NoSQL大数据存储技术思考题及参考答案
思考题及参考答案
第1章 绪论
1. NoSQL和关系型数据库在设计目标上有何主要区别?
(1)关系数据库
优势:以完善的关系代数理论作为基础,具有数据模型、完整性约束和事务的强一致性等特点,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持。
劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等。
(2)NoSQL数据库
优势:NoSQL数据库会采用非关系的数据模型,弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制。可能无法支持,或不能完整的支持SQL语句。目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)等。可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等。
劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等。
2. 简要总结一下NoSQL数据库的技术特点。
(1)NoSQL数据库会采用非关系的数据模型
(2)弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制
(3)可能无法支持,或不能完整的支持SQL语句
(4)目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)等
(5)NoSQL大多是开源免费的
3. 从发展趋势上看,NoSQL是否可以取代关系型数据库?并说明原因。
NoSQL不能取代关系型数据库。事实上,NoSQL数据库和关系型数据库是互补关系,在不限定场景的情况下,无法比较谁更强。
关系型数据库能够更好地保持数据的完整性和事务的一致性,以及支持对数据的复杂操作,在现实中拥有更普遍的适用领域。NoSQL数据库做不到上述,但是可以更好地实现分布式环境下对数据的简单管理和查询,即在大数据业务领域具有更大价值。
第2章 NoSQL数据库的基本原理
1. 描述分布式数据管理的特点。
(1)数据分片:使数据均匀分布到多个节点上,可以充分利用各个节点的处理能力、存储能力和吞吐能力。
(2)数据多副本:将数据存储为多个副本,不同的副本存储在不同节点上。
(3)一次写入多次读取:在系统底层只支持新建和追加,此时系统具有更好的顺序存储特性。
(4)分布式系统的可伸缩性:可以移除故障节点,替换新节点,实现数据的再平衡。
2 什么是CAP原理?CAP原理是否适用于单机环境?
CAP是指分布式系统中的Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)。Consistency(一致性)是指分布式系统中所有节点都能对某个数据达成共识。Availability(可用性)可以理解为分布式系统的响应速度或响应能力。Partition tolerance(分区容错性)指在部分节点故障、以及出现消息丢包的情况下,集群系统(的剩余部分)仍然可以提供服务。
CAP理论是指在分布式系统中,CAP三个特性不可兼得,只能同时满足两个。CAP不能兼顾,但并非绝对对立。
CAP理论的主要场景是在分布式环境下,在单机环境下,基本可不考虑CAP问题.
3. 简述BASE理论的具体含义。
由于CAP无法兼顾,分布式系统需要根据实际业务要求,对一致性做一定妥协,提供弱一致性保障。具体要求为BASE理论:
- Basically Available(基本可用):核心部分或其他数据可用。
- Soft-state(软状态/柔性事务):允许多个副本存在暂时的不一致状态。
(3)Eventual Consistency (最终一致性):存在中间状态,但经历一段时间之后,最终会一致。
4. 在数据一致性问题上,ACID和BASE的差别是什么?
(1)ACID是典型的强一致性要求。要求多个节点的数据副本都是一致的,强调数据的一致性。ACID是大多数NoSQL抛弃的机制,因为无法在分布式环境中保证效率。
(2)BASE的最终一致性(在一些应用场景下)也可以看作NoSQL允许多个副本可以存在暂时的不同步(即异步更新)。结合CAP理论,这种设计强调PA,可以提高响应速度。
5. 简述NoSQL数据库的4种类型,以及它们的数据模型。
- 键值对存储模式(key-value)
数据模型:每行数据的结构为:
(2)列存储模式(column-family)
数据模型:可以看作是一种纵向切分数据的方式,不同列会放到不同的位置(节点)存储,实际软件一般也会按照行键(key)再进行横向切片和分布式存储。
(3)文档存储模式(document)
数据模型:可以看作键值对模式的升级,底层存储的每行数据中仍然存在key(或者ID)和value。但值是采用JSON等格式描述的复杂数据类型。
(4)图存储模式(graph)
数据模型:将数据存储为点和边的关系。
6. 布隆过滤器的优缺点是什么?如何降低布隆过滤器的误报率?
布隆过滤器 的目的是检查某个元素是否存在于集合(例如数据块)中。
优点是空间占用低、检索速度快,缺点则是存储在一定的误报率:当布隆过滤认为某元素存在于集合时,该元素可能并不存在,但如果布隆过滤认为该元素不存在于集合,则肯定不存在。
布隆过滤器的误报率,和哈希算法的个数、二进制向量的大小以及数据总量有关,一般来说二进制向量越大,误报率越低,因此需要在存储空间占用和误报率之间做权衡。降低误报率的方法:(1)采取多个独立的哈希算法同时进行映射。(2)增大二进制向量的大小。
第4章 HBase的基本原理与应用
1. HDFS是否属于NoSQL数据库?请说明用HDFS进行数据管理存在的问题。
HDFS不属于NoSQL数据库。
用HDFS进行数据管理存在的问题:
(1)HDFS不支持对数据的随机读写。
(2)HDFS没有数据表的概念,不能提供对数据的表格化存储。
(3)HDFS无法针对行数统计、过滤扫描等常见数据查询功能。
2. HBase的特点是什么?(4条以上)
(1)采用面向列加键值对的存储模式。
(2)可以实现便捷的横向扩展
(3)可以实现自动的数据分片。
(4)可以实现严格的读写一致性和自动的故障转移。
(5)可以实现对全文的检索与过滤。
(6)支持通过命令行或者Java、Python等语言来进行操作。
3. HBase采用了什么样的数据结构?
HBase采用的是一种面向列的键值对存储模式。HBase表中,列族是表结构的一部分,需要在建表时预先定义。
列不属于表结构,HBase不会预先定义列名及其数据类型和值域等内容。每一个记录中的每个字段必须记录自己的列名(列标识符)以及值和时间戳。
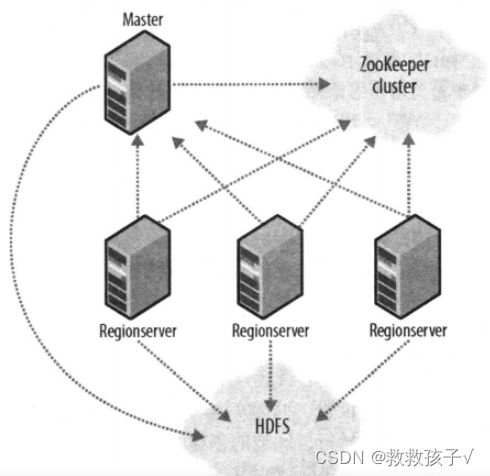
4. HBase的拓扑结构是什么?每个角色起什么作用?
HBase采用主从式架构,包括一个主节点(Hmaster)和若干个从节点(Hregionserver)。除此之外,还需要Zookeeper来实现节点监控和容错。
(1)Zookeeper是一个分布式协调服务,实现节点监控、活跃主节点选举、配置维护等功能
- 维护元数据的总入口,以及记录Master节点的地址
- 监控集群,如果Hregionserver出现故障,则通知Master,Master会将其负责的分区移交给其他Hregionserver
- 当活跃Master节点故障的情况下,Zookeeper会在备用Master节点中选举一个新的活跃Master节点。
(2)HMaster节点是所有Hregionserver的管理者,负责对Hregionserver的管理范围进行分配,但不负责管理用户数据表。
(3)Hregionserver是用户数据表的实际管理者,在分布式集群中,数据表会进行水平分区,每个Hregionserver只会对一部分分区进行管理——负责数据的写入、查询、缓存和故障恢复等。用户表最终是以文件形式存储在HDFS上,但如何将写入并维护这些文件,则是由Hregionserver负责的。
5. 请用拓扑结构图的形式展示HBase的典型架构
第5章 HBase的高级原理
1. HBase中预写日志(WAL)的作用。
当数据被写入memstore之前,Regionserver会先将数据写入预写日志(WAL,Writeaheadlog),预写日志一般被写入HDFS,但键值写入时不会被排序,也不会区分Region。
出现节点宕机、线程重启等问题时,memstore中未持久化的数据会丢失。当Regionserver恢复后,会查看当前WAL中的数据,并将记录进行重放(replay),根据记录的表名和分区名,将数据恢复到指定的store中。
在进行自动或手动的数据持久化操作之后,Regionserver会将不需要的WAL清除掉。
2. 如何理解HBase的分区拆分机制,包括哪几种方式?
HBase为了实现分布式大数据管理,设计了表的水平拆分机制,这是HBase实现分布式、负载均衡以及可伸缩性等机制的重要方式。
HBase具有三种分区方式:自动分区、预分区和手动拆分,都是基于行键进行分区。
3. 如何理解HBase的合并,包括哪几种方式?
HBase中设计了合并(compact)机制,通过读取多个小文件,处理并写入一个新的大文件的方式,实现storefile的合并。它包括MajorCompact和Minor Compact两种合并方式。
4. HBase的Major Compact和Minor Compact两种合并方式有什么区别?
Minor Compact只能对部分文件进行操作。在合并的过程中,会根据TTL和minVersion属性,将过期数据清除,但不做其他清理。
Major Compact将对该Region的store中所有的storefile进行合并,形成一个唯一的storefile,其中所有的无效数据都会被处理。比较而言,Major Compact开销更大且耗时更长。(5分)
第7章 MongoDB的原理和使用
1. 描述MongoDB的集群架构(包含的角色和每个角色的作用)。
MongoDB集群由Mongod、Mongos和Config服务器组成。
(1)负责存储实际数据分片的设备称为Mongod(或称为Shard)。
(2)Mongos服务器,作为用户访问集群的入口,负责与客户端的交互,并在内存中缓存分片数据的存储和路由信息。
(3)Config服务器,负责持久化存储各类元数据和配置信息,当Mongos服务器启动时,会通过Config服务器读取相关信息并缓存到内存。
2. 请用拓扑结构图的形式展示MongoDB的典型架构

3. 描述MongoDB的分片机制,它支持哪几种分片策略?
MongoDB将数据水平切分机制称为分片(Sharding)。MongoDB支持对文档的自动分片,分片的依据是分片键(Shard Keys),分片键可以由文档的一个或多个字段构成。
MongoDB支持三种分片(片键)策略:升序分片、哈希分片和位置分片。
(1)升序分片会将片键进行升序排序,并在当前分片的数据量达到某个阈值时进行分片。
(2)哈希分片会将片键进行哈希运算,使数据的分布更均匀。
(3)位置分片类似于对片键的前缀或子串进行判断。
4. MongoDB集群的数据多副本策略?
MongoDB支持分片的多副本,多副本采用主从备份形式。MongoDB称这种机制为复制集机制。
主节点(Primary节点)负责数据的写入和更新。主节点在更新数据的同时,会将操作信息写入日志,称为oplog。
从节点(Secondary节点)监听主节点oplog的变化,并根据其内容维护自身的数据更新,使之和主节点保持一致(最终一致性)。
第8章 其他NoSQL数据库
1. 什么是Neo4j?并对其数据模型进行详细描述。
Neo4j是一个基于Java语言的开源图数据库系统。Neo4j具有强大的图处理和查询搜索能力,通过专用的Cypher语言完成各类操作。
Neor4j采用将数据存储为节点和边的图存储模式,其中节点表示实体、边表示实体之间的关系。
2,描述Redis的数据类型(5种)。
Redis 支持的数据类型有字符串、散列、列表、集合、有序集合。
3. Redis数据库支持的几种拓扑架构。
(1)主从复制:主从结构具有读写分离,提高效率、数据备份,提供多个副本等优点。
(2)哨兵机制: 哨兵是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 master 并将所有的 slave 连接到新的 master。
(3)Redis集群:Redis没有使用一致性哈希机制,而是引入了哈希槽的概念。Redis 集群有16384个哈希槽,集群中所有设备平分这些哈希槽,数据则根据其行键的散列计算结果,映射到不同的哈希槽中。