LORA概述: 大语言模型的低阶适应
LORA概述: 大语言模型的低阶适应
- LORA: 大语言模型的低阶适应
-
- 前言
- 摘要
- 论文十问
- 实验
-
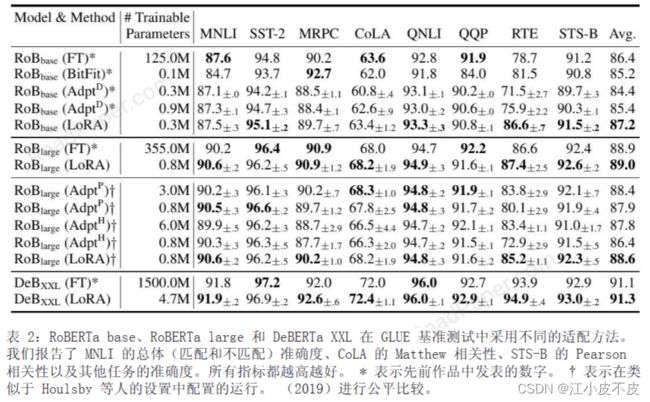
- RoBERTa
- DeBERTa
- GPT-2
- GPT-3
- 结论
- 代码调用
LORA: 大语言模型的低阶适应
前言
LoRA的核心思想在于优化预训练语言模型的微调过程,通过有效地处理权重矩阵的变化(即梯度更新的累积),使其具有“低秩”结构。简而言之,这意味着可以通过低秩分解有效地表示变化矩阵。
具体来说,对于预训练权重矩阵W₀,其更新量可以表示为∆W = BA,其中B和A都是低秩矩阵(例如,秩为r,r明显小于矩阵维度d)。在训练期间,W₀被冻结,而B和A中的参数是可训练的。这明显减少了适应的可训练参数数量。
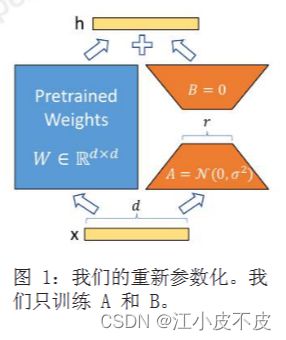
如下图所示,在原始预训练语言模型旁边添加一个旁路,执行降维再升维的操作,以模拟内在秩。在训练过程中,固定预训练语言模型的参数,只训练降维矩阵A和升维矩阵B。模型的输入输出维度保持不变,输出时将BA与预训练语言模型的参数叠加。矩阵A使用随机高斯分布进行初始化,而矩阵B则使用零矩阵进行初始化,以确保在训练开始时,该旁路矩阵仍然是零矩阵。
摘要
自然语言处理的一个重要范式包括在通用域数据上进行大规模预训练,以及针对特定任务或域进行适配。随着我们预训练更大的模型,全面微调,即重新训练所有模型参数,变得更加不可行。
以GPT-3 175B为例,单独部署经过微调的独立实例模型,每个实例拥有1750亿个参数,是极其昂贵的。我们提出了低秩适应(LoRA)方法,其中冻结预训练模型权重,并在transformer体系结构的每个层中插入可训练的低秩分解矩阵,从而大大减少下游任务的可训练参数数量。
与使用Adam微调GPT-3 175B相比,LoRA可以将可训练参数数量减少10000倍,GPU内存需求减少3倍。尽管只有更少的可训练参数和更高的训练吞吐量,但LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3上的性能优于或等同于微调。
我们还对语言模型适配中的秩缺失进行了实证研究,这解释了LoRA的功效。我们发布了一个软件包,可以方便地将LoRA与PyTorch模型集成,并为RoBERTa、DeBERTa和GPT-2提供了我们的实现和模型检查点。
论文十问
- 论文试图解决什么问题?
这篇论文试图解决大规模预训练语言模型(如GPT-3)微调(fine-tuning)所带来的巨大的存储、部署和任务切换成本的问题。
- 这是否是一个新的问题?
这不是一个全新的问题,但随着 transformer 语言模型规模的不断增长(如 GPT-3 175B 参数),这个问题的严重性在增加。论文中也提到了许多相关的已有工作。
- 这篇文章要验证一个什么科学假设?
这篇文章的主要科学假设是微调过程中模型参数的变化矩阵具有低秩结构(rank-deficient)。基于这个假设,作者提出了低秩适应(LoRA)方法来有效地适应下游任务。
- 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
相关的工作包括适配器模块、prompt tuning等参数高效适应方法。
- 论文中提到的解决方案之关键是什么?
LoRA的关键是只训练插入到每个transformer层中的低秩分解矩阵,而保持预训练权重固定。这大大降低了适应的可训练参数数量。
- 论文中的实验是如何设计的?
在 RoBERTa、DeBERTa、GPT-2 和 GPT-3 等模型上进行了大量实验比较。实验设计针对性强,测试了性能和参数数量的权衡。
- 用于定量评估的数据集是什么?代码有没有开源?
使用的数据集包括 GLUE、WikiSQL、SAMSum 等。实验代码和模型检查点开源。
- 论文中的实验及结果有没有很好地支持需要验证的科学假设?
是的,丰富的实验验证了 LoRA 在性能、存储效率、训练速度等方面都优于或匹敌全微调基线,支持了低秩适应的有效性。
- 这篇论文到底有什么贡献?
主要贡献是提出 LoRA 方法,大幅降低大模型微调的成本,并给出可复现的实验验证。
- 下一步呢?有什么工作可以继续深入?
下一步可以考虑与其他高效适应方法(如prompt tuning)的结合,解释微调过程中模型内部表示的变化,进一步提高 LoRA 的泛化性等。
实验
评估了 LoRA 在 RoBERTa (Liu et al., 2019)、DeBERTa (He et al., 2021) 和 GPT-2 (Radford etal., b) 上的下游任务性能,然后再扩展到 GPT- 3 175B(布朗等人,2020 年)
RoBERTa
RoBERTa是Facebook AI于2019年提出的语言表示模型。相比BERT有更优化的预训练步骤,性能更好,参数规模类似,分Base和Large两个版本。实验中分别使用了1.25亿参数和3.55亿参数的RoBERTa模型。
DeBERTa
微软于2020年提出的改进型BERT模型。采用多任务预训练、增强型注意力机制等技术。实验中使用了极大规模的DeBERTa XXL,包含了1500亿参数。
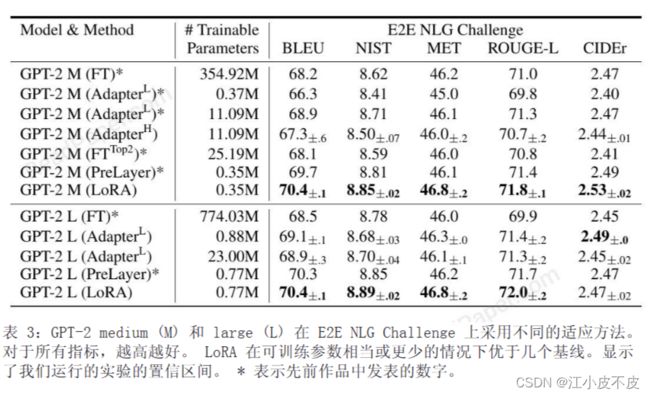
GPT-2
OpenAI于2019年提出的基于Transformer的语言生成模型GPT-2。模型架构采用了解码器,支持自回归文本生成。实验分别基于中等规模(3.54亿参数)和大规模(7.74亿参数)的GPT-2进行。
GPT-3
OpenAI于2020年发布的巨大语言模型, Transformer规模达到了1750亿参数,是当时最大的神经语言模型。论文使用了这个极具挑战性的大模型进行扩展实验。这几种模型的选择,可以让作者全面验证LoRA适配方法在不同规模的Transformer类模型中的有效性。覆盖了目前最典型和最前沿的语言表示与生成模型。

结论
实际好处:
- 内存和存储使用减少: 在使用Adam训练的大型Transformer中,通过使用LoRA,显著减少了VRAM(显存)和存储的使用量。例如,在GPT-3 175B上,将训练期间的VRAM消耗从1.2TB减少到350GB。
- 检查点大小减小: 在一定条件下,检查点大小减少了大约10,000倍,从350GB减少到35MB。这降低了GPU训练的硬件需求,并避免了I/O瓶颈。
- 任务切换成本降低: LoRA允许在任务之间进行切换,通过仅交换LoRA权重而不是所有参数,降低了部署的成本。这使得可以在机器上动态换入和换出预训练权重,创建自定义模型。
- 加速训练: 在GPT-3 175B的训练中,相较于完全微调,观察到25%的加速,因为不需要计算绝大多数参数的梯度。
局限性:
- 前向传递复杂性: 吸收不同任务的A和B到W中,以消除额外推理延迟,在单个前向传递中批量输入并不简单。需要考虑不同任务的权重合并和动态选择LoRA模块的复杂性。
- 推理延迟问题: 尽管可以动态选择LoRA模块以处理不同任务的推理延迟,但在一些场景中,合并权重可能引入不可避免的问题。
代码调用
使用 PEFT 训练您的模型
下面的示例是使用 LoRA 进行微调的情况。
from transformers import AutoModelForSeq2SeqLM
from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])