五种创建型模式
单例模式、建造者模式、抽象工厂模式、工厂方法模式、原型模式
一、单例模式(Singleton)
原始定义:允许存在一个和仅存在一个给定类的实例。它提供一种机制让任何实体都可以访问该实例
单例模式的好处:
- 节省系统开销,省去了频繁创建对象的开销,尤其是比较大型的对象
- 省去了new运算符,降低系统内存的使用频率,减轻GC压力
UML表示

图中Singleton类声明了instance的静态对象和名为getInstance()的静态方法
静态对象用于存储对象自身的属性和方法,静态方法用于返回所属类的一个相同实例
以懒汉式单例为例
package singleton;
/**
* @author hym
* @date 2021/11/3
* @description 懒汉式
*/
public class LazySingleton {
/**
* 用于存储单一实例的静态对象
*/
private static LazySingleton singleton;
/**
* 私有的空构造函数
*/
private LazySingleton() {
}
/**
* 通过判断静态对象是否初始化来选择是否创建对象
*/
public static LazySingleton getSingleton() {
return (null == singleton) ? new LazySingleton() : singleton;
}
}
从上述代码可看出,单例模式的三个要点:
- 单例类只能有一个实例
- 单例类必须自行创建实例
- 单例类必须保证实例能全局唯一访问
需要关注:
- 限制实例数量
- 创造与销毁实例
- 保证实例线程安全的机制
单例模式对象的职责:
- 一个类只有一个实例
- 为该实例提供全局访问点
单例类的默认构造函数和静态对象都是供内部调用的
单例模式提供一个公共的对外方法,以获取唯一实例
构造函数私有的原因:防止在其它类中使用单例类的new运算符,创建新的实例
单例模式类似于全局变量,可以使用单例替代全局变量
使用场景
程序的初始化
创建方式
饿汉式单例
package singleton;
/**
* @author hym
* @date 2021/11/3
* @description 饿汉式单例
*/
public class HungrySingleton {
/**
* 成员变量初始化本身对象
*/
private static HungrySingleton singleton = new HungrySingleton();
/**
* 构造私有
*/
private HungrySingleton() {
}
/**
* 对外提供公共方法获取对象
*/
public static HungrySingleton getSingleton() {
return singleton;
}
}
另一种懒汉式单例
确保线程安全
package singleton;
/**
* @author hym
* @date 2021/11/3
* @description 另一种懒汉式单例
*/
public class AnotherLazySingleton {
private AnotherLazySingleton() {
}
/**
* 此处使用一个内部类来维护单例
* JVM在类加载的时候,是互斥的,所以可以由此保证线程安全问题
*/
private static class SingletonFactory {
private static final AnotherLazySingleton SINGLETON = new AnotherLazySingleton();
}
/**
* 获取实例
*/
public static AnotherLazySingleton getSingleton() {
return SingletonFactory.SINGLETON;
}
}
synchronized 同步
使用synchronized确保线程安全
1、synchronized方法
package singleton;
/**
* @author hym
* @date 2021/11/3
* @description synchronized同步方法
*/
public class SyncMethodSingleton {
private static SyncMethodSingleton singleton;
private SyncMethodSingleton() {
}
public synchronized static SyncMethodSingleton getSingleton() {
return (singleton == null) ? new SyncMethodSingleton() : singleton;
}
}
对整个方法加同步,效率比较低,性能不高
仅在new的时候考虑同步即可
2、synchronize代码块
使用 synchronized代码块 + 双重锁检测 确保线程安全
package singleton;
/**
* @author hym
* @date 2021/11/3
* @description 同步代码块创建单例
*/
public class SyncBlockSingleton {
private static SyncBlockSingleton singleton;
private final static Object SYNC_LOCK = new Object();
private SyncBlockSingleton() {
}
/**
* 双重锁检测机制
* 锁对象可以采用类或静态实例
*/
public static SyncBlockSingleton getSingleton() {
if (singleton == null) {
synchronized (SYNC_LOCK) {
if (singleton == null) {
singleton = new SyncBlockSingleton();
}
}
}
return singleton;
}
}
双重锁定
使用 synchronized代码块 + 双重锁检测 确保线程安全
package singleton;
/**
* @author hym
* @date 2021/11/3
* @description 双重锁检测 + 单例
*/
public class DoubleCheckedLock {
private static DoubleCheckedLock singleton;
private DoubleCheckedLock() {
}
/**
* 双重锁检测机制
* 锁对象可以采用类或静态实例
*/
public static DoubleCheckedLock getSingleton() {
if (singleton == null) {
synchronized (DoubleCheckedLock.class) {
if (singleton == null) {
singleton = new DoubleCheckedLock();
}
}
}
return singleton;
}
}
枚举单例
采取枚举单例的原因及好处请参见
package singleton;
/**
* @author hym
* @date 2021/11/5
* @description 枚举单例
*/
public enum EnumSingleton {
SINGLETON;
public Enum getSingleton() {
return SINGLETON;
}
}
ThreadLocal 单例
package singleton;
import java.util.HashMap;
import java.util.Map;
/**
* @author hym
* @date 2021/11/3
* @description ThreadLocal创建单例
*/
public class ThreadLocalSingleton {
private static final ThreadLocal<ThreadLocalSingleton> local = new ThreadLocal<>();
private Map<String, Object> data = new HashMap<>();
/**
* 初始化的实现方法
*/
private static ThreadLocalSingleton init() {
ThreadLocalSingleton singleton = new ThreadLocalSingleton();
local.set(singleton);
return singleton;
}
/**
* 做延迟初始化
*/
public static ThreadLocalSingleton getSingleton() {
ThreadLocalSingleton singleton = local.get();
return (singleton == null) ? init() : singleton;
}
/**
* 删除实例
*/
public static void remove() {
local.remove();
}
/**
* 获取所有数据
*/
public Map<String, Object> getData() {
return getSingleton().data;
}
/**
* 批量存数据
*/
public void setData(Map<String, Object> data) {
getSingleton().data.putAll(data);
}
/**
* 存数据
*/
public void set(String key, String value) {
getSingleton().data.put(key, value);
}
/**
* 取数据
*/
public void get(String key) {
getSingleton().data.get(key);
}
}
ThreadLocal相比于传统的线程同步机制更有优势
1、传统的同步机制中,会通过对象的锁机制保证同一时间只有一个线程访问单例类,此时该类由多个线程共享
使用同步机制时,对什么时候对类进行读写、什么时候锁定和释放对象有很繁琐的要求
对于一般程序员来说,设计和编写难度相对较大
2、ThreadLocal会为每一个线程提供一个独立的对象副本,从而解决了多个线程对数据访问冲突的问题
省去了线程之间的同步操作
推荐使用ThreadLocal实现单例
为什么使用单例模式
一、系统资源有限
比如:控制共享资源的权限时,资源有限就会带来访问冲突的问题,若不限制实例的数量,有限的资源很快就会耗尽,导致大量的对象处于等待资源中
比如:使用外部进程式服务,若不使用单例模式,随着用户进程数开启越多,系统原有的进程处理资源就会变得更少,不仅会导致操作系统处理速度变慢,同时影响用户进程的处理速度
二、某些对象需要满足全局唯一
比如:系统要求提供唯一的序列号生成器
在系统中要求一个类仅有一个实例时应当使用单例模式
优缺点
优点:
- 合理地利用并保护有限的资源,防止资源重复争夺
- 高内聚的代码组件,提升代码复用性
- 全局唯一访问点方便按照统一的规则管控权限
- 负载均衡:可以轻松的将Singleton扩展至多个实例
缺点:
- 充当全局变量时,引用次数越多,代码修改影响的范围越大
- 充当全局变量时,在全局变量中使用状态变量,会造成加/解锁的性能损耗
- 耦合性较高,隐蔽了不同对象之间的调用关系
- 不支持有参构造
二、建造者模式(Builder)
建造者模式(Builder模式)或叫做生成器模式
用处:创建不同形式的复杂对象
原始定义:将复杂对象的构造与其表示分离,以便同一构造过程可以创建不同的表示。
疑问:为什么不直接使用构造函数或者set方法创建对象,
而采用创建者模式创建?
UML表示
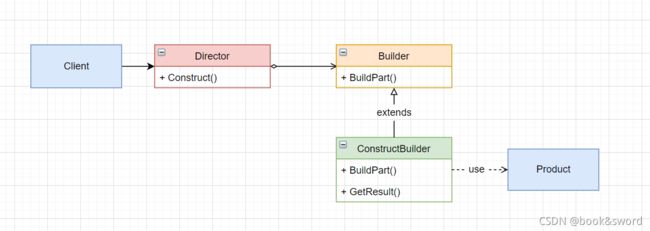 建造者模式包含四类角色
建造者模式包含四类角色
Product:待创建对象
Builder:建造者抽象基类/接口
定义构建Product的步骤
ConcreteBuilder:建造者实现类
实现Builder定义的步骤,并提供获取创建对象的方法,如getProduct()
Director:建造对象的算法
可通过构造方法Construct(Builder builder),来调用Builder的创建方法创建对象
建造者模式时序图
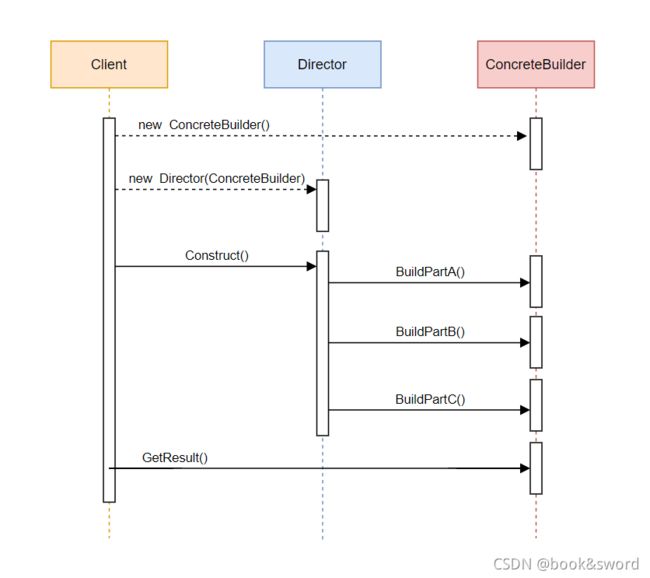
创建原理
1、先创建建造者
2、然后给建造者指定构建算法
3、建造者按步骤构建对象
4、最终获取对象
实现代码
Product
package builder;
/**
* @author hym
* @date 2021/11/5
* @description 待创建对象
*/
public class Product {
private int partA;
private String partB;
private int partC;
public Product(int partA, String partB, int partC) {
this.partA = partA;
this.partB = partB;
this.partC = partC;
}
@Override
public String toString() {
return "Product{" +
"partA=" + partA +
", partB='" + partB + '\'' +
", partC=" + partC +
'}';
}
}
Builder
package builder;
/**
* @author hym
* @date 2021/11/5
* @description 建造者抽象接口
*/
public interface Builder {
void buildPartA(int partA);
void buildPartB(String partB);
void buildPartC(int partC);
Product getResult();
}
ConcreteBuilder
package builder;
/**
* @author hym
* @date 2021/11/5
* @description 建造者实现类
*/
public class ConcreteBuilder implements Builder {
private int partA;
private String partB;
private int partC;
@Override
public void buildPartA(int partA) {
this.partA = partA;
}
@Override
public void buildPartB(String partB) {
this.partB = partB;
}
@Override
public void buildPartC(int partC) {
this.partC = partC;
}
@Override
public Product getResult() {
return new Product(partA, partB, partC);
}
}
Director
package builder;
/**
* @author hym
* @date 2021/11/5
* @description 建造对象的算法
*/
public class Director {
public void construct(Builder builder) {
builder.buildPartA(1);
builder.buildPartB("hello");
builder.buildPartC(2);
}
}
Test 测试类
package builder;
/**
* @author hym
* @date 2021/11/5
* @description 测试类
*/
public class Test {
public static void main(String[] args) {
Director director = new Director();
ConcreteBuilder builder = new ConcreteBuilder();
director.construct(builder);
System.out.println(builder.getResult());
}
}
测试结果

建造者模式封装了
1、建造器的构建步骤
2、正使用的建造器
3、现有建造器数量
4、创建的多个属性的特征
建造者模式中对象的职责
保证属性按照正确的步骤进行组合
使用场景
1、需要生成的对象包含多个成员属性
2、需要生成的对象的属性相互依赖,需要指定其生成顺序
3、对象的创建过程独立于创建该对象的类
4、需要隔离复杂对象的创建和使用,并使得相同的创建流程可以创建不同的产品
例子
对比 使用/不使用 建造者模式的差异
不使用建造者模式
package builder.demo;
/**
* @author hym
* @date 2021/11/5
* @description 不使用创建者模式
*/
public class WorkerWithNoBuilder {
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private int age;
/**
* 电话
*/
private String phone;
/**
* 性别
*/
private String gender;
public WorkerWithNoBuilder(String name, int age, String phone, String gender) {
this.name = name;
this.age = age;
this.phone = phone;
this.gender = gender;
}
public WorkerWithNoBuilder(String name, int age, String phone) {
this.name = name;
this.age = age;
this.phone = phone;
}
public WorkerWithNoBuilder(String name, int age) {
this.name = name;
this.age = age;
}
}
没有使用建造者模式,需要使用传统的 getter、setter 方法,并指定不同的入参来构造对象。
使用创建者模式
package builder.demo;
/**
* @author hym
* @date 2021/11/5
* @description 使用创建者模式
*/
public class WorkerWithBuilder {
private String name;
private int age;
private String phone;
private String gender;
public WorkerWithBuilder() {
}
public static WorkerWithBuilder builder() {
return new WorkerWithBuilder();
}
/**
* 将属性作为步骤
*/
public WorkerWithBuilder name(String name) {
this.name = name;
return this;
}
public WorkerWithBuilder age(int age) {
this.age = age;
return this;
}
public WorkerWithBuilder phone(String phone) {
this.phone = phone;
return this;
}
public WorkerWithBuilder gender(String gender) {
this.gender = gender;
return this;
}
/**
* 执行创建操作
*/
public WorkerWithBuilder build() {
validate(this);
return this;
}
/**
* 基础预校验,自定义校验
*/
public void validate(WorkerWithBuilder worker) {
}
@Override
public String toString() {
return "WorkerWithBuilder{" +
"name='" + name + '\'' +
", age=" + age +
", phone='" + phone + '\'' +
", gender='" + gender + '\'' +
'}';
}
}
测试类
package builder.demo;
/**
* @author hym
* @date 2021/11/5
* @description 测试类
*/
public class Test {
public static void main(String[] args) {
WorkerWithBuilder worker1 = WorkerWithBuilder.builder()
.name("Hans")
.age(27)
.phone("10086")
.gender("男")
.build();
System.out.println(worker1);
WorkerWithBuilder worker2 = WorkerWithBuilder.builder()
.name("Armond")
.age(17)
.phone("10086")
//没有性别
.build();
System.out.println(worker2);
WorkerWithBuilder worker3 = WorkerWithBuilder.builder()
.name("Isabelle")
.age(17)
//没有 电话
.gender("女")
.build();
System.out.println(worker3);
WorkerWithBuilder worker4= WorkerWithBuilder.builder()
.name("August")
//没有 年龄
//没有 电话
//没有 性别
.build();
System.out.println(worker4);
}
}
输出结果

在创建worker对象时,仅指定不同属性构建步骤,但构造出了完全不同的实例。
而使用传统的方式需要定义不同的构造函数
所以说:建造者模式方便了按需进行对象的实例化,避免很多不同的构造函数
同时避免了同一类型参数只能写一个构造函数的弊端
为什么使用建造者模式
可以使用Lombok的@Builder注解实现创建者模式
JDK类库中Appendable接口均采用了建造者模式
一、分步骤的方法适用于多次运算结果类的创建
二、只关注功能,无需关注建造者的具体算法实现
使用建造者模式的优缺点
优点
1、分离了创建与使用
使用者无需关注步骤实现细节,通过统一方法接口调用,实现自由组合出不同的实例
2、满足开闭原则
建造者相对独立,可以方便的进行替换或新增,提升了扩展性
3、创建过程可自由地组合对象
将复杂的创建步骤拆分为单独的创建步骤,提高代码可读性,可以灵活创建对象
Maven、Ant 之类的自动化构建系统、
Jenkins 等持续集成系统,都采用了建造者模式
缺点
1、适用范围有限
对象需具备更多共同点才可抽象出适合的步骤
实例间差距较大时,不适合使用建造者模式
2、易引起超大类
随着需求的新增或变化,增加新的创建步骤,导致代码膨胀,形成超大类
要求我们只关注具备重用性的组件,避免过度的定制化创建步骤
3、增加代码规模
提高了可读性,牺牲了代码量
一旦产品内部开始变得复杂,可能导致需要定义很多定制化的建造者类来适应变化,从而造成代码变得非常庞大。
工厂模式被分为三种:简单工厂模式、工厂方法模式、抽象工厂模式。简单工厂是工厂方法模式的特例
三、抽象工厂模式(Abstract Factory)
作用:统一不同代码风格下的代码级别
重点:找到正确的抽象,找到某一类产品的正确共性功能
原始定义:提供了一个用于创建相关对象/对象族的接口,而无需指定具体类
抽象工厂模式,最终仍涉及指定具体的实现类
UML表示

四个关键角色
抽象工厂
抽象产品(通用的一类对象或接口)
具体工厂
具体产品(继承通用对象或接口后扩展特有属性)
抽象工厂(AbstractFactory)生产抽象产品(Auto)
具体工厂(ChinaFactory)生产具体商品(Byd)
最关键的角色是抽象产品,决定了抽象工厂与具体工厂能否发挥最大作用
代码实现
/**
* @author hym
* @date 2021/11/8
* @description 抽象工厂
*/
public interface AbstractFactory {
/**
* 生产汽车
* @return 汽车
*/
Auto produceAuto();
}
/**
* @author hym
* @date 2021/11/8
* @description 中国工厂
*/
public class ChinaFactory implements AbstractFactory {
/**
* 生产汽车
* @return 国系汽车
*/
@Override
public Auto produceAuto() {
return new Byd();
}
}
/**
* @author hym
* @date 2021/11/8
* @description 德国工厂
*/
public class GermanyFactory implements AbstractFactory {
/**
* 生产汽车
* @return 德系汽车
*/
@Override
public Auto produceAuto() {
return new Vw();
}
}
/**
* @author hym
* @date 2021/11/8
* @description 抽象产品
*/
public interface Auto {
}
/**
* @author hym
* @date 2021/11/8
* @description 比亚迪
*/
public class Byd implements Auto {
}
/**
* @author hym
* @date 2021/11/8
* @description 大众
*/
public class Vw implements Auto{
}
/**
* @author hym
* @date 2021/11/8
*/
public class Client {
private Auto auto;
public Client(AbstractFactory factory) {
auto = factory.produceAuto();
}
}
软件使用者只关注某种产品的某种功能,对实现并不在意;软件创建者需要找到正确的共性功能,尽可能隐藏具体的实现细节,并始终围绕着提供共性功能的软件
使用场景
软件开发中,抽象工厂模式的使用场景是解决跨平台兼容性问题
1、支持多操作系统的程序,会使用到抽象工厂。
为当前应用程序所使用的操作系统选择正确的硬件驱动程序集合
2、电商系统,国内、海外电商都需要使用类似的商品、订单、物流等系统,但不同地区的政策以及购买习惯存在差异,可以使用抽象工厂来解决差异性的问题,并提高代码的可移植性
3、Spring框架的BeanFactory
public interface BeanFactory {
String FACTORY_BEAN_PREFIX = "&";
Object getBean(String var1) throws BeansException;
<T> T getBean(String var1, Class<T> var2) throws BeansException;
Object getBean(String var1, Object... var2) throws BeansException;
<T> T getBean(Class<T> var1) throws BeansException;
<T> T getBean(Class<T> var1, Object... var2) throws BeansException;
<T> ObjectProvider<T> getBeanProvider(Class<T> var1);
<T> ObjectProvider<T> getBeanProvider(ResolvableType var1);
boolean containsBean(String var1);
boolean isSingleton(String var1) throws NoSuchBeanDefinitionException;
boolean isPrototype(String var1) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String var1, ResolvableType var2) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String var1, Class<?> var2) throws NoSuchBeanDefinitionException;
@Nullable
Class<?> getType(String var1) throws NoSuchBeanDefinitionException;
@Nullable
Class<?> getType(String var1, boolean var2) throws NoSuchBeanDefinitionException;
String[] getAliases(String var1);
}
BeanFactory是Spring实现IOC容器的核心接口,职责包括:实例化、定位、配置应用程序中的对象,建立对象间依赖…
实现此抽象工厂的类:AbstractBeanFactory…
 AbstractBeanFactory的子类
AbstractBeanFactory的子类

Object/
AbstractBeanFactory 是 抽象工厂
XmlBeanFactory 是 具体工厂
通过XML注入的Bean 是 具体产品
实际的代码实现中,抽象工厂模式常表现为定义抽象工厂类,由多个不同的具体工厂继承这个抽象工厂类,各自实现相同的抽象功能,进而实现代码的多态性
采用抽象工厂模式的原因
一、提升组件复用性
当不同产品系列有比较多的共性特征时,使用抽象工厂模式可提升组件复用性
JDBC采用抽象工厂模式,可以使用JDBC连接不同的数据库产品进行操作,是可复用的
二、提高代码的扩展性、降低维护成本
将对象的创建和使用过程分开,能有效地将代码统一到统一级别
新增的产品生产流程,不影响旧的生产流程
三、解决跨平台带来的兼容性问题
后台服务应尽可能地使用更高层级的统一抽象功能,然后通过不同客户端的适配程序完成统一的功能交付
收益和损失
优点:
满足开闭原则
对扩展开放,无需更改其他代码
新增产品生产逻辑,仅需新增抽象工厂实现
满足单一职责原则
同一特征的产品的生产流程,高内聚于具体实现内部
一个工厂仅负责生产一种/组产品
将使用和创建的代码解耦
使用抽象工厂的抽象功能,具体功能在具体工厂中实现
保证同一工厂生成的产品符合预期
抽象工厂定义了统一的产品功能
后续的实现基于抽象产品接口功能,不会改变
易于扩展新产品
基于抽象工厂模板,新增对应的实现工厂即可
缺点:
提高代码量
进行了职责分离,但导致类文件和代码行数增加。
并随着实现子类越多,当抽象工厂改动,影响范围大
增加学习成本
找到正确抽象很困难,需要大量实践,不断归纳
产品结构变更困难
抽象工厂更改产品结构,所有具体工厂都需要增加新的实现
会引入风险。本质是继承带来的问题。
只有找到了正确的抽象产品,才能发挥工厂模式的作用
四、工厂方法模式(Factory Method)
和抽象工厂模式类似,但工厂方法模式只围绕着一类接口来进行对象的创建和使用,使用场景更加单一,实际项目中使用频率比抽象工厂模式更高
目的:封装对象创建过程,提升对象方法的可复用性
定义:定义一个创建对象的接口,让实现这个接口的类决定实例化哪个类
UML表示
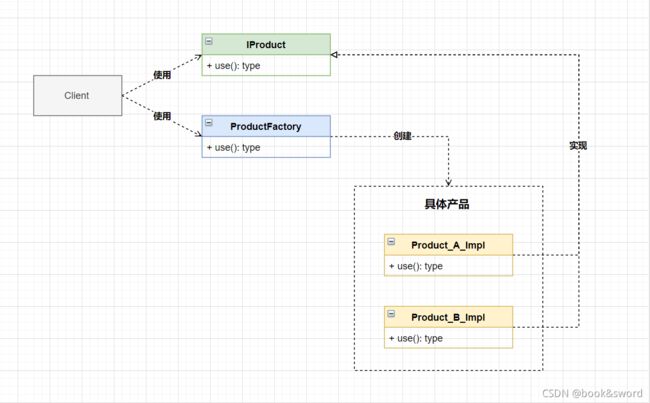
三个角色:
1、抽象接口(抽象产品)
2、核心工厂
3、具体产品(可以是具体工厂)
核心工厂:作为父类负责定义创建对象的抽象接口,以及使用哪些具体产品
具体产品:可以是一个具体的类,也可以是一个具体工厂类,负责生成具体的对象实例。
工厂方法模式将对象的实例化操作延迟到了具体产品子类中去完成
不同于抽象工厂模式,工厂方法模式侧重于直接对具体产品的实现进行封装和调用,通过统一接口定义来约束程序的对外行为
代码:
/**
* @description 抽象产品
*/
public interface IProduct {
void apply();
}
/**
* @description 核心工厂类
*/
public class ProductFactory {
public static IProduct getProduct(String name) {
if ("a".equals(name)) {
return new Product_A_Impl();
}
return new Product_B_Impl();
}
}
/**
* @description 具体产品实现A
*/
public class Product_A_Impl implements IProduct {
@Override
public void apply() {
System.out.println("Produce A");
}
}
/**
* @description 具体产品实现B
*/
public class Product_B_Impl implements IProduct {
@Override
public void apply() {
System.out.println("Produce B");
}
}
/**
* @description 使用者
*/
public class Client {
public static void main(String[] args) {
IProduct product = ProductFactory.getProduct("");
product.apply();
IProduct a = ProductFactory.getProduct("a");
a.apply();
}
}
工厂方法模式很好地实现了分离原则
ProductFactory实现通用逻辑,实例的创建交由具体工厂
子类需要实现公共的接口对外提供统一功能
这允许程序在不修改工厂角色的情况下引入新的产品实现
分离原则:使用与创建分离,好处:提升组件复用性,同时保证对象在同一个逻辑层级里,便于阅读与维护
工厂方法模式封装了
1、具体的实现算法
2、具体产品数量
3、抽象产品
工厂模式是围绕着特定的抽象产品(一般是接口)来封装对象的创建过程,客户端需要通过工厂类来创建对象并使用特定接口的功能
使用场景
1、需要使用很多重复代码创建对象
如DAO层的数据对象、API层的VO对象
2、创建对象需要访问外部信息或资源
读取数据库字段,获取访问授权token、配置文件
3、创建需要统一管理生命周期的对象
会话信息、用户网页浏览痕迹
4、创建池化对象
连接池、线程池、日志...有限、可重用,使用工厂方法可以节约资源
5、隐藏对象真实类型
不希望使用者知道对象的真实构造函数
使用方法模式的原因
一、分离对象的创建与使用
二、减少重复代码
三、统一管理创建对象的不同实现逻辑
优点
根据用户需求定制化创建对象
隐藏具体使用那种产品创建对象
满足里氏替换原则
满足开闭原则
缺点
抽象接口新增方法时,增加开发成本
具体工厂实现逻辑不统一,增加代码理解难度
工厂方法模式侧重于继承的连续性
抽象工程模式侧重于组合的扩展性
五、原型模式(Prototype)
原型模式最早出现于Sketchpad,被认为是现代 CAD 程序的鼻祖,主要思想是拥有一张可以实例化成许多副本的原图,如果用户更改了主工程图,则所有实例也会更改。这便是原型模式最初的思维模型。
不过在面向对象编程中,对象的原型在变化时通常不会影响新实例对象
实际上,原型模式不仅在 Java、C++ 等主要基于类的编程语言中有广泛应用,
而且还在一开始就是基于原型的 JavaScript 等编程语言中得到了发扬光大
模式原理分析
原型模式定义:使用原型实例指定创建对象的种类,然后通过拷贝这些原型来创建新的对象
两个关键点:一个是要建立原型,另一个是基于原型做拷贝
Ctrl+C 加 Ctrl+V 编程,可以说就是最直接的原型模式的实践之一
UML 图:
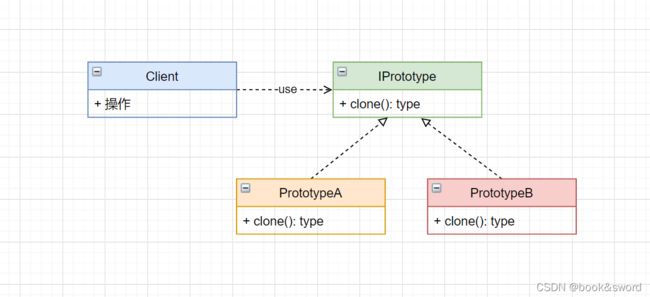
原型模式中的关键角色:
- 使用者
- 原型
- 新实例
使用者需要建立一个原型,才能基于原型拷贝出新实例
除此之外,使用者还需要决策什么时候使用原型、什么时候使用新实例
以及从原型到新实例之间的拷贝应该采用什么样的算法策略,这些都是使用者来进行控制和决定的。只不过通常我们会使用一个通用的抽象拷贝接口来对外提供拷贝。
那 UML 图对应的代码该怎么实现呢?可参考下面这段基于 Java Cloneable 接口的代码实现:
PrototypeInterface 接口,继承Cloneable接口
public interface PrototypeInterface extends Cloneable {
PrototypeInterface clone() throws CloneNotSupportedException;
}
ProtypeB 类,实现 PrototypeInterface 接口
public class ProtypeB implements PrototypeInterface{
@Override
public PrototypeInterface clone() throws CloneNotSupportedException {
System.out.println("Cloning new Object: B");
return (ProtypeB) super.clone();
}
}
ProtypeA 类,实现 PrototypeInterface 接口
public class ProtypeA implements PrototypeInterface {
@Override
public PrototypeInterface clone() throws CloneNotSupportedException {
System.out.println("Cloning new Object: A");
return (ProtypeA) super.clone();
}
/**
* ProtypeA 以自己为原型通过拷贝创建一个新的对象 cloneA
*/
public static void main(String[] args) throws CloneNotSupportedException {
ProtypeA source = new ProtypeA();
System.out.println(source);
PrototypeInterface cloneA = source.clone();
System.out.println(cloneA);
}
}
代码中,我们定义的 PrototypeInterface 接口通过继承 Cloneable 接口并重写 clone() 方法来实现对象的拷贝,
而 ProtypeA 和 ProtypeB 都可以在建立自己的原型对象后,调用 clone() 方法来创建新对象。这里要注意的是,Cloneable 接口本身是空方法,调用的 clone() 方法其实是 Object.clone() 方法。
从以上内容发现原型模式封装了如下变化:
- 原始对象的构造方式;
- 对象的属性与其他对象间的依赖关系;
- 对象运行时状态的获取方式;
- 对象拷贝的具体实现策略。
所以说,原型模式从建立原型到拷贝原型生成新实例,都是对用户透明的,一旦中间任何一个小细节出现问题,你可能获取的就是一个错误的对象。
使用场景分析
原型模式常见的使用场景有以下六种。
-
资源优化场景
当进行对象初始化需要使用很多外部资源时,
比如,IO 资源、数据文件、CPU、网络和内存等。
-
复杂的依赖场景。
比如,F 对象的创建依赖 A,A 又依赖 B,B 又依赖 C……
于是创建过程是一连串对象的 get 和 set。
-
性能和安全要求的场景。
比如,同一个用户在一个会话周期里,可能会反复登录平台或使用某些受限的功能,
每一次访问请求都会访问授权服务器进行授权,但如果每次都通过 new 产生一个对象会非常烦琐,这时则可以使用原型模式。
-
同一个对象可能被多个修改者使用的场景
比如,一个商品对象需要提供给物流、会员、订单等多个服务访问,
而且各个调用者可能都需要修改其值时,就可以考虑使用原型模式。
-
需要保存原始对象状态的场景
比如,记录历史操作的场景中,就可以通过原型模式快速保存记录。
-
结合工厂模式来使用
在实际项目中,原型模式除了单独基于对象使用外,还可以结合工厂方法模式一起使用,
通过定义统一的复制接口,比如 clone、copy。
使用一个工厂来统一进行拷贝和新对象创建, 然后由工厂方法提供给调用者使用。
实际的一些类库和组件中都有原型模式的应用。比如:
- Spring 中使用@Scope(“prototype”)注解来使得注入的 Java Bean 使用原型模式。
- Fastjson 中的 JSON.parseObject() 也是一种原型模式的实践。
- JDK 中,使用 cloneable 接口的都能实现原型模式。
接下来通过一个具体的实例来理解原型模式的使用。
假设我们正在构建一个家庭的知识管理系统,系统会很频繁地使用电子书和电影类的实例对象,
但用户不想每次创建对象时都等待很长的时间,于是开发人员决定使用原型模式来快速拷贝创建对象
首先,创建一个继承接口 Cloneable 的接口 IPrototype,如下:
public interface IPrototype extends Cloneable {
/**
* 继承Cloneable接口,重写clone()方法,便能使用父类的Object.clone()复制方法
* 也可以直接实现Cloneable接口,效果一样。这里我们为了统一业务接口层级,子类都实现IPrototype接口
*/
IPrototype clone() throws CloneNotSupportedException;
}
然后,再分别让电影类 Movie 和电子书类 EBook 实现 IPrototype 接口的拷贝方法。
/**
* @author hym
* @date 2021/12/3
* @description 电影
*/
public class Movie implements IPrototype {
/**
* 打印并拷贝对象
*/
@Override
public Movie clone() throws CloneNotSupportedException {
System.out.println("Cloning Movie object..");
return (Movie) super.clone();
}
/**
* 方便结果展示
*/
@Override
public String toString() {
return "Movie{}";
}
}
/**
* @author hym
* @date 2021/12/3
* @description 电子书
*/
public class EBook implements IPrototype {
@Override
public EBook clone() throws CloneNotSupportedException {
System.out.println("Cloning Book object..");
return (EBook) super.clone();
}
@Override
public String toString() {
return "EBook{}";
}
}
接下来,我们使用工厂模式来根据不同的对象类型进行对象的拷贝创建。
/**
* @author hym
* @date 2021/12/3
* @description 类型
*/
public enum ModelType {
MOVIE("movie"),
EBOOK("ebook");
private String name;
ModelType(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
/**
* @author hym
* @date 2021/12/3
* @description 原型工厂
*/
public class PrototypeFactory {
/**
* 这里充当注册表的作用,用于存放原始对象,作为对象拷贝的基础
*/
private static Map<String, IPrototype> prototypes = new HashMap<>();
/**
* 初始化时就将原始对象放入注册表中
*/
static {
prototypes.put(ModelType.MOVIE.getName(), new Movie());
prototypes.put(ModelType.EBOOK.getName(), new EBook());
}
/**
* 获取对象时,是使用name来进行对象拷贝
*/
public static IPrototype getInstance(final String s) throws CloneNotSupportedException {
return prototypes.get(s).clone();
}
}
单元测试来调用原型工厂创建对象
/**
* @author hym
* @date 2021/12/4
* @description 测试类
*/
public class Test {
public static void main(String[] args) {
try {
String moviePrototype = PrototypeFactory.getInstance(ModelType.MOVIE.getName()).toString();
System.out.println(moviePrototype);
String eBookPrototype = PrototypeFactory.getInstance(ModelType.EBOOK.getName()).toString();
System.out.println(eBookPrototype);
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
}
}
最终的输出结果:
在上面的代码实现中,我们通过实现 Cloneable 接口并使用 clone() 方法来进行对象的拷贝。电影类 Movie 和电子书 EBook 分别实现了各自的拷贝逻辑,
当通过原型工厂 PrototypeFactory 获取指定类型的对象时,我们其实获得的对象就是原始电影类或电子书类的对象副本。
综合以上分析,你会发现,原型模式的适用场景通常都是对已有的复杂对象或大型对象的创建上,在这样的场景中,创建对象通常是一件非常烦琐的事情,通过拷贝对象能快速地创建对象。
其实这里还涉及一个扩展知识点:浅拷贝与深拷贝。
当我们在做对象拷贝时,需要在浅拷贝和深拷贝之间做取舍
-
如果类仅包含**原始字段和不可变字段,**可以使用浅拷贝;
-
如果类还包含有可变字段的引用(比如,对象中包含对象),那么我们就应该使用深拷贝。
为什么要使用原型模式?
分析完原型模式的原理和使用场景后,我们再来说说使用原型模式的原因,主要有以下四个。
第一个,减少每次创建对象的资源消耗
当类初始化消耗资源特别多时,原型模式特别有用。
比如,在 AI 系统中,我们经常需要频繁使用大量不同分类的数据模型文件,
在对这一类文件建立对象模型时,不仅会长时间占用 IO 读写资源,还会消耗大量 CPU 运算资源,
如果频繁创建模型对象,就会很容易造成服务器 CPU 被打满而导致系统宕机。
通过原型模式我们可以很容易地解决这个问题,当我们完成对象的第一次初始化后,新创建的对象便使用对象拷贝(在内存中进行二进制流的拷贝),
虽然拷贝也会消耗一定资源,但是相比初始化的外部读写和运算来说,内存拷贝消耗会小很多,而且速度快很多。
第二个,降低对象创建的时间消耗
比如,需要查询数据库来创建对象时,如果数据库正好繁忙或锁表中,那么这个创建过程就可能出现长时间等待的情况。
在很多高并发场景中,稍微长时间的等待可能都是致命的,因为大量的数据和请求如洪水一般涌入服务器,很容易引起雪崩效应。
这时使用原型模式就是相当于对对象创建的过程进行了一次缓存读取,而不必一直阻塞程序的执行。
第三个,快速复制对象运行时状态
原型模式相比于传统的使用 new 关键字创建对象还有一个巨大的优势,那就是当构造函数中包含大量属性或定制化业务逻辑时,不用完全了解创建过程也能快速创建对象。
比如,当一个对象类有 30 个以上的属性或方法时(属性字段可能为另一个对象),如果都通过 get 和 set 方法来创建对象,会发现复制粘贴都是一件痛苦的事,因为可能都忘记了哪些字段是必选、哪些又是有数据的。
这也是我们在接收 HTTP 和 RPC 传输的 JSON 数据时,更愿意采用反序列化(也是一种原型模式的实践)到对象的方式,而不是 new 一个新对象再赋值的原因。
第四个,能保存原始对象的副本
在某些需要保存历史状态的场景中,
比如,聊天消息、上线发布流程、需要撤销操作的程序等,
原型模式能快速地复制现有对象的状态并留存副本,方便快速地回滚到上一次保存或最初的状态,避免因网络延迟、误操作等原因而造成数据的不可恢复。
优缺点
使用原型模式主要有以下三个大的优点。
-
原型并不基于继承,因此没有继承的缺点
原型模式是对对象的直接复制,当新对象发生变化时,并不会对原始对象有任何影响,
而继承的对象一旦发生了修改则会影响到父类。
-
复制大对象时,性能更优
比如,Java 使用的原型模式是基于内存二进制流的拷贝,
而直接 new 一个大对象是 JVM 进行堆内分配并可能触发 Full GC,
相比之下,使用 new 关键字时所做的操作实际上更多,
而使用内存拷贝的方式在复制的性能上会更优。
-
可以快速扩展运行时对象的属性和方法
原型模式一方面简化了对象的创建过程,另一方面能够保留原始的对象状态,
这样的优势是:在程序运行过程中,如果想要动态扩展对象的功能(增减方法或属性值),
可以在不影响原有对象的情况下,动态扩展对象的功能
比如,结合 AOP 切面编程可以实现录制业务调用轨迹,加入应用性能监控,做动态数据埋点等操作。
当然,原型模式也不是十全十美的,它也有一些缺点。
-
虽然不基于继承,但原型需要一个被初始化过的正确对象
如果被复制的对象在进行复杂的初始化时失败或出现错误的初始化后,
那么复制的对象也可能是错误的。
-
复制大对象时,可能出现内存溢出的 OOM 错误
虽然复制对象有诸多优点,但是不要忘记内存的大小是有限制的,
如果你想要复制的对象已经占用了 80% 的内存空间,那么复制时大概率会导致内存溢出,
而这时的解决办法要么是增加内存,要么是拆分对象。
-
动态扩展对象功能时可能会掩盖新的风险
虽然原型模式能够在运行时帮助我们快速扩展功能,但同时也可能使新对象的负荷更重。
比如,埋点服务中我们通常会拷贝一份对象在某个时间节点的数据,并添加一些追踪数据后再推送给埋点服务,这样就可能增加过多的内存消耗,影响原有功能执行的性能,有时还可能引起 OOM,导致系统宕机。
切记,如果没有充分验证过动态扩展功能的话,就不要轻易使用动态扩展,因为加入额外的新功能,大概率是会影响原有功能的。
总结
原型模式可以说是创建型模式中灵活性最高的模式,不过在带来灵活性的同时,也带来了更大的风险,这对我们的设计与实现间接提出了更高的要求。
使用原型模式时可能需要我们对 IO 流、内存和 JVM 等一些底层的原理有更加深入的理解才行,
虽然对象的拷贝看上去很容易,但是一旦使用不当,很容易就导致系统直接崩溃,这也是很多开发人员不愿意使用原型模式的原因之一。
但是在很多类库和框架中,随处可见原型模式的身影,
比如,JDK、Netty、Spring 等。如果熟悉前端开发的话,还会发现无论是使用 JavaScript 还是 TypeScript,更是会时常用到原型模式。
原型模式的实现——浅拷贝和深拷贝,本质上都是基于性能优化角度来更好地实现拷贝功能,只不过实现方式和使用场景有所不同而已。
等决定了要采用原型模式后,再考虑使用哪种方式会更加合适。
况且很多开源框架和组件里都有相关实现,并不一定非要从零去实现浅拷贝或深拷贝,
比如,Apache Common 包中的 deepCopy,
还有 Spring 中的 BenUtils.copyProperties 等
到此,创建型设计模式就学习完了,下面来简单总结一下这五个创建型模式。
-
单例模式(Singleton),类似于一种技巧,是工厂模式一种数量上的特例,相当于强制实现了有限、唯一对象的生产。
-
建造者模式(Builder),侧重点在于如何实现对象创建过程的自由组合,避免在代码中出现大量 new 式的硬编码。
当对象结构发生改变时,能灵活增删步骤节点,还能避免对程序中大量分散 new 语句的修改。换句话说,它实现了对象创建过程的多态。
-
抽象工厂模式(Abstract Factory),重点是创建一组实现统一抽象产品的工厂对象族(同一个逻辑层级),本质上是为了寻找正确的抽象产品。它可以很好地保证被创建对象的工厂之间的一致性,常常用来解决跨平台的设计问题。
-
工厂方法模式(Factory Method),有效解决了创建对象时的不确定性。使用的办法就是将创建对象的时机延迟到了每一个具体的创建工厂中,让具体工厂自行解决对象的复杂创建过程,并通过统一的定义接口来保证创建对象时的可任意替换性。换句话说,它实现了对象创建时的多态。
-
原型模式(Prototype),就是一种将对象生成的责任代理给自己的模式,也就是“复制自我”。通过复制能快速建立运行的对象副本,最大的作用在于动态扩展运行时的对象能力。换句话说,它实现了对象拷贝的多态。
总结成一句话就是
当软件系统中需要对象的创建、组合或聚集时,就可以考虑使用创建型模式“家族”来帮助提升代码的灵活性。