基于社区电商的Redis缓存架构-库存模块缓存架构(上)
库存模块缓存架构
我们先来分析一下库存模块的业务场景,分为入库和出库,入库的话,在库存模块中需要添加库存,由于库存也是 写多读多 的场景,那么也是以 Redis 作为主存储,MySQL 作为辅助存储
出库的话,是在用户下单时,需要去库存中进行减库存的操作,并且用户退款时,需要增加库存
那么库存模块是存在高并发写的情况的,通过对商品库存进行分片存储,存储在多台 Redis 节点上,就可以将高并发的请求分散在各个 Redis 节点中,并且提供了单台 Redis 节点库存不足时的合并库存的功能
先来说一下如何对商品库存进行缓存分片,比如说有 100 个商品,Redis 集群有 5 个节点,先将 100 个商品拆分为 5个分片,再将 5 个分片分散到 Redis 集群的各个节点中,每个节点 1 个分片,那么也就是每个 Redis 节点存储 20 个商品库存
那么对于该商品的瞬间高并发的操作,会分散的打到多个 Redis 节点中,库存分片的数量一般和 Redis 的节点数差不多
这里分片库存的话,我们是在对商品进行入库的时候实现的,商品在入库的时候,先去 DB 中异步落库,然后再将库存分片写入各个 Redis 节点中,这里写入的时候采用渐进性写入,比如说新入库一个商品有 300 个,有 3 个 Redis 节点,那么我们分成 3 个分片的话,1 个 Redis 节点放 1 个分片,1 个分片存储 100 个商品,那么如果我们直接写入缓存,先写入第一个 Redis 节点 100 个库存,再写入第二个 Redis 节点 100 个库存,如果这时写入第三个 Redis 节点 100 个库存的时候失败了,那么就导致操作库存的请求压力全部在前两个 Redis 节点中,采用 渐进性写入 的话,流程为:我们已经直到每个 Redis 节点放 100 个库存了,那么我们定义一个轮次的变量,为 10,表示我们去将库存写入缓存中需要写入 10 轮,那么每轮就写入 10 个库存即可,这样写入 10 轮之后,每个 Redis 节点中也就有 100 个库存了,这样的好处在于,即使有部分库存写入失败的话,对于请求的压力也不会全部在其他节点上,因为写入失败的库存很小,很快时间就可以消耗完毕
基于缓存分片的入库添加库存方案
在商品入库时,主要就是在 DB 中记录入库的日志并且保存库存信息,在 Redis 中主要将库存进行分片存储,用于分担压力,流程图如下:
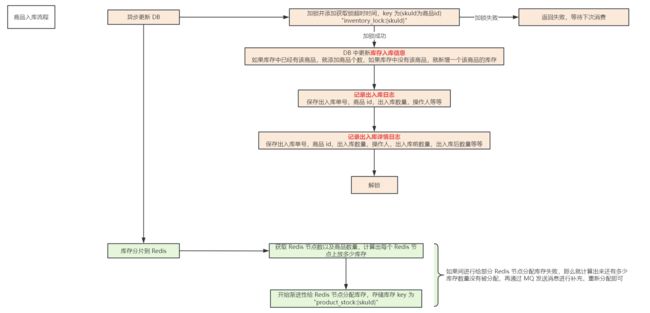
在商品入库时,对库存进行分片,流程为:
- 计算当前 Redis 节点需要分配的库存数量
- 执行 lua 脚本进行库存分配
下边贴出库存分片的代码,主要是 executeStockLua 方法:
/**
* 执行库存分配,使用lua脚本执行库存的变更
* @param request 变更库存对象
*/
public void executeStockLua(InventoryRequest request) {
// Redis 存储商品库存的 key
String productStockKey = RedisKeyConstants.PRODUCT_STOCK_PREFIX + request.getSkuId();
// 当前已经分配的库存数量
Integer sumNum = 0;
Long startTime = System.currentTimeMillis();
try {
// 获取默认设定分桶
int redisCount = cacheSupport.getRedisCount();
// 商品入库数量
Integer inventoryNum = request.getInventoryNum();
// 单个机器预计分配的库存
Integer countNum = inventoryNum / redisCount;
// countNum 指的是每个机器每轮分配的库存数量,要么是单台机器预计分配的库存的 1/10,要么是 3 个
// 也就是如果单个机器预计分配的库存比较小的话,没必要每次分配的 1 个或者 2 个,因此设置每轮分配的库存数量最小值是 3
countNum = getAverageStockNum(countNum,redisCount);
int i = 0;
while (true){
// 对每台机器进行库存分配
for (long count = 0;count < redisCount; count++ ){
// 最后剩余的库存小于每轮分配库存数量的时候,则以最后剩余的库存为准
if (inventoryNum - sumNum < countNum){
countNum = inventoryNum - sumNum;
}
// 这里 cacheSupport 是提供的一个工具类,用于让 Redis 去执行 lua 脚本进行库存的分配
Object eval = cacheSupport.eval(count, RedisLua.ADD_INVENTORY, CollUtil.toList(productStockKey), CollUtil.toList(String.valueOf(countNum)));
if (!Objects.isNull(eval) && Long.valueOf(eval+"") > 0){
// 分配成功的才累计(可能出现不均匀的情况)
sumNum = sumNum + countNum;
i++;
}
if (sumNum.equals(inventoryNum)){
break;
}
}
//分配完成跳出循环
if (sumNum.equals(inventoryNum)){
break;
}
}
log.info("商品编号:"+request.getSkuId()+",同步分配库存共分配"+ (i)+"次"+",分配库存:"+sumNum+",总计耗时"+(System.currentTimeMillis() - startTime)+"毫秒");
}catch (Exception e){
e.printStackTrace();
// 同步过程中发生异常,去掉已被同步的缓存库存,发送消息再行补偿,这里出现异常不抛出,避免异常
request.setInventoryNum(request.getInventoryNum() - sumNum);
// 这个 MQ 的异步操作中,就去去对库存进行添加,之前已经成功添加 sumNum 个库存了,还需要再补偿添加 request.getInventoryNum() - sumNum 个库存
sendAsyncStockCompensationMessage(request);
log.error("分配库存到缓存过程中失败", e.getMessage(), e);
}
}
/**
* 获取每个机器预估的分配库存数量
* @param countNum
* @return
*/
private Integer getAverageStockNum(Integer countNum,Integer redisCount){
Integer num = 0;
/**
* countNum 为单个节点需要分配的库存总数
* StockBucket.STOCK_COUNT_NUM 代表每个节点最多分配的轮次,这里的默认值是 10,也就是单个节点最多分配 10 次库存
* redisCount 是 Redis 的节点数
* 如果 countNum > (redisCount * StockBucket.STOCK_COUNT_NUM)
* 那么每次分配的库存数我们以 redisCount 作为一个标准,假如 redisCount = 3
* redisCount * StockBucket.STOCK_COUNT_NUM 的含义就是分配 10 轮,每轮分配 3 个库存,如果当前节点需要分配的库存数是比(每次分配3个,共分配10轮)还要多的话
* 那么就每轮分配 countNum / 10
* 如果单个节点的库存总数小于(分配 10 轮,每轮分配 redisCount 个库存)的话,再判断 countNum 是否大于 3,如果大于 3,就每轮分配 3 个
* 如果小于 3,就分配 countNum 个
*/
if (countNum > (redisCount * StockBucket.STOCK_COUNT_NUM)){
num = countNum / StockBucket.STOCK_COUNT_NUM;
} else if (countNum > 3){
num = 3;
} else {
num = countNum;
}
return num;
}
下边来讲一下库存分配中,如何选择 Redis 节点并执行 lua 脚本向 Redis 中写入库存的:
Object eval = cacheSupport.eval(count, RedisLua.ADD_INVENTORY, CollUtil.toList(productStockKey), CollUtil.toList(String.valueOf(countNum)));
也就是上边这一行代码,先说一下参数,count 表示循环到哪一个 Redis 节点了,通过 count % redisCount,就可以拿到需要操作的 Redis 节点的下标,表示需要操作哪一个 Redis,就在该 Redis 中执行 lua 脚本
RedisLua.ADD_INVENTORY 表示需要执行的 lua 脚本,CollUtil.toList(productStockKey) 表示 keys 的 list 集合,CollUtil.toList(String.valueOf(countNum)) 表示 args 的 list 集合,这两个参数用于在 lua 脚本中进行取参数使用
那么再说一下 eval 方法执行的流程,首先维护一个 List 集合,那么在 eval 方法中根据 count 参数拿到需要操作的 Redis 节点的下标,取出该 Redis 节点所对应的 Jedis 客户端,再通过该客户端执行 lua 脚本,eval 方法如下:
@Override
public Object eval(Long hashKey, String script,List<String> keys, List<String> args) {
/**
* jedisManager.getJedisByHashKey(hashKey) 这个方法就是将传入的 count 也就是 hashKey 这个参数
* 对 Redis 的节点数量进行取模,拿到一个下标,去 List 集合中取出该下标对应的 Jedis 客户端
*/
try (Jedis jedis = jedisManager.getJedisByHashKey(hashKey)){
return jedis.eval(script,keys,args);
}
}
那么在这个 eval 方法中,拿到存储当前库存分片的 Redis 客户端,在该客户端中执行 lua 脚本,脚本内容如下:
/**
* 初始化新增库存
* 这里的 KEYS[1] 也就是传入的 productStockKey = product_stock:{skuId}
* ARGV[1] 也就是 countNum,即当前 Redis 节点需要分配的库存数量
*/
public static final String ADD_INVENTORY =
"if (redis.call('exists', KEYS[1]) == 1) then"
+ " local occStock = tonumber(redis.call('get', KEYS[1]));"
+ " if (occStock >= 0) then"
+ " return redis.call('incrBy', KEYS[1], ARGV[1]);"
+ " end;"
+ "end;"
+ " redis.call('SET', KEYS[1], ARGV[1]);"
+ " return tonumber(redis.call('get', KEYS[1]));";