Characterizing possible failure modes in physics-informed neural networks
论文阅读:Characterizing possible failure modes in physics-informed neural networks
- Characterizing possible failure modes in physics-informed neural networks
-
- PINN的常见故障模式
-
- convection
- reaction-diffusion
- 软偏微分方程约束和优化困难
- 表现力与优化难度
-
- 课程正则化
- 序列到序列学习
- 总结
Characterizing possible failure modes in physics-informed neural networks
PINN的常见故障模式
作者首先从convection和reaction-diffusion入手,用实验证明了PINN即使在面对简单的pde方程时,也会产生故障。
convection
考虑如下一维对流问题:
∂ u ∂ t + β ∂ u ∂ x = 0 , x ∈ Ω , t ∈ [ 0 , T ] , u ( x , 0 ) = h ( x ) , x ∈ Ω . \begin{gathered} \frac{\partial u}{\partial t}+\beta\frac{\partial u}{\partial x} =0,\quad x\in\Omega,t\in[0,T], \\ u(x,0) =h(x),\quad x\in\Omega. \end{gathered} ∂t∂u+β∂x∂u=0,x∈Ω,t∈[0,T],u(x,0)=h(x),x∈Ω.
其中 β \beta β 为对流系数, h ( x ) h(x) h(x) 为初始条件,对于常对流系数与周期边界条件下的情况,其具有如下精确解:
u analytical ( x , t ) = F − 1 ( F ( h ( x ) ) e − i β k t ) u_{\text{analytical}} ( x , t ) = F ^ { - 1 }\big(F(h(x))e^{-i\beta kt}\big) uanalytical(x,t)=F−1(F(h(x))e−iβkt)
其中, F F F 为傅里叶变换, i = − 1 i=\sqrt {-1} i=−1 , k k k 代表了在傅里叶域上的频率。该问题对应的PINN损失如下:
L ( θ ) = 1 N u ∑ i = 1 N u ( u ^ − u 0 i ) 2 + 1 N f ∑ i = 1 N f λ i ( ∂ u ^ ∂ t + β ∂ u ^ ∂ x ) 2 + L B \mathcal{L}(\theta)=\frac1{N_u}\sum_{i=1}^{N_u}\left(\hat{u}-u_0^i\right)^2+\frac1{N_f}\sum_{i=1}^{N_f}\lambda_i\Big(\frac{\partial\hat{u}}{\partial t}+\beta\frac{\partial\hat{u}}{\partial x}\Big)^2+\mathcal{L}_{\mathcal{B}} L(θ)=Nu1i=1∑Nu(u^−u0i)2+Nf1i=1∑Nfλi(∂t∂u^+β∂x∂u^)2+LB
其中 u ^ = N N ( θ , x , t ) \hat u = NN(\theta,x,t) u^=NN(θ,x,t) 为神经网络的输出, L B \mathcal L_\mathcal B LB 为边界损失。对于 Ω = [ 0 , 2 π ) \Omega =[0, 2\pi) Ω=[0,2π) 上的周期性边界条件,其损失函数如下:
L B = 1 N b ∑ i = 1 N b ( u ^ ( θ , 0 , t ) − u ^ ( θ , 2 π , t ) ) 2 \mathcal{L}_{\mathcal{B}}=\frac1{N_b}\sum_{i=1}^{N_b}\left(\hat{u}(\theta,0,t)-\hat{u}(\theta,2\pi,t)\right)^2 LB=Nb1i=1∑Nb(u^(θ,0,t)−u^(θ,2π,t))2
本例使用以下简单的初始和周期性边界条件:
u ( x , 0 ) = s i n ( x ) , u ( 0 , t ) = u ( 2 π , t ) . \begin{aligned}u(x,0)&=sin(x),\\u(0,t)&=u(2\pi,t).\end{aligned} u(x,0)u(0,t)=sin(x),=u(2π,t).
作者将 PINN 的软正则化应用于这个问题。 训练后, PINN 的预测解和解析解之间的相对误差和绝对误差,如下图所示。

可以看到,PINN 只能在对流系数较小的情况下获得良好的解,而当 β \beta β 变大时,它会失败,当 β > 10 \beta > 10 β>10 时,相对误差几乎达到 100%。中间为精确解的可视化结果,右侧为PINN解的可视化结果。可以清楚地看到 PINN 无法学习正确解。后面作者将证明神经网络架构确实有足够的能力来近似正确解,但训练/优化问题很难用 PINN 来解决(它可能需要大量的超参数调整,这在实践中通常是不可行的)。
reaction-diffusion
考虑如下反应扩散方程:
∂ u ∂ t − ν ∂ 2 u ∂ x 2 − ρ u ( 1 − u ) = 0 , x ∈ Ω , t ∈ ( 0 , T ] , u ( x , 0 ) = h ( x ) , x ∈ Ω . \begin{aligned} \begin{aligned}\frac{\partial u}{\partial t}-\nu\frac{\partial^2u}{\partial x^2}-\rho u(1-u)\end{aligned}& =0,\quad x\in\Omega,t\in(0,T], \\ u(x,0)& =h(x),\quad x\in\Omega. \end{aligned} ∂t∂u−ν∂x2∂2u−ρu(1−u)u(x,0)=0,x∈Ω,t∈(0,T],=h(x),x∈Ω.
其中, ν ( ν > 0 ) \nu (\nu > 0) ν(ν>0) 是扩散系数。这种系统的解可以通过斯特朗分裂来求解,即将方程分成两个独立的模型(反应分量和扩散分量):
d u d t = ρ u ( 1 − u ) d u d t = ν ∂ 2 u ∂ x 2 \begin{aligned}\frac{du}{dt}&=\rho u(1-u)\\\frac{du}{dt}&=\nu\frac{\partial^2u}{\partial x^2}\end{aligned} dtdudtdu=ρu(1−u)=ν∂x2∂2u
对于每个时间步,可以通过如下方程求解反应方程:
u analytical ( x , t ) = h ( x ) e ρ t h ( x ) e ρ t + 1 − h ( x ) u_{\text{analytical}} ( x , t ) = \frac { h ( x ) e ^ { \rho t }}{h(x)e^{\rho t}+1-h(x)} uanalytical(x,t)=h(x)eρt+1−h(x)h(x)eρt
扩散方程有如下解析解:
u analytical ( x , t ) = F − 1 ( F ( u ( x , t = t n ) ) e − ν k 2 t ) u_{\text{analytical}} ( x , t ) = F ^ { - 1 }\big(F(u(x,t=t^n))e^{-\nu k^2t}\big) uanalytical(x,t)=F−1(F(u(x,t=tn))e−νk2t)
其中, u ( x , t = t n ) u(x,t=t^n) u(x,t=tn) 为第 n t h n^{th} nth 个时间步的解。作者首先求解每个时间步的反应方程,然后使用反应方程的解作为初始条件来求解扩散分量并得到最终的解。这个问题的PINN损失可以表示如下:
L ( θ ) = 1 N u ∑ i = 1 N u ( u ^ − u 0 i ) 2 + 1 N f ∑ i = 1 N f λ i ( ∂ u ^ ∂ t − ν ∂ 2 u ^ ∂ x 2 − ρ u ^ ( 1 − u ^ ) ) 2 + L B \begin{aligned} \mathcal{L}(\theta)=\frac1{N_u}\sum_{i=1}^{N_u}\left(\hat{u}-u_0^i\right)^2+ \frac{1}{N_f}\sum_{i=1}^{N_f}\lambda_i\Big(\frac{\partial\hat{u}}{\partial t}-\nu\frac{\partial^2\hat{u}}{\partial x^2}-\rho\hat{u}(1-\hat{u})\Big)^2+\mathcal{L}_{\mathcal{B}} \end{aligned} L(θ)=Nu1i=1∑Nu(u^−u0i)2+Nf1i=1∑Nfλi(∂t∂u^−ν∂x2∂2u^−ρu^(1−u^))2+LB
与之前的情况类似,可以看到 PINN 也无法学习反应扩散。下图为当 ν = 5 \nu = 5 ν=5 时 ρ = 5 \rho = 5 ρ=5 的情况。
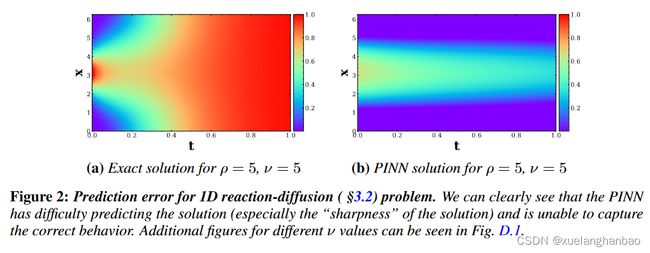
PINN 的相对误差高达 93% 。在这里,可以清楚地看到 PINN 无法捕获反应或扩散分量。不同 ν \nu ν 值的附加图如下:
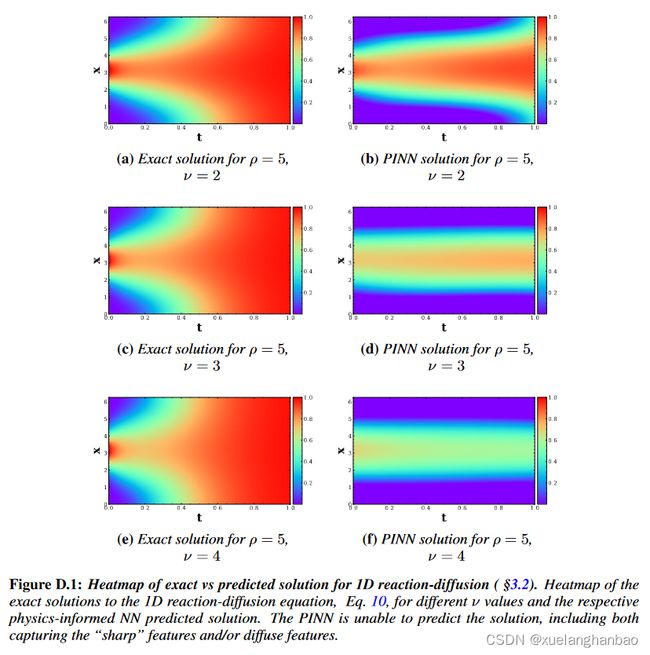
当 ν = 2 \nu = 2 ν=2 时,PINN 的相对误差为 50%。可以看到,尽管它可以更好地预测解的中心,但它无法捕获“更清晰”的转变。
软偏微分方程约束和优化困难
从上面两个样例可以看出,即使对于简单的物理状态,PINN 也会导致很高的误差,特别是对于具有非平凡对流/反应/扩散系数的偏微分方程/常微分方程。作者将这种情况归因于 L F \mathcal L_\mathcal F LF 使用基于偏微分方程的软约束,这使得损失景观难以优化。
作者分析了上文中的对流问题在有/没有 PINN 软正则化的情况下,不同情况下的损失情况如何变化。结果表明,添加软正则化实际上会使问题更难优化,即正则化会导致损失景观不太平滑。对于所有实验,作者通过扰动前两个主要 Hessian 特征向量的(经过训练的)模型并计算相应的损失值来绘制损失图。这往往比随机方向扰动模型参数提供更多信息 。
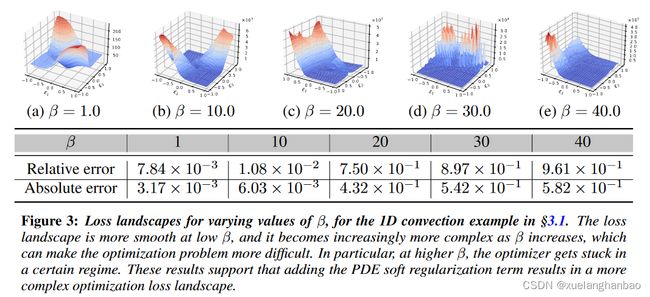
上图显示了不同 β \beta β 值的对流问题的损失情况。有趣的是,相对较低的 β = 1 β = 1 β=1 时的损失景观相当平滑,但增加 β β β 会进一步导致复杂且不对称的损失景观。同样明显的是,优化器陷入了局部极小值,对于大的 β β β 值具有非常高的损失函数。
最后,作者研究了改变软正则化项(即 λ \lambda λ 参数)的权重/乘数的影响,这与提高 PINN 性能相关。虽然作者发现调整 λ \lambda λ 可以帮助改变误差,但它不能解决问题,如下图所示。
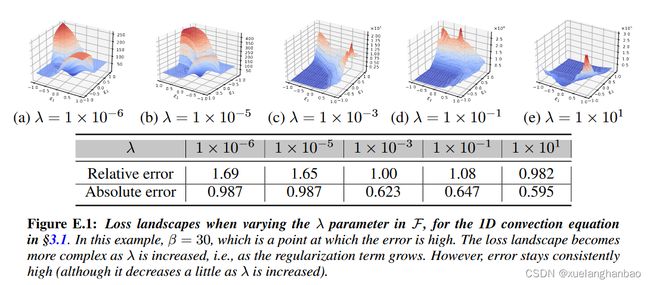
值得注意的是,随着正则化参数的增加,损失情况变得越来越复杂且更难以优化(此外,请参见 z 轴比例)。
表现力与优化难度
课程正则化
为了证明PINN表现不好并不是由于神经网络的表达能力不足,作者设计了课程正则化方法,通过找到良好的权重初始化来热启动神经网络训练。并不是训练 PINN 立即学习具有较高 β / ρ \beta / \rho β/ρ 的情况的解决方案,而是首先在较低 β / ρ \beta / \rho β/ρ 上训练 PINN(PINN 更容易学习),然后逐渐转向在较高 β / ρ \beta / \rho β/ρ 上训练 PINN 。这有点类似于 ML中的课程学习,使 PDE/ODE 逐渐更难求解。

上图展示了 β = 30 \beta = 30 β=30 的示例对流情况的训练过程。课程正则化方法产生的解决方案比常规 PINN 训练准确得多。通过课程正则化,相对误差几乎降低了两个数量级。

上表展示了更多其他 β \beta β 情况下的训练结果。
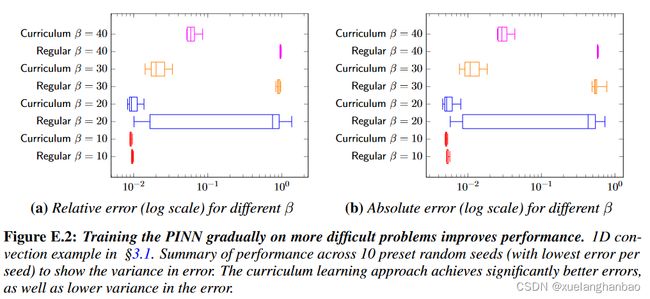
上图则表明课程正则化不仅显着降低了误差,而且还降低了误差的方差。

在上图中,可以看到与常规 PINN 训练相比,课程正则化导致损失情况更加平滑。
序列到序列学习
原始 PINN 方法训练 NN 模型一次性预测整个时空(即预测所有位置和时间点的 u u u)。在某些情况下,这可能更难学。在这里,作者证明,将问题作为序列到序列(seq2seq)学习任务可能会更好,其中神经网络仅学习在下一个时间步(而不是所有时间)预测解决方案。
这样,可以使用时间前进方案来预测不同的序列/时间点。需要注意的是,此处唯一可用的数据来自偏微分方程本身,即仅初始条件。通过在 t = Δ t t = \varDelta t t=Δt 时进行预测,并以此作为初始条件在 t = 2 Δ t t = 2\varDelta t t=2Δt 时进行预测,依此类推,如下图所示:

作者发现将问题作为 seq2seq 学习可以显着降低错误。对于反应和反应扩散情况,差异尤其显着,其中 seq2seq PINN 模型将误差降低了几乎两个数量级,如下表所示:
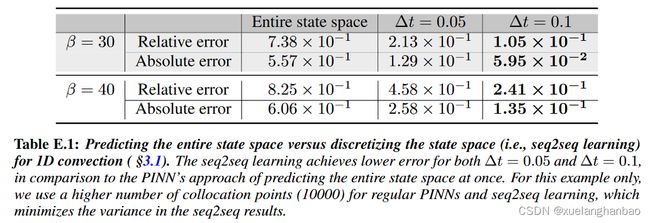
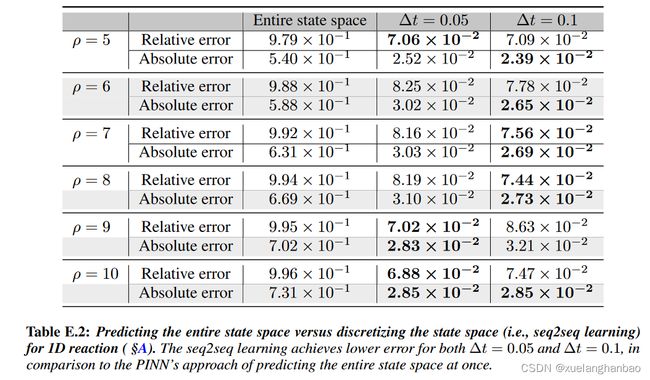

上图为 1D reaction-diffusion 的结果,其中 seq2seq 方法能够恢复解,而常规 PINN 的效果非常差。请注意,这种行为也与科学计算中使用的数值方法类似,与时间推进方法相比,时空问题通常更难解决。直观上,由于问题是病态的,限制维度预计会有所帮助。此外,与整个时间范围相比,输入到解决方案的底层函数/映射应该更简单地在较小的时间跨度内进行近似。
总结
作者通过convection和reaction-diffusion两个样例展示了PINN在简单情况下的故障问题,并通过可视化损失景观,认为使用软约束会导致优化困难。后续作者使用课程学习、序列到序列方法证明上述问题并不是由于神经网络表达能力不足导致的。
文中损失景观似乎是根据训练完成后模型参数的两个最大 Hessian 特征向量来进行可视化的,我不太清楚不同参数下的损失景观是否可以直接放在一起比较。以如下一维Poisson方程为例:
∇ 2 u = f \nabla^{2}u=f ∇2u=f
其中, f = − π 2 sin ( π x ) f=-\pi^2\sin(\pi x) f=−π2sin(πx) 。在 Ω = [ 0 , 25 ] \Omega=[0,25] Ω=[0,25] 施加狄利克雷边界条件如下:
u ( 0 ) = u ( 25 ) = 0 u(0)=u(25)=0 u(0)=u(25)=0
其精确解为:
u = sin ( π x ) u=\sin(\pi x) u=sin(πx)
PINN训练结果如下:

其损失景观如下:

从图中可以看出,损失景观也是比较平滑的,但PINN依然没有学习到正确的解。所以,我不太确定损失景观的方法是否有足够的说明能力,后面可能会去看一下相关文章。
同时,本文虽然公开了代码,但只包含了原始PINN的部分,课程学习和序列到序列的方法均未包含,所以我也不知道序列到序列方法中提到的
通过在 t = Δ t t = \varDelta t t=Δt 时进行预测,并以此作为初始条件在 t = 2 Δ t t = 2\varDelta t t=2Δt 时进行预测
具体是怎么实现的,猜测是以 Δ t \varDelta t Δt 预测结果在 2 Δ t 2\varDelta t 2Δt 时刻当做真实数据吧。
相关链接:
- 原文:[2109.01050] Characterizing possible failure modes in physics-informed neural networks (arxiv.org)
- 代码:a1k12/characterizing-pinns-failure-modes: Characterizing possible failure modes in physics-informed neural networks. (github.com)