VanillaKD:Revisit the Power of Vanilla KnowledgeDistillation from Small Scale to Large Scale 中文版
论文原地址:
https://arxiv.org/abs/2305.15781
摘要
近年来,深度学习在计算机视觉领域取得了显著进展,模型的能力和容量不断增加[1,2,3,4,5]。实现更好性能的主流方法的理念是“越大越好”,这可从不断增加深度[2,6,7,8]和宽度[9,10]的模型取得的成功得以证实。然而,这些庞大的模型拥有大量参数,难以部署在计算资源有限的边缘设备上,例如手机和自动驾驶汽车。为了克服这一挑战,知识蒸馏(KD)[11]及其变种[12,13,14,15,16,17,18]被提出,在训练过程中通过从更大的教师模型向更紧凑的学生模型传递知识,以提高性能。
介绍
到目前为止,文献中大部分现有的知识蒸馏(KD)方法都是针对小规模基准(例如CIFAR[19])和小型师生对(例如Res34-Res18[2]和WRN40-WRN16[10])进行了定制。然而,实际的下游视觉任务[20,21,22]需要对骨干模型进行在大规模数据集(例如ImageNet[23])上的预训练,以实现最先进的性能水平。
仅仅在小规模数据集上探索知识蒸馏(KD)方法可能无法在实际场景中提供全面的理解。考虑到大规模基准数据集的可用性和大型模型的容量[24,3,25,26,27],目前仍不确定先前的方法在涉及更强的训练方法、不同模型容量和更大数据规模的更复杂方案中是否仍然有效。
在本文中,我们深入探讨了这个问题,并对决定蒸馏效果的关键因素进行了彻底研究。我们指出了当前知识蒸馏文献中的小数据陷阱:在小规模数据集(如CIFAR-100,训练图像为50K)上评估时,针对这些数据集精心设计的知识蒸馏方法往往能轻松超越基本的知识蒸馏[11]。然而,在大规模数据集(如ImageNet-1K,训练图像为1M)上评估时,基本的知识蒸馏方法可以达到甚至超过其他方法的结果。为了解决这个问题,我们首先通过在小规模数据集上进行更长时间的训练[28]来弥补数据量不足。尽管训练时间更长,精心设计的知识蒸馏方法仍然大幅优于基本的知识蒸馏方法。这表明大规模数据集对于基本的知识蒸馏方法发挥最佳效果至关重要。我们进一步研究了影响知识蒸馏效果的关键因素,并仔细研究了两个关键元素,即训练策略和模型容量。在不同的训练策略方面,我们得出了以下观察结果:(i) 通过评估在大规模数据集(如ImageNet[23])上采用不同训练方法[12,29,30]的精心设计方法[14,15],这些方法在小规模基准测试上表现良好,显然,随着数据增强技术和更长的训练迭代次数的提高,基本的知识蒸馏方法[11]与其他精心设计的知识蒸馏方法之间的差距逐渐缩小。(ii) 我们的实验还表明,在可推广性方面,**基于logits的方法[11,14,15]优于基于提示的方法[12,13,18,17]。**随着数据集和模型规模的增加,教师模型和学生模型具有处理复杂分布的不同能力。因此,采用基于提示的方法,即学生模仿教师的中间特征,越来越不利于实现满意的结果。
图1:随着数据集规模的增加,基本的知识蒸馏方法(vanilla KD)与其他精心设计的方法之间的性能差距逐渐减小。
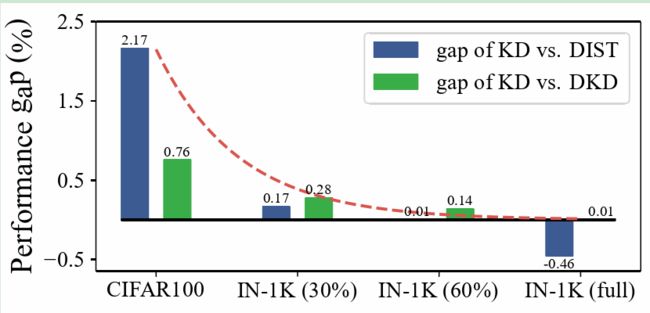
关于模型容量,我们比较了不同规模的师生对,例如,使用Res34教授Res18和使用Res152教授Res50。结果显示,基本的知识蒸馏(vanilla KD)最终达到了与最佳精心设计方法相当的性能,表明模型容量对知识蒸馏效果的影响实际上很小。在我们的研究过程中,我们强调由于小数据陷阱,基本知识蒸馏的威力被严重低估。与此同时,精心设计的蒸馏方法在面对更强的训练策略[29,28]和更大的数据集[31]时可能变得次优。此外,直接将基本的知识蒸馏方法应用到ResNet-50[2]、ViT-Tiny、ViT-Small[3]和ConvNeXtV2[27]架构上,在ImageNet上分别达到了83.1%、78.1%、84.3%和85.0%的准确率,超过了文献中报告的最佳结果[28]而无需额外的修改。我们的结果为基本知识蒸馏方法的潜力和能力提供了有效的证据,并表明其实际价值。此外,我们还需要进一步思考是否合适在小规模数据集上设计和评估知识蒸馏方法。最后,我们证明了通过提高在ImageNet上性能更好的骨干架构,还可以显著提升诸如目标检测和实例分割等下游任务的性能[20,32,33]。虽然本文没有提出新的蒸馏方法,但我们相信我们对小数据陷阱的识别和基于此的一系列分析将为视觉领域的知识蒸馏提供有价值的见解,并在更实际的场景下追求新的最先进结果。此外,我们期待常用架构的发布检查点将促进对下游任务的进一步研究。
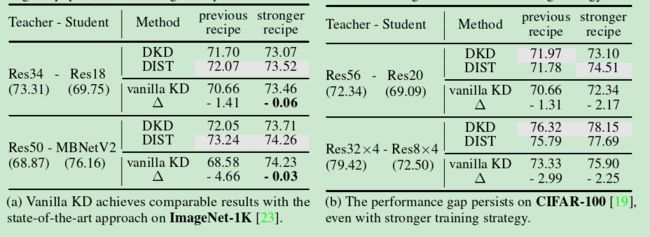
表1:数据集规模对知识蒸馏(KD)性能的影响。在大规模数据集上采用更强的训练策略时,基本的知识蒸馏(vanilla KD)[11]可以达到与**最先进方法(如DKD[15]和DIST[14])**相当的结果。然而,在小规模数据集上并未观察到这种现象,揭示了小数据陷阱低估了基本知识蒸馏的能力。符号∆表示基本知识蒸馏与其他方法取得的最佳结果之间的准确率差距(用灰色标记)。“previous recipe”指的是原始论文中报告的结果,“stronger recipe”指的是通过我们增强的训练策略获得的结果。
2.基本知识蒸馏方法在处理小规模数据集时表现不佳或性能受限的情况
2.1 Review of knowledge distillation
知识蒸馏(KD)技术可以根据预先训练的教师模型使用的信息来源广泛分为两种类型:一种利用教师模型的输出概率(基于logits的方法)[15,14,11],另一种利用教师模型的中间表示(基于提示的方法)[12,13,18,17]。基于logits的方法利用教师的输出作为辅助信号来训练一个较小的模型,即学生模型:
![]()
其中, p s p_s ps和 p t p_t pt分别是学生模型和教师模型的logits, y y y是one-hot形式的真实标签。 D c l s D_{cls} Dcls和 D k d D_{kd} Dkd分别是分类损失和蒸馏损失,例如交叉熵和KL散度。超参数 α \alpha α确定了两个损失项之间的平衡。为方便起见,我们在所有后续实验中将 α \alpha α设置为0.5。
除了logits外,中间提示(即特征)[12]也可以用于知识蒸馏。考虑一个学生特征 F s F_s Fs和一个教师特征 F t F_t Ft,基于提示的蒸馏的实现如下:
![]()
其中, T s T_s Ts和 T t T_t Tt是用于对齐两个特征的转换模块。 D h i n t D_{hint} Dhint是特征差异的度量,例如l1或l2范数。在常规实践中,提示式损失通常与分类损失一起使用,在我们的实验中也遵循了这种设置。
2.2 基本知识蒸馏(Vanilla KD)在小规模数据集上无法达到令人满意的结果。
最近,许多研究使用了简化的评估方案,涉及小型模型或数据集。然而,关于仅在这些小规模环境中评估知识蒸馏方法的局限性,人们越来越关注[28],因为许多实际应用涉及更大的模型和数据集。在本节中,我们广泛调查了使用小容量模型和小规模数据集对不同知识蒸馏方法的影响。为了进行全面分析,我们特别将基本知识蒸馏与两种最先进的基于logits的知识蒸馏方法进行比较,即DKD[15]和DIST[14]。与[28]压缩大型模型到Res50不同,我们的主要关注点是确定基本知识蒸馏的不理想性能是否归因于小型学生模型或小规模数据集。
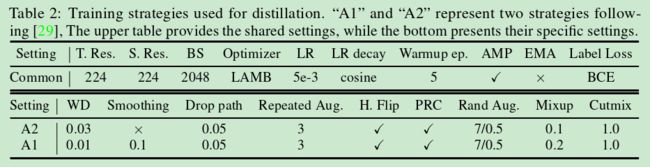
A1和A2两种参数设置
表2:用于蒸馏的训练策略。"A1"和"A2"代表遵循[29]的两种策略。上表提供了共享的设置,而下表呈现了它们的具体设置。
不同的KD结果对比
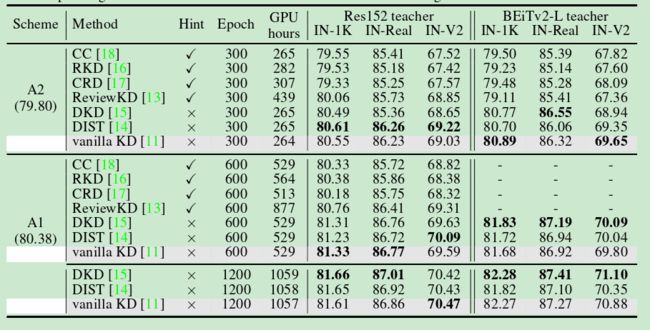
表3:提示式和基于logits的蒸馏方法之间的比较。学生模型为Res50,而教师模型分别为Top-1准确率为82.83%的Res152和88.39%的BEiTv2-L。“✓”表示对应的方法是基于提示的。GPU小时是在单台拥有8个V100 GPU的机器上评估的。
结论
受到深度学习中不断强调扩展规模以实现显著性能提升的影响,本文重新审视了几种知识蒸馏(KD)方法,涵盖了从小规模到大规模数据集设置的范围。我们的分析揭示了先前KD方法中存在的小数据陷阱,即当应用于大规模数据集时,大多数KD变体相对于基本的知识蒸馏(vanilla KD)的优势会减弱。基于增强的数据增强技术和更大的数据集,基本知识蒸馏崭露头角,成为一个可行的竞争者,能够达到与最先进的KD变体相媲美的性能。值得注意的是,我们训练的基本知识蒸馏的ResNet-50、ViT-S和ConvNeXtV2-T模型在没有任何额外修改的情况下取得了新的最先进性能。虽然在大规模数据集上应用知识蒸馏可以显著提升性能,但需要承认与之相关的更长训练时间,这不可避免地会增加碳排放。这些增加的计算资源需求可能会妨碍从业者充分探索和确定最佳设计选择。未来的努力应该专注于更长的训练时间和碳排放带来的限制,并探索新途径进一步提升蒸馏方法的效力和效率。