实验并不成功。我们也要感谢Jann Horn对早期草稿的意见。Jann Horn在6月份向Intel透漏了这个问题。随后围绕KAISER补丁的后续活动也使得我们开始调查这个问题。此外,我们也欣赏英特尔、ARM、高通和微软在早期草案阶段给予的反馈。
We would also like to thank Intel for awarding us with a bug bounty for the responsible disclosure process, and their professional handling of this issue through communicating a clear timeline and connecting all involved researchers. Furthermore, we would also thank ARM for their fast response upon disclosing the issue.
我们也要感谢英特尔公司,在发现meltdown漏洞之后对我们进行了奖励,并且负责的披露整个过程,感谢他们专业的处理了这个问题(给出一个明确的时间表进行充分沟通,并联系了所有相关的研究人员)。此外,我们还感谢ARM在披露问题时的快速反应。
This work was supported in part by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 681402).
欧洲研究委员会(ERC)根据欧盟Horizon 2020科研创新计划(编号:681402)对本项工作有一定的支持。
参考文献:
[1] BENGER, N., VAN DE POL, J., SMART, N. P., AND YAROM, Y. “Ooh Aah… Just a Little Bit”: A small amount of side channel can go a long way. In CHES’14 (2014).
[2] CHENG, C.-C. The schemes and performances of dynamic branch predictors. Berkeley Wireless Research Center, Tech. Rep (2000).
[3] DEVIES, A. M. AMD Takes Computing to a New Horizon with RyzenTMProcessors, 2016.
[4] EDGE, J. Kernel address space layout randomization, 2013.
[5] FOGH, A. Negative Result: Reading Kernel Memory From User Mode, 2017.
[6] GRAS, B., RAZAVI, K., BOSMAN, E., BOS, H., AND GIUFFRIDA, C. ASLR on the Line: Practical Cache Attacks on the MMU. In NDSS (2017).
[7] GRUSS, D., LETTNER, J., SCHUSTER, F., OHRIMENKO, O., HALLER, I., AND COSTA, M. Strong and Efficient Cache Side-Channel Protection using Hardware Transactional Memory. In USENIX Security Symposium (2017).
[8] GRUSS, D., LIPP, M., SCHWARZ, M., FELLNER, R., MAURICE, C., AND MANGARD, S. KASLR is Dead: Long Live KASLR. In International Symposium on Engineering Secure Software and Systems (2017), Springer, pp. 161–176.
[9] GRUSS, D., MAURICE, C., FOGH, A., LIPP, M., AND MANGARD, S. Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR. In CCS (2016).
[10] GRUSS, D., MAURICE, C., WAGNER, K., AND MANGARD, S. Flush+Flush: A Fast and Stealthy Cache Attack. In DIMVA (2016).
[11] GRUSS, D., SPREITZER, R., AND MANGARD, S. Cache Template Attacks: Automating Attacks on Inclusive Last-Level Caches. In USENIX Security Symposium (2015).
[12] HENNESSY, J. L., AND PATTERSON, D. A. Computer architecture: a quantitative approach. Elsevier, 2011.
[13] HUND, R., WILLEMS, C., AND HOLZ, T. Practical Timing Side Channel Attacks against Kernel Space ASLR. In S&P (2013).
[14] INTEL. IntelR 64 and IA-32 Architectures Optimization Reference Manual, 2014.
[15] IONESCU, A. Windows 17035 Kernel ASLR/VA Isolation In Practice (like Linux KAISER)., 2017.
[16] IRAZOQUI, G., INCI, M. S., EISENBARTH, T., AND SUNAR, B. Wait a minute! A fast, Cross-VM attack on AES. In RAID’14 (2014).
[17] JANG, Y., LEE, S., AND KIM, T. Breaking Kernel Address Space Layout Randomization with Intel TSX. In CCS (2016).
[18] JIM´E NEZ, D. A., AND LIN, C. Dynamic branch prediction with perceptrons. In High-Performance Computer Architecture, 2001. HPCA. The Seventh International Symposium on (2001), IEEE, pp. 197–206.
[19] KOCHER, P., GENKIN, D., GRUSS, D., HAAS, W., HAMBURG, M., LIPP, M., MANGARD, S., PRESCHER, T., SCHWARZ, M., AND YAROM, Y. Spectre Attacks: Exploiting Speculative Execution.
[20] KOCHER, P. C. Timing Attacks on Implementations of Diffe- Hellman, RSA, DSS, and Other Systems. In CRYPTO (1996).
[21] LEE, B., MALISHEVSKY, A., BECK, D., SCHMID, A., AND LANDRY, E. Dynamic branch prediction. Oregon State University.
[22] LEVIN, J. Mac OS X and IOS Internals: To the Apple’s Core John Wiley & Sons, 2012.
[23] LIPP, M., GRUSS, D., SPREITZER, R., MAURICE, C., AND MANGARD, S. ARMageddon: Cache Attacks on Mobile Devices. In USENIX Security Symposium (2016).
[24] LIU, F., YAROM, Y., GE, Q., HEISER, G., AND LEE, R. B. Last-Level Cache Side-Channel Attacks are Practical. In IEEE Symposium on Security and Privacy – SP (2015), IEEE Computer Society, pp. 605–622.
[25] LWN. The current state of kernel page-table isolation, Dec. 2017.
[26] MAURICE, C., WEBER, M., SCHWARZ, M., GINER, L., GRUSS, D., ALBERTO BOANO, C., MANGARD, S., AND R¨OMER, K. Hello from the Other Side: SSH over Robust Cache Covert Channels in the Cloud. In NDSS (2017).
[27] MOLNAR, I. x86: Enable KASLR by default, 2017.
[28] OSVIK, D. A., SHAMIR, A., AND TROMER, E. Cache Attacks and Countermeasures: the Case of AES. In CT-RSA (2006).
[29] PERCIVAL, C. Cache missing for fun and profit. In Proceedings of BSDCan (2005).
[30] PHORONIX. Linux 4.12 To Enable KASLR By Default, 2017.
[31] SCHWARZ, M., LIPP, M., GRUSS, D., WEISER, S., MAURICE, C., SPREITZER, R., AND MANGARD, S. KeyDrown: Eliminating Software-Based Keystroke Timing Side-Channel Attacks. In NDSS’18 (2018).
[32] TERAN, E., WANG, Z., AND JIM´ENEZ, D. A. Perceptron learning for reuse prediction. In Microarchitecture (MICRO), 2016 49th Annual IEEE/ACM International Symposium on (2016), IEEE, pp. 1–12.
[33] TOMASULO, R. M. An efficient algorithm for exploiting multiple arithmetic units. IBM Journal of research and Development 11, 1 (1967), 25–33.
[34] VINTAN, L. N., AND IRIDON, M. Towards a high performance neural branch predictor. In Neural Networks, 1999. IJCNN’99. International Joint Conference on (1999), vol. 2, IEEE, pp. 868–873.
[35] YAROM, Y., AND FALKNER, K. Flush+Reload: a High Resolution, Low Noise, L3 Cache Side-Channel Attack. In USENIX Security Symposium (2014).
[36] YEH, T.-Y., AND PATT, Y. N. Two-level adaptive training branch prediction. In Proceedings of the 24th annual international symposium on Microarchitecture (1991), ACM, pp. 51–61.
[37] ZHANG, Y., JUELS, A., REITER, M. K., AND RISTENPART, T. Cross-Tenant Side-Channel Attacks in PaaS Clouds. In CCS’14 (2014).