Hadoop——分布式存储HDFS
HDFS集群环境部署
VMware虚拟机中部署
一、https://hadoop.apache.org中下载安装包

二、环境分配

三、上传、解压
确认服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等
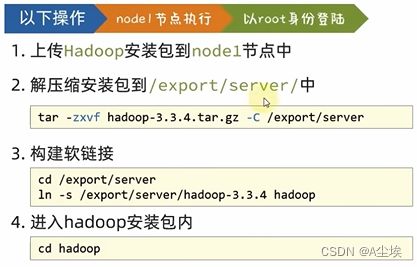
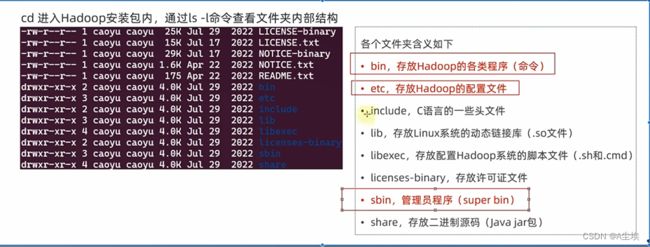
四、修改配置文件



hdfs-site.xml
①、dfs.datanode.data.dir.perm 700
hdfs文件系统,默认权限700,rwx------
②、dfs.namenode.name.dir /data/nn
NameNode元数据的存储位置 在node1节点的/data/nn目录下
需要在node1节点:mkdir -p /data/nn mkdir data/dn 创建两个文件夹目录
③、dfs.namenode.hosts
NameNode允许哪几个节点的DataNode连接(即允许加入集群)
node1/node2/node3这三台服务器被授权
④、dfs.blocksize
默认块大小
⑤、dfs.namenode.handler.count
namenode处理的并发线程数 100 表示以100个并行度处理文件系统的管理任务
⑥、dfs.datanode.data.dir
从节点dataNode的数据存储目录
/data/dn,即数据存放在node1,node2,node3三台机器的/data/dn内
mkdir -p /data/dn 需要在node2,node3各创建一个文件夹目录

五、从node1将hadoop安装目录文件夹远程复制到node2\node3,并且配置环境变量

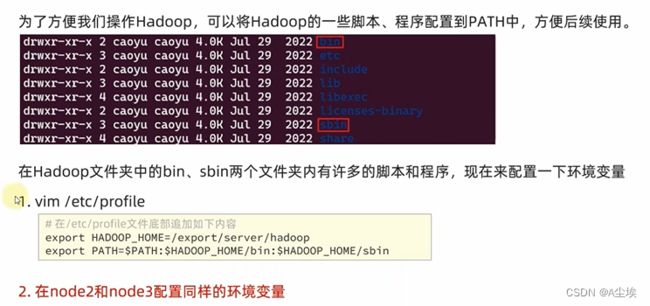
六、授权hadoop用户
为了确保安全,hadoop系统不以root用户启动,将以普通的hadoop来启动整个hadoop服务
所以需要对文件权限进行授权(前提需要创建好hadoop用户,并配置好了hadoop用户之间免密登录)
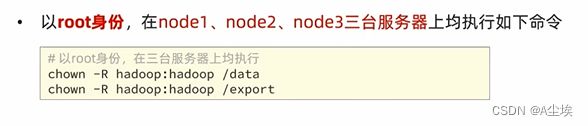
七、对整个文件系统执行初始化
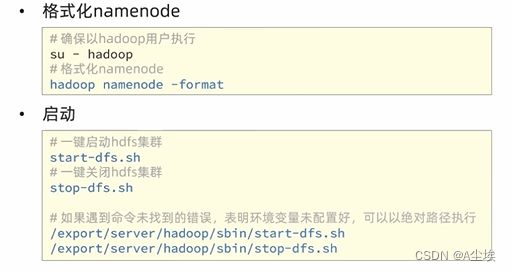
通过jsp命令查看,三台节点的运行程序

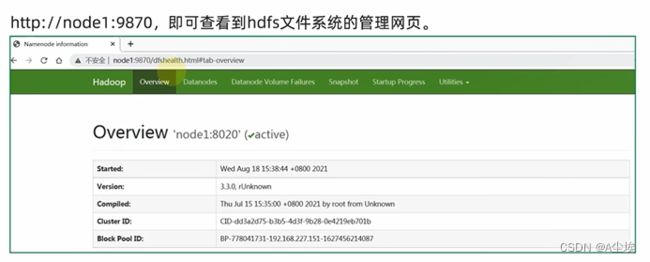
八、浏览器查看
关闭hadoop系统之后,然后init 0,关闭虚拟机,进行快照操作

云服务器中部署

以上步骤和虚拟机一样。
三、云服务是通过内网互通
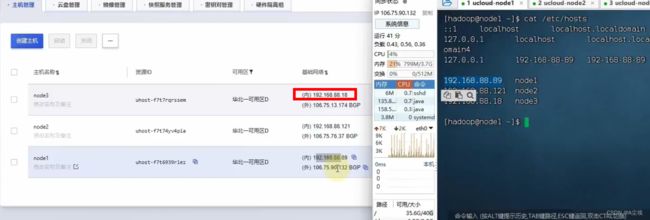
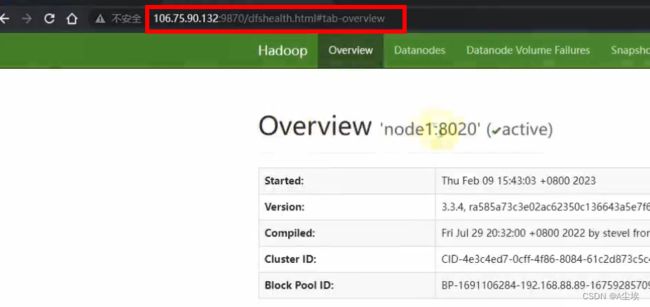
通过浏览器访问需要公网IP
四、云服务中操作镜像

集群部署常见问题

一、权限被拒绝
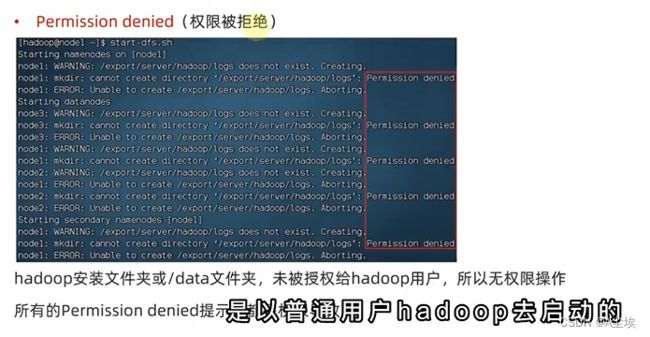
需要对hadoop用户授权

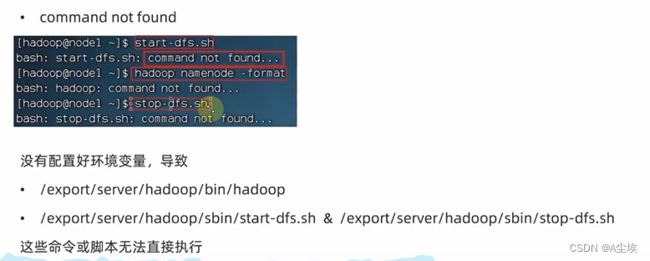
二、command not found
三、worker文件

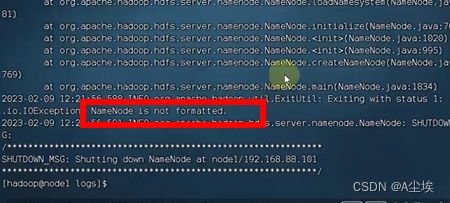
四、未格式化
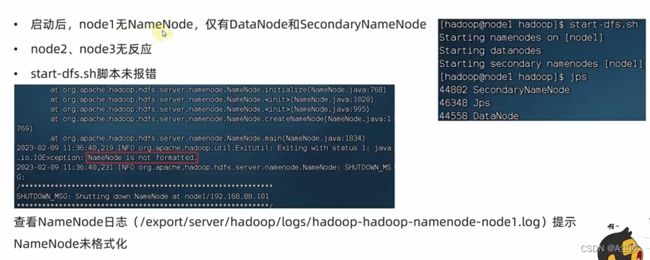
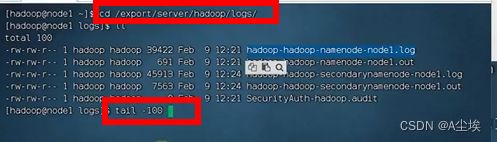
排查日志
======================================================================================
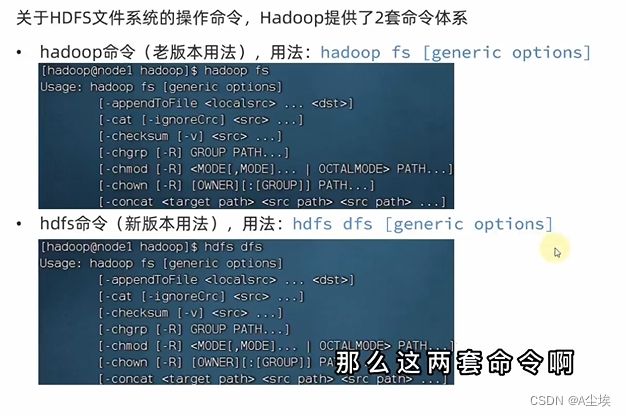
HDFS的Shell操作
进程启停管理
①、一键启停脚本

②、独立进程启停(只对所在机器有效)

文件系统操作命令
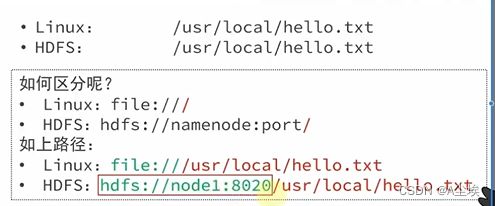
协议头file:/// 或hdfs://node1:8020/ 可以省略
- 需要提供Linux路径的参数会自动识别为file://
- 需要提供HDFS路径的参数会自动识别为hdfs://
①、创建文件夹
# path 为待创建的目录
# -p选项的行为与Linux mkdir -p一致,沿着路径创建父目录
hadoop fs -mkdir -p /michael/bigdata
hadoop fs -mkdir -p hdfs://node1:8020/michael/bigdata #带上协议头
hdfs fs -mkdir -p /michael/hadoop
# 如果添加协议头(在Linux创建)
hadoop fs -mkdir -p file:///home/hodoop/test
②、查看指定目录下的内容
# path 指定目录路径
# -h 人性化显示文件size kb
# -R 递归查看指定目录以及子目录
hadoop fs -ls / # hadoop根目录下
hdfs dfs -ls -R /
③、上传文件到HDFS指定目录下
# -f 覆盖目标文件
# -p 保留访问和修改时间,所有权和权限
# localsrc 本地文件系统(客户端所在机器)
# dst 目标文件系统(HDFS)
hadoop fs -put word.txt /michael
hdfs dfs -put file:///etc/prifile hdfs://node1:8020/michael
④、查看HDFS文件内容
hadoop fs -cat /test.txt
# 对于大文件,可以使用管道符配合more 按下空格进行翻页查看
hdfs dfs -cat /test.txt | more
⑤、下载HDFS文件
# -f 覆盖目标文件
# -p 保留访问和修改时间,所有权和权限
# HDFS->Linux下载
hadoop fs -get /test.txt . # .表示当前目录
⑥、拷贝HDFS文件
# HDFS->HDFS
hadoop fs -cp /test.txt /home/
# 也可以添加-p强制覆盖,并改名
hadoop fs -cp /test.txt /home/abc.txt
⑦、追加数据到HDFS文件中
echo 1 >> 1.txt
echo 2 >> 2.txt
echo 3 >> 3.txt
hadoop fs -put 1.txt /
hadoop fs -cat /1.txt
# 本地内容追加到hdfs
hadoop fs -appendToFile 2.txt 3.txt /1.txt
hadoop fs -cat /1.txt
⑧、移动
hadoop fs -mv /test.txt /michael
hadoop fs -mv /test.txt /michael/abx.txt #移动之后还可以改名
⑨、删除
hadoop fs -rm -f /home # 删除home文件夹目录
hadoop fs -rm /michael/test.txt # 删除文件,不需要添加-r

如果开启了回收站之后,删除文件是需要通过指定参数跳过回收站
hadoop fs -rm -r -skipTrash /michael
除了以上通过命令的方式查看文件,可以通过浏览器进行查看

但没有权限去操作,只能查看。



HDFS客户端-Jetbrians产品插件

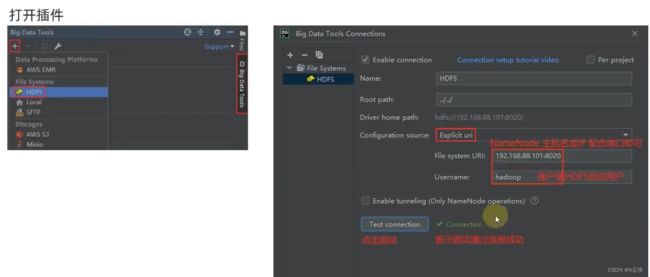
①、以DataGrip工具为例,安装Big Data Tools插件

②、配置Window,然后重启DataGrip工具

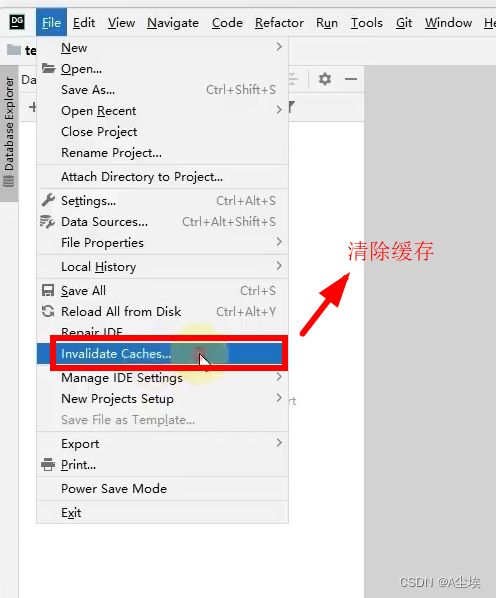
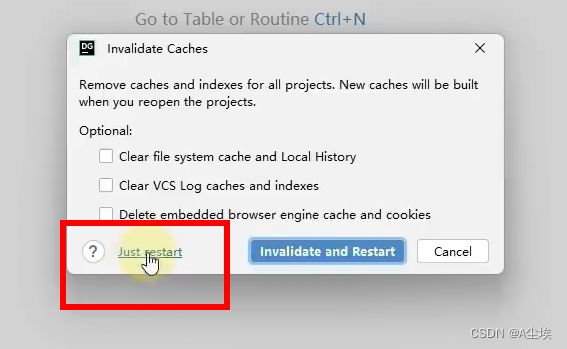
③、配置Big Data Tools插件
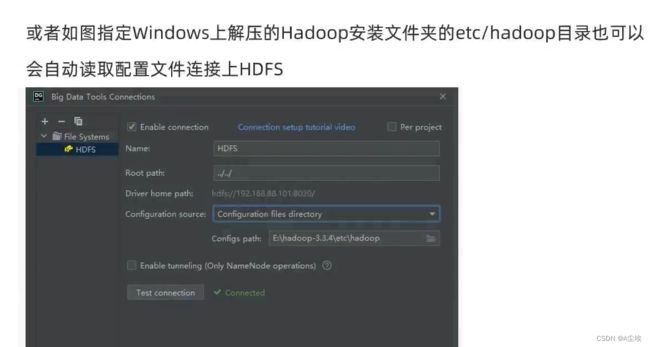
或者
(需要重新打包配置文件等进行替换)
④、配置成功之后,可以操作上传文件
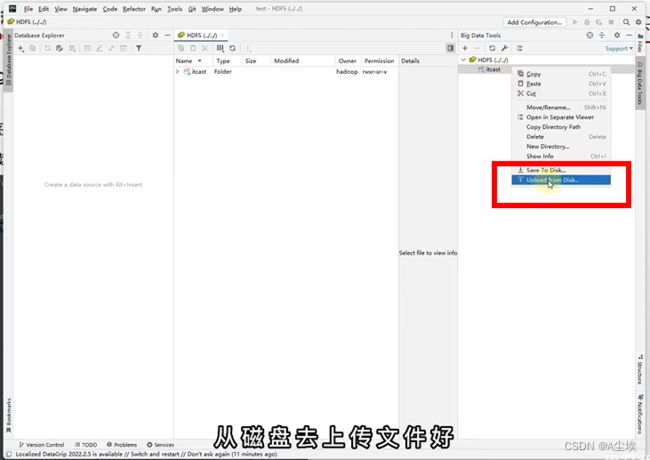
HDFS客户端-NFS

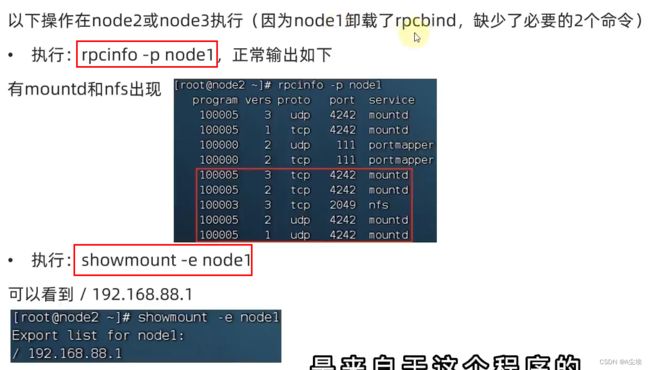
①、在node1节点上进行如下操作:
进入cd /export/server/hadoop/etc/hadoop目录下配置如下文件
core-site.xml内新增如下两项

hdfs-site.xml新增如下:

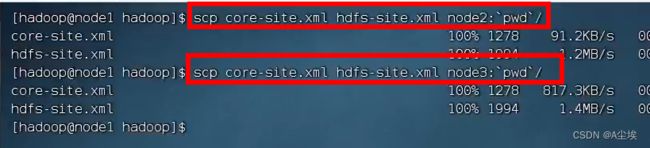
②、将以上node1配置好的节点复制到node2和node3中

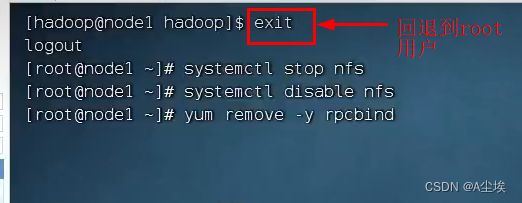
停止系统NFS相关进程需要回退到root用户的权限
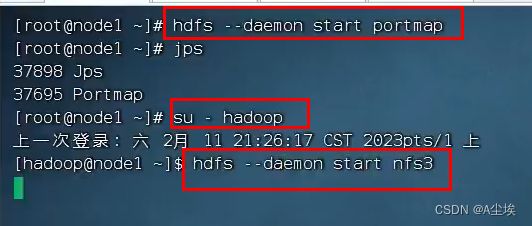
启动集群:start -dfs.sh
③、检查NFS是否正常
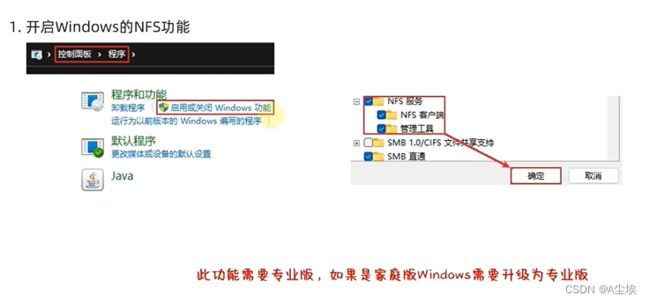
④、在Window挂载HDFS文件系统

HDFS的存储原理
block块


副本要放在不同的服务器,可以设置配置文件决定副本存储,还可以通过命令临时设置
①、配置文件设置

②、临时命令设置

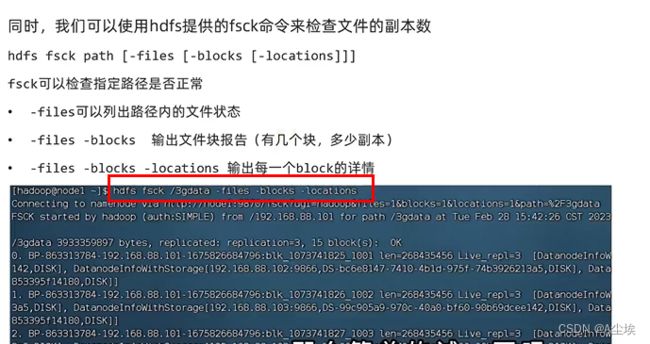
fsck命令
NameNode元数据
NameNode基于一批edits和一个fsimage文件的配合完成对整个文件系统的管理和维护。
-
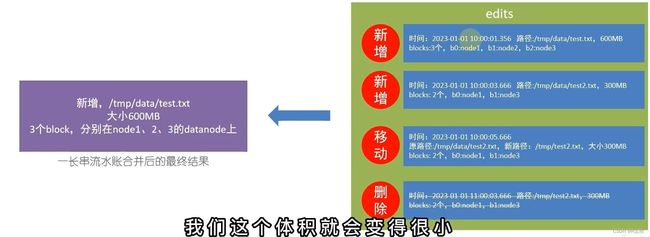
edits文件,是一个流水账文件,记录hdfs中的每一次操作,以及本次操作的文件其对应的block,为了保证检索功能会存在多个edits文件,确保不会出现过大的edits文件
-
FSImage文件,全部的edits文件合并为最终结果,即得到一个FSImage文件
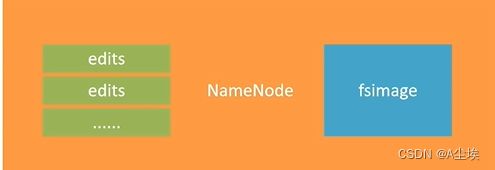
①、整个文件系统的管理流程:

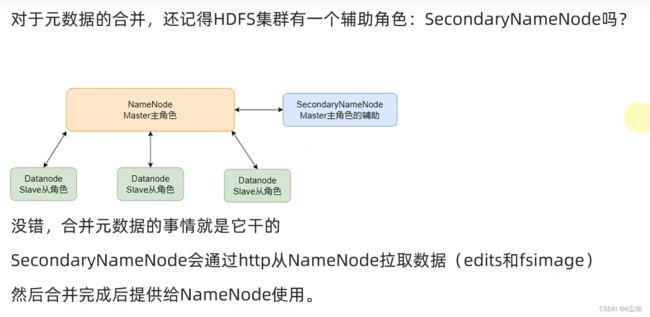
②、元数据合并控制参数

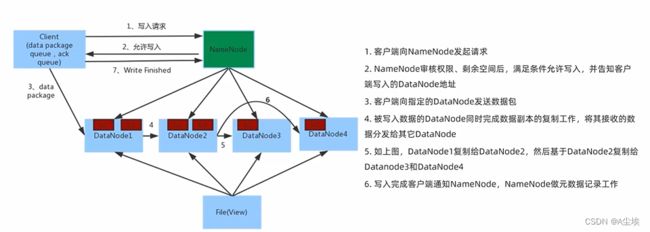
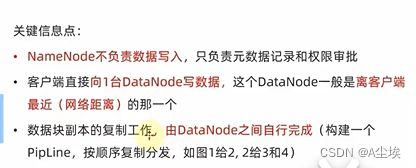
HDFS数据的读写流程
一、数据写入流程
二、数据读取流程
