电商营销场景的RocketMQ实战01-RocketMQ原理
架构图
Broker主从架构与集群模式
RocketMQ原理深入剖析
Broker主从架构原理
HAConnection与HAClient
Broker基于raft协议的主从架构
Consumer运行原理

基础知识
001_RocketMQ架构设计与运行流程分析
RocketMQ这一块,非常关键的一个重要的技术,面试的时候也是非常的高频
建议的学习顺序分为三块:
1、儒猿技术窝里的付费的专栏《从0带你成为消息中间件实战高手》,几十块钱,rocketmq整体的基本原理,高阶的玩法以及一些案例的实践,都讲了一下,用在项目里的时候可能出一些什么问题,如何解决;
2、rocketmq内核原理,会把rocketmq内核级的深入的源码讲解一遍,让大家站在第一点的基础之上,可以对rocketmq有一个技术深度的理解和掌握;
3、会给大家去讲解电商场景下的一些基于rocketmq实战案例,包括实战代码,生产环境下如何对rocketmq进行每秒上10w并发的大压力的生产经验和优化
4、rocketmq的源码:不在跳槽营的范围之内,儒猿有自己的高阶课的体系,架构级的一些课程,本身来说是在儒猿高阶的课程里
002_NameServer是如何管理Broker集群的?
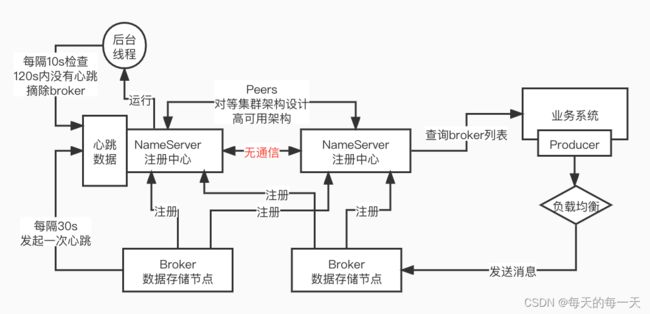
为什么各个Namesrv之间不通信,为什么设计上要做这样的取舍?保证Namesrv功能的单一、简单,不需要维持各个Namesrv之间的peer to peer,也就是不需要强制维持各个Namesrv之间数据强一致。把压力给到broker端去,就算两台Namesrv之间数据不一致,表现出来的效果也是下层不同broker受到的读写压力不一样
Eureka之间,是互相通信,保证数据一致的,这其实,就是一种设计上的取舍,无所谓好坏
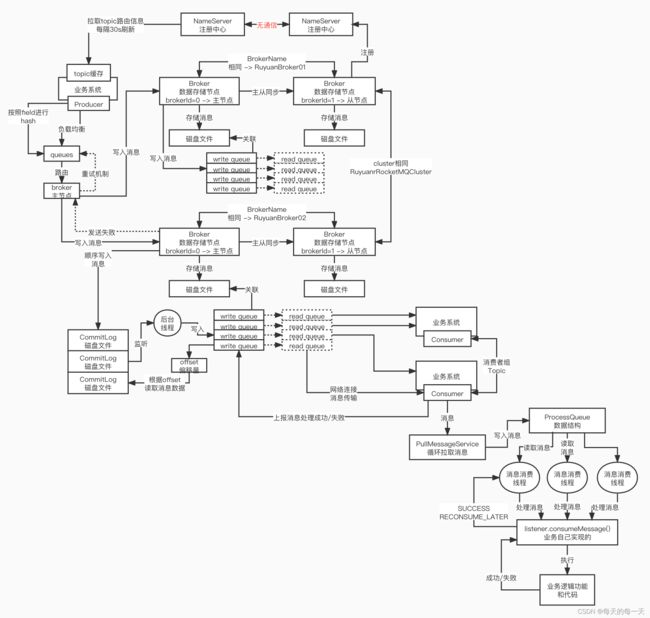
003_Broker主从架构与集群模式原理分析
broker主从,broker集群,大家一定要把这些概念理清楚,才能深入理解nameserver的内核的原理
一个broker cluster集群,会有多套broker主从
004_基于 Topic 队列机制实现的数据分片架构
注意理解,RocketMQ是如何实现的数据分片治理
消息中间件,有一个关键的数据模型和概念Topic,它是逻辑上的一个大的数据集合,逻辑概
念不是物理概念,要往一个 Topic 里写入消息,Topic 是虚的概念,底下实的概念,其实是 broker,但是对我们的业务系统来说,我们在写代码的时候,是没有 broker的概念在里面,只有 topic 的概念,topic -> broker 之间需要有一个关联,虚到实
消息数据分布式存储
数据分片概念,producer 写出来的消息会分散在很多台 broker 服务器上,每台 broker 服务器上存储的消息数据,都是一个shard数据分片
此时,引入一个RocketMQ 里的很关键的概念,topic -> 多个 queue(逻辑上的概念,映射到物理
层面去了,每个 queue 可以认为就是一台 broker 服务器上的一个磁盘数据,已经可以初步的
做一个映射关系了)
一个topic 在各个 broker 分组里的 queue 是如何分布的呢?
默认情况下,一个 topic 你创建之后,会在每个 broker 分组里,搞 4 个 write queue,4 个 read queue
005_NameServer 内存中核心数据模型分析
// 表示有RuyuanBroker01, RuyuanBroker02,两套主从
clusterAddrTable: {
RuyuanRocketMQCluster: [RuyuanBroker01, RuyuanBroker02]
}
brokerAddrTable: [{
RuyuanBroker01: {
cluster: RuyuanRocketMQCluster,
brokerAddrs: [0: xx.xx.xx.xx:8888, 1: xx.xx.xx.xx:8889]
}
},{
RuyuanBroker02: {
cluster: RuyuanRocketMQCluster,
brokerAddrs: [0: xx.xx.xx.xx:8888, 1: xx.xx.xx.xx:8889]
}
}]
brokerLiveTable: {
xx.xx.xx.xx:8888: {
lastUpdateTimestamp: 242342341,
haServerAddr: xx.xx.xx.xx:8889
},
xx.xx.xx.xx:8889: {
lastUpdateTimestamp: 242342341,
haServerAddr: xx.xx.xx.xx:xxx
}
}
topicQueueTable: {
RuyuanTopic: {
{
brokerName: RuyuanBroker01,
readQueueNums: 4
writeQueueNums: 4
},
{
brokerName: RuyuanBroker02,
readQueueNums: 4
writeQueueNums: 4
}
}
}
006_Producer 内核级发送消息机制分析
1、 消息是如何发送到 broker去的
2、 如果说消息要是发送失败了,此时会如何处理
3、 发送消息的时候,有哪些比较高阶的特性可以使用,按照 key hash,orderid 相同的消息,orderid=001,都进入到一个 queue 里去,以保证他们的顺序性
发送消息,肯定是指定一个topic ,往topic里去进行一个发送,RuyuanTopic ,send message,把一个消息发送到我们的 topic 里去:首先需要获取该topic他有哪些 queue,这些 queue 分布在哪些 broker 上
生产者进行消息发送时
先从生产者本地关于topic信息的缓存中,通过比如轮询的负载均衡算法,在topicQueueTable中选择出一个queue,然后根据选择出来的queue对应的brokerName,从brokerAddrTable中找出该brokerName对应的brokerAddrs列表中brokerId为0的主节点,然后对着这个主节点进行真正的网络通信发送消息的过程
007_ 基于 Producer内核分析消息hash分发原理
在各个broker上,一个topic是有很多的queue,默认情况下,往一个topic里写入的数据,会均匀分散到各个broker的各个queue里去
同一个queue就代表一个队列,所以消息进入到同一个queue里去的时候,在同一个queue里的消息是有顺序的。 但是不同的queue之间的消息是没有顺序的,如果说有一些场景让某一类数据有一定的特殊顺序性,比如orderid,orderid=11001,对应的多条消息可以有顺序,唯一的选择就是让 orderid=11001的所有消息都进入同一个queue, 同一个队列,保证他们在同一个队列里是有顺序的
用这个字段值的hash值,对queue的数量进行取模,就可以确保同一个字段值 -> 同一个hash值 -> 取模出来同一个queue 序号 -> 进入同一个 queue -> 保证有顺 今序
topic queue -> data shard分片
发送高可用
broker故障延迟感知:因为nameserver在发现某个broker没有更新心跳挂了以后,不会主动的通知各个producer说某个broker挂了。只有producer自己每30s主动拉取刷新一次路由缓存,才能够感知到某个broker挂了,而在这期间,producer发送到这台broker的消息可能会失败,但是失败后可以有故障避退,和重试发送的机制来保证整个的发送过程高可用
自动重试机制:
故障退避机制:
nameserver在发现某个broker挂了以后,不会主动的通知各个producer,因为这样会使得nameserver的实现变得很复杂,每次注册表变化还得通知各个producer,但zk是这样实现的
此时的消息发送的负载均衡机制,就从轮询,变成了hash取模的负载均衡机制
其实,rocketmq的多个broker就已经组成了一个分布式存储系统了,客户端发送过来的消息,通过一定的负载均衡机制,打散存储在各个broker的queue之上
008_Broker 如何实现高并发消息数据写入?
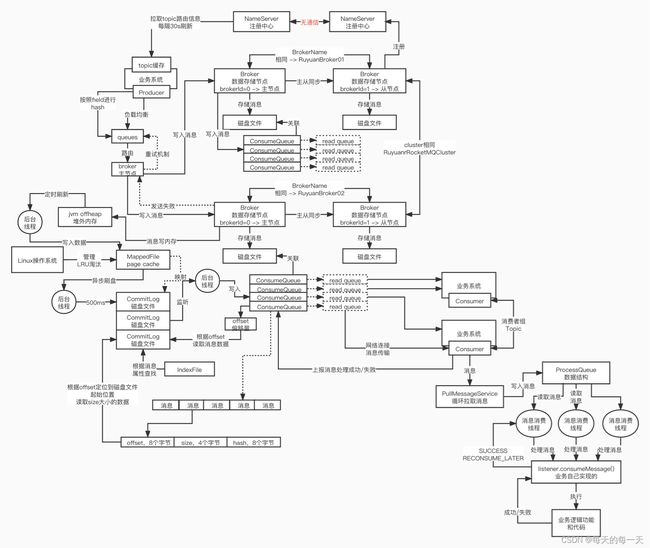
写入消息有两种方式,一种随机写,一种顺序写, 写哪里 ( 内存、磁盘 )
一般来说,如果说你要持久化保存我们的消息数据的话,消息必须是要落地到磁盘里去的, 落地到内存里去,避免内存里的dsfdsdf数据丢失,此时就需要设计一套避免内存里数据不丢失的一套机制,这套机制一般都是基于WAL(write ahead log,这种也是需要写磁盘的 )
到底是用随机写,顺序写
随机写,磁盘文件里面的数据格式是你自定义的,每次写入数据,都是需要找到磁盘文件里的某个位置,在那个位置里插入你最新的数据, word文件肯定是放在我笔记本电脑的磁盘里的, 磁盘文件每次写入数据,都是在一个文件末尾去进行追加就可以了,绝对不会随机在文件里寻址,找到一个中间的位置插入数据, 而是就是不停的对文件进行数据追加,这种就叫做顺序写
如果要是不把数据写在磁盘里,而是写在内存里, 顺序写和随机写,意思是差不多的, 内存里随机写,内存也是有地址空间 ,就是在内存里随机的内存地址的寻址,再去插入数据,一块连续 的内存空间里,顺序的不停追加写入数据,避免了随机寻址 在内存里随机写数据,性能当然是非常高的了
随机写磁盘文件 -> 几十 ms 、 几百 ms,顺序写磁盘文件 = 约等于在内存里随机写数据 -> 毫秒级
Commitlog默认是1GB,每个文件不要过大,过大了以后对后续的数据读写性能都不太好,所以写 满 了一个文件就切换下一个文件就可以了
009_RocketMQ读写队列的运作原理分析
设计write queue和read queue概念的原因?
主要是为了让producer发送消息是路由到哪些队列,和consumer消费时消费哪个队列进行分离,从而为了进行队列的扩容和缩容的方便
write queue是一个实的,是有磁盘文件一一对应的和
read queue是一个虚的,一般一个read queue都会绑定一个write queue,从而方便consumer通过read queue实际消费到write queue中的数据
010_Consumer 内核级消息拉取原理分析
rocketmq写concumser代码的时候,一般都是写一个consumer listener 回调监听函数,让
consumer在拉取消费到消息之后,把消息回调来调用我们自己写的回调监听函数,在函数里进行消息的处理就可以了
老师有一个问题: 当我们不使用rocketmq在消费端自带的线程池,而使用我们自定义的业务线程池来消费消息, 那当我们把在ComsumerListener#consumeMessage()方法中,把消息一丢入自己定义的业务线程池,就相当于返回了Consume_Success,那消费进度就提交了,此时如果自定义的消费线程池出了问题,当前这条消息,不就丢失了吗? 这个问题一般有什么解决方案呢?
管理员(2023-9-20): 同学你好,可以在消费者端,在消息消费之前,将消息本地存储起来,然后将消息提交给自定义的业务线程池。如果自定义线程池出现问题,你可以实现一个重试机制,定期检查未确认的消息并重新处理它们
011_CommitLog和ConsumeQueue物理存储格式
consumer读取消息的场景,consumer 正常来说,都是按照顺序一条消息一条消息的去进行读取, 一个 topic 是可以给多个 consumer group 去进行消费的
比如,RuyuanTopic这个topic ( 8 个 queue ) -> 业务系统 A ( 部署了 3 台机器, 这三台机器组成一个consumer group ,每台机器就是一个 consumer ) ,业务系统B (部署了 5 台机器组成另一个consumer group, 每台机器就是一个 consumer )
不同的 consumer group 对一个 queue , 消费的 进度是不一样的, 有的consumer group对这个queue可能已经消费了 500 个消息了,有的 consumer group可能才消费了100 个消息
假设这个queue 里已经有了 1 000 个消息了, 但是有的 consumer group 才消费到了 1 00 个消息, 此时下一个消息的消费是从 101 个消息继续 往后去进行消费的,broker在接收到consumer发送过来的拉取offset从101开始的消息的请求时,需要能快速的定位到第101条消息
一个consume queue是一个磁盘上的文件,甚至是多个文件,如果想定位到第101条消息,此时就涉及到随机磁盘读 ,也就是说我们希望能够随时 根据我要消费的消息的序号,快速定位到那条消息在磁盘文件里的位置,再定位到那个位置,从那个位置去进行一个读取需求
针对这样的一个读取的需求,我们的 consume queue 磁盘文件应该如何设计,才能支持我们高效的磁盘位置定位以及读取呢 ?
012_ConsumeQueue 的高性能物理存储设计
ConsumeQueue对应的物理磁盘目录层级结构为:~/topicName/queueId/多个磁盘文件,
比如,~/RuyuanTopic/0/ 多个磁盘文件,每个磁 盘文件里都会存储一条一条消息的索引条目,每条索引条目在磁盘文件里存储的是什么东西? commitlog 偏移量 8 个字节,大小 4 个字节,tag 哈希码8 个字节,每条消息在 ConsumeQueue 磁 盘文件里存储的大小是定长的, 20 个字节一条条目数据,固定下来每个 ConsumeQueue 里面大概是 30 万个条目,每个 ConsumeQueue 的磁盘文件大概就是 5.72MB 大小
013_ConsumeQueue 如何实现高性能消息读的?
某一个consumer group来读取的消息,每条消息都是有一个自己在queue中的逻辑offset ,逻辑 offset可以大致认是queue里的第几条消息
consumer group里的一个consumer是负责读取某个queue的消息的,此时他知道说要读取的是这个queue 里的第几个消息, 比如说要读取的是第 150 个消息,应该先是根据消息的逻辑上的 offset,根据他是queue里的第几个消息, 先去定位到他是属于该 ConsumeQueue 的哪一个磁盘文件, 就可以 150 * 20 个字 节 , ( 1 - 1 ) * 20 个字 节 =0 字 节 (起始位置), 从 0 字 节 开始 读取 20 个字 节,就可以把第一个消息读取出来了,( 150 – 1 ) * 20 个字 节 = 算出来一个字节 数,就是这消息的起始位置,对于这个起始位置是真实的磁盘中的物理位置,
物理位置是根据字节计算出来的,从那个起始位置开始读,连续读20个字节,就可以把第150 个消息索引条目给读取出来
这种方式,其实是一种极为高效率,高性能的 consume queue 读取方式,根本就不需要进行遍 历读取磁盘文件里一条一条的消息来查找,不需要遍历 ,有点类似于跟数组 [index] , 直接定位到一个位置,然后从那个位置把数据读取出来一 样的效果 (不需要像链表一样一直遍历下去才知道当前消息是queue中的第几条消息,而是类似数据的定位方式,这使得consumer带着消息逻辑偏移来broker拉取消息时,broker能通过这种快速定位的方式,快速的找到该条消息,这一点是非常重要的)
014_CommitLog 基于内存的高并发写入优化
1 、 Broker 写入性能优化
( 1 ) CommitLog在写入的时候,是基于磁盘顺 序写来提升性能的
( 2 ) ConsumeQueue是基于异步转发写入机制来提升一个性能的
2 、 Broker读取性能优化
( 1 ) ConsumeQueue 基于定长消息索引条目 + 定长文件, 消息索引条目的一次定位 + 读取
( 2 ) CommitLog 是基于文件名 = 第一条消息的 总物理偏移量, 基于消息物理偏移量可以快速的定位CommitLog文件以及其中的物理起始位置, 一次定位 + 读取
无论是写入还是读取,此时此刻最大的问题,就是还是基于物理磁盘文件在做这个事情,能否基于内存进一步的去提升我们的整体的写入性能和读取的性能
rocketmq确实就是基于内存来提升了commitlog 他的写入性能,如果不基于内存映射机制,哪怕是仅仅使用磁盘顺序写入,写入性能也不是最优的
基于MappedFile,mapping文件内存映射机制, 实现了一个把你的消息数据写入,由直接写入磁盘,变成写入到内存里,然后由操作系统的异步刷磁盘线程,把内存里的消息,通过磁盘顺序写来刷到磁盘里去
此时的消息写入,就既用到了内存映射,又用到了磁盘顺序写
关于PageCache与内存映射
PageCache
首先要认识到一点,因为磁盘和内存之间速率的差异,以及程序的局部性原理,linux引入了PageCache的概念,所以,就算是传统的普通IO模式中,依然是有PageCache的存在的,传统IO下,数据也是由缺页中断调起,先从磁盘进入PageCache,然后用户程序空间再通过read()系统调用,把数据从PageCache复制到用户空间中来
内存映射
核心的一点是,是磁盘文件对应的PageCache与用户虚拟地址空间之间的映射,内存映射指的不是PageCache与磁盘文件之间的映射。PageCache与磁盘文件之间的映射,是linux在引入PageCache这个概念时,就自己帮我们做好了
当磁盘文件对应的PageCache与用户虚拟地址空间完成了一对一映射后,程序员通过直接操作虚拟地址空间,就实现了操作磁盘文件对应的PageCache的效果。原来的传统io模式,还需要把PageCache中的内容拷贝到用户空间,完成修改后,再通过系统调用write()来把修改的内容写回PageCache
总结一下就是,有了内存映射后,少了一次PageCache拷贝到用户空间的操作,程序员可以在用户虚拟地址空间来操作虚拟地址,来达到直接操作内存中的PageCache的效果
如果后台异步线程在将commitlog写入到ConsumeQueue的时候宕机了,是不是要记录一下已经写入ConsumeQueue队列的最大commitlog偏移量,然后在在系统恢复的时候才能将没有写完的commitlog继续异步写入ConsumeQueue队列?
管理员(2022-9-24): 是的,是会记录commitlog maxoffset
015_Broker数据丢失场景以及解决方案
1 、 Broker 写入性能 优 化
( 1 ) CommitLog 写入:磁 盘 文件 顺 序写 + 磁 盘 文件 ->page cache 内存映射 = 直接就是 顺 序写内存,
如果希望数据是 0 丢 失的, 只能改成同步刷盘 + 磁盘顺序写
如果希望牺牲一点数据丢失性, 换取高吞吐高性能,保持默认的异步刷盘就可以了
( 2 ) ConsumeQueue 是异步写入的, 这块 性能影响就不大了
第一种情况, Broker ( rocketmq 就是用 java 开 发出来的中间件系 统 , 启 动 之后就是一个 jvm 进 程), Broker 作为 一个 jvm 进 程, 突然崩溃 掉了, 仅仅只是说是一个 jvm 进程没了而已, page cache 里的数据是 os 管理的, 概率比较高一些
第二种情况, Broker jvm 进程所在的服务器,服 务器自己本身故障宕机了,os 、虚拟机、物理机、硬件层面的故障,此时就会导致你之前写入到 page cache 里的数据丢失, 这种情况发生的概率很低很低很低,但不是说不会发生机器故障, 也是有的,小概率,极端情况下数据丢失一定要考虑到位
016_Page Cache 内存高并发读写问题分析
牺牲一丢丢的数据可能丢失的问题 ,换来的是写内存,提升性能和吞吐量
page cache 内存数据,可能会在高并发高吞吐的 读写竞争之下,因为异步刷盘场景下,producer刚刚才把大量的消息写入到PageCache,又立马有大量的消息读请求,此时的消费者会直接从PageCache中读取消息,不用去磁盘读
此时,就会出现一个经典的问题,rocketmq里异常, broker busy ,broker 过于繁忙,导致你的一些操作,可能会阻塞住或执行失败。因为,此时os的page cache数据,被竞争争用的太频繁了, 太激烈了,高并发和高吞吐的场景之下的
如何解决上述的PageCache被竞争争用太频繁的问题:transientStorePool机制
017_基于jvm offheap 的内存读写分离机制
transientStorePoolEnabled 机制, 瞬时存储池启用, 机制, 你可以 选择 去开启他, 如果你要真 是 压 力大到了
老师,有个疑问:rocketmq也采用的这样的双缓冲的刷盘机制,但是,是采用的一个单独的后台线程,定时每10ms刷一次缓冲中的数据到磁盘,而不是像我们这里,是随机的某一个客户端写入线程来执行真正的刷盘动作。hadoop的刷盘逻辑,可能会造成大量写入线程的周期性卡顿,而rocketmq的实现方式,好像就不存在这个问题?
管理员(23小时前): 1、Hadoop的随机客户端写入线程刷盘机制: Hadoop采用这种机制,在写入数据时由随机的客户端写入线程执行实际的刷盘动作,将数据刷入磁盘。 这种方式的优点是可以充分利用系统的并行性,不会受到单一后台线程的限制,可以实现高并发写入。 缺点是可能会出现周期性的卡顿,尤其当有大量写入线程在同一时间刷盘时,可能会导致短暂的写入延迟。 2、RocketMQ的后台线程定时刷盘机制: RocketMQ采用一个单独的后台线程定时刷盘,将缓冲中的数据定期刷入磁盘,通常是每隔一定时间(如10ms)执行一次刷盘操作。 这种方式的优点是可以避免周期性卡顿,因为刷盘动作是由单独的后台线程负责,不会受到其他写入线程的影响。 缺点是在刷盘时间间隔内,数据可能会在内存中暂存,有一定的数据丢失风险。 针对同学你的疑问,为什么Hadoop的刷盘逻辑可能会造成大量写入线程的周期性卡顿,而RocketMQ的实现方式不存在这个问题?? 并发度与刷盘频率的平衡: Hadoop的随机客户端写入线程刷盘机制可能会造成卡顿,主要是因为并发度较高时,多个写入线程同时刷盘会导致竞争和延迟。在Hadoop中,需要平衡并发度和刷盘频率,避免过多的写入线程同时刷盘。 业务特点和数据丢失风险: RocketMQ选择定时刷盘的方式可能基于其业务特点和对数据丢失的容忍程度。在消息中间件场景下,短暂的数据暂存可能是可以接受的,而定期刷盘可以降低系统的整体压力。
出现了我 刚 才所 说 的那个 问题 之后,就可以实现一个内存级别 的 读 写分离模式
一般来说 , 在一个服 务 器上部署了一个系 统 之后, 这个系统作为一个 jvm 进 程会运行再操 作系 统 上, 内存一般来说分成三种,一种 jvm heap 内存, jvm 管理堆内存,第二种是 offheap 内存, jvm 堆外的内存, 第三种就是 page cache 是 os 管理的
开启这个机制后,就变成了一个“两级缓存”的机制,第一级缓存是堆外内存,第二级缓存就是PageCache。此时,消息是先写入堆外内存,就返回消息写入成功了,然后有后台线程每隔一段时间将堆外内存中的消息一次性刷到PageCache中,然后进入PageCache中的脏页就由内核自己的后台线程,默认每隔500ms刷一次脏页到磁盘中去
此时,就实现了一种读写分离的效果:
写是先写入堆外内存,然后隔段时间统一刷入PageCache一次,就降低了针对PageCache的频繁的写压力,将写压力转给了堆外内存
读是直接去读PageCache,因为PageCache没有了频繁的写压力,所以此时去频繁的读也不会产生激烈的读写竞争
018_jvm offheap+page cache 数据丢失问题
系统设计里,凡事皆有利弊,没有什么事情是十全十美的,不可能的
为了解决一个问题,往往会引入一个新的问题 , 开发一个系统 ,遇到了一个技术问题,为了解决他,引入了一个新的技术 ,可是新的技术 引入了之后,他自己本身又会产生新的问题 ,所以这个就是一个非常的 问题
为了解决高并发高吞吐之下对 page cache 竞 争 读写导致的问题,引入了 jvm offheap 做了两 级缓 存, 实现了内存级别的读写分离, 解决掉了 对 一 块 内存空间的写和读,竞争的问题,搞定了 数据丢失的风险会大大的提高
数据丢失,主要是分为两种情况:
1 、 broker jvm 进程,崩溃宕机, jvm 进程可能会意外退出,或者自己正常的关闭 broker jvm 进 程,再重新启动和打开他 ,此时 jvm offheap中的数据也会丢失
2 、 broker 所在的服务器,可能会有一个崩溃的 问题,此时jvm offheap和PageCache中的数据都会丢失
没有一个技术方案是完美的,你只能去抓当前场 景里的主要矛盾是什么
你金融级的数据,数据绝对不能丢失的,你可能要牺牲性能和吞吐量,直接让你的数据每一次写入都直接刷盘
大部分的普通情况,数据可以丢一下下,丢一点数据,是在服务器宕机极端场景下,才会丢几百毫秒的数据,这个时候就保持默认就可以了,写 page cache ,同时异步的刷 盘 ;
默认情况下,出现了高并发竞争 page cache 的问题时,开启高阶机制 jvm offheap ,容忍一定的 jvm 崩溃丢失一点数据,核心原理就是,通过使用多级缓存的读写分离,来抗高并发读写和高吞吐
这个机制懂原理就好,实际中,一般不开启
019_ConsumeQueue 异步写入失败恢复机制
一次消息的真正写入成功,需要写入CommitLog和写入ConsumeQueue都成功。写入CommitLog和写入ConsumeQueue,是两个独立的步骤,两者之间是异步执行的
写入到MappingFile映射文件中的数据,只要linux系统不宕机,这部分数据迟早会通过linux的内核后台线程刷去磁盘CommitLog文件中,也就是说这部分数据,不会丢
写入到ConsumeQueue的数据则不同,有另外的一个负责写ConsumeQueue的后台线程,当监听到CommitLog文件有新消息写入时,则会将该条消息在CommitLog文件中的全局物理偏移、消息大小size、还有消息的哈希码,三个作为一个消息索引条目,写入ConsumeQueue
场景一
消息写入CommitLog文件成功后,后台线程还没没监听到这条消息,linux服务器就宕机了,此后让linux服务器重启以后,后台线程仍然可以去监听写入CommitLog文件但还没写入ConsumeQueue的消息,继续后续写入动作
场景二
消息写入CommitLog文件成功后,且后台线程监听到这条消息,准备开始异步写入ConsumeQueue时, linux服务器就宕机了,此后让linux服务器重启以后,后台线程有一套比对机制,比对写入CommitLog文件但还没写入ConsumeQueue的消息,继续后续写入动作
至于这个比对机制,我还没在源码中见过,后续在看,这个很重要,数据异步双写的一致性兜底策略
总结一下就是,只要成功写入到CommitLog文件中的消息,都能保证成功写入ConsumeQueue中
020_Broker写入与读取流程性能优化总结
物理存储结构主要是为了优化写入和读取, 都是为了写入、存储 、 读取, 这三块去做一个设计的,写入尽可能高吞吐,高并发,如何让存储可以有效的进行数据结构组织服务于我们的写入和读取, 如何让高并发的读取可以有效的进行,broker主要要做到的一些事情
1 、 写入优化
( 1 ) 默认就是直接写入 os page cache 里, mappedfile 机制来实现的,把磁盘文件映射成一 块内存,写文件 = 写内存,就直接返回成功了,内存级顺序写入,亮点就是基于 os page cache 来写入数据, 如果 broker jvm 进程崩溃(高概率事件) 了,是不会导致os page cache 的数据丢失的,服务器崩溃的极端场景才会导致几百毫秒内写入的数据会丢失,一般来说不会发生
( 2 ) 对于 ConsumeQueue 和 IndexFile 写入, 是异步写入的,这个也是性能提升的一个点, 但是只要数据在 commit log 里没丢失,哪怕是异步写入没有成功,broker jvm 就崩也不能溃了, 但是broker jvm重启和恢复了,此也时基于 commit log 数据都可以恢复consume queue 的数据
2 、 存储结构
( 1 ) ConsumeQueue 存储结构是经过了极大的 优化设计的,物理存储结构设计,极 为 的精 巧的,每个消息在 ConsumeQueue 里存储的都是定 长的( 20 字 节 ) ,每个文件也是定长的是30w 个消息,定长则能很好的topic目录 -> 多个 queue目录 -> 多个磁盘文件,每个磁盘文件一 样 大的,都是5.72MB
( 2 ) CommitLog 他的物理存储结构也是精心 设计的,他也是每个文件默认就 1 GB , 满了以 后就写下一个文件, 文件名,就是每条消息在所有的 commitlog 里都有一个总的物理偏移量, 每 个文件的第一条消息他的总物理偏移量, 就是文件的名称, 每个 commitog 他的起始消息的总物理偏移量通过文件名就可以看出来了
3 、 读取优化
(1) 根据消息 逻辑 offset 偏移量 ( 类 似于 这 个queue 里的第几个消息),定位到你的 ConsumeQueue 的磁盘文件(比如第30w到60w个消息索引条目,就在第2个磁盘文件中),在磁盘文件里,就可以去根据你的逻辑上的偏移量, 就可以去计算出在ConsumeQueue 的磁盘文件中的物理偏移量, 通过这第一次定位,就找到这条消息索引条目, 通过条目就可以找到消息在 commitlog 里的全局物理偏移量, 通过全局物理偏移量再第二次定位,就可以把真正的消息读取出来了
(2) 高并发的对page cache 进行读写竞争的时候 broker busy, transientStorePool 机制, 开启之后,就会启用 jvm offheap 内存,内存级的读写分离
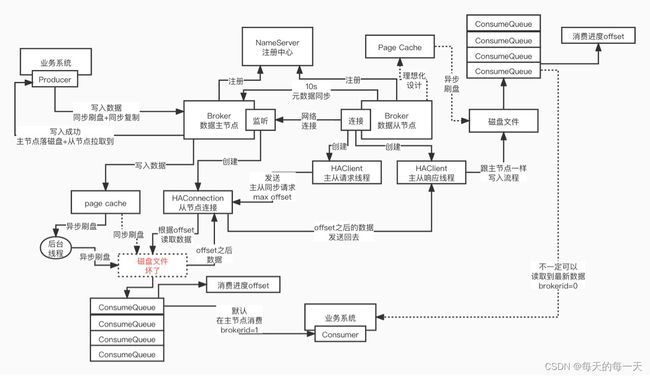
021_Broker基于Pull模式的主从复制原理
push 模式, pull 模式
push 模式 -> 我 们业务 系 统 的 producer 往 broker 主 节 点里写入数据之后, 直接由 broker 主 节 点主 动 的把数据 push 发 送到从 节 点里面去
pull 模式 -> producer 仅仅是往 broker 主节点里写入数据,此时主节点是不会主动的把数据推送到从节点里去,是等待从节点反过来发送 pull 拉取数据的请求,然后主节点收到了拉取数据的请求之后,才会把数据发送给从节点
022_Broker层面到底如何做到数据0丢失?
在这套主从同步机制之下,我们如何做到数据0 丢 失如果broker主节点改成同步刷盘机制之后, 每一次写入,必须把数据写入到物理磁盘的层面, 此时写入才会返回,broker jvm 进程崩溃 ,数据 100% 不会丢 ,broker 部署所在的服务器突然宕机了(断 电 ) ,此时数据 页也不会丢失了, 因 为数据在物理磁盘上,第三种极端中的极端中的多年难得一遇的场景,物理磁盘坏了 (没法恢复数据)
仅仅是依赖 broker 主节点同步刷盘 , 还是会存在物理磁盘损坏,导致数据丢失;主节点崩溃了以后, 此时 ,如果你的数据 还没来得及同步给从 节点, 此时主节点崩溃了,从节点还没同步到这 个数据,此时你从从节点里读取数据,是读不到的,这也是一个问题 ,短时间内,如果主节点没有恢复,从节点也是读不到数据的
此时,broker层面100%稳妥的办法,就是改成同步刷盘 + 同步复制,但是这种写入性能太差,一般不使用
023_数据0丢失与写入高并发的tradeoff
99% , 99.9% , 99.99% , 99.999% -> 无限的逼近与 100% , 无限的把 损 失的概率降低到接近 于 0% , 这是我们能做到的事情
反复的跟大家讲的,反复权衡tradeoff ,你要的到底是什么,你想要什么,你能失去什么,任何事情,技术上的事情,系统设计上的事情,没有1 00% 的完美,当你要解决一个问题的,引入了一堆的技术,此时连带引入对应的新的问题
如果你真想实现数据在 broker 层 面的 0 丢 失, 确实写入成功的数据几乎不会丢失 但是写入性能?写入吞吐量?狂跌不止,性能估 计 会 调 几个数量级, 一次消息写入 broker , 异步刷 盘 + 异步复制, 只要写入 page cache 就可以返回了, 几 ms 、 几十 ms -> 同步刷盘, 几十 ms 、 几百 ms + 同步复制, 等待从节点发送 pull 请 求, 物理磁盘读数据,通过网络把拉取数据返回,从节 点把数据写入磁盘,从节点下一次 pull 请求,快 则几百 ms,慢一两 s 都有这种可能
几百 ms 打底, 一两 s , 两三秒 s , 都有 这 种可能,吞吐量和并发就会咔咔掉, 单位时间里能 完成的发送消息的请求数量原来是每秒可以上万, 现在是每秒只能几百,1000 , 都有可能
金融级场景钱有关的,才要做到这么严苛, 一点 问题不能出
场景:生产者发送消息到broker,broker同步刷盘了,此时在等待从节点的拉取响应。如果此时从节点在没有拉到最新写入主节点的数据就挂了。那么此时broker如何响应给生产者呢?如果响应失败的话,实际上消息在主broker上已经写入了,还没有写入从节点而已,如果生产者重试,是否消息就会重复了?
管理员(2022-8-7): 首先要看rocketmq的架构是什么,现在都是raft高可用的架构方式,是主写点写完之后去同步其他follower节点,等待大多数节点响应后返回给client端;broker上有条消息,但是broker这条数据不是commit的是uncommit的状态,这块你可以看下raft写log的过程,uncommit的数据是无效的,消费者是消费不到的,响应失败后producer端需要自己重试来发送
024_RocketMQ 4.5.0 以前的读写分离模式
默认情况下,rocketmq 是不倾向于主动让你直接 长期进行读写分离的,而是倾向于写和读都是在主节点来进行的,从节点主要是用于进行数据复制和同步,实现热备份,万一主节点挂了,此时 作为一个备选,才会去从从节点那里读取数据
为什么像上述一样设计,下一讲会给大家来进行分析
如果说主节点过于繁忙,积压了大量的消息,处 理不过来了,写和读,积压的消息数量,超过了他本地内存的40% ,这是自己定的一个比例 -> 主 节点太繁忙了 -> 在你发起一次拉取消息请求之后,他会通知你下一次拉取消息的 broker id 是谁
如果又过了一段时间,从节点发现自己本地的消息积压量小于自己的物理内存30%,说明拉取很顺利很快速,此时,从节点又会给消费者拉取线程返回一个brokerId=0,也就是说让消费者又漂移回主节点进行消息拉取
025_RocketMQ为什么采取惰性读写分离模式?
读写分离,主从漂移模式。赛车一般是玩漂移,我们也是一个 专业 的技术术语, ip漂移,主从机器对外提供一个完整的服务,你在访问的时候, 有的时候访问主,有的时候访问从,此时主从之 间的给你访问的 ip 漂移, 一会儿漂移到主, 一会儿漂移到从
彻底的读写分离,对于从节点的数据读取,备用备选,什么时候会在从节点进行消费和读取呢, 如果说主节点过于繁忙了,积压的没消费的消息太多了,都占比达到了自己物理内存 的 40% 了, cpu 负载可能很高(大量的读写线程并发运行, 机器运行效率可能都降低了),来不及处理这么多的 请 求了
消费请求漂移到从节点去,出现了一个请求漂移
主节点如果崩溃了,毫无疑问的,只能从从节点去进行消费了
在从节点消费的非常好,消息的积压数量很快就下降到了从节点物理内存的30% 占比以内, 就说 明你此时消费一切良好,又会让你漂移回主节点去了,惰性读写分离,懒惰、不情愿的、不主动 的、偶尔的才会让你去从节点进行消费
rocketmq作为一个 mq,还算是支持了可以从从 节点去进行消费和读取,kafka 也是一个 mq , topic -> 不是很多queue 而是很多的partition , 不同的节点组成了 leader 和 follower 主从结构,去进行数据复制, 默认也是不会让你去从节点去 读取
MQ 作为一个特殊的中间件系统,他要维护你的每个 consumer对一个queue的消费进度
如果有一主三从的broker集群,如果消费者一会儿去主读,一会儿又去三个从里面各自读取一会儿,因为此时没有统一的一个消费进度管理的位置,消费进度都各自为政,就很不好办。像这种broker集群的消费进度,一定要维护到一个统一的地方,进行集中式的存储跟管理(突然想起zk就是一个元数据集中式存储与管理好组件)
一般,从会每隔10s把自己当前的消费进度等元数据信息同步给主一次,以便当发生了主从读写分离后,主能够同步的更新当前的消费进度
就是因为消费进度不好统一管理的问题,所以,RocketMQ没有选择一上来就主张读写分离
Broker高可用
026_Broker数据与服务是否都实现高可用了?
RocketMQ 4.5.0之前,主节点崩溃之后,是没有高可用的主从切换机制的,主从机制在 4.5.0 之前仅仅是用来进行热备份的,让主节点数据在从节 点也有一份,主节点崩了之后,这个时候就全靠 从节点提供有限的数据和服务了
服务的高可用,broker提供的服务就两个,一个是写、一个是 读 ,写数据,读数据。
从节点就是从节点,是不能写入数据的,只能作 为一个备胎一样的感觉,偶尔主节点实在是忙不 过来或者是挂掉的时候,从节点可以顶上
主从漂移 + 惰性读写分离机制, 如果主节点崩溃 了以后,producer 就会全部是写失败了, 但是consumer 任可以继续去找从节点进行消费,从节 点之前同步到了多少数据,就只能提供这些数据的继续消费行为
rocketmq 按照上面这一套实现原理, 实现broker的服务高可用了吗 ?数据和服务都没实现高可用
服务高可用,这块就只能提供有限的读,写是不行了, 不能写就导致没新的数据进来,已有的数据消费完了也就完了,读也只是有限的读;
数据高可用,数据可能有些最新数据都没来得及同步给从,从而从的数据也不是完整的,只能说 是大部分的数据不丢失而已,主从同步实现了热备份、热同步,主节点全崩的时候, 从节点保留了大部分的数据
rocketmq 在 4.5.0 之后,做一个最新的架构改造,主从同步 + 主从切 换 ( 高可用机制, 数据 和服务 , 都是高可用)
027_Broker 数据与服务高可用的理想化设计
rocketmq以前老版本的,单纯的主从复制,实现 了数据不丢,效果不是特别好,你的一个数据分片也就是一个broker集群,broker主节点挂掉了以后,从节点都没法接管主节点的工作
理想情况下,应该是一个什么样的设计呢?
主的数据写入后,先直接进page cache 就可以了,但是主从同步,如果你要实现主从数据强一致的同步。
如果采用 pull 模式,必然会导致主必 须去等待从过来 pull 拉取数据,时效性一般来说 比较差 。主从数据强一致,写入主节点,主节点直接进 page cache 就算成功了,到此为止,写内存速度还是很快的
此时最好是采取一个push的模式, 主直接把你的这条数据push 同步给从节点,此时客户端的写请求只要等待一次从节点的push成功就可以了 。对于从节点,同样也是采取了异步刷 盘的策略,从收到了一条消息之后,直接也是写入 page cahce 就可以返回,这时就说本次push 同步成功了
ps:
主从同步,同步调用从节点如果网络问题导致失败,主节点会返回生产者失败,当大多数节点不满足的时候,会告诉生产者失败
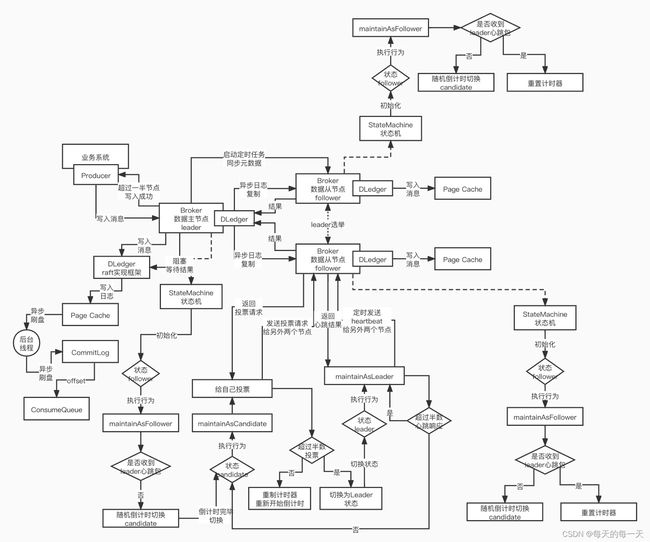
028_Broker基于raft协议的主从架构设计
Raft协议使用过半机制和选举周期来避免脑裂
Zab协议使用过半机制和全局唯一的Zxid来避免脑裂
场景:如果主有12345,5条消息,两台从,从1只有消息1234,从2只有消息125,这时主挂了,从1成为新的主,消费者此时找从1拿消息,不就拿不到消息5了吗? 主往从1同步消息3 4成功,同步消息5失败 主往从2同步消息 3 4失败,同步消息5成功
管理员(18分钟前): 同学你好,首先,RocketMQ 的主从架构是为了实现消息的高可用性和容错性而设计的。当主节点挂掉后,会从从节点中选举出新的主节点,确保消息服务的持续可用。然而,在主从切换的过程中,可能会出现消息同步不一致的情况,这取决于各个节点的同步进度和状态。 在同学你提到的情况中,主节点有消息 1-5,从节点1有消息 1-4,从节点2有消息 1、2、5。如果主节点挂掉,从节点1成为新的主节点,消费者此时从从节点1拉取消息,将只能拉取到消息 1-4,而无法获取消息 5。 解决这个问题的方法通常是依赖于 RocketMQ 的消息复制机制和同步策略: 消息复制机制: RocketMQ 默认的消息复制机制是支持多副本的。在这种情况下,消息被存储在多个节点上,确保了消息的冗余性和可靠性。当主节点切换时,新的主节点会尽力同步副本,使得各个副本最终保持一致。但是在切换过程中可能会存在少量的不一致性。 同步策略: RocketMQ 提供了同步策略来控制消息的同步行为。这些策略包括同步刷盘、同步主从等。你可以调整同步策略的参数,以权衡消息的可靠性和性能。 为了尽量避免消息同步不一致的情况,你可以考虑以下几点: 1: 配置适当的消息复制因子,使得主从节点数目足够,即使在切换过程中也能够保持足够的消息冗余。 2: 配置合适的同步策略,根据你的业务需求来平衡消息的可靠性和性能。 3: 在设计应用程序时,考虑处理消息重复和消息丢失的情况,以保证数据的完整性和一致性。
问题1:也就是说,从1在切换为新主后,第一件会做的事情是去其他从拉取消息,来让各方的数据对齐?
问题2:配置适当的同步因子,我理解就是增加从机器的数量? 从机器越多,主往从需要同步的也就越多,同步给某一台从或某几台从失败的概率不就更增大了?
问题3:配合合适的同步策略,使用了raft协议高可用后,不是默认同步n/2 + 1台机器就返回写入成功了吗,难道n/2 + 1这个比例,还能更改吗?
管理员(1小时前):
问题1:是的,当从节点1成为新的主节点时,它会尝试与其他从节点进行消息同步,以使各方的数据尽可能对齐。这个过程可能涉及消息的复制、同步和确认,以确保消息的冗余性和一致性。
问题2:配置适当的消息复制因子并不是指增加从机器的数量。消息复制因子是指每条消息在集群中被复制的次数,也就是消息副本数。默认情况下,RocketMQ 会将消息复制到多个节点上,以提供冗余和可靠性。增加消息复制因子会增加磁盘和网络负载,但可以提高数据的冗余性。从机器的数量与消息复制因子不完全一致,你可以根据业务需求和性能考虑来调整消息复制因子。
问题3:RocketMQ 使用 Raft 协议来实现高可用性的主从架构,确实默认情况下需要将消息同步到大多数节点才会返回写入成功。在一个有 n 个节点的集群中,写入成功需要同步到 n/2 + 1 个节点。这是为了确保在大多数节点可用的情况下,数据的一致性和可靠性。
029_raft 协议的leader选举算法介绍
raft 协议,就是一套针对分布式系统多台机器,进 行Leader 选举 + 主从同步复制 + 主从切换,定义的一套算法和方法论
具体思想怎么实现的,要看开源的 raft 框架,或者是自己动手实现一套 raft 协议算法
具体原理是,
每个follower都会给自己设置一个1 50ms~300ms之间的随机的倒计时时间,也就是 说有的follower可能会倒计时150ms,有的可能是 160ms,有的可能是240ms,大家的时间一般是不一样的
肯定有一个follower 倒计时时间是最少的,他是最先完成倒计的, 也就是第一个完成倒计时的follower, 此时这个follower就会苏醒过来,并把自己的身份转变为candidate,成为一个leader候 选人,他会开始想要竞选成为一个leader,就需要大家一起来给它投票,他自己也可以投票,他当然会投票给他自己, 但这是不够的,他还需要得到别人的认可,这个很关键 ,他会发送请求给其他的节点,进行拉票的动作,他把拉票的请求发送给另外2个还是follower状态的节点,他们还在 进行倒计时呢
follower节点,此时收到一个拉票的请求之后,如果他之前没有给别人投过票,此时收到了一个拉票请求,就会把自己的票投给你,如果他要是之前投票给别人了,此时他就拒绝你的拉票。
当前的两个follower,他们肯定没有投过票,因为 他们之前一直在倒计时,这两个follower会把票都投给我们的第一个苏醒过来的candidate
candidate完成拉票之后,因为那两个follower都把票投给了他,他此时发现自己的得票数,已经超 过了半数quorum了,n/2+1,此时它就顺理成章成为leader
大多数follower,比如说他之前倒计时250ms , 此时还有50ms就要倒计时完毕了,但是收到了一个人说自己是leader, 该follower就会重置自己的倒计时计时器,重新从 250ms 开始进行计时,这就是leader维持自己的地位的手段,只要有它在,让两个follower永远没有机会成为candidate
030_Broker基于状态机实现的leader选举
状态机就是状态模式的一个运用,
状态设计模式,你的系统可以维护多个状态State,多个State之间可以进行切换,每次切换到一个新的state之后,执行的行为是不同的,行为是跟state绑定在一起的
状态设计模式 -> 状态机 -> state machine , 就是跟状态设计模式是差不多的,可以维护多个state 状态,不同的状态可以对应不同的行为
rocketmq,broker在实现leader选举的时候,采取的就是一个状态机制来实现的
031_Leader选举状态机实现细节全分析
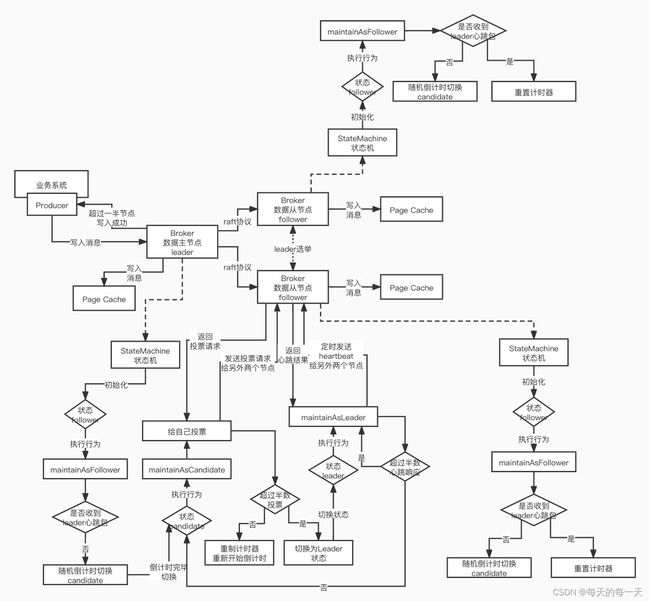
broker1 2 3
如果1和3同时结束倒计时,都像2发出了拉票,2把票给了1,则1成为leader,3重新开始倒计时
如果1 2 3都同时结束倒计时,三个人各自都向对面两个人发出了拉票,那么此轮就三个人都只有各自给自己投的一票,则1 2 3都重新开始倒计时进入下一轮投票
032_Broker基于DLedger的数据写入流程
基于raft协议思想指导的leader选举的机制,都已 经搞定了,数据是如何进行写入的, raft 协议之下,只有 leader 可以对外提供服务,对外提供写和读的服务,follower是不对外提供服务的,他们仅仅是进行数据复制和同步,只有在leader故障的 时候,follower们才会完成重新的leader选举, 以便继续对外提供服务
kafka、zookeeper其实是如出一辙的,如果说你要是一边写leader,一边从follower去读,raft协议 之下,过半写成功机制,此时如果允许对 follower 发起一个读的话,可能会有一个问题,可能会读 到那个还没复制成功数据的follower,从而导致broker集群对外看到的数据视图是不一致的
为了解决数据写和读的一致的问题,kafka、zk、rocketmq raft实现,都是写和读针对 leader就可以了,写成功了再去读,一定是可以读到一致的数据
033_Broker引入DLedger后的存储兼容设计
消费的时候,读数据,只要 leader 写入成功了,此时就可以在leader读取到呢? 仅仅是写入 leader的page cache,本次写入是并没有宣告成功的,还需要等待是否超过半数节点写入成功, 此 时写入并没有成功,就不应该让你消费的时候读 取到leader写成功的数据,这里大家一定要注意这 个点,一定要等到半数写成功,返回这条消息写入已经成功了,做到这一点,才可以让在leader上的数据被消费到读取到
消息数据被调整为了dledger 的日志格式, 针对这 个日志格式,此时应该如何来进行兼容
dledger写入的日志格式的数据,写入 commitlog 里面去的是有header 和 body 两个部分, header 这里是包含了很多的 header头字段(每个头字段 4 个字节或者几个字节 )和长度不固定的 body体
原始的commitlog存储的一条一条的数据,会把原始的commitlog里的数据,一个数据条目,给他放到dledger里面的body里面去,header一堆头字段 +body ( commitlog 原始数据), 不 就可以了 吗
把dledger数据存储结构和原始的 commitlog 做了一个兼容和整合,两块数据就集成到一块儿去了 commitlog 里是每一条数据都有 header+body , 此时你如果准备存入ConsumeQueue的消息索引条目中的消息全局物理偏移量,还是从header开始去计算就不对了,在ConsumeQueue里放入的每个消息索引条目的offset偏移量,是 commitlog 里一条数据的body起始的物理偏移量
034_BrokerController主从元数据同步
元数据、消息写入和读取,都是基于broker leader 来进行的
topic路由信息,topic在当前broker组里放了几个 queue,集群里会有很多的 topic, 每个不同的topic都会在当前broker里放他们自己所属的queue , 类 似 这样 的 topic 路由数据
消费进度数据,各个consumer group对同一个queue的不同消费进度数据,此时都是存储在主节点上的
需要从节点起一个定时任务,每隔60s去主节点拉取一次
从节点的BrokerController#initiallize()方法内,会通过延时单线程线程池,起一个每60s执行一次的定时任务,定时任务中会判断broker是Master则打印一下主从的diff,如果是slave就会执行SlaveSynchronize#syncAll()方法来同步四种数据:Topic数据,就是当前topic在当前master broker上有几个队列之类的信息,因为一个topic的queue可能分布在多台不同的master broker上、消费进度信息,比如TEST_01_TOPIC这个topic,在当前master broker中有4个queue,那么同步给从节点的消费进度信息可能就是 { TEST_01_TOPIC@trade_system_consumer_group,0:137,1:128,2:145,3:115 }。 这样的不同消费组对于同一个topic下,四个不同队列的消费进度
从节点起一个定时任务,去主节点拉取四种不同类型的元数据,也就意味着从节点会通过netty向主节点发送四次request_code不同的请求,主节点侧会有一个请求入口统一接收这四种request_code不同的请求,每个request_code都对应有一套不同的逻辑处理,然后分发路由给不同的逻辑处理。四种不同类型的数据,就对应着主节点这边有四种不同类型的XxxxxManager的数据管理器,来管理着这四种不同类型的数据
从节点拉取到主节点返回的元数据以后,比如拉取到返回的topic信息后,首先要做的就是比对返回的数据的DataVersion与自己本地缓存的数据版本是否一致,如果不一致才会执行更新本地缓存数据
Consumer端
036_Consumer端队列负载均衡分配机制
topic是有一堆的queue,且分布在不同的broker上的; consumer group 是有多个 consumer ,要把多个queue 分配给多个consumer,每个 consumer都会分配到一部分的queue
- 这个queue->consumer的分配关系谁来负责,负责分配的角色,他就可以根据一定的算法,把 queue分配个我们的consumer ,
- topic里的有多少queue信息从哪里获取,
- 如何知道一个consumer group 里到底有多少个 consumer
每个consumer都会去获取到 topic有多少个queue同时还会去获取consumer group里有多少个 consumer, 然后每个consumer自己都会按照相同的算法,去做一次分配
每个Consumer会向所有的broker进行注册,从而每个broker就都知道一个consumer group的所有 consumer有哪些
RebalanceService , 拉取 topic queue 信息, 拉取 consumer group , 根据算法分配 queue , 确 认 自己要拉取哪些 queue 平均分配算法、 轮询 分配算法、 一致性 hash 、 配置化、 机房分配
037_Consumer 消息拉取的挂起机制分析
q1 , q2 , q3 , q4 , q5 , q6 , q7 , q8 , 两个broker 组,8个queue,2个consumer,完成了queue->consumer的分配之后,当前的 consumer也就知道自己应该负责的queue是哪些了
如果没有开启 consumer 拉取消息的long polling 长轮询机制,默认情况下就是 short polling 机制
- 短轮询机制,默认情况下他会挂起 1s , 通过shortPollingMillis 参数可以去进行控制挂起时长,如果过来未拉取到消息也挂起1s后,再次检查是否有满足条件的消息,此时不管有没有消息都会返回
- 如果开启了long polling 长轮询机制, 此时又分push和pull两种情况,
push模式,会挂起 + 每隔 5s 检查, 一直到 15s 都没有拉到消息,此时才会超时返回, 长轮询 ,
pull模式,挂起超时时间20s
不同模式的参数控制的时间不太一 样
PS:
关于push模式的长轮询,挂起 + 每隔 5s 检查,分别是两个不同的线程,当消费者消息拉取线程来到broker后发现没有符合条件的消息,则会进去挂起状态,然后broker端会另外起一个后台轮询线程,每隔 5s 检查一次有没有符合条件的消息,如果有,则唤醒前面挂起的消费者消息拉取线程、如果没有,则继续等待下一个5s
038_Consumer的处理队列映射与并发消费
messageQueue和processQueue是一对一对应的关系,当前consumer分配到消费4个messageQueue,也自己本地内存中就会建立4个一一对应的processQueue
MessageQueue是一个虚拟的概念。在Broker中,一个topic下有许多个MessageQueue,每个MessageQueue都会有一系列的ConsumeQueue文件,这个ConsumeQueue文件存储的是一条消息索引条目中存储的原始消息,对应在CommitLog文件中的offset偏移量,即一个全局物理位置
从MessageQueue拉回来的消息,会存储到本地的processQueue中,本地消费成功,则会将该条消息从processQueue中中删除
039_Consumer处理成功后的消费进度管理
两级异步刷写线程,才能让消费端传过来给到broker的消费进度,刷入broker的磁盘processQueue中删除,并把该消息对应的位点写入consumer本地的内存进度管理,此时异步线程还未来得及把该进度刷给broker的内存端,consumer就宕机了,此时就会引起重复消费
040_Consumer消息重复消费原理剖析
consumer 消息重复消费,是一个可能很经常的一个事情, mq consumer,都要实现一套严格的分布式锁和幂等性检查保障的机制和体系
消费进度的两级刷盘机制,如果消费端的listener刚成功处理一条消息返回SUCCESS,把该消息从
consumer重复消费具体代码怎么落地呢,分布式锁是使用redisson?
管理员(2022-8-5): 是的,一般上游消息里面有一个messageid,然后证据这个id做消息的幂等,或者通过 redis redisson做分布式锁来保证幂等(重复消费)
041_Consumer处理失败时的延迟消费机制
处理失败的消息,或者处理过程中抛出异常并没有捕获的场景,会返回一个RECONSUME_LATER,此时也会删除processQueue中对应的该条消息,并且此时也会给broker返回一个ack,此时broker会做几个动作
会将原消息整体包装起来,外层换成RETRY_XXX_TOPIC,然后把封装后的消息写入commitlog中,并且此时会有18个延迟队列分别对应不同的延迟等级,首先把包装后的消息丢入第一级延迟队列,每一级延迟队列都对应有一个定时任务扫描,发现自己负责的队列中有消息到达延迟时间后,就把包装消息从commitlog中取出来,然后换成原始的业务topic,成为原始消息,此时把这个恢复出来的原始消息又丢进commitlog,并会重新被reput到ConsumeQueue中,最后消费者消息拉取线程,就又可以把这条消息从broker的ConsumeQueue中拉回到本地processQueue中进行针对该条消息的重试消费
042_Consumer Group变动时的重负载机制
consumer group内增减consumer ,都会引起重平衡
比如当前就一台broker内部有4个queue,有一个consumer group内部有2个consumer,按照平均分配算法,consumer1分配queue1和2,consumer2分配queue3和4,当consumer1挂掉后,consumer2就会去接管queue1和2,也就是说consumer2的消息拉取线程,会同时负责拉取4个队列的消息,同时,因为该台broker内部保存了queue1和2当前的消费进度,所以consumer2可以接着这个进度往后进行消费
从这里,就能看出重平衡可能引起重复消费,consumer1消费了10条queue1的消息,但是还未将消费进度同步给broker就挂了,引起重平衡,后续consumer2又会再次消费这10条queue1的消息