pycharm运行模型时怎么设置权重?_用通用的语义分割模型实现裂缝检测

前期试错
说来也是曲折,先是找了一篇PSPNet训练自己样本集的博文(如下),兴冲冲以为很快就可以搞定
https://blog.csdn.net/ziyouyi111/article/details/80416935blog.csdn.net用的是TensorFlow的框架下该项目
hellochick/PSPNet-tensorflowgithub.com
来来回回折腾了快一个礼拜,好不容易可以跑训练代码,最后跑出来的模型有很大问题,预测出来的图像是全黑的,因为TensorFlow的先构建静态图,然后再填充数据(feed)的机制,要在TensorFlow上Debug的难度可想而知,TensorFlow查看变量方法如下:
https://blog.csdn.net/sa726663676/article/details/81835333blog.csdn.net出现训练时loss很快归0,预测图片全黑的问题
1.首先是以为裂缝像素占所有像素的比例很小,正负样本极不平衡,预测全为0,尝试将Loss函数改为使用 tf.nn.sparse_softmax_cross_entropy_with_logits()继续尝试用Train.py训练模型,结构发现结果并没有改变。
和凯哥讨论过后,发现语义分割不存在正负样本不平衡的问题,语义分割的是指对一张图所有像素做多分类(归为哪一标签),Loss函数和图片多分类问题是相似的,都是交叉熵;不过语义分割不存在正负样本不平衡的问题,是因为关心的前景分类(裂缝)像素总体特征是相似的,而且从整个样本集来看数量很多,留下的特征是不断叠加的,而背景(后景分类)像素特征是随机的,因此大量背景的特征平均之后,特征量很少,没有留下来。
2.用控制变量法,企图通过修改一个个参数,查看模型训练后的test表现,以为是Loss函数的正则项的问题,最后找到Weight decay权重衰减项过小导致了过拟合,初期迭代20轮左右的模型test确实正常,但是再过多轮迭代之后又会出现预测全黑的情况。尝试调整loss改为sigmoid、去掉L2loss(正则项)、调整Weight_decay权重衰减系数(0,0.001,0.0001,0.00005,0.00001),在迭代30轮之后的模型test输出图像变为全黑输出,同样存在问题。

3.一筹莫展的时候想到用Tensor Board进一步检查PSPNet网络中的问题,主要参考
毕骁鹏:使用Tensorflow时的爽物之Tensorboardzhuanlan.zhihu.com
# 记录一个tensor,之后产出这个tensor中元素的直方图和分布随迭代次数i之间的关系,支持二级名称
tf.summary.histogram('name/sub_name',weight_tensor)
# 记录一个标量,之后产出这个标量和迭代次数i之间关系的曲线图
tf.summary.scalar('name/sub_name',scalar_val)
# 指定输出文件夹路径以及对应的计算图,之后产出此计算图的图形化展示
writer = tf.summary.FileWriter('./graph',sess.graph)
# 定例搞法,一般在一个循环里操作,i是需要把上面标量和分布去绑定的迭代次数
merged = tf.summary.merge_all()
result = sess.run(merged)
writer.add_summary(result,i)想要查看模型计算图,一打开TensorBoard,看着巨大的网络发呆,看不出模型哪有问题。
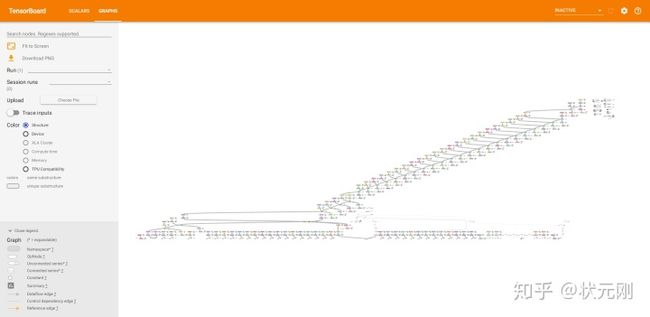

4.输出的图像仍有问题,Debug发现是Mask读入尺寸和值,以及0-255范围与0,1标签问题的处理出现问题,需要进一步Debug。尤其要注意Mask标注的png格式是否和所需的原数据集Mask标注png格式是否完全一致,“L”型、“1”型还是“RGB”型?图片维度是h*w还是h*w*d?最好都通过Debug方式用cv2或者PIL函数读取查看进行仔细比对。
学会怎样用Pycharm通过断点Step Over逐步运行程序相当重要,观察Debug窗口中变量的变化,可以更好的理解代码与更快的找到错误。
小结:
就像凯哥在分享会上所说的那样,Tensorflow像C语言那样先编译后计算,先建立静态图,然后再填入实值进行计算,运算相对高效,且在工业界部署等整套流程完善,缺点就是调试代码极其麻烦,出现了问题,有两种原因,一种是TensorFlow内code出现问题,另一种是本身模型存在缺陷,但是无法确定究竟哪里有问题,,因此TensorFlow更适合中高级程序员(代码能力过硬)。
Pytorch采用动态图计算,更像是Python、Matlab的风格,设置断点即可看到运行过程中的变量值,调试代码方便许多,因此更适合高校师生以及研究人员做算法研究与实现,而不必过考虑工业落地的问题。
因此,对于后续研究,我可能更会考虑用Pytorch和Keras来建立和调试模型。看来Pytorch还是很有必要学一下的。
采取策略:
因之前测试仍未成功,改为先验证项目模型的有效性,主要是train代码的有效性,在项目中提到的原样本集上进行训练,测试验证模型有效之后,再考虑将项目原样本集换成自己裂缝的数据集进行调参,目的是确保项目模型的train代码没有问题,否则后续调整代码时出现效果不佳的情况,难以界定问题是出在原本的代码问题,还是其他问题所导致的。
成功经验
利用image-segmentation-keras中的vgg_unet模型,成功在其原数据集dataset1上实现训练,而且语义分割效果正确。
排除法一步步去除问题,一般先验证在原数据集上模型有效性与训练的有效性,再次基础上进行修改以适应自己的样本集。
附上语义分割代码:
divamgupta/image-segmentation-kerasgithub.com



总之把image-segmentation-keras中的vgg_unet模型给训练成功了,也就是验证改训练代码至少没什么太大问题,下一步就是考虑怎么把训练的样本集换成我们自己裂缝图像的样本集。
原github项目的Python脚本模式写的有问题,我自己改了一下,可以实现训练:
#start_train.py
原Github项目命令行模式在Anaconda的命令行里可以很好的执行,尤其是预测Predict模块,对应的Python脚本我写了老是出现问题,建议就直接用命令行形式。
当然最开始的时候预测的Output就是一片绿色:

怎么又失败了呢?反复排查,把问题聚焦在输入的Mask标签Png图片上,仔细看看原来数据集dataset1中一张Masl标注Png图像:

乍一看是全黑的,其实用以下脚本
from PIL import Image
import numpy as np
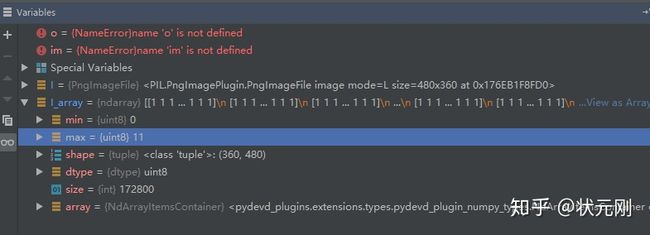
I = Image.open('D:神经网络模型image-segmentation-keras-masterdataset1/annotations_prepped_train/0001TP_006690.png')
I.show()
I_array = np.array(I)
print(I_array.shape)Debug可以发现,Mask标签图片最大值是11,相比于255还是很小,因此看上去就是全黑。


我们再来看看Crack500的png标签是什么样的,同样也是Debug得到:
from PIL import Image
import numpy as np
I = Image.open('D:神经网络模型image-segmentation-keras-masterdataset/traincrop_mask/20160222_081011_1_361.png')
I.show()
I_array = np.array(I)
print(I_array.shape)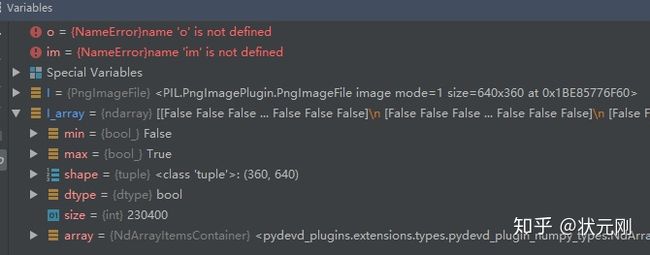
所以,发现两者的不同,现在为了使得和原先训练数据集dataset1的Label保持一致,把自己Crack500的mask(png图片)批量处理成只含有标签[0,1]的图片。
用以下脚本来把原先的“1”型PNG文件转成“L”型PNG文件,并把像素值255改成1:
import 这样Label就批量处理好了:

这次,为了保险起见,仍然使用之前验证成功的VGG_UNet模型进行测试:
#start_train_crack_vgg_unet.py
import keras_segmentation
model = keras_segmentation.models.pspnet.pspnet(n_classes=2, input_height=320, input_width=640)
#input_height, input_width必须是32的倍数,否则后续层需要修改
model.train(
train_images="./dataset/traincrop",
train_annotations="./dataset/traincrop_label",
checkpoints_path="./vgg_unet_checkpoints_crack",
val_images="./dataset1/valcrop",
val_annotations="./dataset/valcrop_label",
epochs=5
)生成模型vgg_unet_checkpoints_crack.4,进而进行测试,
python -m keras_segmentation predict --checkpoints_path="vgg_unet_checkpoints_crack"
--input_path="dataset/testcrop/" --output_path="dataset/testcrop_predict_vgg_unet/"效果如下:






总的来说,虽说效果不是特别好,毕竟之迭代了5轮,一轮512steps,batchsize=2,迭代更多轮次可能有更好的表现,但是表现最佳能达到什么程度,仍然需要继续训练。
用PSPNet在训练集上进行训练:
import keras_segmentation
model = keras_segmentation.models.pspnet.pspnet(n_classes=2, input_height=384, input_width=576)
#这里 input_height,input_width必须设置成192的倍数,否则需要修改模型内部层的参数
model.train(
train_images="./dataset/traincrop",
train_annotations="./dataset/traincrop_label",
checkpoints_path="./pspnet_checkpoints_crack",
val_images="./dataset1/valcrop",
val_annotations="./dataset/valcrop_label",
epochs=5
)训练4轮后
512/512 [==============================] - 1362s 3s/step - loss: 0.1062 - acc: 0.9584
saved ./vgg_unet_checkpoints_crack.model.4
Finished Epoch 4验证集准确率大概有95.8%,其实效果已经不错了,用以下命令流进行测试
python -m keras_segmentation predict --checkpoints_path="pspnet_checkpoints_crack"
--input_path="dataset/testcrop/" --output_path="dataset/testcrop_predict_pspnet/"效果如下:



可以观察到,PSPNet整体效果要比VGGUNet效果更好,这也是迭代了5轮,一轮512steps,batchsize=2的结果,接下来后续可以选用其他PSPNet50或者PSPNet_101模型,层数更多的模型预期会得到更好的表现。
接下来还可以玩点啥
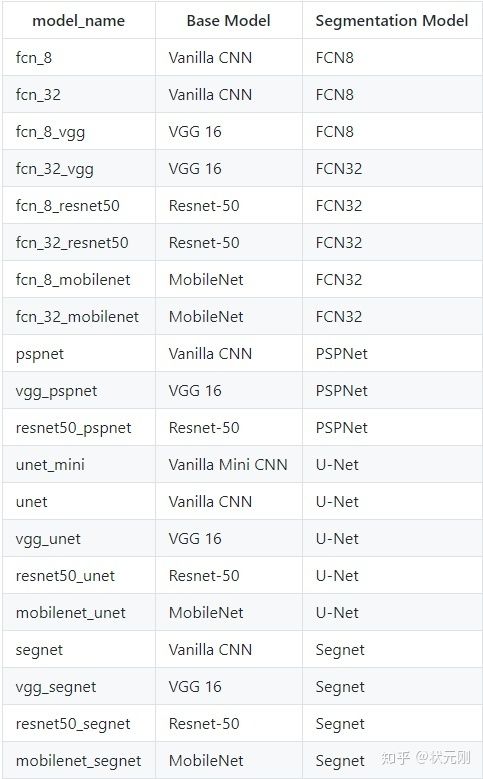
该Github项目给出了许多语义分割模型,大家有耐心的话可以挨个尝试一下,在裂缝检测上表现比较好的是哪些模型,也欢迎大家和我交流。
最后附上一个我个人认为质量很高的PSPNet代码讲解,不得不说,Keras版本代码确实比TensorFlow版本易读太多。
https://blog.csdn.net/u011974639/article/details/78985130blog.csdn.net