16.认识下Docker之docker的核心原理(1)
1.简介
到现在为止,关于docker的内容也写了10篇博客了,对于一个服务端开发者来说,我认为也基本够用了,剩下的就是去多看官方文档、多实践。现在呢,我想回过头来再重新认识下docker,重新认识下容器,看看docker的核心原理到底是什么。在这个专栏的第一篇,我也写了一个认识下docker的博客,那也就仅仅是个大篇幅的文字介绍和我自己在使用过程中的一些心得而已,并没有深入的去理解深挖 。下面就深挖一下吧,写的不对的地方,还请指正。
2.busybox镜像-Linux命令和工具的精简工具集
为什么在这里介绍busybox这个镜像,因为在这篇博客中,我主要使用这个镜像来启动容器做相关的演示,所以先介绍一下它。
busybox是一个继承了一百多个最常用Linux命令了工具(如cat、echo、grep、mount、telnet等)的精简工具集。它很小,很方便进行各种快速验证。
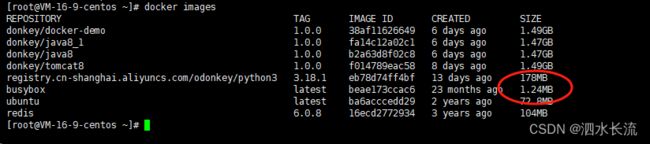
所以我们看到,它特别轻巧。
3.Namespace技术-Linux容器的隔离技术
3.1 示例
说到docker等容器技术,那么namespace技术是一个迈不过去的知识点。我们说docker容器之间相互隔离,其实就是用了namespace技术来实现的。
我们先run一个busybox的容器
docker run -it busybox /bin/sh
然后在容器内部执行ps -A,查看所有进程

我们看到有一个PID=1的一号进程,就是我们在容器里指定的 bin/sh,那么这就表示了我们的进程在一个新的操作系统中运行了。但事实是这样么?
我们在宿主机中执行以下命令:
docker ps
docker top optimistic_lalande

可以看到,在docker容器中运行的PID=1d的进程,其实是宿主机上的一个PID=27192进程的进程。那这肯定说明了有一个进程号PID假的,很显然那就是容器中的PID=1的这个进程号是假的。所以所谓的隔离,其实就象是给容器蒙蔽了双眼,本来宿主机上有很多进程,但是在容器内我只让你看到你应该看到的。就拿这个例子来说,容器就能让你看到宿主机上的PID=27192这个进程,并且容器中重新编号,把它编为1号进程PID=1。
这就是Linux里面的Namespace技术或者机制。
3.2 原理解释
在Linux中创建进程,我们使用的下面的函数调用:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
这里我解释一下这面这段代码,它使用Linux系统中的clone()系统调用创建一个新的进程,并指定了main_function作为新进程的执行函数,stack_size作为新进程的栈大小,CLONE_NEWPID | SIGCHLD作为新进程的标志,NULL作为可选的参数。这个系统调用会返回新进程的进程号pid。在这段代码中,clone()系统调用创建了一个新的进程,并且返回了它的进程号pid。这个新进程会执行main_function函数,并且具有指定的新进程标志和栈大小。 **CLONE_NEWPID标志表示创建一个新的进程空间,新进程会看到一个全新的进程空间,在这个进程空间里,它的PID是1。**SIGCHLD用于指定信号标志。
除了上面所介绍的PID Namespace,还有Mount Namespace、UTS Namespace、Network Namespace和 User Namespace,用来对不同的进程进行上下文进行隔离操作,其实就是蒙蔽容器内部的双眼。
3.3 小结
所以在创建docker容器进程时,指定了这个容器所需要的一组或者一小撮Namespace参数,容器就只能看到当前限定区域(Namespace)内的资源、文件、设备、状态、用户等等,对于宿主机上不在它区域内的进程,容器就不管了。
这就是Namespace技术最基本的原理,也是docker等容器技术基本的实现原理。所以,容器就是一种特殊的进程。
Namespace技术其实就是修改了app进程看待整个计算机的“视图”,只能看到让它看到的内容,呵呵,这像不像一个社会啊。
4.Cgroups技术—设置资源限制
4.1 为什么要对容器做限制?
从上面的Namespace技术中我们知道,虽然进程在容器中是一个1号进程,可是对应的宿主机上,它和其他进程没有任何区别,都是平等的,也就说,和其他进程都是平等竞争来获取宿主的各种资源。所以一不小心,容器的这个进程也是可以把宿主机的资源给吃光的,所以要给它做限制。
4.2 Cgroups的概念
Namespace技术实现了容器的隔离,而Cgroups则实现了对资源的限制。Linux Cgroups,全称 Linux Control Group,它最主要是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
4.3 原理解释
在Linux中,Cgroups给用户暴露出来的是文件系统,它以文件和目录的方式放在/sys/fs/cgroup/的目录下,可以使用mount -t cgroup 命令把它们全部给列出来
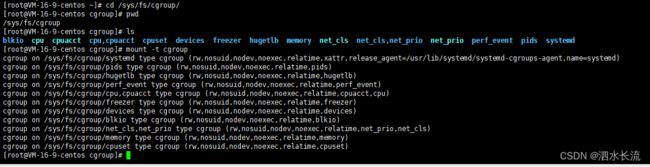
可以看到,在 /sys/fs/cgroup 目录下有cpu、memory、cpuset、net_cls等待那个 这样的子目录,这些都是当前这台机器可以被 Cgroups 进行限制的资源种类。而在各个子目录中国,我们能看到该类资源具体可以被限制的方法。这里我拿CPU 这个目录来说,我们就可以看到如下几个配置文件
ls /sys/fs/cgroup/cpu
![]()
我在这里创建一个mycontainer的目录,创建完成后,我看一看到在这个mycontainer目录下,生成了一系列的文件
mkdir mycontainer
ls /sys/fs/cgroup/cpu/mycontainer/

这个mycontainer目录就可以看成是一个限制组,这些文件就是该限制组对应的资源限制文件。下面我做个简单示例
在linux上我写了一个hello_world.sh的脚本,无限循环打印“hello world”
#!/bin/bash
while true
do
echo "hello world"
done
设置下权限
chmod +x hello_world.sh
这是一个死循环,可以把机器的cpu拉的很高,下面我执行这个shell脚本
. hello_world.sh
我们看到在疯狂打印。使用top 命令,我们看到这个进程和相应的cpu情况
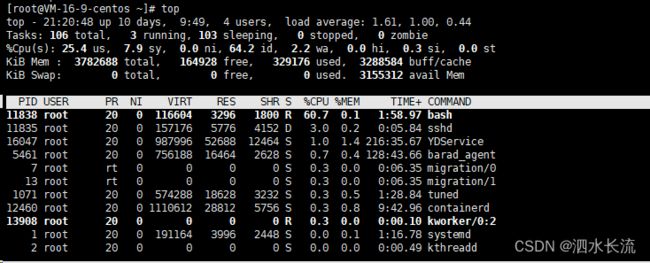
可以看到这个进程号是PID=11838,CPU的使用率很高。下面我修改下mycontainer限制组中的cpu的设置,来限制这个进程使用的cpu。
echo 10000 > /sys/fs/cgroup/cpu/mycontainer/cpu.cfs_quota_us

这一意味着在每100ms 的时间里,被该控制组限制的进程只能使用10ms 的 CPU 时间,也就是说这个进程只能使用到 10% 的 CPU 。
设置完成后,我把PID=11838这个进程号设置到mycontainer目录下的tasks文件中
echo 11838 > /sys/fs/cgroup/cpu/mycontainer/tasks
cat /sys/fs/cgroup/cpu/mycontainer/tasks

那这时候我们再来看cpu的使用情况
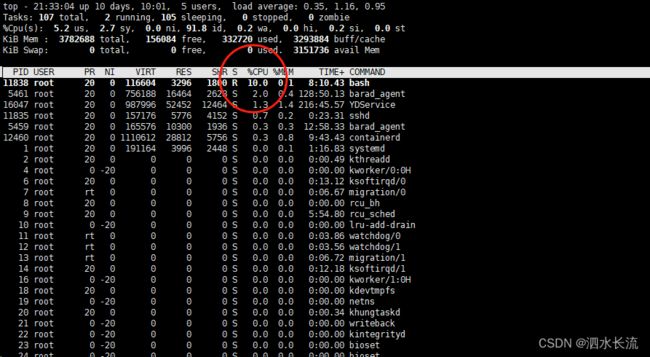
是不是很神奇啊,PID=11838这个进程的cpu使用率基本最高就10%。
除了CPU,Cgroups还能给其他资源提供限制能力,常见的memory,为进程设定内存使用的限制。
所以,docker容器对资源限制的原理也很简单,利用Cgroups技术,只需要为docker容器创建一个限制组(目录),启动容器进程以后,把这个进程ID,也就是PID填写到对应控制组的tasks文件中就可以了。
4.4 小插曲
上面示例完成了,我这里把刚创建的mycontainer给删除掉
cd /sys/fs/cgroup/cpu
rm -rf mycontainer/

哈哈,很遗憾,没有删除成功。那怎么办呢?
我们先查看这个文件:
cat /sys/fs/cgroup/cpu/mycontainer/tasks

然后执行下面的命令:
rmdir mycontainer/
![]()
还是很遗憾,没有删除成功。
这里我们先查看一下tasks文件内容:
cat /sys/fs/cgroup/cpu/mycontainer/tasks

里面有三个进程号,我把这三个进程都给kill掉
kill -9 11838 20397 14853
然后再执行删除:
rmdir /sys/fs/cgroup/cpu/mycontainer

这次删除成功了。
5.docker容器采用Namespace的缺陷
docker容器由于采用的Namespace,所以使得它非常轻巧,但是这也给它带来了一些缺陷。最主要是因为Namespace的隔离不彻底。
第一、容器使用的Linux宿主机的内核,如果想要再windows宿主机或者低版本的Linux宿主机上运行高版本的Linux容器,这都办不到;这也是他和虚拟机很大的差别之一;
第二、在Linux内核中,不是所有的资源都可以被Namespace化,比如时间等,这也就意味着,如果在容器中更改了时间,那么宿主机的时间也会改变;而在虚拟机中,这种情况是不存在。
6.对docker容器的理解
通过上面对Namespace和Cgoups技术的简单剖析可以得出,一个运行的docker容器,就是一个启用了Linux中多个Namespace的应用级进程,并且这个进程能够使用的宿主机上的资源量,是受Cgroups配置的限制的。
所以我们在使用docker的时候,都是启动一个服务,即一个docker就代表一个服务,而没有把多个服务放在一个docker容器中运行。所以,这样就可以认为一个运行的容器就是一个进程,这个进程对应的就是容器中PID=1的这个进程。
7.对docke容器是单进程容器的理解
我们说docker是单进程模型,并不是说docker容器只能启动一个进程,而是说只有PID=1只有 的进程才会被 Dockerd 控制,即 pid=1 的进程挂了 Dockerd 能够感知到,但是其它的进程却不受 Dockerd 的管理,当出现孤儿进程的时候,管理和调度是个问题。说白了,希望容器和运行在容器的服务的生命周期是完全一致的。
容器和运行在容器的服务使用相同的生命周期,这里的相同,不仅仅是空间上的,而是实时的相同,就是两者要死一起死,要活一起活,生死相许的一种关系。同生命周期,这个概念很重要,特别以后关于容器的编排,因为一旦出现像容器时正常,但是容器中的服务已经死掉了,这就会非常麻烦。
8.总结
花了这么大的篇幅讲了Namespace和Cgroups,我也只是说了一点皮毛。但是通过这个分析 ,我确信自己对容器有了一个更深的理解,哦,原来docker容器不是一个多么神秘的东西,甚至我们自己都可以写一个简单的docker出来,这都是用的Linux现有的技术来做的实现。除了这两个技术,我认为docker最成功的就是引入了镜像,即模板化技术,由于篇幅原因,后面我会专门再写一下docker镜像的一些核心原理。