深入浅出C语言——C语言实现二叉树
文章目录
- 一、树
-
- 1. 树的概念
- 2. 树的存储
- 二、二叉树
-
- 1.概念
- 2. 特殊的二叉树
- 3. 二叉树的性质
- 4. 二叉树的存储结构
- 三、二叉树链式结构的实现
-
- 1. 二叉树的建立
- 2. 二叉树遍历
- 3. 二叉树基本属性
一、树
1. 树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
树的特点
树有一个特殊的结点,称为根结点,根节点没有前驱结点。除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继。 树形结构中,子树之间不能有交集,否则就不是树形结构。另外,要注意树是递归定义的。
树相关的名词
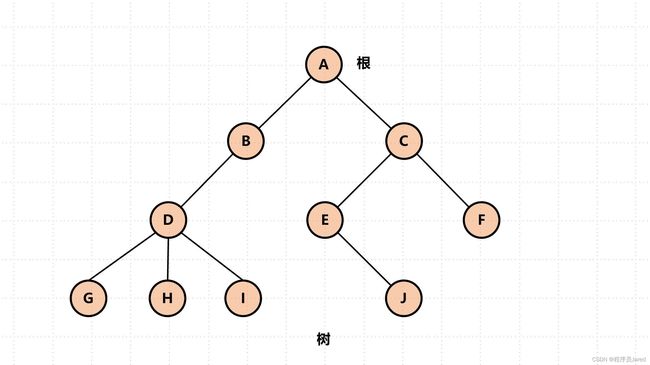
- 节点的度:一个节点含有的子树的个数称为该节点的度; 如上图:A的度为2,D的度为3。
- 叶节点或终端节点:度为0的节点称为叶节点; 如上图:G、H、I、J、F节点为叶节点。
- 非终端节点或分支节点:度不为0的节点; 如上图:D、E、B、C.节点为分支节点。
- 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点。
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点。
- 兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
- 树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为3。
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推。
- 树的高度或深度:树中节点的最大层次; 如上图:树的高度为4。
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:D、E互为兄弟节点。
- 节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先。
-子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙。
-森林:由m(m>0)棵互不相交的树的集合称为森林。
2. 树的存储
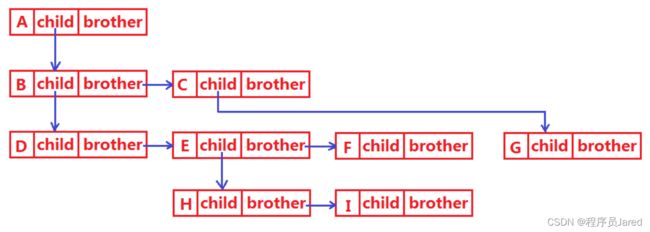
树结构存储既保存值域,也要保存结点和结点之间的关系。实际中树有很多种表示方式如:双亲表示法、孩子表示法、孩子双亲表示法、孩子兄弟表示法…等。其中最常用的孩子兄弟表示法。
typedef int DataType;
struct Node
{
DataType _data; // 结点中的数据域
struct Node* _firstChild1; // 第一个孩子结点
struct Node* _pNextBrother; // 指向其下一个兄弟结点
};
孩子兄弟表示法,即左孩子右兄弟表示法。无论树中一个节点有多少个孩子,都可以表示,因为这个表示法只指向第一个孩子,剩下的孩子,让孩子之间用兄弟指针串起来。
二、二叉树
1.概念
一棵二叉树是结点的一个有限集合,该集合由一个根节点加上两棵分别称为左子树和右子树的二叉树组成或者为空。因为二叉树的这种结构,所以二叉树不存在度大于2的结点。另外,二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树。

2. 特殊的二叉树
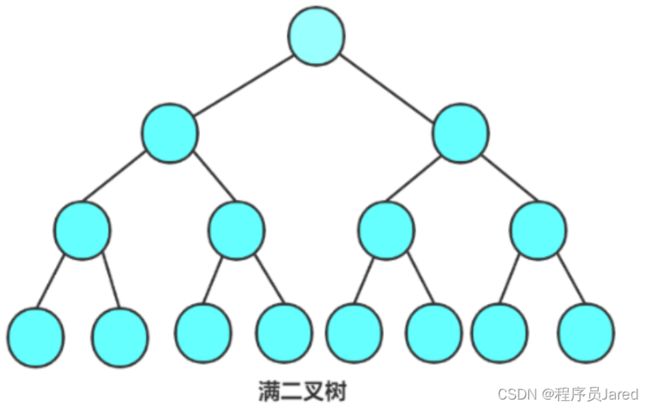
满二叉树
如果一个二叉树的每一个层的结点数都达到最大值,这个二叉树就是满二叉树。假设此二叉树的层数为K,那么它的结点总数是2^k-1。
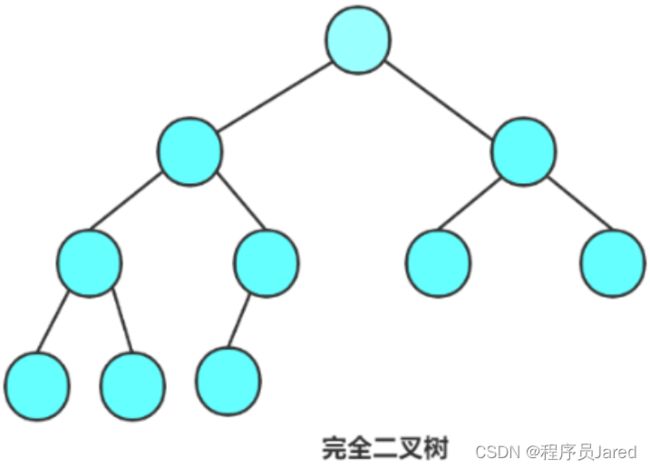
完全二叉树
完全二叉树的前K-1层都是满的,最后一层可以不满,但是从中到右都是连续的,满二叉树是一种特殊的完全二叉树。
3. 二叉树的性质
- 若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个结点。
- 若规定根节点的层数为1,则深度为h的二叉树的最大结点数是(2^h)-1。
- 对任何一棵二叉树, 如果度为0其叶结点个数为n0 , 度为2的分支结点个数为n2 ,则有n0=n2 +1。简言之,度为0比度为2的永远多一个。
- 若规定根节点的层数为1,具有n个结点的满二叉树的深度,h= log2(n+1)。
- 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有以下性质:(1)若i>0,i位置节点的双亲序号:(i-1)/2;i=0,i为根节点编号,无双亲节点。(2)若2i+1
4. 二叉树的存储结构
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
顺序结构存储
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费,而现实中使用中只有堆才会使用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
链式结构存储
二叉树的链式存储结构是用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。
三、二叉树链式结构的实现
数据结构的价值普遍来说就是对数据进行增删改查,普通的二叉树存储数据不如顺序表,链表那么方便,搜索数据的效率也比较低。所以在实际工程中,普通二叉树的增删改查并没有太大的价值。
1. 二叉树的建立
代码实现
typedef int BTDataType;
typedef struct BinaryTreeNode
{
struct BinaryTreeNode* _left;
struct BinaryTreeNode* _right;
BTDataType _data;
}BTNode;
BTNode* BuyNode(BTDataType x)
{
BTNode* node = (BTNode*)malloc(sizeof(BTNode));
assert(node);
node->_data = x;
node->_left = NULL;
node->_right = NULL;
return node;
}
BTNode* CreatBinaryTree()
{
BTNode* node1 = BuyNode(1);
BTNode* node2 = BuyNode(2);
BTNode* node3 = BuyNode(3);
BTNode* node4 = BuyNode(4);
BTNode* node5 = BuyNode(5);
BTNode* node6 = BuyNode(6);
node1->_left = node2;
node1->_right = node4;
node2->_left = node3;
node4->_left = node5;
node4->_right = node6;
return node1;
}
2. 二叉树遍历
遍历是二叉树最重要的运算,也是其他运算的基础。二叉树的遍历是按照那个某种特定的规则,依次对二叉树中的节点进行相应的操作,并且每个节点只操作一次,二叉树的遍历分为四种:
| 1. 前序遍历 | 访问根节点的操作发生在遍历其左右子树之前 |
|---|---|
| 2.中序遍历 | 访问根节点的操作发生在遍历其左右子树之间 |
| 3.后序遍历 | 访问根节点的操作发生在遍历其左右子树之后 |
| 4.层序遍历 | 层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第二层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。 |
由上述表格可以看出前中后序遍历的区别在于访问根的时机。前中后序遍历都符合DFS(深度优先遍历),但是在这三种遍历方式中,前序是最符合DFS的遍历方式。层序遍历符合BFS(广度优先遍历)。
案例
借助2.1节的图片,用@代表空,分别分析前中后序遍历:
- 前序遍历:1 2 3 @ @ @ 4 5 @ @ 6 @ @
- 中序遍历:@ 3 @ 2 @ 1 @ 5 @ 4 @ 6 @
- 后序遍历:@@ 3 @ 2 @ @ 5 @ @ 6 4 1
代码实现
/*
* 递归调用属于分治算法
* 一个函数结束回到它调用的地方,return也是回到它调用的地方
*/
// 二叉树前序遍历
// 根 左子树 右子树
void PreOrder(BTNode* root)
{
if (root == NULL)
{
printf("# ");
return;
}
printf("%d ", root->_data);
PreOrder(root->_left);
PreOrder(root->_right);
}
// 二叉树中序遍历
void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("# ");
return;
}
InOrder(root->_left);
printf("%d ", root->_data);
InOrder(root->_right);
}
// 二叉树后序遍历
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("# ");
return;
}
PostOrder(root->_left);
PostOrder(root->_right);
printf("%d ", root->_data);
}
3. 二叉树基本属性
二叉树的基本属性有节点的总数、叶子节点的个数、节点值的查找、二叉树的深度,这里都统一使用递归来处理。
代码实现
// 二叉树节点个数
int TreeSize(BTNode* root)
{
return root == NULL ? 0
: TreeSize(root->_left)
+ TreeSize(root->_right)
+ 1;
}
// 二叉树叶子节点个数
int TreeLeafSize(BTNode* root)
{
if (root == NULL)
return 0;
if (root->_left == NULL && root->_right == NULL)
return 1;
return TreeLeafSize(root->_left) + TreeLeafSize(root->_right);
}
// 二叉树第k层节点个数
int TreeKLevel(BTNode* root, int k)
{
// 转换成子问题:求左子树的第k-1层+求右子树的第k-1层
assert(k >= 1);
if (root == NULL)
return 0;
if (k == 1)
return 1;
return TreeKLevel(root->_left, k - 1) + TreeKLevel(root->_right, k - 1);
}
// 二叉树查找值为x的节点
BTNode* TreeFind(BTNode* root, BTDataType x)
{
if (root == NULL)
return NULL; //这个Null,不是直接return给最外面的,而是上一层的
// 最好采用前序遍历
if (root->_data == x)
return root;
BTNode* ret1 = TreeFind(root->_left, x);
if (ret1)
return ret1;
BTNode* ret2 = TreeFind(root->_right, x);
if (ret2)
return ret2;
return NULL;
}
// 二叉树的深度
int TreeDepth(BTNode* root)
{
if (root == NULL)
return 0;
int leftDepth = TreeDepth(root->_left);
int rightDepth = TreeDepth(root->_right);
return (leftDepth > rightDepth) ? leftDepth + 1 : rightDepth + 1;
}