KNN实战-图像识别
数据说明
是在循环0-9的数字一直循环500次所得到的数据,然后以手写照片的形式存在
识别的步骤
- 加载数据
- 构建目标值
- 构建模型
- 参数调优
- 可视化展示
加载数据
import numpy as np
import matplotlib.pyplot as plt
# 记载数据
data = np.load('./digit.npy')
data
构建目标值
# 构建基础的目标值
y = list(np.arange(0,10))*500
# 对生成的目标值进行排序,与图片的目标值进行对应
y.sort()
# 为了在拆分数据的时候可以正常拆分
y = np.array(y)
数据处理和数据拆分
数据处理
X = data.reshape(5000,-1)
X.shape # 784:是图片的像素值 ,也就是图像的特征
数据拆分
from sklearn.model_selection import train_test_split
X_tarin,X_test,y_train,y_test = train_test_split(X,y,# x,y的数据
test_size=0.05 # 验证集的占总数据的比重
,random_state=1024 # 随机数的种子)
display(X_tarin.shape,X_test.shape,y_train.shape,y_test.shape)
创建模型
from sklearn.neighbors import KNeighborsClassifier
# 创建模型
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_tarin,y_train)
# 数据分数
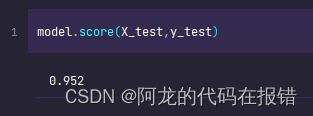
model.score(X_test,y_test)
训练数据的结果的分数
参数调优
%%time
from sklearn.model_selection import GridSearchCV
prams = dict(n_neighbors = [5,7,9,12,15,17,21,23,30],
weights=['uniform','distance'],
p=[1,2])
estimator = KNeighborsClassifier()
gCV = GridSearchCV(estimator,prams,cv=5,scoring='accuracy')
gCV.fit(X_tarin,y_train)

%%time:获取当前程序的运行时间
获取最佳参数
gCV.best_params_
获取平均分数
gCV.best_score_
获取最佳模型
gCV.best_estimator_
数据的验证与预测
best_model = gCV.best_estimator_
y_predict = gCV.predict(X_test)
print('测试值:',y_predict)
print('真实值:',y_test)
best_model.score(X_test,y_test)
得到的结果(在得分上看模型的质量还是有所提升的)

可视化
plt.figure(figsize=(5*2,10*3))
for i in range(50):
plt.subplot(10,5,i+1)
plt.imshow(X_test[i].reshape(28,28))
true = y_test[i]
predict = y_predict[i]
plt.title(f'true:{true}\n'+f'predict:{predict}')

坚持学习,整理复盘
