环境安装步骤
5.2.2安装NVIDIA驱动
1.输入sudo gedit /etc/modprobe.d/blacklist.conf 用编辑器打开blacklist.conf配置文件

图5-16 修改blacklist
2.在文件的最后一行加入下面的命令,屏蔽有影响的驱动包
blacklist nouveau
options nouveau modeset=0
加入后按ctrl+s保存,之后关闭
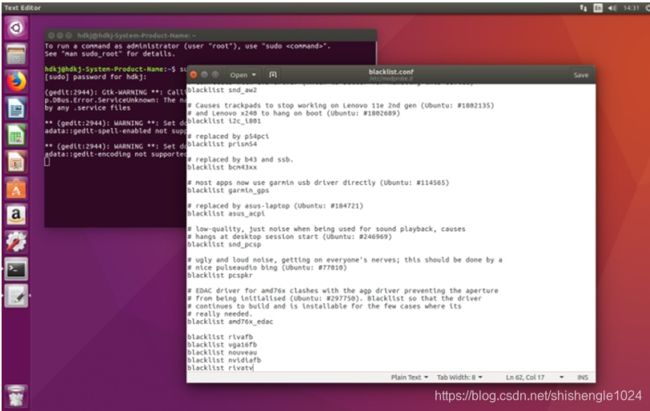
图5-17 需要加入的内容
3.输入sudo update-initramfs –u 更新linux内核
![]()
图5-18 更新内核
4.输入reboot重新启动
![]()
图5-19 重新启动
5.重启后,按Ctrl+Alt+F1进入命令提示符界面,输入对应的username和passwd进入命令行
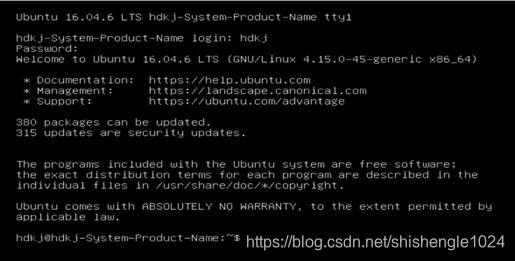
图5-20 命令提示符界面
6.输入指令:sudo service lightdm stop 关闭图形界面,再使用cd指令进入包目录,输入sudo chmod 755 NVIDIA-Linux-x86_64-440.82.run修改run文件权限

图5-21 安装前所需的操作
7. 输入sudo ./NVIDIA-Linux-x86_64-440.82.run –no-x-check –no-nouveau-check –no-opengl-files 安装驱 动
![]()
图5-22 安装NVIDIA驱动
8.等待后,发现预安装错误询问是否继续,选择continue installation

图5-23 预安装警告
9.询问是否安装DKMS,选择NO

图5-24 不安装DKMS
10. 警告兼容问题,选择OK继续

图5-25 兼容警告
11.询问是否启用nvidia配置文件,选择yes

图5-26 启用nvidia配置文件
12. 安装成功,选择OK

图5-27 安装成功
13.输入sudo service lightdm start打开图形化界面
![]()
图5-28 打开图形化界面
14.使用nvidia-smi查询是否成功挂载
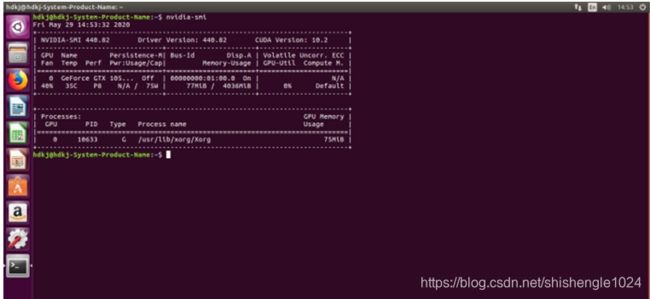
图5-29 查询是否成功安装
5.2.3安装CUDA
1.使用cd命令进入目录后,输入sudo sh cuda_10.0.130_410.48_linux.run 开始安装CUDA
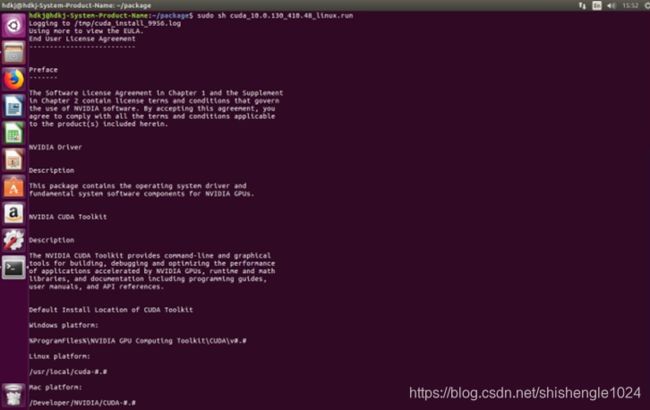
图5-30 运行CUDA的run文件
2.阅读安装须知后(使用enter键换行,使用space键翻页),按图中的选择后即可成功安装CUDA, 每次选择依次为 accept,n,y,y,y

图5-31 阅读安装须知
3.安装后,输入nvcc -V查询CUDA是否安装成功
或者cat /usr/local/cuda/version.txt

图5-32 查询是否安装成功
5.2.4安装cudnn
1.使用终端进入包目录后,输入tar –xzvf cudnn-10.0-linux-x64-v7.6.5.32.tgz 解压cudnn包文件
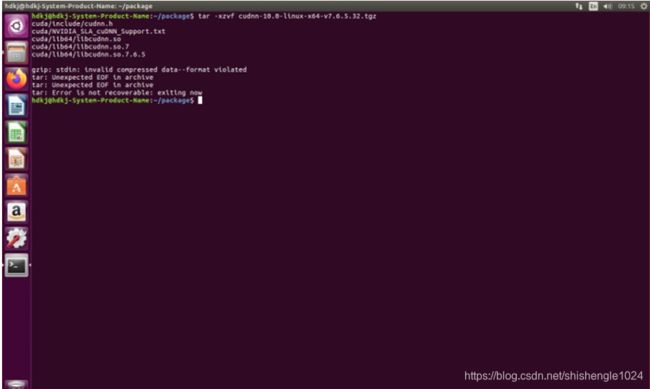
图5-33 解压CUDNN包
2.依次输入
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
将所需文件复制到CUDA文件夹中并授权

图5-34 复制包中内容并授权
3.输入 cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2 查看cudnn版本
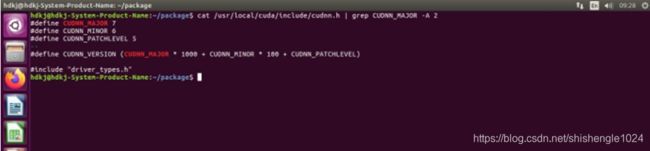
图5-35 查看是否安装成功
5.2.5安装anaconda
1.进入包目录后输入bash Anaconda3-2020.02-Linux-x86_64.sh

图5-36 运行anaconda安装包
2.按下回车后开始阅读安装须知

图5-37 安装须知
3.阅读后询问是否接受条款,输入yes,之后选择安装位置,使用默认位置即可
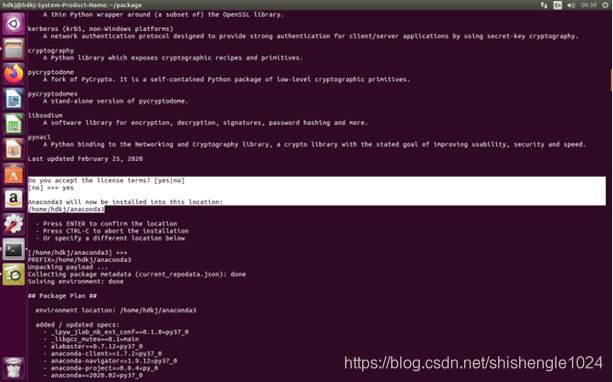
图5-38 接受条款
4.询问是否添加环境变量,输入yes,之后安装完成

图5-39 添加环境
5.关闭终端后,再次打开终端命令行的前方出现(base)表示安装成功,由于此试验台不使用Jupyter命令,所以输入conda config --set auto_activate_base False 关闭base

图5-40 关闭base
6.输入后再次打开终端,发现前面的base消失
5.2.6安装pytorch
1.输入conda create -n hdkj python=3.7,创建虚拟环境
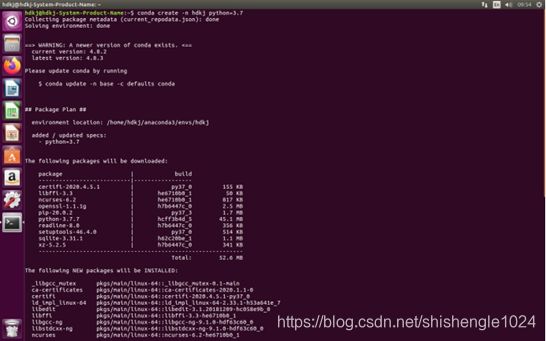
图5-41 建立虚拟环境
2.询问是否继续,输入y继续
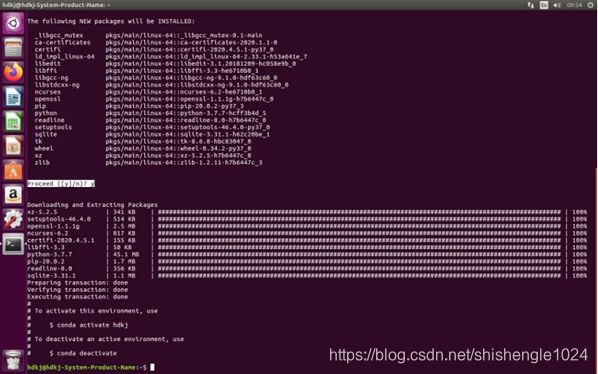
图5-42 继续安装
3.进入包目录后,输入conda activate hdkj ,激活虚拟环境,前方有(hdkj)表示激活成功
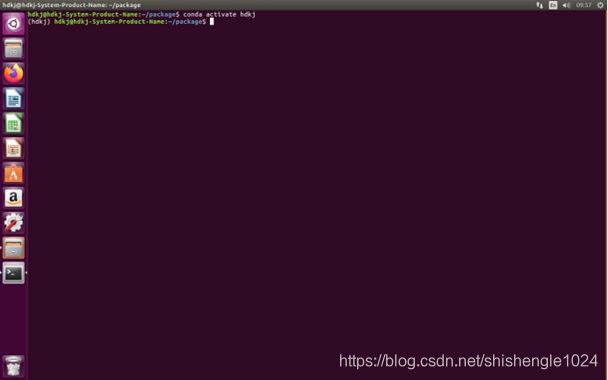
图5-43 激活环境
4.输入pip install torch-1.1.0-cp37-cp37m-linux_x86_64.whl 安装pytorch
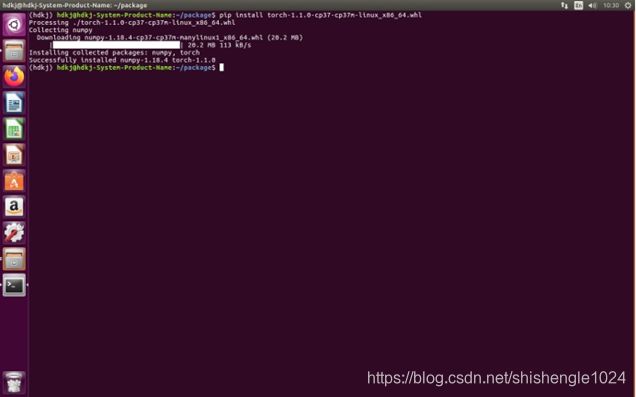
图5-44 安装pytorch
5.安装成功后,输入pip install torchvision-0.3.0-cp37-cp37m-linux_x86_64.whl 安装torchvision
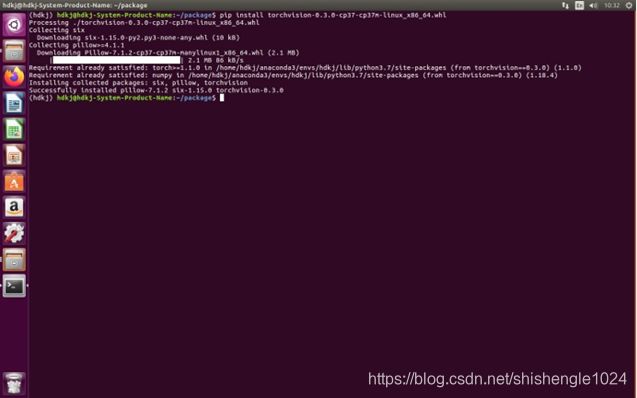
图5-45 安装torchvision
6.输入pip list查看是否安装成功
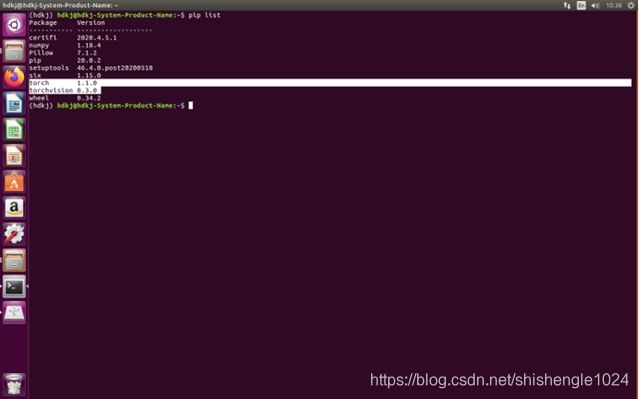
图5-46 查看库列表
5.2.7安装mmec
1.进入包目录后,输入unzip mmcv-master.zip 解压mmcv包
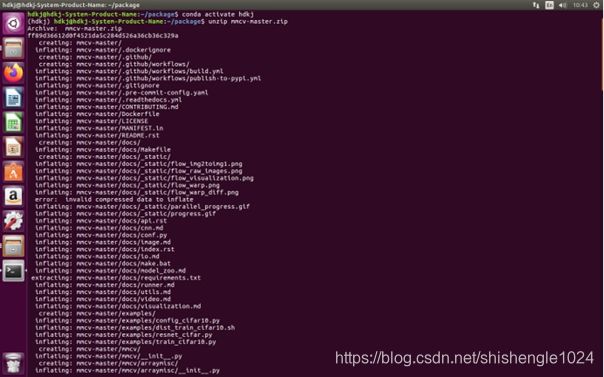
图5-47 解压mmec
2.进入mmcv-master目录,输入“pip install . ”安装mmcv
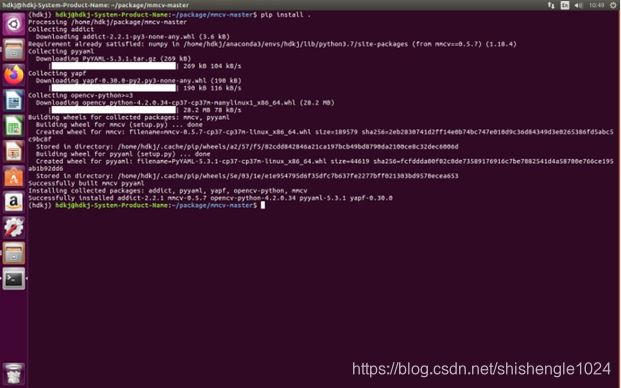
图5-48 安装mmcv
3.输入pip list查看是否安装成功
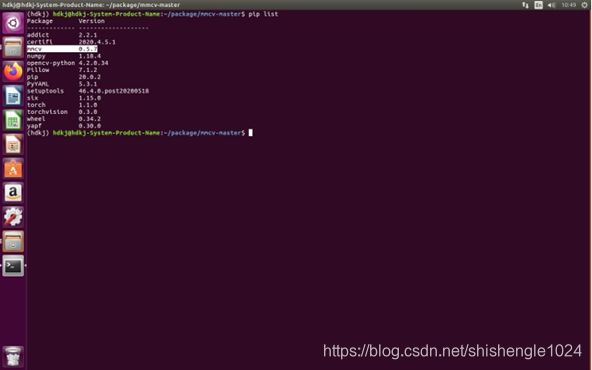
图5-49 查看是否安装成功
5.2.8安装mmdetection
1.进入包目录后,输入unzip mmdetection.zip 解压mmdetection包

图5-50 解压mmdetection包
2.激活环境后不需要改变目录,输入python setup.py develop
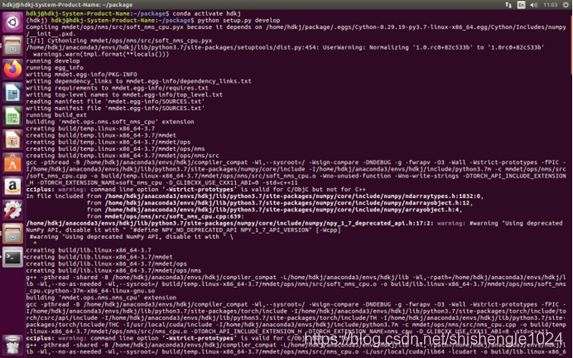
图5-51 安装mmdetection
3.输入pip list查看是否安装成功
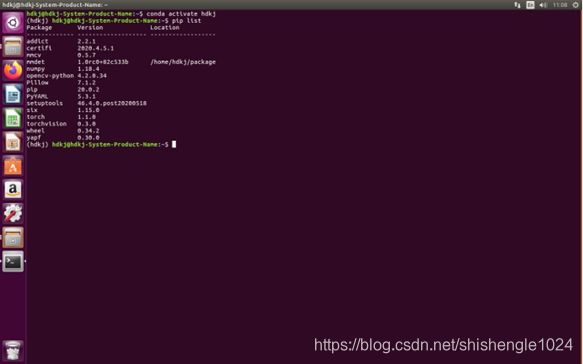
图5-52 查看是否安装成功
5.2.9安装其余所需要的库
1.其他需要的库包括
appdirs,chardet,click,cycler,Cython,decorator,Flask,idna,imagecodecs,imageio
imgaug,intel-openmp,mkl,opencv-python-headless,packaging,pooch,pycocotools
setuptools,terminaltables
以上所有的库在激活环境后,输入pip install –r requestments.txt –i https://pypi.tuna.tsinghua.edu.cn/simple some-package即可完成安装
2.安装过后输入pip list与下图进行比对,若一致则环境已安装完毕
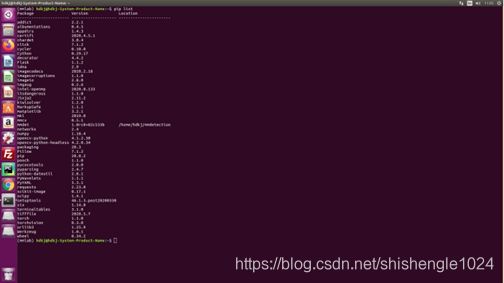
图5-53 配置完毕的库列表
5.2.10安装pycharm
1.进入目录后,输入tar –zxvf pycharm-community-2020.1.1.tar.gz 解压缩

图5-54 解压pycharm安装包
2.输入sudo mv pycharm-community-2020.1.1/ /opt 将解压缩后的目录移动到 /opt 目录下
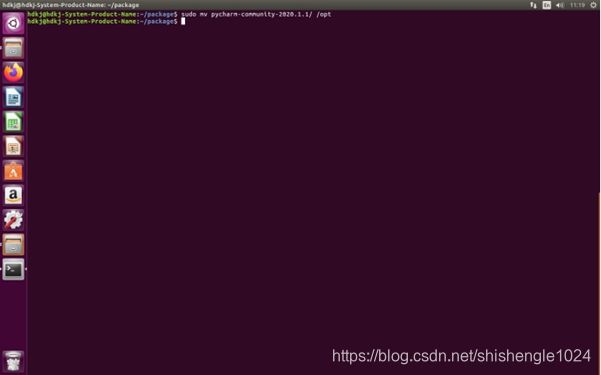
图5-55 复制包中文件
3.启动pycharm.sh
输入命令/opt/pycharm-community-2020.1.1/bin/pycharm.sh

图5-56 启动pycharm.sh
4.按照步骤安装完成后,出现pycharm主界面,选择Create New Project

图5-57 创建新项目
5.在此处我们选择Existing interpreter,之后点击右侧的”…”按钮
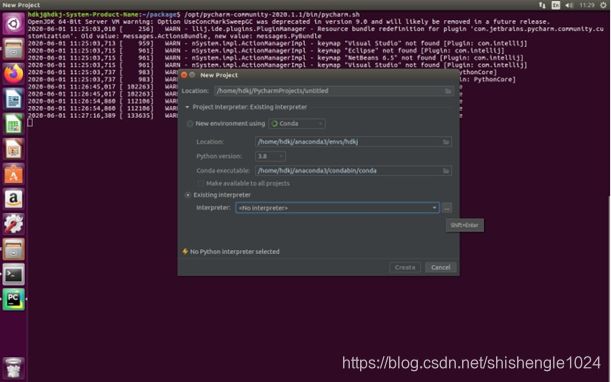
图5-58 Existing interpreter
6.点击Conda Environment,选择之前创建的环境hdkj,之后点击“OK”
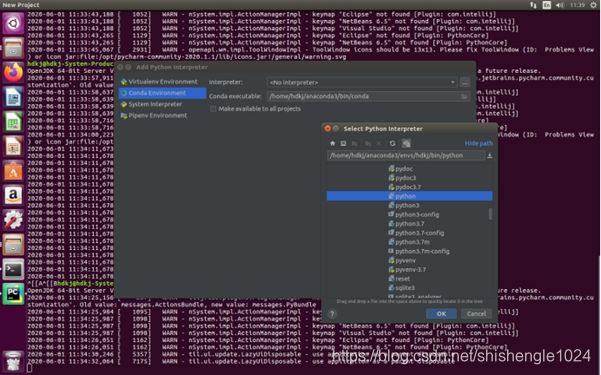
图5-59 Conda Environment
7.点击后返回New Project窗口,选择项目路径,之后点击Create,创建后,之前创建的环境即可在pycharm中进行使用
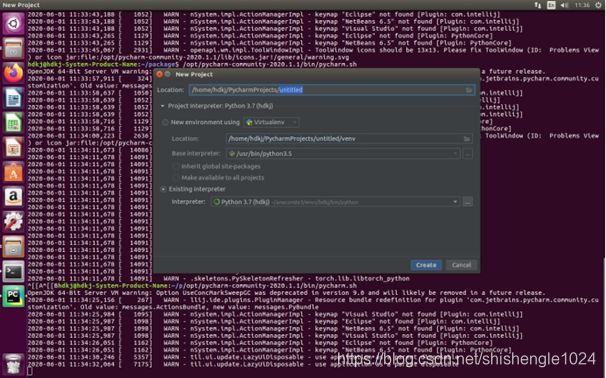
5.2.11换元方法
1.在home下创建文件夹.pip,在其中新建document,命名为pip.conf。想其中输入内容
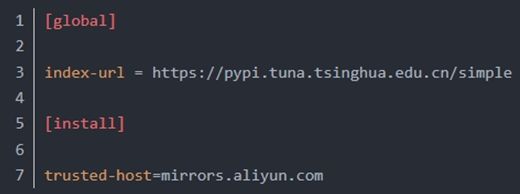
5.2.12离线安装环境
- 安装nvidia显卡驱动
- 安装cuda
- 安装cudnn
- 安装anaconda
- 复制base环境,命令为
conda create -n hdkj --clone base
- 安装requirement.txt中其余库,注意顺序,每一个都用离线包安装
- 安装torch与torchvision库
- 安装mmcv,同样使用离线包安装
- 安装mmdetection
- 安装pycharm
5.2.13安装google浏览器
进入包目录后,输入命令sudo dpkg –i google-chrmoe-stable_current_amd64.deb
若出现dpkg: error: dpkg status database is locked by another process
输入
(1)sudo rm /var/lib/dpkg/lock
(2)sudo dpkg --configure -a
5.2.14下载的resnet50-19c8e357.pth存放位置
存放在/home/hdkj/.cache/torch/checkpoints
5.2.15 修改开机启动项
进入第一个系统后依次输入三个命令
sudo add-apt-repository ppa:danielrichter2007/grub-customizer
这个命令最后要显示OK
sudo apt-get update
sudo apt-get install grub-customizer
之后在系统中搜索grub,点击那个图像化的软件,在里面修改即可
5.2.16 Ubuntu修改默认Python
sudo rm /usr/bin/python
sudo ln –s /usr/bin/python3.5 /usr/bin/python
5.2.17采集平台自启动
1.将collection_restart.sh放入home下
2.左上角搜索Startup Applications
3.打开应用,之后点击Add,Name框中输入collection_restart.sh,command点击Browse,之后选择collection_restart.sh,comment这一行不用写,之后点击Add,然后关掉
4.打开终端输入sudo chmod 777 collection_restart.sh
5.2.18标注平台自启动
在启动服务输入--restart=always
5.2 使用环境
第一步,环境创建成功后,自定目录创建文件夹用于放置训练所需的数据,例子中文件名为dataset

图5-61 创建数据集目录
第二步,文件夹中包含三个子文件夹,文件名自定,例子中文件夹名为Annotations,ImageSets,JPEGimages
图5-62 数据集中的子文件夹
第三步,Annotations文件夹中内容为在标注平台上下载的标注文件,此时需保留xml文件,删除所有json文件
图5-63 下载好的数据
第四步,ImageSets文件夹内容为名称为train与test的两个txt文件
图5-64 定义训练数据集与测试数据集
文件内容分别为train数据集与test数据集的图片文件名

(a)

(b)
图5-65 文本中的内容
第五步,JPEGimages文件夹内容为端侧应用开发平台采集的商品图片
图5-66 采集的图片
第六步,更改mmdetection/mmdet/datasets 中my_dataset.py与voc.py中的标签名称与标签个数
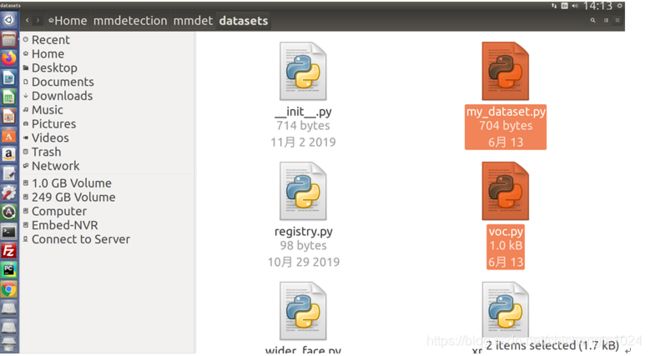
图5-67 修改my_dataset.py与voc.py
其中my_dataset中需将下图的类别改为自己训练的类别

图5-68 修改my_dataset.py
在voc.py同样需将下图的类别改为自己训练的类别

图5-69 修改voc.py
第七步,修改mmdetection/mmdet/datasets中__init__.py

图5-70 文件__init__.py
导入部分末尾增加一行:from .my_dataset import MyDataset

图5-71 加入一行
之后文件在最下面的 all =[ ]中加入: 'MyDataset'
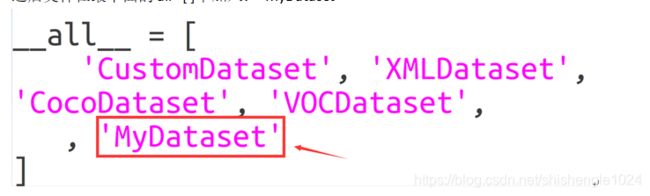
图5-72 加入MyDataset
第八步,选择需要的算法,例中算法为faster_rcnn_r50_fpn_1x,文件位于mmdetection/configs/faster_rcnn_r50_fpn_1x.py
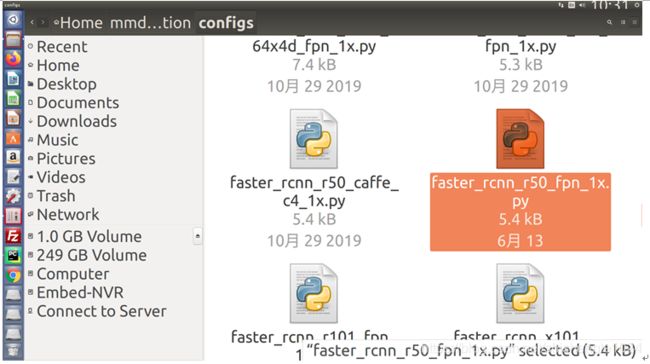
图5-73 faster_rcnn_r50_fpn_1x
需要修改的内容为: 第40行,num_classes = 4, 标注的类别数+1
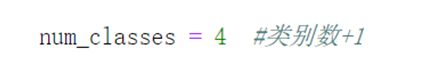
图5-74 第40行
第101行,dataset_type = 'MyDateset'
![]()
图5-75 第101行
第102行,data_root = '/media/zs/data/' 修改为自己的数据根目录

图5-76 第102行
第135行,ann_file = data_root + 'face_2/ImageSets/Main/train.txt' 修改为自己实际的文件路径
![]()
图5-77 第135行
第136行,img_prefix = data_root + 'face_1/'修改为自己实际的文件路径
![]()
图5-78 第136行
第145行,ann_file = data_root + 'face_2/ImageSets/Main/test.txt'修改为自己实际的文件路径
![]()
图5-79 第145行
第146行,img_prefix = data_root + 'face_2/'修改为自己实际的文件路径
![]()
图5-80 第146行
第171行,work_dir = '../work_dirs/face_2/' 模型和日志保存的路径
![]()
图5-81第171行
第九步,修改mmdetection/tools 中train.py对数据集进行训练,之后进行训练
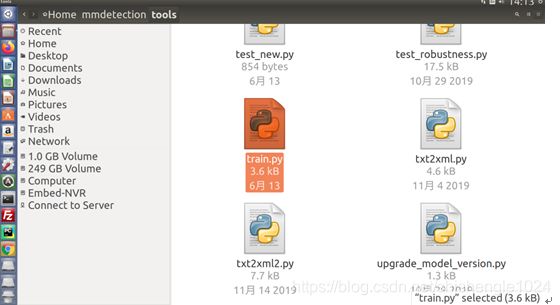
图5-82 使用train.py
需修改的内容有,第17行,parser.add_argument('--config', help='train config file path', default='/home/zs/mmdetection/configs/faster_rcnn_r50_fpn_1x.py')
![]()
图5-83 第17行
第18行,parser.add_argument('--work_dir', help='the dir to save logs and models',default='/home/zs/mmdetection/configs/faster_rcnn_r50_fpn_1x.py')
![]()
图5-84 第18行
训练结束后在mmdetection/work_dirs/faster_rcnn_r50_fpn_1x中会得到训练模型pth文件
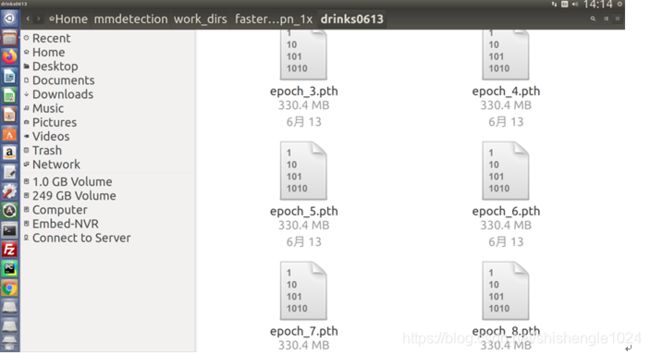
图5-85 训练完毕的pth文件
如需测试训练好的pth文件则需先修改再运行mmdetection/tools/test.py文件
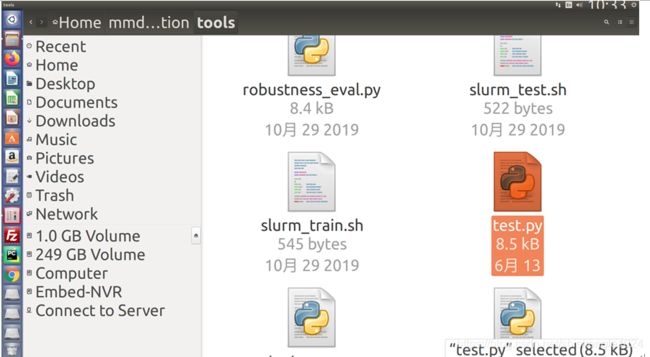
图5-86 test.py
需修改第107行,parser.add_argument('--config', help='test config file path', default='/home/zs/mmdetection/configs/faster_rcnn_r50_fpn_1x.py',type=str)
![]()
图5-87 第107行
第108行,parser.add_argument('--checkpoint', help='checkpoint file', default='/home/zs/mmdetection/work_dirs/face_2/epoch_1.pth',type=str)
![]()
图5-88 第108行
如需显示检测结果,在第120行,parser.add_argument('--show', action='store_true', default='True')
![]()
图5-89 第120行
6.1 微服务
6.1.1微服务简介
微服务是一个新兴的软件架构,就是把一个大型的单个应用程序和服务拆分为数十个的支持微服务。一个微服务的策略可以让工作变得更为简便,它可扩展单个组件而不是整个的应用程序堆栈,从而满足服务等级协议。
对于大型应用程序来说,增加更多的用户则意味着提供更大型的弹性计算云(EC2)实例规模,即便只是其中的一些功能扩大了规模亦是如此。其最终结果就是企业用户只需为支持超过微服务的那部分需求的EC2实例支付费用。
微服务应用的一个最大的优点是,它们往往比传统的应用程序更有效地利用计算资源。这是因为它们通过扩展组件来处理性能瓶颈问题。这样一来,开发人员只需要为额外的组件部署计算资源,而不需要部署一个完整的应用程序的全新迭代。最终的结果是有更多的资源可以提供给其它任务。
微服务应用程序的另一个好处是,它们更快且更容易更新。当开发者对一个传统的单体应用程序进行变更时,他们必须做详细的QA测试,以确保变更不会影响其他特性或功能。但有了微服务,开发者可以更新应用程序的单个组件,而不会影响其他的部分。测试微服务应用程序仍然是必需的,但它更容易识别和隔离问题,从而加快开发速度并支持DevOps和持续应用程序开发。
第三个好处是,微服务架构有助于新兴的云服务,如事件驱动计算。类似AWS Lambda这样的功能让开发人员能够编写代码处于休眠状态,直到应用程序事件触发。事件处理时才需要使用计算资源,而企业只需要为每次事件,而不是固定数目的计算实例支付。
平台中微服务使用Flask作为框架。Flask是由python实现的一个web微框架,让我们可以使用Python语言快速实现一个网站或Web服务。flask诞生于2010年,是Armin ronacher用python语言基于Werkzeug工具箱编写的轻量级Wed开发框架,它本身相当于一个内核,其他几乎所有的功能都需要用扩展,例如:邮箱扩展:Flask-Mail; 用户认证:Flask-Login; 数据库Flask_SQLAlchemy。第三方扩展工具如:ORM,窗体验证工具,文件上传,身份验证等。Flask没有默认的数据库,可以用Myaql,或者Nosql。
6.1.2使用微服务
使用模型训练开发平台中mmdetection/server的HDserver.py,此步骤使用Flask建立模型训练平台与端侧应用开发平台的通讯

图6-1 开启通讯
6.2 使用模型进行识别
第一步,操作端侧应用开发平台,运行调用模型的文件,例中文件为55.py(即retail.py文件)

图6-2 打开调用文件夹
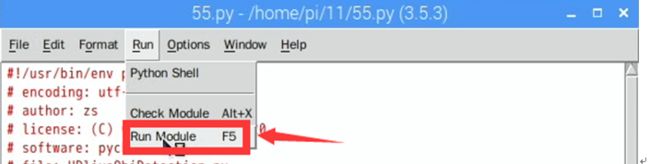
图6-3 运行调用文件
第二步,运行代码后,调整其代码至界面符合要求。如识别结果并不理想,检查前面所进行过的操作,找出错误点
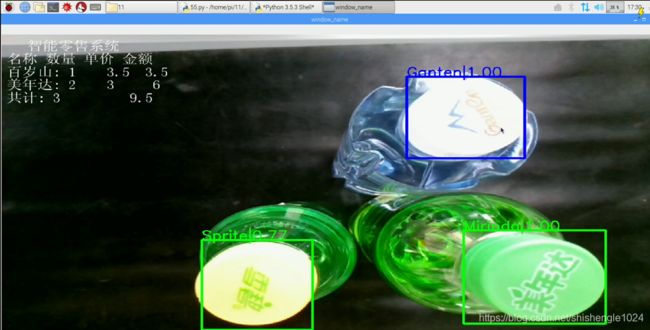
图6-4 装调运维
6.3使用识别结果控制其他设备
6.3.1舵机
我们可以通过模型识别的结果使用端侧开发板中的GPIO接口控制舵机,舵机上有三个引脚分别为VCC,GND与Signal,平台中舵机的Signal接口与端侧开发板扩展板的GPIO25接口相连。在代码中我们使用两个python库RPi.GPIO与time。
首先我们开启微服务获取识别信号,之后定义舵机的端口号,端口号为25,设置参数语句为
servopin = 25
定义参数后,设置GPIO引脚编号的模式(BCM格式)
GPIO.setmode(GPIO.BCM)
设置引脚状态及初始类型
GPIO.setup(servopin,GPIO.OUT,initial=False)
设置频率为50KHZ
pwm = GPIO.PWM(servopin,50)
设置占空比为0
pwm.start(0)
通过用户输入的角度来改变舵机的角度
p.ChangeDutyCycle(2.5+r/360*20)
6.3.2指示灯
同理我们使用识别的结果控制指示灯的亮灭,指示灯的接线方式正极接5V电源,红色指示灯,黄色指示灯,绿色指示灯的负极分别接串口继电器OUT2,OUT3与OUT4的3号端口,在串口继电器对应输出OUT2,OUT3,OUT4的输入为IN2,IN3,IN4,IN2,IN3,IN4分别与端侧开发板扩展版中的GPIO18,GPIO23,GPIO24相连,当我们打开设备的时候,端侧开发板GPIO18,GPIO23,GPIO24为低电平,平台上指示灯为亮状态。由此指示灯的控制方式为:高电平——灭,低电平——亮。
在控制指示灯代码中,首先开启微服务获取识别信号,之后定义指示灯的端口号,红色指示灯,黄色指示灯,绿色指示灯端口号分别为18,23,24,之后设置GPIO模式,其语句为
GPIO.Setmode(GPIO.BOARD)
此处以黄色指示灯为例设置提示灯的输出方式,其语句为
GPIO.setup(23,GPIO.OUT)
之后控制GPIO端口的高低电平即可控制指示灯的状态。语句为暗状态
GPIO.output(23,GPIO.HIGH)
前如想将指示灯置为亮状态,则使用
GPIO.output(23,GPIO.LOW)
6.3.3HMI串口屏
在实训平台中放置了HMI串口屏,串口屏同样可以接受模型识别信号做出相应的响应,下图为HMI串口屏显示画面。

图6-5 HMI串口屏界面
其中x0,x1,x2,x3,x4数据类型为浮点数,以x0为例改变变量x0命令为x0.val = 35,则x0显示处显示为3.5。
n5,n6,n7,n8,n9数据类型为整形,以n5为例改变变量n5命令为n0.val = 35,则x0显示处显示为35。
t0,t1,t2,t3,t4数据类型为字符串,以t0为例改变变量t0命令为t0.txt = 35,则x0显示处显示为35。
HMI串口屏的控制引脚为端侧开发板扩展板中的TXD0与RXD0即串口的发送与接收,在python中使用的库为serial库,首先设置波特率,端侧开发板的波特率为9600,其语句为
ser = serial.Serial('/dev/ttyAMA0', 9600)
之后打开串口,其语句为
ser.open()
之后对模型识别的数据类型进行修改,最终使HMI串口屏接收到相应的数据,之后显示在串口屏上。语句以n5举例
uart5 = "n5.val=" + str(num)
ser.write((uart5).encode("utf-8"))
ser.write(b'\xFF\xFF\xFF')