yolov5 7.0版本部署手机端。通过pnnx导出ncnn。
yolov5 7.0版本部署手机端。通过pnnx导出ncnn。
- 流程
- 配置ncnn android yolov5
- 导出自己模型的ncnn
-
- 修改yolo.py文件
- 导出TorchScript文件
- pnnx转torchscript为ncnn
- 安卓运行
-
-
- 权重路径
- 输入输出
- anchors 大小
- 类别名
- generate_proposals方法修改
- 结果
-
流程
网络yolov5 的部署已经有很多了,但是他们很多都是老版本,2023.12.03最新的版本是7.0。导致现在部署碰到各种问题。如下:
- (根源) yolov5 export.py导出onnx时添加train参数。但是train参数在最新的7.0版本已经被去掉了。导致问题。
- 没有train参数后,使用export.py 导出onnx,再将onnx转ncnn时报错。修改onnx模型麻烦且容易出问题。
本文使用pnnx代码库https://github.com/pnnx/pnnx将torchscript转为ncnn.避免上述问题。流程如下:

配置ncnn android yolov5
代码库:https://github.com/nihui/ncnn-android-yolov5。先使用代码库中提供的yolov5s ncnn权重。手机端能正常运行并产生输出。

导出自己模型的ncnn
修改yolo.py文件
老版本的export.py 中,通过添加train参数,去除模型中的后处理。但是新版本中,这个参数没了,所以我们需要将模型中的后处理去掉。
找到yolov5代码中的models->yolo.py文件,将Detect类下面的forward函数替换(大概是56-80行),修改为下面的forward
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
feat = self.m[i](x[i]) # conv
# x(bs,255,20,20) -> x(bs,20,20,255)
feat = feat.permute(0, 2, 3, 1).contiguous()
z.append(feat.sigmoid())
return tuple(z)
导出TorchScript文件
直接导出即可
python export.py --weights yolov5s.pt --include torchscript
pnnx转torchscript为ncnn
代码库:https://github.com/pnnx/pnnx.直接使用releases中的可执行文件即可。使用下面的命令转。需要注意的是zsh不支持官网的[]命令,需要用""包裹
'./pnnx' 'yolov5s.torchscript' "inputshape=[1,3,640,640]"
正常情况下,在yolov5s.torchscript的文件中已经产生了yolov5s.ncnn.bin 和yolov5s.ncnn.param。这就是我们要的ncnn文件。
安卓运行
将上面的yolov5s.ncnn.bin 和yolov5s.ncnn.param都放入ncnn-android项目文件夹。路径是ncnn-android-yolov5/app/src/main/assets/,这里面应该有一个yolov5s.bin和yolov5s.param。我们将我们转的模型也放进去。如下图。

然后我们修改yolov5ncnn_jni.cpp文件(上图中的绿色框)。修改模型权重路径,输入输出、anchors大小和类别名。
权重路径
全局搜索yolov5.load_param,将后面的yolov5s.param修改为自己的param名。就在这个代码附近有bin的加载.同理修改
输入输出
打开https://netron.app/,然后将param拖进去, 最上面的这个名字是in0,将in0填写到ex.input中。 模型有三个输出,分别对应stride 8,stride 16和stride 32.将这个输出的名字也填写到对应位置。一般情况下,stride 8对应out0,stride 16对应out1,stride 32对应out2.
 最上面的模型输出,以及对应的名字
最上面的模型输出,以及对应的名字
下面是应该填写的位置。红色是input,绿色是output.

模型的第一个头。同理可找另外两个头。

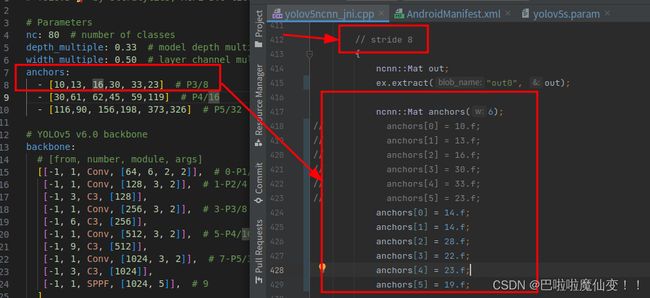
anchors 大小
anchors的大小就在ex.extract的下方。一共有3个地方需要填写,对应stride 8(小物体),stride 16和stride 32(大物体)。如果自己的网络anchors大小没变则不用改。下图是stride 8 的修改。
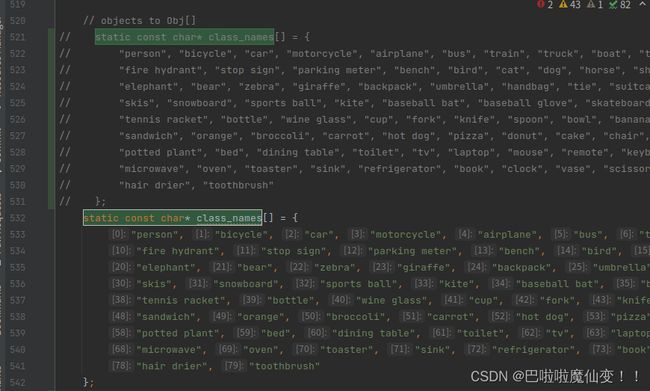
类别名
类别名。全局搜索static const char* class_names。改成自己的就好了。
generate_proposals方法修改
把整个generate_proposals方法的代码用下面的代码替换。大概在yolov5ncnn_jni.cpp文件的185行。
static void generate_proposals(const ncnn::Mat& anchors, int stride, const ncnn::Mat& in_pad, const ncnn::Mat& feat_blob, float prob_threshold, std::vector<Object>& objects)
{
const int num_w = feat_blob.w;
const int num_grid_y = feat_blob.c;
const int num_grid_x = feat_blob.h;
const int num_anchors = anchors.w / 2;
const int walk = num_w / num_anchors;
const int num_class = walk - 5;
for (int i = 0; i < num_grid_y; i++)
{
for (int j = 0; j < num_grid_x; j++)
{
const float* matat = feat_blob.channel(i).row(j);
for (int k = 0; k < num_anchors; k++)
{
const float anchor_w = anchors[k * 2];
const float anchor_h = anchors[k * 2 + 1];
const float* ptr = matat + k * walk;
float box_confidence = ptr[4];
if (box_confidence >= prob_threshold)
{
// find class index with max class score
int class_index = 0;
float class_score = -FLT_MAX;
for (int c = 0; c < num_class; c++)
{
float score = ptr[5 + c];
if (score > class_score)
{
class_index = c;
class_score = score;
}
float confidence = box_confidence * class_score;
if (confidence >= prob_threshold)
{
float dx = ptr[0];
float dy = ptr[1];
float dw = ptr[2];
float dh = ptr[3];
float pb_cx = (dx * 2.f - 0.5f + j) * stride;
float pb_cy = (dy * 2.f - 0.5f + i) * stride;
float pb_w = powf(dw * 2.f, 2) * anchor_w;
float pb_h = powf(dh * 2.f, 2) * anchor_h;
float x0 = pb_cx - pb_w * 0.5f;
float y0 = pb_cy - pb_h * 0.5f;
float x1 = pb_cx + pb_w * 0.5f;
float y1 = pb_cy + pb_h * 0.5f;
Object obj;
obj.x = x0;
obj.y = y0;
obj.w = x1 - x0;
obj.h = y1 - y0;
obj.label = class_index;
obj.prob = confidence;
objects.push_back(obj);
}
}
}
}
}
}
}
结果
点击运行。

参考:https://zhuanlan.zhihu.com/p/606440867