Pytorch .numpy(), .item(), .detach(), .cpu(), .cuda(), .tensor(), .as_tensor(), Tensor(), .clone(),
今天说明一下Pytorch的Tensor变量与Numpy之间的转化。
Pytorch中有以下这么多命令涉及到tensor和numpy之间的转化: .numpy(), .item(), .detach(), .cpu(), .cuda(), .tensor(), .as_tensor(), Tensor(), .clone(),
具体怎么用呢?请看下面的详细解释。
正如Numpy中所有的操作都是针对Numpy特有的变量类型Array,在Pytorch中几乎所有的操作都是针对Pytorch特有的变量类型Tensor.
那么Tensor和Array有什么不同呢?
最大的不同是:Tensor既可以存储在GPU(或者’cuda’设备)上,也可以存储在cpu设备上(准确来讲是cpu的内存上);而Array只能存储在cpu的内存上。
这就引出一个问题了:如何把cpu和GPU上的Tensor互相传递呢?
import torch as t
a = t.Tensor([1, 2, 3]) # 默认是在cpu的内存上放着呢
print(a)
# output: tensor([1,2,3])
# 如果你有GPU,想把tensor从cpu传到GPU,那么用以下函数
b = a.duda()
print(b)
# output: tensor([1,2,3], device='cuda:0')
# 但是如果你没有GPU,那么当用.cuda()函数就会报错
# RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver from http://www.nvidia.com/Download/index.aspx
# 如果你想把tensor从GPU传回到CPU
c = b.cpu()
print(c)
# output: tensor([1,2,3])
那它们两个之间如何互相转化呢?
看下面的例子。
import torch as t
import numpy as np
a = np.array([1,2,3]) # 一个numpy.Array()诞生,存储在cpu内存上
okay, 目前搞清楚了.cpu()和.cuda()了。
把numpy.array转化成torch.tensor有下面几种方法。
(这里我插一句话啊,Array和array, Tensor和tensor,就类似List和list。首字母大写表示类,首字母小写表示实例)
-
t.Tensor()或者t.tensor()或者t.as_tensor(). 他们功能基本一致,可互换使用。
t.Tensor()和t.tensor()的区别是 torch.Tensor是torch.tensor 和 torch.empty的集合. 为了避免歧义和困惑,才把 torch.Tensor 分拆成了torch.tensor 和`torch.empty. 所以t.tensor和t.Tensor()可以互换,没有谁更好。不过推荐使用t.tensor(),就类似list(),np.array()一样。
而t.tensor()和t.as_tensor()的区别是t.tensor()会复制原来的数据,t.as_tensor()会尽力不复制,尽力尝试与原来的numpy.array共享内存。
-
可使用t.from_numpy(),与原Numpy数据共享内存。
上文中说过的t.Tensor()会复制数据,那么同时,数据的格式也变了。t.Tensor()是t.FloatTensor()的另一个名字,他们会把数据转化成32位浮点数。即使原来的numpy.array数据是int或者float64,都会被转化成32位浮点数。
而使用t.from_numpy()的话就会保留数据的格式,这是因为t.from_numpy()会共用同一个内存,不会复制数据。
okay, 又明白了.Tensor()和.tensor()(复制数据),.as_tensor()(尽量不复制数据), .from_numpy()(不复制数据,共享内存)。
把torch.tensor转化成numpy.array有下面几种方法。
如果tensor是放在cpu上,那么很简单一个命令搞定:
import torch as t
a = t.tensor([1,2,3])
b = a.numpy()
print(b)
# output: array([1, 2, 3])
但是如果tensor是放在GPU上,那么在用.numpy()之前先得用.cpu()把它传到cpu上。如下:
import torch as t
a = t.tensor([1,2,3]).cuda()
b = a.cpu().numpy()
print(b)
# output: array([1, 2, 3])
如果tensor本身还包含梯度信息,需要先把用.detach()梯度信息剔除掉,再转成numpy。如下:
import torch as t
a = t.tensor([1,2,3]).cuda()
net = ... # 建立一个神经网络
out= net(a) # 该输出是带有梯度的
b = out.cpu().detach().numpy()
print(b)
# output: array([1, 2, 3])
这里呢需要用一段来好好讲一下pytorch中tensor的梯度问题。在Pytorch中,tensor的存在就类似于numpy中array的存在。但是Pytorch中tensor还有个额外的属性:梯度。为了参与神经网络训练,每一个tensor一般都会有自己的梯度(除了叶节点)。这种情况下,我们在把tensor转化为numpy.array的时候就要先把tensor的梯度去掉,然后再做转化。之前的例子中tensor可以直接被转化成numpy.array是因为我们用的那些tensor都是直接创建的,属于叶节点,不包含梯度,所以可以直接转化。.detach()返回一个与当前 graph 分离的、不再需要梯度的新tensor(当然tensor.data也可以做相同的事情,但是推荐使用.detach,因为.data会偶尔引入bug)。
okay, 又kill掉几个名词:.numpy(), .detach(),
.item() 将张量的值转换为标准的 Python 数值,只有当张量仅含一个元素时才能使用它,使用它的时候不必要考虑tensor是在cpu还是gpu上,也不必要考虑该tensor是不是带有梯度。一般用这个命令去把loss转成数值。当然,你也可以用.detach().cpu().numpy()做。
其他问题:
- Variable和Tensor的不同:Variable已经被弃用了,以后不要再用它了。最开始的时候Tensor不带梯度,为了自动求导梯度,引入了Variable。后来开发者直接把梯度嵌入到了Tensor理,就放弃了Variable了。
- .clone()是什么?如下图:
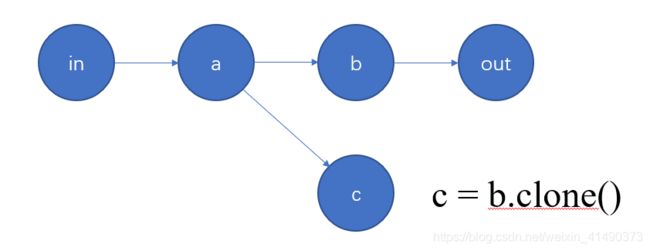
.clone()会复制一个tensor出来,这个新的tensor是带梯度的,它是和原来的动态图依然链接在一起的。
总结:
- 不推荐使用t.Tensor(),不推荐tensor.data, 不推荐Variable。
- cpu转GPU:tensor.cuda(); GPU转CPU:tensor.cpu()。
- tensor转numpy.array,tensor.numpy();array转tensor:t.from_numpy(),t.as_tensor(), t.tensor()。注意:GPU上的tensor不能直接转numpy.array。
- 对于带梯度的tensor,转numpy之前先用.detach()提取一个无梯度的tensor再转。